Раздел 3. Дисперсионный, корреляционный и регрессионный анализ результатов испытаний
Лекция 5. Основные понятия статистического анализа. Задачи и виды статистического анализа.
1). Предмет и общая задача статистического анализа.
2). Формы взаимосвязи между переменными в задачах СА. Сущность понятия стохастической зависимости.
3). Частные задачи, виды и основные этапы статистического анализа.
Предмет и общая задача статистического анализа.
Определение вероятностных характеристик случайных величин и процессов по опытным данным и формирование на этой основе соответствующих выводов- предмет теории статистических решений.
Установление причинно-следственных механизмов взаимосвязи между случайными величинами, определяющими состояние и развитие испытываемого объекта или изучаемого явления- предмет статистического анализа (СА).
Задачи СА подразделяются на общую и частные. Рассмотрим суть общей задачи. Ее формулировка предполагает рассмотрение объекта испытаний совместно с характеризующими его переменными величинами. Последние подразделяются на входные и выходные (результирующие). Входные переменные представляют собой характеристики воздействующих на объекты факторов. Поэтому для краткости они именуются просто факторами и обозначаются через Х. Различают управляемые и латентные факторы. Первые представляют собой контролируемые исследователем характеристики, уровни которых он может задавать (фиксировать) с требуемой точностью. Латентные это скрытые, не поддающиеся учету и измерению факторы, в том числе ошибки измерения управляемых факторов. В математических моделях их для краткости именуют остатками и обозначают через Е.
Выходные переменные представляют собой результат преобразования объектом входных переменных, в следствии чего они называются откликами. Отклики принято обозначать через Y.
В общем случае факторы Х и отклики Y суть многокомпонентные случайные векторы, образующие систему (Х, У):
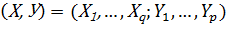 (10.1)
(10.1)
Система (10.1) полностью характеризует объект с точки зрения типовых задач статистического анализа.
По результатам испытаний объекта формируется выборка объемом n, представляющая собой совокупность n опытных значений системы (10.1):
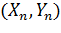 (10.2)
(10.2)
Общая задача СА заключается в том, чтобы на основе опытных данных, представленных выборкой (10.2), сформировать некий оператор A(X,E), связывающий вектор Y с вектором Х и позволяющий наилучшим, в определенном смысле, образом прогнозировать отклик объекта на заданные воздействия (факторы), т.е. получить:
Y=A(X, E) (10.3)
Выражение (10.3) следует рассматривать не как строгое математическое соотношение, а как чисто формальную запись (знаковое представление) тезиса о наличии связи между откликом и факторами. Вопрос о том, в какой форме может проявиться эта связь, рассмотрим ниже. В случае ее конкретизации выражение (10.3) превращается в математическую модель объекта. Поэтому общая задача СА есть не что иное, как задача идентификации объекта по результатам испытаний.
Формы взаимосвязи между переменными в задачах СА. Сущность понятия стохастической зависимости.
В общем случае связь между откликами и факторами может проявиться в одной из форм, представленных в табл. 10.1.
Из табл. 10.1 видно, что результат (отклик) всегда случаен. Но причины этой случайности различны для различных форм зависимости.
Таблица 10.1.
Формы связи между откликом и факторами
| Отклик | Факторы | Зависимость | Форма записи | Предмет теории… |
| Y | x | Функциональная | Y=ϕ(x)+E | Статистических решений |
| Y | X | функциональная | Y=ϕ(Х) | Статистических решений |
| Y | x | Стохастическая | Y=  (x) (x)
| Регрессионного анализа |
| y | X | Полная стохастическая | Y= (Х)
| Корреляционного анализа |
Обозначения принятые в табл. 10.1:
х- неслучайный вектор факторов,
Х- случайный вектор факторов,
ϕ(x)- неслучайная функция неслучайных аргументов,
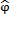 (x)- условное обозначение стохастической зависимости между Х и Y,
(x)- условное обозначение стохастической зависимости между Х и Y,
(Х)- условное обозначение полной стохастической зависимости между Х и Y.
В случаях функциональной зависимости такими причинами являются либо латентные факторы, либо случайный характер факторов. Оценка результатов испытаний в этих случаях базируется на положениях теории статистических решений и выливается в конечном итоге либо в одно из решений на множестве D, либо в принятие (отклонение) статистической гипотезы, либо в точечную или интервальную оценку исследуемого параметра объекта. В любом из этих случаев нет надобности строить математическую модель объекта, т.к. вид функции ϕ известен заранее. Если же это не так (задачи прогностики), то вид функции ϕ постулируется, а входящие в нее параметры определяются на основе опытных данных методом наименьших квадратов (МНК).
Что же касается случаев стохастической зависимости, то они предполагают построение моделей типа ϕ(x) в качестве самостоятельной задачи оценки результатов испытаний. В связи с этим остановимся подробнее на понятии стохастической зависимости.
Понятие зависимость между компонентами системы случайных величин (X, Y) удобно установить по аналогии с понятием зависимости между событиями А и В, если под событием А понимать выполнение неравенства Х<x, а под событием В- выполнение неравенства Y<y. Тогда величины X и Y независимы, если вероятность совместного наступления этих двух событий для любых x и y равна произведению вероятностей проявления каждого из них, т.е.
P(AB)=P((Х<x)( Y<y))= P(Х<x)P( Y<y)=P(A)P(B)
Заменив вероятности функциями распределения, получим определение независимости в виде равенства:
F(x,y)=F(x)F(y) (10.4)
Если функцию распределения F(x,y) невозможно представить в виде (10.4), то величины X и Y зависимы.
Для непрерывных случайных величин условие (10.4) можно выразить через дифференциальную функцию распределения:
f(x,y)=f(x)f(y) (10.5)
Условия зависимости между X и Y выражается через плотности условных распределений f(y/x) или f(x/y), под которыми подразумевают плотность одной случайной величины при конкретном значении другой, т.е. f(y/x) представляет функцию плотности распределения величины Y, полученную при условии, что случайная величина Х приняла значение х.
Для зависимых случайных величин справедливо соотношение:
f(x,y)= 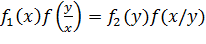 , (10.6)
, (10.6)
где 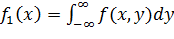 и
и 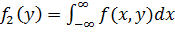 (10.7)
(10.7)
Зависимости (10.7) определяют плотности так называемых маргинальных (предельных) распределений. Используя их можно найти плотности условных распределений:
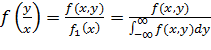 (10.8)
(10.8)
Таким образом, стохастической (вероятностной) зависимостью двух случайных величин называется зависимость плотности условного распределения одной из них от значений, принимаемых другой.
Стохастическая зависимость в некотором смысле обобщает понятие функциональной связи между величинами. Так, если выражение y= ϕ(x) означает, что каждому значению х соответствует определенное значение у, то при стохастической зависимости между Х и Y каждому значению Х=х соответствует множество значений, которое может принимать случайная величина Y/x. Это множество как раз и характеризуется плотностью условного распределения f(y/x).
Следовательно, стохастическая зависимость отражает или представляет нежесткость соотношений (связей) между случайными величинами, их множественность, как это показано на рисунке.
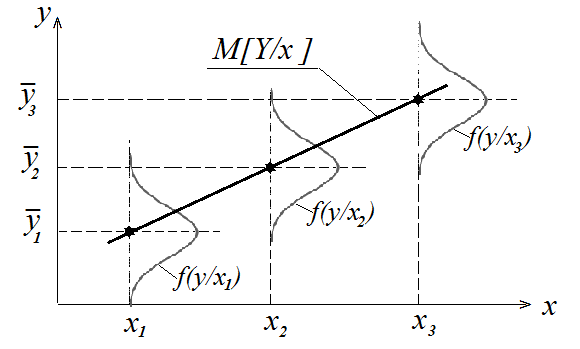
Как видно из рисунка, математическое ожидание случайной величины Y/x представляет собой некоторую функцию ϕ(x).
В рассмотренном на рисунке примере это линейная функция.
Зависимость M[Y/x]= ϕ(x) называется регрессией (уравнением регрессии) Y на Х. В общем случае для системы (Х,Y) регрессией Y на Х называется любая функция g(x), приближенно представляющая стохастическую зависимость Y=  (x).
(x).
Частные задачи, виды и основные этапы статистического анализа.
Различают три типа частных задач статистического анализа.
Задачи первого типа представляют установление самого факта наличия или отсутствия стохастической зависимости между переменными. Ответ в таких задачах носит альтернативный характер: стохастическая зависимость есть (значима) или ее нет (незначима). Обычно решение основывается на количественном показателе (измерителе) степени взаимозависимости между переменными. Выбор конкретного вида математической модели играет при этом подчиненную роль и нацелен исключительно на максимизацию величины этого показателя.
Задачи второго типа предполагают прогнозирование отклика по заданным значениям факторов. При этом выбор функции ϕ(x) также играет подчиненную, хотя и более значимую роль и нацелен на минимизацию ошибки прогноза. Интерес представляют лишь значения функции ϕ(x), но не ее структура.
Задачи третьего типа нацелены на выявление причинных связей между переменными, а также на управление откликом путем регулирования факторов. Эти задачи претендуют на проникновение в физику процесса, т.е. в механизм преобразования факторов в отклик. Поэтому структура зависимости ϕ(x) играет в таких задачах решающую роль.
Различные типы частных задач являются предметом различных видом статистического анализа, как показано в таблице 2.
Таблица 2.
Типы частных задач и виды СА
| Тип задачи | Факторы | Отклик | Вид СА |
| Количественные | Количественный | Дисперсионный анализ Корреляционный анализ | |
| Качественные | Количественный | Дисперсионный анализ | |
| 2,3 | Количественные | Количественный | Регрессионный анализ |
| Количественные | Качественный | Кластерный анализ | |
| Смешанные | Количественный | Факторный анализ | |
| Качественные | Качественный | Анализ ранговых корреляций |
Основными видами СА являются дисперсионный, корреляционный и регрессионный анализы.
Процесс статистического анализа в общем случае можно представить семью этапами в соответствии с хронологией их реализации.
Первый этап постановочный. Определяются объект исследования, входные и выходные переменные, цель статистических исследований.
Второй этап информационный. Формируется выборка (Xn, Yn).
Третий этап- корреляционный анализ компонент системы (X, Y).
Четвертый этап- выбор математической модели ϕ(x).
Пятый этап-анализ коррелированных факторов.
Шестой этап-параметризация математической модели.
Седьмой этап- оценка качества математической модели: оценка значимости параметров модели и оценка адекватности модели.
Этапы 4…7 являются этапами регрессионного анализа.
Дата добавления: 2022-05-27; просмотров: 226;
Поиск по сайту

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
