Процедура обратного распространения
Ограниченные возможности однослойных сетей и отсутствие длительное время теоретически обоснованного алгоритма для обучения многослойных искусственных сетей привели к тому, что направление нейронных сетей пришло в упадок. Разработка алгоритма обратного распространения сыграла важную роль в возрождении интереса к искусственным нейронным сетям. Процедура обратного распространения применима к сетям с любым числом слоев с прямым и обратным распространением. Рассмотрим алгоритм на примере сети, состоящей из двух слоев с прямым распространением (рис. 13.7)

Рис. 13.7. Двухслойная сеть обратного распространения
Цель обучения сети состоит в такой подстройке весов, чтобы определенное множество входов X(x1,...,xn) приводило к требуемому множеству выходов Y(y1,...,yn). Предполагается, что для каждого вектора X существует парный ему целевой вектор Y и вместе они (X,Y) называются обучающей парой. Входная часть X этой пары состоит из нулей и единиц и может представлять, например, двоичный образ некоторой буквы алфавита. Так, букве алфавита, изображенной на странице в клетку, будет соответствовать двоичный образ, в котором xi=1, когда часть буквы располагается в клетке, и xi=0 - в противном случае. Таким образом, распознавание всех букв алфавита требует 32 обучающие пары.
Перед началом обучения присвоим весам любые небольшие начальные значения, с тем, чтобы избежать насыщения сети большими значениями весов. Алгоритм обучения сети обратного распространения включает в себя следующие шаги:
1. Выбрать очередную обучающую пару (X,Y) из обучающего множества и подать входной вектор X на вход сети.
2. Вычислить выход сети.
3. Вычислить разность между реальным (вычисленным) выходом сети и требуемым выходом (целевым вектором обучающей пары).
4. Подкорректировать веса сети так, чтобы минимизировать ошибку.
5. Повторить шаги с 1 по 4 для каждого вектора обучающего множества до тех пор, пока ошибка на всем множестве не достигнет приемлемой величины.
Шаги 1 и 2 подобны тем, которые имеются в уже обученной сети.
Вычисления в сети выполняются послойно. На шаге 3 каждый из выходов сети OUT вычитается из соответствующей компоненты целевого вектора с целью получения ошибки. Эта ошибка используется на шаге 4 для коррекции весов сети, причем знак и величина изменений определяются алгоритмом обучения.
Шаги 1 и 2 можно рассматривать как “проход вперед”, так как сигнал распространяется по сети от входа к выходу . Шаги 3 и 4 составляют “обратный проход”, здесь вычисляемый сигнал ошибки распространяется обратно по сети и используется для подстройки весов. Эти два прохода можно выразить в математической форме.
Проход вперед. На входе имеем вектор X, на основе которого вычисляется выходной вектор Y. Вектор Y вычитается из целевого вектора T с целью получения ошибки:
e=T-Y
Как мы видим, величина NET каждого нейрона первого слоя вычисляется как взвешенная сумма входов нейрона. Затем активационная функция F “сжимает” NET и дает величину OUT для каждого нейрона в этом слое. Полученное выходное множество OUT является входом для следующего слоя. Процесс повторяется слой за слоем, пока не будет получено заключительное множество сети.
Описанный процесс можно представить в векторной форме. Веса между нейронами соседних слоев можно представить с помощью матрицы W, где wij - вес от нейрона i (например, слоя 2) к нейрону j (слоя 3). Тогда NET-вектор слоя равен:
NET = XW.
Применение функции F к каждой компоненте вектора NET дает нам вектор OUT:
OUT = F(XW).
Последнее уравнение применяется к каждому слою сети от входа к выходу.
Обратный проход. Здесь происходит подстройка весов выходного слоя. Так как для каждого нейрона выходного слоя задано целевое значение, то подстройка весов легко осуществляется с помощью дельта-правила из п. 13.3. Внутренние слои не имеют целевых значений и их называют скрытыми слоями.
Рассмотрим процесс подстройки одного веса от нейрона p в скрытом слое j к нейрону q в выходном слое (рис.13.8). Выход OUT слоя k, вычитаясь из целевого значения T, дает ошибку, которая умножается на производную сжимающей функции [OUT (1-OUT)], вычисленную для этого нейрона слоя k, давая, таким образом, величину
d= OUT (1-OUT) (T-OUT)
Затем d умножается на величину OUT нейрона j, из которого выходит рассматриваемый вес.
Dwpq,k=hdq,k*OUTp,q
где dq,k - величина d для нейрона q в выходном слое k; OUTp,q - величина выхода для нейрона в скрытом слое j.
Это произведение в свою очередь умножается на коэффициент обучения h (0,01£h£1) и результат прибавляется к весу. Такая же процедура выполняется для каждого веса от нейрона скрытого слоя к нейрону в выходном слое:
| wpq,k(n+1)=wpq,k(n)+Dwpq,k | (13.17) |
где wpq,k(n) - величина веса от нейрона в скрытом слое k нейрону q в выходном слое на шаге n (до коррекции); отметим, что индекс относится к слою, в котором заканчивается данный вес, с которым он объединен.
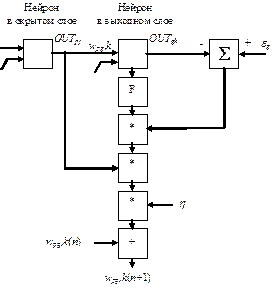 Рис. 13.8. Настройка веса в выходном слое
Рис. 13.8. Настройка веса в выходном слое
|
wpq,k(n+1) - величина веса на шаге n+1 после коррекции.
Подстройка весов скрытого слоя. Каждый нейрон скрытого слоя, предшествующего выходному, передает свои выходы к нейронам выходного слоя через соединяющие их веса. В процессе обучения эти веса функционируют в обратном направлении, пропуская величину d от выходного слоя к скрытому. Каждый из этих весов умножается на величину d нейрона, к которому он присоединен в выходном слое.
Величина d, необходимая для обучения нейрона скрытого слоя, равна сумме всех таких произведений, умноженной на производную сжимающей функции:
| dp,j=OUTp,j(1-OUTp,j)(S dq,k×wpq,k) | (13.18) |
После получения величины d веса скрытого слоя корректируются c помощью формул (13.16) и (13.17) (рис 13.9).
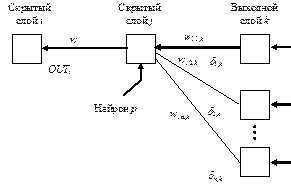 Рис. 13.9. Настройка веса в скрытом слое
Рис. 13.9. Настройка веса в скрытом слое
|
Для каждого нейрона в данном скрытом слое требуется вычислить d и подстроить все веса, связанные с этим слоем. Этот процесс повторяется слой за слоем по направлению к входу, пока все веса не будут подкорректированы.
Запишем операцию обратного распространения ошибки в векторной форме. Пусть Dk - множество величин d выходного слоя и Wk, множество величин выходного слоя. Для получения d-вектора Dj выходного слоя достаточно следующих операций:
1. Умножить d-вектор выходного слоя Dk на транспонированную матрицу весов W¢k , соединяющую скрытый слой с выходным.
| Dj=Dk×W¢k | (13.19) |
2. Умножить каждую компоненту полученного произведения на производную сжимающей функции соответствующего нейрона в скрытом слое:
| $[OUTj(I-OUTj)] | (13.20) |
где оператор $ обозначает покомпонентное произведение векторов. OUTj - выходной вектор слоя j и i - вектор, все компоненты которого равны 1.
Дата добавления: 2016-10-26; просмотров: 2513;
Поиск по сайту
Узнать еще
- Альфа-бета-процедура
- Биомасса, или живое вещество биосферы. Закономерности распространения биомассы в биосфере, тенденции ее изменения под влиянием деятельности человека.
- Вакцинация — уникальная медицинская процедура
- Влияние условий горения на скорость распространения пламени
- Внешнее управление как процедура, применяемая в деле о банкротстве.
- Внутр. к ЭЛТ (гашение обратного
- Возможные пути распространения пожара и меры профилактики
- Воспламенение жидкости и механизм распространения пламени по поверхности жидкости

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
