Лекция 6. Дисперсионный и корреляционный анализ.
1). Назначение и сущность дисперсного анализа. Классификация.
2). Однофакторный дисперсный анализ.
Назначение и сущность дисперсионного анализа. Классификация по видам.
Дисперсионный анализ представляет собою совокупность методов обработки результатов испытаний, зависящих от различных одновременно действующих количественных факторов с целью установления значимости их влияния на дисперсный отклик. При этом количественные факторы также рассматриваются как качественные.
Сущность дисперсионного анализа заключается в разложении с помощью специальных правил общей дисперсии результата испытаний на независимые слагаемые, каждый из которых характеризует влияние того или иного фактора. Последующее сравнение этих слагаемых между собой и с общей дисперсией позволяет оценивать влияние каждого из факторов на результат испытаний.
Пусть, например, ожидаемый результат наблюдений есть случайная величина Y, зависящая от двух факторов Х1 и Х2. Будем полагать известным математическое ожидание My. Тогда отклонение Δ=Y-My, которое может проявиться на опыте, также является величиной случайной, состоящей из трех слагаемых:
Δ =А+В+Г,
где А – отклонение, обусловленное влиянием фактора Х1,
В – отклонение, обусловленное влиянием фактора Х2,
Г - отклонение, обусловленное влиянием латентных факторов.
Предположим, что А, В и Г являя.тся независимыми случайными величинами с дисперсиями Dα, Dβ, Dγ соответственно.
Тогда:
D [Δ]= Dα + Dβ + Dγ
Но: D [Δ]= D [Y-My]=Dy
Следовательно, общая дисперсия отклика предстает в виде
Dy = Dα + Dβ + Dγ
Это соотношение между дисперсиями как раз и отражает сущность дисперсионного анализа. Сопоставляя Dα и Dβ между собою, можно судить о степени влияния учитываемых факторов по сравнению с латентными.
Существующие правила разложения общей дисперсии отклика на составляющие разработаны на основе ряда допущений, основным из которых является допущение о нормальном распределении отклика. На первый взгляд может показаться, что такое допущение существенно сужает область применимости правил дисперсного анализа. Но на самом деле это не так в силу двух важных обстоятельств: нормальное распределение широко распространено в практике испытаний технических изделий и, кроме того, в тех случаях, когда результаты наблюдений имеют распределение, отличное от нормального, можно прибегнуть к известным процедурам их нормализации.
Существует достаточно много видов дисперсионного анализа, соответствующих классификации, представленной в таблице 11.1.
Классификация видов дисперсного анализа. Таблица 11.1
| Признак классификации | Вид дисперсионного анализа |
| Число факторов | Однофакторный Многофакторный |
| Характер уровня факторов | С фиксированными уровнями факторов Со случайными уровнями факторов |
| Наличие пересечения факторов | С непересекающимися факторами С пересекающимися факторами |
| Число наблюдений результата | С одним наблюдением в ячейке С несколькими наблюдениями в ячейке |
| Число откликов | Одномерный Многомерный |
| Организация процесса наблюдения | С полным планом наблюдений С неполным планом наблюдений |
Смысловое содержание понятий, определяющих тот или иной вид дисперсионного анализа, удобно рассмотреть на следующем примере.
Пусть результаты наблюдений получены при использовании M1 типов приборов M2 наблюдателями в M3 условиях наблюдения. Как видно, все три фактора являются качественными: Х1 – тип прибора, Х2 – квалификация наблюдателя, Х3 – вид условий наблюдения. Если дисперсионный анализ проводить с учетом всех факторов, то будет иметь место многофакторный анализ. При этом числа M1, M2, M3 будут фигурировать в качестве фиксированных уровней факторов, если они заданы заранее, и в качестве случайных уровней, если они выбираются случайным образом из некоторого множества возможных значений.
Если каждый наблюдатель будет получать результаты с помощью каждого типа приборов, то факторы Х1 и Х2 будут пересекающимися. Если же каждый наблюдатель использует только свой, для него предназначенный тип прибора, то эти факторы не будут пересекающимися. Таким образом, приходим к выводу, что факторы являются пересекающимися, когда все уровни одного из них повторяются на каждом уровне другого.
Если для каждого уровня каждого фактора получено не более одного результата наблюдения, то имеет место анализ с одним наблюдением в ячейке, в противном случае – с несколькими наблюдениями.
Если в процессе наблюдения фиксируется один отклик, то анализ является одномерным, в противном случае – многомерным. Наконец, если результаты наблюдений получены для всех уровней всех факторов, то имеет место дисперсионный анализ с полным планом наблюдений, иначе – с неполным.
Однофакторный дисперсный анализ.
Для ознакомления с типовыми процедурами дисперсионного анализа рассмотрим случай, когда объект подвергается воздействию одного управляемого фактора и на выходе фиксируется один отклик.
Фактор проявляется на m заданных уровнях (k = 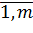 ). На каждом уровне фиксируется n значений отклика (j =
). На каждом уровне фиксируется n значений отклика (j = 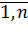 ). .
). .
Таким образом, имеем случай однофакторного одномерного дисперсионного анализа с фиксированными уровнями фактора, n наблюдениями в ячейке, с полным планом наблюдений. Условия испытаний и их результаты представлены в таблице 11.2.
Таблица 11.2
Условия и результаты испытаний.
| Уровни фактора | Результаты испытаний | Средний результат по уровням | ||||
| … | j | … | n | |||
| Y11 | … | Y1j | … | Y1n | Y1 | |
| … | … | … | … | … | … | … |
| k | Yk1 | … | Ykj | … | Ykn | Yk |
| … | … | … | … | … | … | … |
| m | Ym1 | … | Ymj | … | Ymn | Ym |
Обработку полученных результатов целесообразно начинать с определения средних значений – среднего по уровням 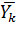 и общего среднего
и общего среднего 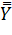 :
:
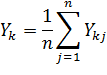
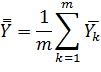
На втором этапе анализа определим общую сумму квадратов отклонений отдельных результатов Ykj от общего среднего :
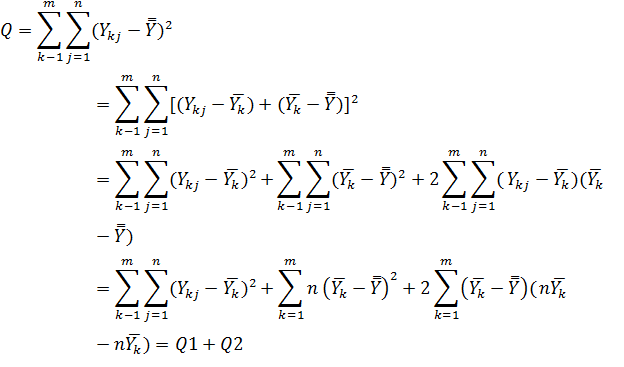
Где Q1= 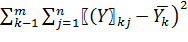
Q2= 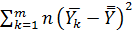
Как видно, общая сумма Qo разбивается на две составляющие Q1 и Q2, из которых первая характеризует внутриуровневый разброс опытных значений отклика, т.е. разброс относительно средних по уровням, а вторая – межуровневый, т.е. разброс средних по уровням относительно общего среднего. Если влияние исследуемого фактора на отклик является малозначимым, то значение общего среднего будет близким к значениям среднего по уровням и сумме Q2 в целом не будет статистически значимой. Другими словами, если фактор слабо влияет на разброс отклика, то доминирующим будет влияние латентных факторов. Чтобы подтвердить или опровергнуть это, необходимо от сумм Q0, Q1 и Q2 перейти к оценкам соответствующих дисперсий, а затем воспользоваться теорией статистических гипотез о дисперсиях. Поэтому следующим этапом анализа является определение оценок общей дисперсии S0, внутриуровневой дисперсии S1 и межуровневой дисперсии S2, для чего необходимо суммы Q0, Q1 и Q2 разделить на соответстующие каждой из них число степеней свободы V0, V1 и V2:
V0 = mn-1
V1 =m(n-1)
V2 =m-1
Значения V0 и V2 очевидны, а при определении V1 исходят из предположения о равенстве внутриуровневых дисперсий, для оценок которых Sk число степеней свободы Vk=n-1. Тогда определения по уровням оценка S1 будет иметь V1=m(n-1). Предположение о равенстве внутриуровневых дисперсий нуждается в подтверждении на основе полученных опытных данных. Поскольку речь идет о нескольких (всего m) дисперсиях, то для такого подтверждения необходимо воспользоваться критериями Кохера, если nk=n k ∇k= 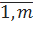 , или критерием Бартлетта в противном случае, где nk – число опытов на k-m уровне фактора.
, или критерием Бартлетта в противном случае, где nk – число опытов на k-m уровне фактора.
В итоге будут получены оценки дисперсий:
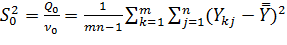 ;
;
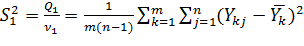 ;
;
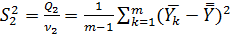 .
.
О значимости влияния фактора должна свидетельствовать значимость в различии оценок 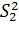 и
и 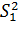 , что проверяется на основе гипотезы:
, что проверяется на основе гипотезы:
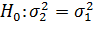
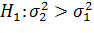
Для проверки используется критерий Фишера с числом степеней свободы 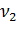 для числителя и
для числителя и 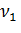 для знаменателя, т.к. обычно > .
для знаменателя, т.к. обычно > .
Если основная гипотеза противоречит опытным данным, то влияние фактора следует считать значимым.
В заключение отметим, что в случаях многофакторного дисперсного анализа сущность рассмотренных процедур сохраняется с той лишь разницей, что она распространяется на большее число сумм квадратов отклонений.
Корреляционный анализ
1). Назначение и сущность корреляционного анализа. Классификация по видам.
2). Однофакторный корреляционный анализ.
Назначение и сущность корреляционного анализа. Классификация по видам.
Корреляционным анализом называется совокупность методов статистической обработки результатов испытаний, зависящих от различных одновременно действующих факторов, с целью анализа и оценки существенности влияния данных факторов на отклик.
В отличие от дисперсионного анализа, при проведении которого любые факторы рассматриваются как качественные, в корреляционном анализе могут рассматриваться как качественные, так и количественные факторы, хотя предпочтение отдается последним.
Сущность корреляционного анализа заключается в установлении стохастической зависимости между откликом и факторами и в определении существенности влияния факторов на отклик, степени тесноты стохастической связи между ними. Смысл понятия «корреляционная зависимость» удобнее рассматривать для случая одномерных фактора и отклика, образующих систему случайных величин (X,Y).
Прежде всего, необходимо отметить, что корреляционная зависимость является разновидностью стохастической зависимости и уже по этой причине не является жесткой, функциональной. При изучении такой зависимости между компонентами системы (X,Y) возможны 2 различных подхода к формированию исходных предположений. Первый заключается в том, что определяемые значения переменной X задаются, т.е. не являются случайными. Тогда каждому фиксированному значению х соответствуют некоторые генеральные распределения Y/х с математическим ожиданием M[Y/x] и дисперсией D[Y/x], а наблюдаемые на опыте значения у рассматриваются как выборочные значения из этой генеральной совокупности. Зависимость M[Y/x] = φу(х) называется, как уже отмечалось, регрессией Y на Х.
Второй подход к формированию исходных предположений состоит в том, что реализации случайной переменной Х, т.е. значения х, не задаются, а генерируются датчиком нормально распределенных чисел. А так как одно из основных допущений корреляционного анализа, как и дисперсионного, заключается в предположении о том, что участвующие в анализе переменные распределены нормально, это следует признать, что в этом случае реализации Х и Y, наблюдаемые на опыте, будут представлять собою выборку из двумерного нормального распределения. При таком варианте исходных предположений компоненты системы (X,Y) становятся как бы полностью «равноправными». Вследствие чего необходимо вести речь о регрессии Y на Х, но и о регрессии Х на Y, т.е. о зависимости:
M [Х/у] = φх(у)
Поэтому приходим к выводу, что корреляционная зависимость, как разновидность стохастической, может быть представлена двумя уравнениями регрессии - φу(х) и φх(у).
Зависимости φу(х) и φх(у) могут быть как линейными, так и не линейными. Соответственно различают линейный и нелинейный корреляционный анализ. Обычно предполагается линейный характер этих регрессий. В этом предположении заключается второе из основных допущений корреляционного анализа (первое предполагает нормальность распределения компонент Х и Y). Оно гласит: регрессия имеет линейный или близкий к линейному характер.
Поэтому обычно полагают:
φу(х) = β0 + βх (12.1)
φх(у) = γ0 + γy
Такая связь или корреляция называется парной. Если с увеличением одной из компонент условное среднее другой также возрастает, то корреляция называется положительной, в противном случае – отрицательной.
Для определения коэффициентов в уравнениях (12.1) используются диаграммы или корреляционные поля. Каждая точка такого поля имеет координаты xi, yi, соответствующие значениям переменных в i-том опыте. Обработка опытных данных ведется методом наименьших квадратов. В итоге получают оценку b0 для β0, b для β и т.д.
Эта процедура называется параметризацией уравнений (12.1).
Определение характера зависимостей φу(х) и φх(у), т.е. установление формы стохастической связи между компонентами Х и Y, является одной из основных задач корреляционного анализа. Вторая основная задача заключается в определении существенности этой связи, т.е. существенности взаимовлияния компонент Х и Y. С решением этих задач связанны основные процедуры корреляционного анализа, рассмотренные в следующем параграфе.
В заключение отметим основные виды корреляционного анализа. Они различаются:
-по количеству факторов – однофакторный, многофакторный (множественный);
-по количеству откликов – одномерный, многомерный (векторный);
-по форме стохастической связи – линейный, нелинейный.
Однофакторный корреляционный анализ.
Основные этапы и соответствующие им процедуры корреляционного анализа рассмотрим на примере однофакторного одномерного анализа, позволяющего изучить взаимовлияние двух случайных компонент – фактора Х и отклика Y.
Первым этапом корреляционного анализа является установление наличия стохастической связи между компонентами Х и Y. Для этого используются рассмотренные ранее процедуры дисперсионного анализа. Если по итогам дисперсионного анализа делается вывод о наличии стохастической связи, то переходят ко второму этапу.
Вторым этапом является установление формы стохастической связи, т.е. решение вопроса о том, линейна она или нелинейна. Решение данной задачи может проводиться качественными и количественными методами.
Качественные методы опираются на анализ поля корреляции, а количественные – на методы построения кривой, наилучшим образом аппроксимирующей результаты наблюдений. В случае использования количественных методов выдвигается гипотеза о типе кривой, а затем осуществляется её параметризация, например, с помощью метода наименьших квадратов. В полном объеме эта процедура рассматривается на заключительных этапах регрессионного анализа.
Третьим, заключительным этапом корреляционного анализа является определение существенности стохастической связи между фактором и откликом.
Если стохастическая связь между переменными является линейной, то мерой этой связи служит парный коэффициент корреляции, определяемый выражением:
rхy =Кху/ϬхϬу =М[(X-mх)(Y-mу)] /ϬхϬу (12.2)
Если исследуемые переменные связаны функциональной зависимостью, то rхy=±1, а в случае их независимости rхy=0.
На практике используется оценка парного коэффициента корреляции, определяемая по опытным данным:
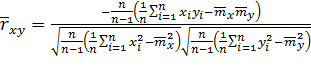 (12.3)
(12.3)
Значимость этой оценки проверяется на основе гипотез:
H0: rхy = 0
H1: rхy ≠ 0
В случае большой выборки оценка 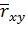 распределена по нормальному закону с параметрами:
распределена по нормальному закону с параметрами:
M [ ] = 0
D [ ] = (1- rхy2)2 /n
Поэтому основная гипотеза может быть проверена с использованием Z – статистики, при формировании которой следует использовать оценку дисперсии D [ ], т.е. 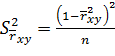
Если выборка не является большой, то используется статистика
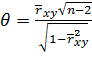 , (12.4)
, (12.4)
которая подчиняется t – распределению с числом степеней свободы υ = n-2.
В случае отклонения основной гипотезы выборочный коэффициент корреляции признается значимым с выбранным уровнем значимости. Он характеризует степень приближения стохастической зависимости между переменными к линейной. Для количественной оценки нелинейности используется так называемый коэффициент детерминации ɳху, который определяется как rхy2. Этот коэффициент позволяет ответить на вопрос о том, каково качество описания зависимости с помощью уравнения регрессии. Очевидно, чем теснее наблюдения примыкают к линии регрессии, тем лучше она описывает соответствующую зависимость переменных и с большей надежностью может быть применена для оценивания значений отклика по заданным значениям фактора.
Можно показать, что rхy2 равен отношению межуровневой дисперсии к общей дисперсии отклика, откуда следует, что коэффициент детерминации характеризует долю так называемой объясненной регрессией дисперсии в общей величине дисперсии. Чем теснее наблюдения примыкают к линии регрессии, тем эта доля выше. Например, если rхy =0,9, то ɳху = rхy2 = 0,81. Это значит, что 81% общей дисперсии (общей для среднего значения отклика) определяется уравнением регрессии, т.е. корреляционная связь между откликом и фактором вполне удовлетворительно может быть представлена линейным уравнением, т.к. доля нелинейности сравнительно невелика.
Проверкой значимости оценки rхy завершаются основные процедуры корреляционного анализа.
Лекция 7. Регрессионный анализ и планирование эксперимента.
1). Назначение и сущность регрессионного анализа. Классификация по видам.
2). Планирование эксперимента. Как метод реализации процедуры РА. Критерии оптимальности планов.
Назначение и сущность регрессионного анализа. Классификация по видам.
Регрессионным анализом называется один из видов статистического анализа, представляющий собою совокупность методов обработки результатов испытаний, зависящих от различных одновременно действующих случайных факторов различной природы, с целью построения уравнения регрессии в интересах исследования стохастической взаимосвязи между откликом и факторами.
Таким образом, исходная предпосылка заключается в том, что между случайным откликом Y и случайным вектором факторов X существует стохастическая зависимость вида 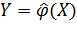 , где
, где 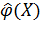 в общем случае может быть как случайной, так и неслучайной функцией случайных аргументов, вид которой неизвестен. Если бы была известна зависимость закона распределения Y от вектора X, то она позволила бы провести всесторонний анализ стохастической взаимосвязи Y и X. Такой путь решения задачи в принципе возможен, но как свидетельствует опыт исследований, не всегда целесообразен. В практике испытаний гораздо чаще используется другой вариант решения, идея которого заключается в том, чтобы установить зависимость какой-либо числовой характеристики Y от возможных значений компонент вектора X в виде неслучайной функции неслучайных аргументов. В регрессионном анализе в качестве такой числовой характеристики используется условное математическое ожидание отклика Y, определяемое при условии, что компоненты вектора X приняли определенные значения:
в общем случае может быть как случайной, так и неслучайной функцией случайных аргументов, вид которой неизвестен. Если бы была известна зависимость закона распределения Y от вектора X, то она позволила бы провести всесторонний анализ стохастической взаимосвязи Y и X. Такой путь решения задачи в принципе возможен, но как свидетельствует опыт исследований, не всегда целесообразен. В практике испытаний гораздо чаще используется другой вариант решения, идея которого заключается в том, чтобы установить зависимость какой-либо числовой характеристики Y от возможных значений компонент вектора X в виде неслучайной функции неслучайных аргументов. В регрессионном анализе в качестве такой числовой характеристики используется условное математическое ожидание отклика Y, определяемое при условии, что компоненты вектора X приняли определенные значения: 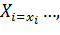
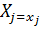 ….,
…., 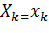 ….
….
Следовательно, в РА используется зависимость вида:
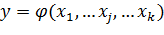 (13.1)
(13.1)
где: 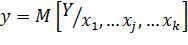 ,
,
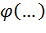 - неслучайная функция неслучайных аргументов.
- неслучайная функция неслучайных аргументов.
Эта зависимость предназначена для того, чтобы приближенно представлять истинную стохастическую взаимосвязь между откликом и факторами, т.е. она является регрессией отклика на факторы.
Таким образом, в представлении соотношения в виде (13.1) заключается сущность РА, а в построении зависимости (13.1) по результатам испытаний – его цель.
Различают однофакторный и многофакторный, одномерный и многомерный РА, а по виду зависимости – линейный и нелинейный.
В линейном РА зависимость (1) представляют в виде полинома:
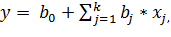
где 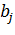 - оценка коэффициентов регрессии
- оценка коэффициентов регрессии 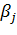 (
( 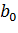 – оценка для
– оценка для 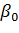 ).
).
В нелинейном РА зависимость (13.1) обычно включает члены, представляющие так называемые эффекты взаимодействия и степенные эффекты, т.е. члены вида
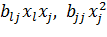 и т.д.
и т.д.
Активный и пассивный эксперимент.
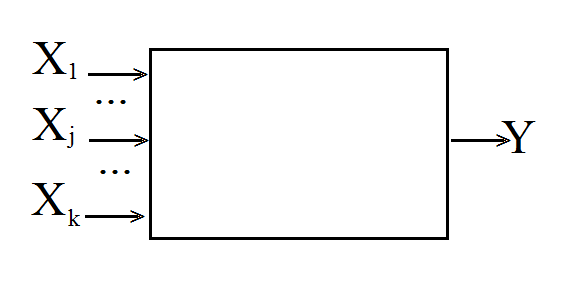
Исходные понятия ТПЭ: фактор, отклик, план эксперимента.
Отклик Y – однокомпонентный вектор. Фактор X – многокомпонентный вектор столбец вида:
X= 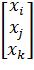 , j=1, , j=1, 
| 
|
В каждом опыте участвуют все факторы, так что в i-м опыте имеем:
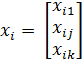 ;
; 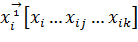
Всего опытов N, т.е. i = 1, 
Матрицей спектра плана эксперимента называется матрицы вида:
X = 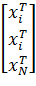 =
= 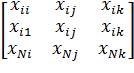
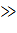 N точек с координатами (
N точек с координатами ( 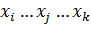 )
)
Совокупность всех точек в пространстве k факторов, отличающихся уровнями хотя бы одного фактора, называется спектром плана эксперимента.
Опыт в i-х условиях может повторяться n раз, что можно представить матрицей дублирования опытов e:
e = 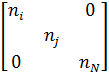
Матрица спектра совместно с матрицей e дает план эксперимента, совокупность данных, определяющих число, условия и порядок реализации опытов.
ПЭ:
точный, если 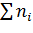 задана;
задана;
насыщенный, если N=k (без учёта 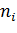 )
)
регулярный, если 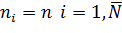
Разработка плана эксперимента (ПЭ):
Определение пространства факторов
Выбор стратегии испытания
Полный факторный эксперимент
1. Принятие решений перед планированием эксперимента.
2. Полный факторный эксперимент типа. Его свойства и математическая модель.
Принятие решений перед планированием эксперимента.
Исследование на основе теории планирования эксперимента предполагает использование как формальных, так и не формальных процедур. Последние требуют «Интуитивных решений». Перед планированием эксперимента такие решения должны быть приняты по трем вопросам:
Выбор экспериментальной области факторного пространства, выбор основного уровня факторов и выбор интервала варьирования факторов. При этом предполагается, что сама совокупность исследуемых факторов уже сформирована и цель исследования определена.
Выбор экспериментальной области: (области определения факторного пространства) прежде всего, означает оценку границ областей определения факторов, т.е. возможных диапазонов изменения каждого из выбранных факторов. При этом обычно учитываются ограничения трех типов.
Первый тип- принципиальные ограничения, которые не могут быть нарушены ни при каких обстоятельствах. Например, если фактор температура, то нижним пределом будет абсолютный нуль.
Второй тип- ограничения, связанные с технико-экономическими соображениями: стоимостью сырья, дефицитностью отдельных компонентов, времени ведения процесса.
Третий тип ограничений, с которыми чаще всего приходится иметь дело, определяется конкретными условиями эксперимента: существующей аппаратурой, технологией, организацией.
На данном этапе рекомендуется тщательный анализ и активное использование всей имеющейся априорной информации о каждом из выбранных факторов.
Выбор основного уровня:Основным (нулевым) уровнем называется такое значение фактора, относительно которого осуществляется варьирование данным фактором в ходе эксперимента.
Выбор основного уровня зависит от цели исследования. Если цель исследования заключается в характере влияния факторов на отклик, то в качестве основного уровня следует выбирать середину диапазона возможных значений каждого фактора:
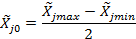
где 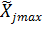 - натуральное значение верхней границы диапазона изменения j-го фактора ;
- натуральное значение верхней границы диапазона изменения j-го фактора ;
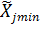 - натуральное значение нижней границы диапазона изменения j-го фактора;
- натуральное значение нижней границы диапазона изменения j-го фактора;
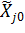 - натуральное значение основного (нулевого) уровня j-го фактора.
- натуральное значение основного (нулевого) уровня j-го фактора.
В тех случаях, когда целью эксперимента является поиск оптимальных условий, т.е. условий, при которых отклик достигает оптимального значения, в качестве основного уровня для каждого из факторов выбирают координаты так называемой наилучшей точки:
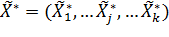
Это такая точка в k-мерном фактором пространстве, в которой получено наилучшее значение отклика. Если такая точка известна из анализа априорной информации, то полагают:
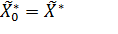 т.е.
т.е. 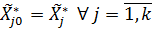
Если априорные значения координат наилучшей точки неизвестны, то рекомендуется случайным образом выбрать несколько (минимум две) точек в факторном пространстве, поставить в них предварительные опыты и на этой основе определить лучшую из них. Найденная точка называется центром плана.
Выбор интервалов варьированияфакторов заключается в том, чтобы для каждого фактора выбрать два уровня, на которых он будет варьироваться в эксперименте. В общем случае уровней может быть больше двух. Мы ограничимся двумя.
Представим себе координатную ось, на которой откладываются натуральные значения j-го фактора:
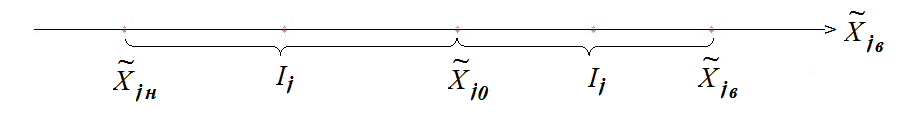
|
После выбора основного уровня нам известна точка 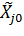 . тогда два интересующих нас уровня можно изобразить двумя точками
. тогда два интересующих нас уровня можно изобразить двумя точками 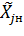 (нижний уровень) и
(нижний уровень) и 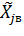 (верхний уровень) симметричными относительно основного уровня. Обычно за верхний уровень принимается тот, который соответствует большему значению фактора, хотя это и не обязательно.
(верхний уровень) симметричными относительно основного уровня. Обычно за верхний уровень принимается тот, который соответствует большему значению фактора, хотя это и не обязательно.
Интервалом варьирования факторов называется число, свое для каждого фактора, прибавление которого к основному уровню дает верхний, а вычитание - нижний уровни фактора. Обозначается интервал выравнивания через 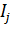 .
.
Для упрощения записи условий эксперимента масштабы по осям выбирают так, чтобы верхний уровень соответствовал «+1», нижний «-1», а основной-нулю. Для факторов с непрерывной областью определения это всегда можно сделать с помощью процедуры кодирования факторов:
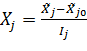
Где 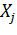 -кодированное значение j-го фактора;
-кодированное значение j-го фактора;
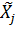 - натуральное значение j-го фактора.
- натуральное значение j-го фактора.
Для 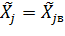 получим:
получим: 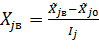
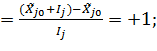
Для 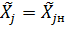 = получим:
= получим: 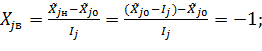
Для 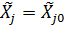 = получим:
= получим: 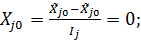
Тогда координатная ось преобразуется к виду:
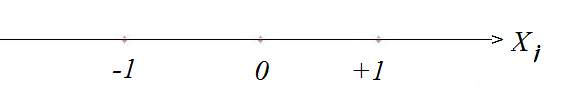
На интервалы варьирования факторов накладываются ограничения сверху и снизу. Интервал не может быть меньше той ошибки, с которой фиксируется уровень фактора (иначе верхний и нижний уровни окажутся неразличимыми). С другой стороны, интервал не может быть настолько большим, чтобы верхний или нижний уровни оказались за пределами области определения факторов. Этот перечень ограничений является исчерпывающим для задач первого типа, т.к. в этих задачах 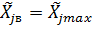 и
и 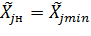 . Что же касается задач оптимизации отклика, то для них такие соотношения в общем случае не выполняются, в силу чего внутри вышеуказанных ограничений еще остается значительная неопределенность, которая устраняется обычно с помощью интуитивных решений. Существенную помощь в принятии таких решений призваны оказать сведения о точности, с которой фиксируются факторы, о кривизне поверхности отклика и о диапазоне изменения отклика. Таким же образом, на всех этапах принятия решений перед планированием эксперимента важную роль играет анализ априорной информации.
. Что же касается задач оптимизации отклика, то для них такие соотношения в общем случае не выполняются, в силу чего внутри вышеуказанных ограничений еще остается значительная неопределенность, которая устраняется обычно с помощью интуитивных решений. Существенную помощь в принятии таких решений призваны оказать сведения о точности, с которой фиксируются факторы, о кривизне поверхности отклика и о диапазоне изменения отклика. Таким же образом, на всех этапах принятия решений перед планированием эксперимента важную роль играет анализ априорной информации.
Когда экспериментальная область факторного пространства определена, основные уровни и интервалы варьирования факторов выбраны можно приступать к планированию эксперимента.
Полный факторный эксперимент типа 2к
Его свойства и математическая модель
Планирование эксперимента заключается в построении матриц Х и ε. Матрица спектра Х, как было установлено, содержит набор возможных сочетаний уровней факторов. Если этот набор является полным (исчерпывающим), то число таких сочетаний равно 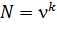 .
.
Эксперимент, в котором реализуются все возможные сочетания уровней факторов, называется полным факторным экспериментом (ПФЭ).
Если в эксперименте участвуют k факторов и каждый из них варьируется на двух уровнях, то имеет ПФЭ типа 2k. Матрица спектра при этом содержит N=2k строк, каждая из которых представляет один из N возможных вариантов сочетаний уровней факторов. Следовательно, для реализации всех вариантов потребуется N опытов. Например для k=2 матрица спектра имеет вид, представленный в таблице 14.1.
Таблица14.1
Матрица спектра плана ПФЭ
| Номер опыта/факторы | Х1 | Х2 |
| - | - | |
| + | - | |
| - | + | |
| + | + |
В таблице приняты обычные обозначения, когда «+» означает «+1» (верхний уровень фактора), а «-» означает «-1» (нижний уровень фактора). Для реализации такого плана потребуется всего N=22 =4 опыта, т.к. полный набор возможных сочетаний уровней двух факторов при n=2 равен четырем. Как видно каждая строка матрицы спектра определяет условия опыта: в первом опыте оба фактора находятся на нижнем уровне, в последнем- на верхнем, а во втором и третьем опытах имеют место смешанные сочетания уровней.
Матрица спектра превращается в матрицу плана, если к ней добавить столбец повторных опытов в каждой строке и столбец для значений отклика. Такая матрица представлена в таблице 14.2.
Таблица 14.2
| Номер опыта\факторы | Х1 | Х2 | Число повторных опытов | Значения отклика |
| - | - | n1 | 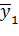
| |
| + | - | n2 | 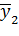
| |
| - | + | n3 | 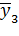
| |
| + | + | n4 | 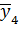
|
Обратимcя вновь к матрице спектра, чтобы уяснить правила ее формирования. Для плана 22 не составляет труда установить все возможные комбинации уровней факторов прямым перебором этих комбинаций или их простым запоминанием. С ростом числа факторов возникает потребность в использовании определенных правил. Отметим основные из них:
Правило первое: при добавлении нового фактора каждая комбинация уровней исходного плана выбирается дважды- в сочетании с нижним и верхним уровнями нового фактора.
Правило второе: использует перемножение столбцов матрицы. При построчном перемножении двух столбцов произведение единиц с одноименными знаками дает «+1», а с разным – «-1».
При использовании этого правила сначала надо записать исходный план, определить для него знаки произведения Х1Х2, а затем повторить исходный план, поменяв у столбца произведений знаки на обратные.
Правило третье:основано на чередовании знаков: в первом столбце знаки меняются поочередно, во втором они чередуются через два, в третьем- через четыре, в четвертом -через восемь и т.д. по степени двойки, начиная с нуля.
Рассмотрим свойства ПФЭ типа 2k.Они определяются свойствами матрицы спектра. Любая матрица спектра плана ПФЭ типа обладает четырьмя основными свойствами: симметричностью относительно центра плана, выполнением условия нормировки, ортогональностью столбцов и рототабельностью.
Симметричность матрицы спектра означает, что алгебраическая сумма элементов вектор- столбца каждого фактора равна нулю:
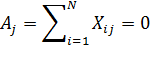
Условие нормировки:
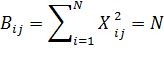
Свойство ортогональности: сумма почленных произведений любых двух векторов- столбцов матрицы спектра равна нулю:
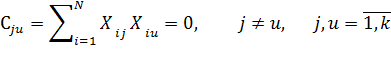
Свойство рототабельности означает одну и ту же точность предсказания отклика в задачах первого типа на равных расстояниях от центра плана.
Перечисленные свойства обеспечивают получение качественной математической модели.
ПФЭ типа 2k позволяет формировать математические модели различной степени сложности. Простейшей из них является линейная модель вида:
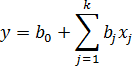
где -среднее значение отклика в центре плана (оценка),
- коэффициенты р
Дата добавления: 2022-05-27; просмотров: 278;
Поиск по сайту

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
