ЯЗЫКИ И ГРАММАТИКИ. ОБОЗНАЧЕНИЯ, ОПРЕДЕЛЕНИЯ
И КЛАССИФИКАЦИЯ
Вначале дадим ряд определений.
Алфавит - это непустое конечное множество элементов. Элементы алфавита называются символами
Всякая конечная последовательность символов алфавита называется цепочкой. Так a, b, c, ab, aaca - цепочки в алфавите A = {a,b,c}.
Допустим существование пустой цепочкиe, не содержащей ни одного символа.
Важен порядок символов в цепочке. Цепочка ab отличается от ba.
Длина цепочки ½a½равна количеству символов в цепочке. Так ½a½=1, ½abc½=3, ½ e ½=0.
Если a иb - цепочки, то их конкатенациейab является цепочка, полученная путем дописывания символов цепочки b вслед за символами цепочки a . Например, если a=ab, b=bc, то ab= abbc и ba= bcab. Поскольку e - цепочка,не содержащая символов, то в соответствии с правилами конкатенации для любой цепочки a можно записать
ea=ae=a.
Обращением цепочки a (обозначается a R ) называется цепочка a, записанная в обратном порядке, т.е. если a = a1...an, где все ai- символы, то aR= an... a1. Кроме того, e R=e .
Если g = ab - цепочка, то a - голова(префикс), а b - хвост(суффикс) цепочки g. При этом, a - правильная голова, если b- не пустая цепочка (b ¹ e), b - правильный хвост, если a ¹ e. Таким образом, если a = abc, то e , a, abи abc - головы a, и все они, кроме abc, - правильные головы.
Иногда удобнее и нагляднее писать
a ...вместо ab,
если нас не интересует b- остальная часть цепочки. Три точки "..." будут обозначать любую возможную цепочку, включая пустую.
Языком Lв алфавите A называется множество цепочек в A.
Это определение подходит почти для любого языка. Языки Паскаль, С, Модула-2, английский и русский охватываются этим понятием.
Рассмотрим простые примеры языков в алфавите A.
Пустое множество Æ - это язык. Множество {e },содержащее только пустую цепочку, также является языком.
Заметим, что Æи { e } - это два разных языка.
Обозначим через A* множество, содержащее все цепочки в алфавите A, включая e.
Например, если A бинарный алфавит {0,1}, то
A* = { e , 0, 1, 00, 01, 10, 11, 000, 001, 010, 011, 100, 101, 110, ...}.
Каждый язык в алфавите A является подмножеством множества A*. Множество всех цепочек в A, за исключением e, обозначим A +, то есть A*= A+È e.
Формально цепочку в алфавите A можно определить следующим образом:
1). e - цепочка в A,
2). если a цепочка в A и aÎ A, то aa - цепочка в A (aa Î A*),
3). b - цепочка в A, тогда и только тогда, когда она является таковой в силу 1) или 2).
Цепочку, состоящую из i символов a будем обозначать a i, то есть a0=e, a1= a, a2= aa, a3= aaa и т.д.
Итак, язык L - это некоторое множество цепочек в некотором алфавите A. Как описать этот язык. Если L состоит из конечного числа цепочек, то самый очевидный способ состоит в составлении списка всех цепочек этого языка. Однако для большинства языков нельзя или нежелательно устанавливать верхнюю границу длины самой длинной цепочки. Следовательно, приходится рассматривать язык, содержащий сколь угодно много цепочек. Очевидно, их нельзя описать перечислением цепочек. Мы хотим, чтобы описание языка было конечным (имело конечный объем), хотя сам язык может быть и бесконечным. Известно несколько методов такого описания. Один из основных состоит в использовании порождающей системы, называемой грамматикой.
В грамматике, определяющей язык L, используется два конечных непересекающихся множества: множества терминальных символов (терминалов) S имножества нетерминалов N. Из терминалов образуются слова (цепочки) языка L, а нетерминалы - суть синтаксические понятия(синтаксические единицы) языка, служащие для порождения (вывода) слов языка L. Сердцевину же грамматики составляет конечное множество продукций образования (правилвывода) R, которые описывают процесс порождения цепочек языка. Правило - это просто пара цепочек, а точнее элемент декартового произведения:
(N È S)* N (N È S)* ´ (N È S)*.
Иначе говоря, первым компонентом правила служит любая цепочка, содержащая хотя бы один нетерминал, а вторая - любая цепочка из терминалов и нетерминалов, включая e . Правила обычно записывают в виде
a ® b
или
a ::=b
что означает a порождает (состоит из)b.
Язык, порождаемый грамматикой,- это множество цепочек, которые состоят только из терминалов и выводятся, начиная с одного, особо выделенного, нетерминала S, называемого начальным символомили аксиомой грамматики. Среди множества правил грамматики R должно присутствовать хотя бы одно правило
S ® b
где SÎ N - начальный символ, аbÎ (N È S)* - любая цепочка.
В последующем, если не оговорено дополнительно, используем следующие обозначения. Грамматику языка обозначим через G, возможно с индексом, илиG(S). Язык L, определяемый грамматикой G, обозначимL(G). Терминальные символы обозначим малыми буквами, а нетерминалы - прописными, или в виде текста в угловых скобках, например, <нетерминал>. Цепочки будем обозначать греческими буквами. Если в грамматике встречаются правила с одинаковыми левыми частями
a ::=b1
a ::=b2
..........
a ::=bn,
то будем писать
a ::=b1½b2½ ... ½bn
в виде одного правила, имеющего ряд альтернатив в правой части.
Рассмотрим ряд грамматик и обсудим алгоритм порождения, применяемый для вывода цепочек языка.
Пример 1.1.
<предложение>::=<подлежащее><группа сказуемого>
<подлежащее>::=мать½отец
<группа сказуемого>::=<сказуемое><дополнение>
<сказуемое>::=любит½обожает½боготворит
<дополнение>::=сына½дочь ™
Если имеется множество правил, то ими можно воспользоваться для того, чтобы вывести или породить цепочку (предложение) по следующей схеме. Начнем с начального символа грамматики - <предложение>, найдем правило, в котором <предложение> слева от ::= , и подставим вместо <предложение> цепочку, которая расположена справа от ::=, т.е.
<предложение> Þ <подлежащее> <группа сказуемого>
Таким образом, мы заменяем синтаксическое понятие на одну из цепочек, из которых оно может состоять. Повторим процесс. Возьмем один из нетерминалов в цепочке <подлежащее> <группа сказуемого>, например <подлежащее>; найдем правило, где <подлежащее> находится слева от ::=, и заменим <подлежащее> в исходной цепочке на соответствующую цепочку, которая находится справа от ::=. Это дает
<подлежащее> < группа сказуемого > Þ мать < группа сказуемого >
Символ "Þ" означает, что один символ слева от Þ в соответствии с правилом грамматики заменяется цепочкой, находящейся справа от Þ. Полный вывод одного предложения будет таким:
<предложение> Þ <подлежащее> <группа сказуемого>
Þ мать < группа сказуемого >
Þ мать <сказуемое> <дополнение>
Þ мать любит <дополнение>
Þ мать любит сына
Этот вывод предложения запишем сокращенно, используя новый символ Þ+
<предложение> Þ+ мать любит сына
На каждом шаге можно заменить любой нетерминал. В приведенном выше выводе всегда заменялся самый левый из них.
Вывод, на каждом шаге которого заменяется самый левый нетерминал сентенциальной формы называется левым (левосторонним) выводом. Существует и часто используется также правый (правосторонний) вывод, который получается, если в сентенциальной форме заменять всегда самый правый нетерминал.
Обратите внимание на то, что предложенная грамматика используется для описания многих предложений. Девять правил грамматики, если считать каждую альтернативу за отдельное правило, а так оно и есть, определяют двенадцать предложений (цепочек) языка:
мать любит сына мать обожает сына мать боготворит сына
мать любит дочь мать обожает дочь мать боготворит дочь
отец любит сына отец обожает сына отец боготворит сына
отец любит дочь отец обожает дочь отец боготворит дочь
Одно из назначений грамматики как раз и состоит в том, чтобы описывать все цепочки языка с помощью приемлемого числа правил. Это особенно важно, если учесть, что количество предложений в языке, чаще всего, бесконечно.
Рассмотрим еще один пример полезной грамматики
Пример 1.2.Грамматики целого числа без знака содержат следующие 13 правил
(1) <число>::=<чс> S ® A
(2) <чс>::=<цифра><чс> A ® AB
(3) <чс>::=<цифра> A ® B
(4) <цифра>::=0 B ® 0
(5) <цифра>::=1 B ® 1
(6) <цифра>::=2 B ® 2
(7) <цифра>::=3 B ® 3
(8) <цифра>::=4 B ® 4
(9) <цифра>::=5 B ® 5
(10) <цифра>::=6 B ® 6
(11) <цифра>::=7 B ® 7
(12) <цифра>::=8 B ® 8
(13) <цифра>::=9 B ® 9
Заметим, что грамматики G(<число>) и G(S) определяют один и тот же язык и отличаются только именами нетерминалов и вторым правилом.
А теперь продолжим наши определения.
Пусть G - грамматика. Будем говорить, что цепочка a непосредственно порождает цепочку b, и обозначим
a Þ b,
если для некоторых цепочекj и y можно написать
a = jUy
b = jgy
где
U::= g
правило грамматики G. Будем также говорить, что b непосредственно выводима из a или что b непосредственно приводится (редуцируется, сворачивается) к a .
Цепочки j и y, конечно, могут быть пустыми. Следовательно, для любого правила A®aграмматики G имеет место A Þ a . На рис. 1.1 даны некоторые примеры непосредственных выводов для грамматики G(<число>) из примера 1.2 и обозначений предыдущего определения.
Будем говорить, что a порождает b или b приводится к a и записывать a Þ+ b, если существует последовательность непосредственных выводов
a = g0 Þ g1 Þ g2 Þ ... Þ gn = b,
где n>0. Эта последовательность называется выводом длины n. Будем писать a Þ* b, если a Þ+ b или a = b.
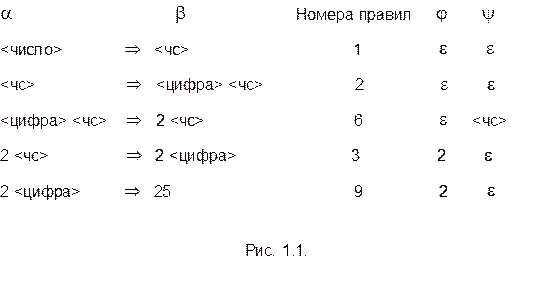
Если просмотреть все строки рис 1.1 то мы получим
<число> Þ <чс> Þ <цифра> <чс> Þ 2 <чс> Þ 2 <цифра> Þ 25
Таким образом, <число> Þ+ 22 и длина вывода равна 5. (Если длина вывода известна можно записывать в явном виде <число> Þ 5 22 )
Заметим, что пока в цепочке есть хотя бы один нетерминал, из нее можно вывести новую цепочку, Однако если нетерминальные символы отсутствуют, то вывод завершен. Неслучайно "терминалом" (terminal - заключительный, конечный) называют символ, который не встречается в левой части ни одного из правил.
Попробуем еще раз определить язык.
Пусть G(S) = {N,S,R,S} - грамматика. Цепочка a называется сентенциальной формой, если a выводима из начального символа S, т.е. если
SÞ *a.
Цепочка языка - это сентенциальная форма, состоящая только из терминалов.
Язык L(G(S)) - это множество цепочек:
L(G)={ a çSÞ *a и aÎS*}
т.е. язык - это подмножество множества всех терминальных цепочек S *.
Структура цепочек языка задается грамматикой и, как видно из примера 1.2, несколько грамматик могут определять один и тот же язык. Такие грамматики называются эквивалентными.
Пусть G(S) - грамматика. И пусть w =abg - сентенциальная форма. Тогда b называется фразой сентенциальной формы w для нетерминального символа U, если SÞ * aUg и UÞ + b; и далее, b называется простой фразой, если SÞ * aUg и UÞ g.
В общем случае, еслиUÞ +...U..., то говорят, что грамматика рекурсивна по отношению к U. Если UÞ + U..., то имеет место левая рекурсия, а если UÞ +...U, то - правая рекурсия. Соответствующие правила называют лево- (право)рекурсивными. Если язык бесконечен, то определяющая его грамматика должна быть рекурсивной.
Ниже представлен пример грамматики, которая включает правило с двухсторонней рекурсией.
Пример 1.3.Грамматика идентификатора, то есть последовательности из одного или более символов, начинающейся с буквы, и содержащей буквы и цифры в качестве возможного продолжения
S ® AB
A ® a A ® b
.............................
A ® y A ® z
B ® BB B ® e
B ® A B ® 0
..............................
B ® 9. ™
Дата добавления: 2021-02-19; просмотров: 483;
Поиск по сайту
Узнать еще
- DBASe-подобные реляционные языки
- U-Pb метод определения возраста по циркону
- А) Общие определения
- Алгебраический метод определения симметричных колебаний
- Алгебраический способ определения симметричных автоколебаний и устойчивости
- Алгоритм определения параметров
- Алгоритм определения передаточного отношения от
- Алгоритм определения эффективной пористости)

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
