Остатки Векторы ошибок Остатки
на n -м такте
 Детектор для выделенного синдрома 100 можно построить из одного логического элемента НЕ и одного элемента ИЛИ — НЕ.
Детектор для выделенного синдрома 100 можно построить из одного логического элемента НЕ и одного элемента ИЛИ — НЕ.
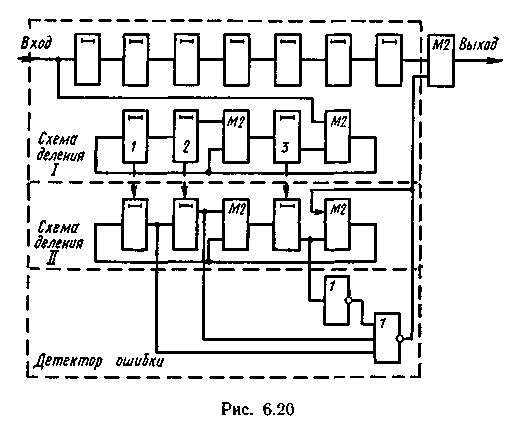
На рис. 6.20 представлена схема декодирующего устройства для этого случая.
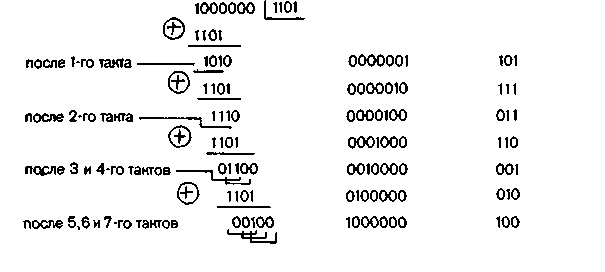
Табл. 6.18 позволяет проследить по тактам процесс исправления ошибки в кодовой комбинации 1000011 (искажен символ в 4-м разряде).
Таблица 6.18

Сравнение показывает, что использование в декодирующем устройстве схемы деления за k тактов предпочтительнее, так как выделенный синдром в этом случае при любом объеме кода содержит единицу в старшем и нули во всех остальных разрядах, что приводит к более простому детектору ошибки.
Пример 6.19. Рассмотрим более сложный случай исправления одиночных и двойных смежных ошибок. Для этой цели может использоваться циклический код (7,3) с образующим многочленом g(x) = (x+1)(x3 + x2+1).
Ориентируясь на схему деления за k тактов, найдем выделенный синдром для двойных смежных ошибок:
Остатки Остатки Векторы ошибок на n-м такте
Для одиночных ошибок соответственно получим
Остатки Векторы ошибок на n -м такте
Детектор ошибок в этом случае должен формировать сигнал коррекции при появлении каждого выделенного синдрома. Схема декодирующего устройства представлена на рис. 6.21.
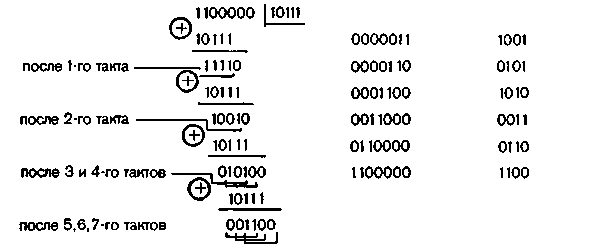
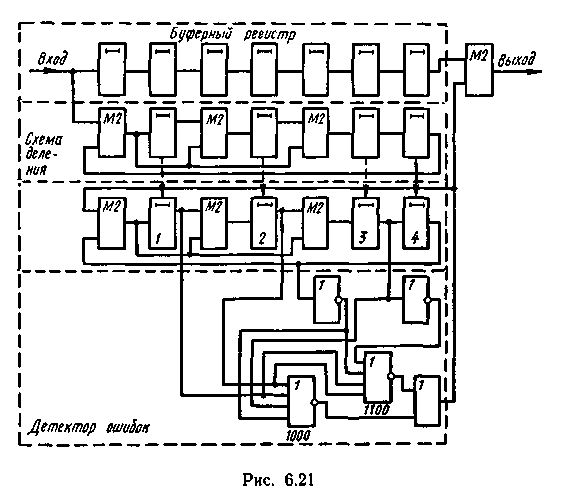 Процесс исправления кодовой комбинации 1000010 с искаженными символами в 4-м и 5-м разрядах поясняется табл. 6.19.
Процесс исправления кодовой комбинации 1000010 с искаженными символами в 4-м и 5-м разрядах поясняется табл. 6.19.
На 9-м такте в схеме деления II появляется первый выделенный синдром 1100. На следующем такте на выходе аналогично обозначенного элемента ИЛИ — НЕ детектора ошибок формируется импульс коррекции, который исправляет 5-й разряд кодовой комбинации и одновременно по цепи обратной связи изменяет остаток в схеме деления II, приводя его в соответствие выделенному синдрому еще неисправленной одиночной ошибки в 4-м разряде (1000) На 11 м такте импульс коррекции формирует элемент ИЛИ — НЕ детектора ошибок, соответствующий указанному выделенному синдрому. Этим импульсом обеспечивается исправление 4-го разряда кодовой комбинации и получение нулевого остатка в схеме деления II
Таблица 6.19

Декодирование кодов Файра. Рассмотрев код, исправляющий единичные и двойные смежные ошибки, мы установили необходимость двух схем в детекторе ошибок, настроенных на два выделенных синдрома. При большом числе выделенных синдромов, как это имеет место, например, в случае кодов, исправляющих пакеты ошибок значительной длины, такой подход неприемлем, так как декодирующее устройство оказывается чрезвычайно сложным.
В связи с этим разработаны коды, в схемах декодирования которых детектор ошибки автоматически настраивается на нужный выделенный синдром. Осуществляется это за счет схемы деления на второй соответствующим образом подобранный многочлен. Образующий многочлен таких кодов, следовательно, представляет собой произведение двух многочленов:
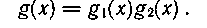
В качестве примера рассмотрим класс кодов Файра с образующим многочленом
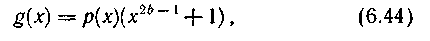
где р(х) — неприводимый многочлен степени m>=Ь, принадлежащий показателю степени е = 2m-1; b — длина корректируемого пакета ошибок.
Поступающую из канала связи кодовую комбинацию h(x) представляем суммой по модулю два неискаженной комбинации кода f(x) и вектора, соответствующего пачке ошибок В(х):
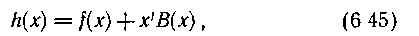
где х1 характеризует положение пачки ошибок В(х) в векторе ошибки. Вектор f(x) делится на каждый из многочленов g1(x) и g2(x) без остатка Поэтому процесс декодирования можно анализировать, ограничиваясь вектором хi*В(х). Отметим, что при выбранном нами соотношении числа разрядов в пакете ошибок и степени образующего многочлена m = b совокупность различных исправляемых пакетов ошибок является одновременно совокупностью остатков, получаемых при делении на р(х). В качестве остатка на n-м такте (выделенного синдрома) при пакете ошибок в старших разрядах h(x) желательно иметь сам многочлен ошибки. Тогда на следующих тактах, выводя его в узел коррекции синхронно с последовательностью h(x) из буферного регистра, легко исправить искаженные символы.
Остаток на n-м такте мы получим только в том случае, если будем использовать схему, обеспечивающую деление с первого такта и требующую домножения h(x) на хm.
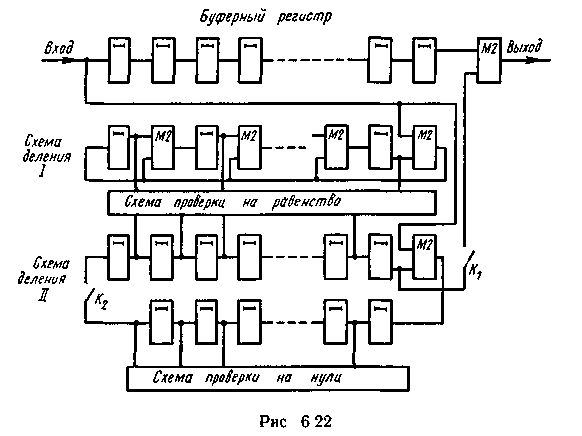 Для случая поступления кодовых комбинаций, разнесенных во времени, схема декодирующего устройства для кодов Файра представлена на рис. 6.22.
Для случая поступления кодовых комбинаций, разнесенных во времени, схема декодирующего устройства для кодов Файра представлена на рис. 6.22.
При поступлении h(x) в схему деления I [на многочлен р(х)] в ней начинается закономерное чередование остатков В(х), являющийся одним из остатков, появляется в первый раз на (2m-1)-м такте. Следовательно, для того чтобы он появился на n-м такте, общее число разрядов должно быть кратно 2m-1.
В процессе деления h(x) на многочлен х2b-1 + 1, принадлежащий показателю (2b — 1), образуется (2b — 1) остатков. Вектор типа В(х)хb-1 является одним из остатков. Он возникает впервые на (2b — 1)-м такте и затем его появление циклически повторяется с периодом (2b — 1) тактов
Если мы желаем выставить этот остаток в детекторе ошибки, т. е. получить его также на n-м такте, то n должно быть кратно (2b—1). Чтобы детектор ошибки не сработал раньше, числа 2m-1 и 2b — 1 должны быть взаимно простыми, а n — наименьшим кратным этих чисел.
Равенство остатков В(х) в регистрах двух схем деления, а также равенство нулю остальных (b — 1) разрядов в схеме деления II (на многочлен хb2 + 1) являются условиями возможности исправления обнаруженного пакета ошибок и устанавливаются схемным путем.
После фиксации условий, допускающих исправление пакета, ключ Κι замыкается, а ключ K2 размыкается. На схему коррекции (сумматор по модулю два) одновременно начинают выводиться символы В(х) как с буферного регистра, так и со схемы деления II. При этом пакет ошибок В(х) в векторе h(x) устраняется.
В общем случае, когда В(х) начинается не со старшего разряда, а с j-го, для обеспечения равенства остатков, полученных на n-м такте, нужно проводить последовательные домножения их на x с приведением по модулю р(х) в одной схеме и по модулю (x2b-1 + 1) — в другой.
Если пачка начинается с j-го разряда, то необходимо сделать дополнительно (n-j) тактов, прежде чем остатки в регистрах сравняются, причем с учетом домножения h(x) на хm*j может принимать значения от 1 до n.
За (n — j) дополнительных сдвигов содержимое буферного регистра сместится, и ошибочные символы снова окажутся непосредственно перед схемой коррекции.
Если за время вывода h(x) из буферного регистра условия возможности проведения коррекции не были выполнены, то обнаружена неисправимая ошибка.
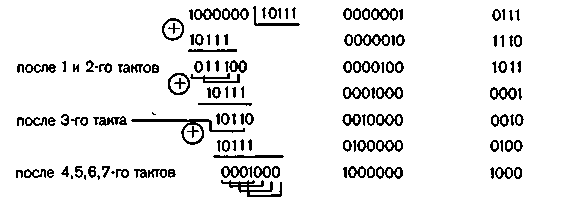
Пример 6.20. Рассмотреть процесс исправления пакетов ошибок кодом Файра с образующим многочленом
Код может исправлять пакеты ошибок, состоящие из трех символов (b = 3). Длина кодовой комбинации равна n = (23—1)(2 ·3-1) = 35. Предположим, что в трех старших разрядах нулевой кодовой комбинации возникла пачка ошибок типа В(х) = 101.
При делении В(х) на g1(x) = х3 + x2+ 1 остаток В(х) будет появляться в регистре с периодом 7 тактов. Действительно,
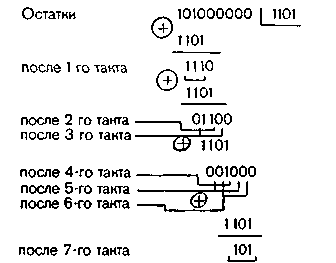
Чередование остатков В(х)х^b-1 при делении В(х) на g2(x) = x5 + 1 происходит с периодом 5 тактов.
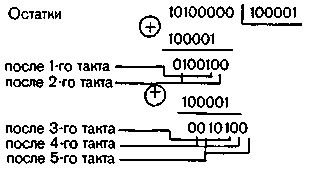
Последовательность изменения остатков в регистрах схем деления I и II при поступлении на вход декодирующего устройства нулевой кодовой комбинации с пачкой ошибок 101 в старших разрядах приведена в табл. 6.20. В силу специфики работы схемы деления за k тактов первые b — 1 остатков отличаются от полученных при делении столбиков.
Таблица 6.20
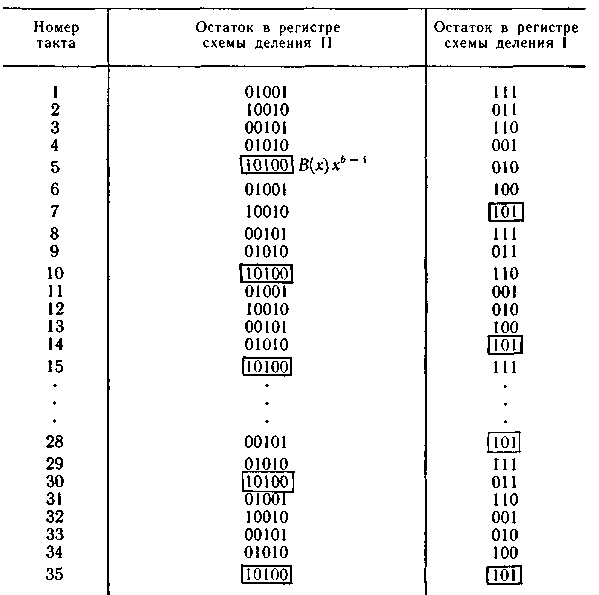
Условия возможности исправления пакета ошибок выполняются на 35-м такте. За последующие три такта при выводе кодовой комбинации из буферного регистра на схему коррекции пачка ошибок устраняется.
Мажоритарное декодирование циклических кодов. Система контрольных проверок, найденная для одного (например аi) или нескольких символов кодовой комбинации циклического кода, может быть использована для декодирования всех символов этой кодовой комбинации, так как контрольным соотношениям удовлетворяет любая кодовая комбинация, а следовательно, и комбинация, полученная из принятой циклическим сдвигом. Таким образом, для декодирования символа аi+k достаточно произвести k сдвигов и осуществить решение «по большинству» посредством того же мажоритарного элемента.
Основная трудность состоит в нахождении систем контрольных проверок. В случае циклического кода совокупность проверочных равенств может быть получена из рекуррентных соотношений.
Приведем контрольные равенства в развернутом виде:
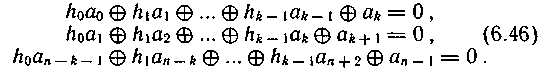
Из данной системы выбираем уравнения, включающие какой-либо один символ а, или одну и ту же сумму некоторых символов, и пытаемся разрешить их относительно этих символов. При этом может оказаться, что:
1. каждое контрольное равенство позволяет выразить некоторый символ а, посредством линейной комбинации символов, которые не входят ни в какое другое равенство (система разделенных проверок);
2. систему разделенных проверок удается построить только относительно суммы каких-либо символов (система квазиразделенных проверок);
3. каждое контрольное равенство позволяет выразить некоторый символ аi, посредством линейной комбинации других символов аj, однако не удается устранить повторения этих символов в других равенствах.
Последнюю систему называют λ-связанной, если хотя бы один символ ai(i неравно j) входит в λ равенств и никакой другой aj (i неравно j) в большее число равенств не входит. Поскольку способы выражения символов аiоказываются зависимыми, общее число нетривиальных проверок, требующееся для исправления и обнаружения ошибок, по сравнению с предыдущим случаем должно быть больше [16].
Для любого из рассмотренных случаев возможна техническая реализация декодирующего устройства с использованием мажоритарного принципа. Простейшей она оказывается для кодов, позволяющих получить систему разделенных проверок.
Ограничимся рассмотрением конкретного примера только для этого случая.
Пример 6.21. Составим систему разделенных проверок и построим схему декодирующего устройства для циклического кода (7,3) с образующим многочленом g(x) = (x+1)(x3 + x + 1), предназначенного для исправления единичных и одновременного обнаружения двойных ошибок (d = 4)
Найдем генераторный многочлен
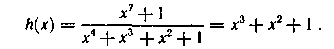
Выражая символ старшего разряда a0 через различные символы и добавляя тривиальную проверку a0 = а0, получим систему:
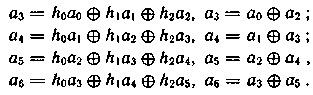
Запишем контрольные равенства:

Соответствующая схема декодирующего устройства представлена на рис. 6.23.
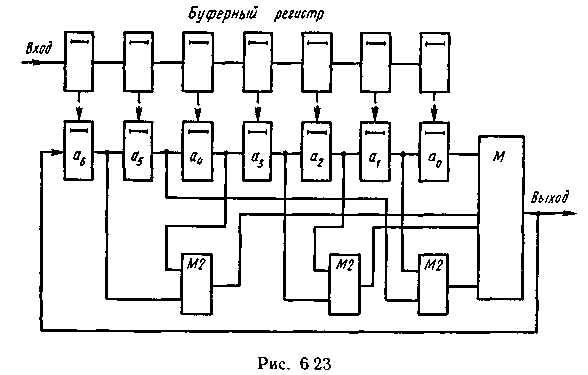 Поступившая в буферный регистр кодовая комбинация параллельно переписывается в регистр декодера. На каждом из n последующих тактов на входе мажоритарного элемента M формируются сигналы в соответствии с равенствами (6.47).
Поступившая в буферный регистр кодовая комбинация параллельно переписывается в регистр декодера. На каждом из n последующих тактов на входе мажоритарного элемента M формируются сигналы в соответствии с равенствами (6.47).
При наличии одиночной ошибки искаженный сигнал имеет место только на одном из четырех входов мажоритарного элемента и последний по большинству неискаженных входных сигналов формирует правильный выходной сигнал, соответствующий символу а0. Значение каждого последующего символа определяется аналогично после очередного сдвига.
Табл. 6.21 позволяет проследить процесс мажоритарного декодирования для случая, когда одиночная ошибка произошла в 4-м разряде кодовой комбинации 1001110.
Таблица 6.21
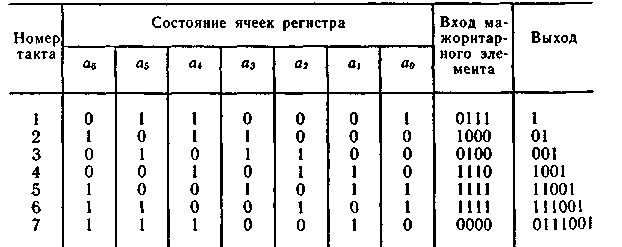
Случай, когда на двух входах мажоритарного элемента оказывается сигнал «1», а на двух других — «0», соответствует обнаружению двойной ошибки.
§ 6.9. КОДЫ БОУЗА — ЧОУДХУРИ — ХОКВИНГЕМА
Математическое введение. Рассматриваемые циклические коды, сокращенно называемые БЧХ - кодами, составляют большой класс кодов, предназначенных для исправления независимых ошибок произвольной кратности s. Их минимальное кодовое расстояние, следовательно, должно быть не менее чем dmin = 2s + 1.
Для понимания математической структуры БЧХ - кодов необходимо ознакомиться с некоторыми новыми понятиями линейной алгебры. В общем случае эти понятия справедливы для множества многочленов с коэффициентами из поля GF(q), где q — простое число. Поскольку нас интересуют в первую очередь двоичные коды, мы ограничимся случаем q = 2.
Ранее было рассмотрено разложение кольца на классы вычетов по идеалу (см. табл. 6.10). Если в качестве образующего многочлена идеала g(x) взят неприводимый многочлен степени т, принадлежащий показателю степени n(n = 2m—1), то общее число классов вычетов, включая идеал, равно 2^m.
Зададим операции сложения и умножения для полученных классов вычетов:
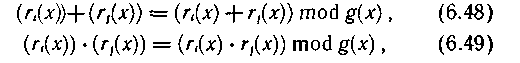
где (ri(х)) — класс вычетов по модулю многочлена g(x) содержащий элемент ri(x).
При этом совокупность классов вычетов образует конечное поле. Оно насчитывает 2m элементов, обозначается GF(2m) и называется расширением поля степени m над GF(2). Единичным и нулевым элементами поля являются классы вычетов соответственно (1) и (0).
Нетрудно убедиться в том, что для любого ненулевого элемента поля (гa(х)) в нем найдется обратный ему элемент (ra(х)), удовлетворяющий равенству
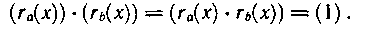
Пример 6.22. Построим поле порядка 24, используя неприводимый многочлен g(x) = x4 + x + 1 ·
Полная совокупность классов вычетов равна числу остатков, получающихся при делении произвольного многочлена на многочлен р(х). Для заданного многочлена эта совокупность составляет 16 классов вычетов: (0), (1), (x), (х+1), (х2), (х2+1), (х2+х), (х2+х+1), (х3), (х3+1), (х3+х), (х3+х2), (х3+х+1), (х3+х2+1), (х3+х2+х), (х3+х2+х+1).
Поскольку построение таблицы сложения элементов поля трудностей не представляет, ограничимся записью таблицы умножения этих элементов. Обозначив через α класс вычетов (х), содержащий многочлен х, и исключив из рассмотрения нулевой элемент, получим табл. 6.22.
Таблица 6.22
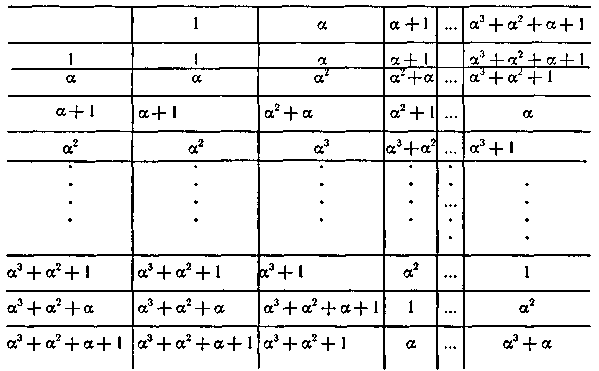
Из приведенного примера видно, что составление таблицы умножения элементов поля, представленных многочленами, является достаточно трудоемким делом. Однако процедура умножения существенно упрощается благодаря возможности представления всех элементов поля в виде степеней одного из его элементов.
Доказано, что в любом конечном поле найдется по крайней мере один элемент α, такой, что все ненулевые элементы поля могут быть представлены в виде различных степеней αi этого элемента, называемого примитивным элементом поля. Так как рассматриваемое поле конечно и насчитывает n=2m-1 ненулевых элементов, то начиная с αn = 1 элементы поля начнут повторяться.
Элементы поля могут быть выражены и через отрицательные степени α , так как поле содержит мультипликативный обратный элемент каждого ненулевого элемента. Используя элементы αm-1, αm-2, ..., α, 1 в качестве базиса, элементы поля можно представить также в виде двоичных последовательностей (векторное представление).
Пример 6.23. Приведем различное представление элементов поля, построенного на основе неприводимого многочлена g(x) = х4 + х+1 (табл. 6.23).
Таблица 6.23

Выражение элементов через отрицательную степень α осуществляется делением на α15 = 1.
Покажем теперь, что любой элемент конечного поля порядка 2m является корнем уравнения
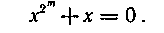
Для ненулевых элементов поля соответственно имеем
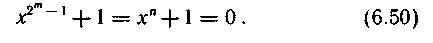
Если α — примитивный элемент поля, то произвольный ненулевой элемент представляется в виде степени а, т. е. β = αi.
Тогда 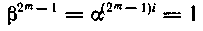 и, следовательно, все ненулевые элементы поля являются корнями уравнения хn + 1 = 0. Эти корни принадлежат различным неприводимым в поле GF(2) многочленам, на которые разлагается двучлен xn +1. Алгоритм такого разложения был приведен ранее. В частности, в примере 6.13 получена совокупность многочленов, корнями которых являются элементы поля Gf(24):
и, следовательно, все ненулевые элементы поля являются корнями уравнения хn + 1 = 0. Эти корни принадлежат различным неприводимым в поле GF(2) многочленам, на которые разлагается двучлен xn +1. Алгоритм такого разложения был приведен ранее. В частности, в примере 6.13 получена совокупность многочленов, корнями которых являются элементы поля Gf(24):
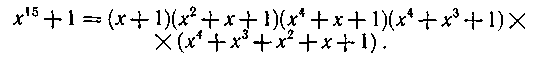
Для нас существенно, как распределены корни двучлена xn+1 (а следовательно, и элементы поля) по составляющим неприводимым многочленам. Доказана следующая закономерность. Если известен один из корней β неприводимого многочлена степени m, то все другие корни этого многочлена являются определенными степенями β, а именно:
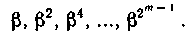
Порядок корней неприводимого многочлена является показателем, которому этот многочлен принадлежит.
Многочлен g(x) наименьшей степени, такой, что g(β)=0, называется минимальным многочленом для элемента β. Будем обозначать его gβ(x). Неприводимый над полем GF(2) многочлен степени т называется примитивным, если его корнем является примитивный элемент поля GF(2m).
Пример 6.24. Найдем распределение корней двучлена
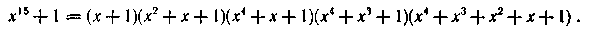
Если корни рассматривать как элементы поля, построенного с использованием неприводимого многочлена g(x) = x4 + x + 1, то этот многочлен является примитивным Действительно, примитивный элемент α поля GF(24) является корнем многочлена g(x). Остальные его корни соответственно равны α2 , α4 и α8. Можно непосредственно убедиться в справедливости равенства
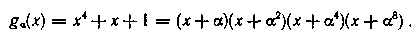
Теперь найдем минимальный многочлен g3(x) для элемента α3. Его корнями должны быть элементы
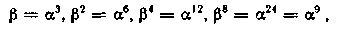
откуда
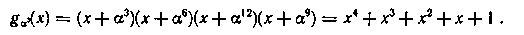
Аналогично определим минимальные многочлены g5(x) и g7(x) для элементов α5 и α7. Цикл корней g5(x) включает α5 и α10 соответственно для g7(x) имеем α7, α14, α13, α11.
Следовательно,
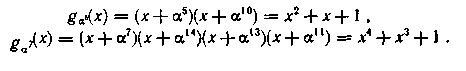
Итак, распределено 14 корней многочлена x15 + 1. Последний корень α0 равен 1 и принадлежит двучлену x + 1.
Построение и реализация кодов. Процесс выбора образующего многочлена кода Боуза — Чоудхури — Хоквингема, рассчитанного на исправление единичных ошибок, ничем не отличается от рассмотренного ранее. Основное отличие заключается в интерпретации опознавателей ошибок. В данном случае ими считаются различные степени примитивного элемента поля GF(2m), построенного с использованием выбранного неприводимого многочлена g(x) степени m, принадлежащего показателю степени n = 2m—1. Так как число различных ненулевых элементов поля, выраженных степенями примитивного элемента, равно n, то каждому вектору ошибки в отдельном разряде можно сопоставить свой опознаватель, что и гарантирует возможность исправления ошибок.
При возникновении двух ошибок построенный код позволяет определить только сумму s опознавателей этих ошибок
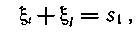
где ξ, и ξ, — опознаватели ошибок в разрядах i и j.
Для однозначного определения ошибок необходимо еще одно независимое уравнение. Возможно использование степенных функций от ξ. Однако квадраты опознавателей не приводят к желательному результату, поскольку второе уравнение с учетом сложения по модулю два оказывается квадратом первого.
Действительно,
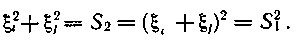
Если использовать кубы опознавателей, то уравнения оказываются независимыми
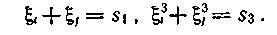
Такой подход допускает обобщение на случай исправления 3- и 4-кратных ошибок и т. д. При этом к полученным уравнениям соответственно добавляются уравнения с опознавателями в пятой, седьмой степенях и т. д.
Коснемся подробнее случая исправления двойных ошибок. Проведем преобразование второго уравнения
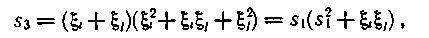
откуда
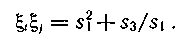
Поскольку известны сумма и произведение опознавателей, то на основании теоремы Виета можно составить уравнение, для которого опознаватели ξi и ξj являются корнями:
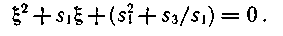
Если ошибка оказалась одна, то
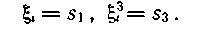
и ее опознаватель удовлетворяет уравнению
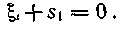
При отсутствии ошибок, естественно, получаем нулевые опознаватели, так как s1=s3 = 0.
На практике оказывается удобнее использовать многочлены, корнями которых являются не опознаватели ошибок, а их мультипликативные обратные элементы z= =ξ-1.
Для случая исправления двойных ошибок левая часть уравнения преобразуется к виду
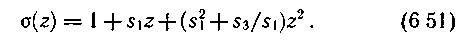
При возникновении одной ошибки

при отсутствии ошибок
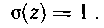
Осталось выяснить, как получить суммы нечетных степеней опознавателей ошибок, в частности сумму 5з кубов опознавателей при исправлении двойных ошибок. Указанные суммы можно определить за счет последовательного добавления к выбранному примитивному многочлену g(x) в качестве сомножителей минимальных многочленов для элементов α3 (случай двойных ошибок), α5 (случай тройных ошибок) и т. д. Суммы нечетных степеней опознавателей ошибок вычисляются по остаткам, получаемым в результате деления принятой кодовой комбинации на соответствующий минимальный многочлен.
В общем случае образующий многочлен кода Боуза — Чоудхури — Хоквингема представляет собой наименьшее общее кратное (НОК) примитивного и минимальных многочленов
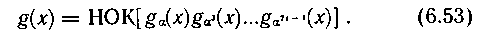
В частности, для кода с n =15, рассчитанного на исправление двойных независимых ошибок, получаем
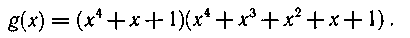
Пример 6.25. Рассмотрим процесс исправления единичных ошибок кодом Боуза — Чоудхури (15, 11) с образующим многочленом g(x) = x4 + x + 1.
Используя табл. 6.23, сопоставим каждому вектору ошибки свой опознаватель в виде определенной степени примитивного элемента ее поля GF(24) Результат представлен табл. 6.24.
Таблица 6.24

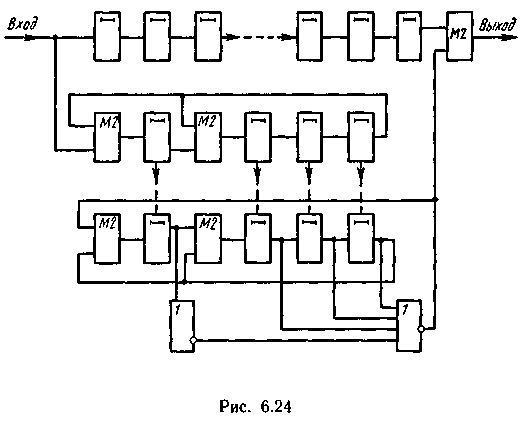 Схема декодирующего устройства представлена на рис 6.24. Детектор ошибки выполнен в соответствии с уравнением l+s1z = 0. За первые n = 15 тактов в результате деления поступающей из канала связи кодовой комбинации h(x) на g(x) получаем в регистре I опознаватель ошибки х-j. Затем он переписывается в регистр II схемы, осуществляющей домножение опознавателя на α с приведением по модулю g(x), тес превращением α4 в α + 1.
Схема декодирующего устройства представлена на рис 6.24. Детектор ошибки выполнен в соответствии с уравнением l+s1z = 0. За первые n = 15 тактов в результате деления поступающей из канала связи кодовой комбинации h(x) на g(x) получаем в регистре I опознаватель ошибки х-j. Затем он переписывается в регистр II схемы, осуществляющей домножение опознавателя на α с приведением по модулю g(x), тес превращением α4 в α + 1.
На (n + 1)-м такте символ старшего разряда кодовой комбинации h(x) поступает из буферного регистра в сумматор коррекции. Одновременно производится домножение опознавателя α-j на α, и на схему ИЛИ детектора подается вектор 1+si*α. Если 1 +s1 α неравно 0, то s1 неравно α-1 и, следовательно, ошибка произошла не в старшем разряде.
Аналогично анализируется правильность других символов, последовательно поступающих в узел коррекции из буферного регистра. Когда в схеме коррекции появляется искаженный символ j-и позиции (начиная со старшего разряда), то 1+ +s1αj = 0 и s1 = α-j. При этом выходной сигнал схемы ИЛИ детектора равен нулю и импульс с выхода схемы НЕ корректирует ошибку.
Пример 6.26. Наметим последовательность операций при исправлении двойных ошибок кодом (15, 7) с образующим многочленом g(x) = (x4 + x + 1)(x4 + x3 + x2 + x + 1).
В процедуре декодирования указанного кода можно выделить следующие этапы:
1) нахождение суммы s1 опознавателей ошибок путем деления поступившей из канала связи кодовой комбинации h(x) на многочлен х4 + x + 1;
2) определение суммы s3 кубов опознавателей в базисе α9 α6 α1 путем деления h(x) на многочлен х4 + х3 + x2 + x + 1;
3) выражение s3 в базисе α3 α2 α1;
4) вычисление s12, отношения s3/s1 и суммы s12 + s3/s1,
5) построение схемы для определения корней уравнения q(z) = 1+s1z+(s12 + + s3/s1)z2 путем последовательного домножения s1 на α и (s12 + s3/s1) на α2.
§ 6.10. ИТЕРАТИВНЫЕ КОДЫ
Для итеративных кодов характерно, что операции кодирования проводятся над совокупностью информационных символов, располагаемых по нескольким, например q, координатам. В связи с этим итеративные коды также называют многомерными, многостепенными. Число информационных символов в кодовом векторе q-степенного кода

где mγ — число информационных символов по координате γ. Последовательности информационных символов по каждой из координат кодируются каким-либо линейным кодом. В общем случае каждый информационный символ входит одновременно в q различных кодовых векторов.
Классические итеративные коды. Идея создания рассматриваемых кодов принадлежит П. Элайесу.
В этом случае определенным линейным кодом кодируется каждая из отдельных последовательностей информационных символов по координате γ, (например, каждая строка). Получаемый итеративный код также является линейным.
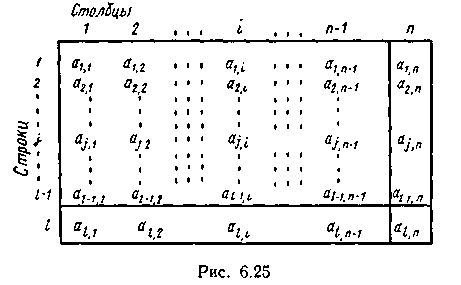 Простейший из таких кодов является двухстепенной (двумерный) код с проверкой на четность по строкам и столбцам, который широко используется на практике для обнаружения ошибок на магнитной ленте. Расположение информационных и проверочных символов приведено на рис. 6.25.
Простейший из таких кодов является двухстепенной (двумерный) код с проверкой на четность по строкам и столбцам, который широко используется на практике для обнаружения ошибок на магнитной ленте. Расположение информационных и проверочных символов приведено на рис. 6.25.
Значения проверочных символов, располагающихся в крайнем правом (или в любом другом) столбце и нижней строке, определяются уравнениями
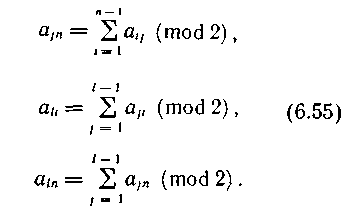
Передачу символов такого кода обычно осуществляют последовательно символ за символом, от одной строки к другой, либо параллельно целыми строками. Декодирование начинают сразу, не ожидая поступления всего блока информации.
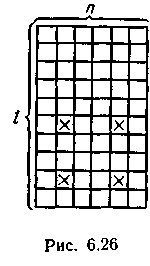
Проверка справедливости соотношения (6.55) при декодировании позволяет исправить любое нечетное число искаженных символов, расположенных в одной строке или в одном столбце. Действительно, строка (столбец) с нечетным числом искаженных символов будет выявлена неудовлетворительным результатом проверки ее на четность, а искаженные символы конкретно будут указаны при проверках по столбцам (строкам). Большинство ошибок другой конфигурации этим кодом может быть обнаружено. Необнаруженными оказываются только ошибки, имеющие четное число искаженных символов, как по строкам, так и по столбцам. Простейшая не обнаруживаемая ошибка содержит четыре искаженных символа, расположенных в вершинах прямоугольника (рис. 6.26).
 Число ошибок такого вида В4 для блока из lхn символов равно
Число ошибок такого вида В4 для блока из lхn символов равно
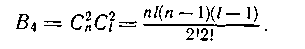
Общее число четырехкратных ошибок составляет
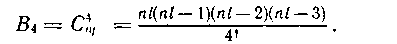
Таким образом, отношение числа не обнаруживаемых четырехкратных ошибок к общему числу таких ошибок
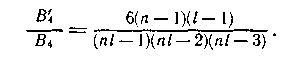
Определим минимальный вес ненулевого вектора рассматриваемого итеративного кода (двумерной кодовой комбинации). Такой вектор должен содержать только одну ненулевую вектор-строку, минимальный вес, которой равен 2. Проверка на четность каждого из ненулевых столбцов также дает вектор веса 2. Следовательно, минимальный вес ненулевого вектора итеративного кода с двойной проверкой на четность равен 2*2 = 4.
Аналогично можно показать, что в общем случае минимальный вес вектора итеративного кода равен произведению минимальных весов векторов итерируемых кодов. Так как минимальное кодовое расстояние для линейного кода равно минимальному весу его ненулевых векторов, то минимальное расстояние итеративного кода равно

где dγ — кодовое расстояние линейного кода по координате γ.
Коррекция ошибок проводится последовательно. Сначала исправляют ошибки по одной координате, затем осуществляют исправление оставшихся ошибок по другой координате и т. д.
Такая процедура проста, но снижает корректирующую способность итеративного кода, поскольку оказывается невозможным исправить часть ошибок кратности (d-l)/2.
Поясним это на примере итерации двух кодов Хэмминга (7, 4). Результирующий итеративный код (49, 16) имеет минимальное кодовое расстояние, равное 3x3 = =9, и, следовательно, потенциально, как любой линейный код, способен исправлять все ошибки кратности 4 и менее. Однако, применяя указанную выше процедуру декодирования, невозможно исправить четырехкратные ошибки с расположением искаженных символов в вершинах прямоугольника (рис. 6.26).
Специальные двухстепенные коды. Специальные двухстепенные коды нашли широкое применение для обнаружения и исправления ошибок, возникающих при записи, хранении и считывании цифровой информации с накопителей на магнитном носителе, например на магнитной ленте. Разработанные коды базируются на исследованиях статистики ошибок. Опубликованные данные показывают, что при эксплуатации магнитных носителей преобладают пачки ошибок вдоль дорожек (столбцов), причем вероятность возникновения двух пачек ошибок и более на разных дорожках в кадре информации из нескольких десятков строк достаточно мала.
Рассмотрим один из таких кодов [4].
Стандартный код для записи информации на магнитную ленту. В каждом кадре информации формируется одна дополнительная строка. Проверочные символы на дополнительной дорожке определяются из условия обеспечения нечетности числа единиц вдоль данной строки. В направлении дорожек используется параллельный циклический код, позволяющий определить номер дорожки, на которой возникла пачка ошибок. Зная номер дорожки с искаженными символами и используя результаты проверок по  строкам, можно произвести их исправление.
строкам, можно произвести их исправление.
Расположение кодируемого кадра информации на ленте показано на рис. 6.27.
Кодирование циклическим кодом осуществляется следующим образом. Многочлен F1(x), соответствующий информации перкой строки, умножается на x и результат приводится по модулю образующего многочлена g(x) степени n, где n — число дорожек, включая контрольную [например, для 9 дорожек g(x) = (х + 1)(х8 + + х4 + х3 + x2 + 1)]. Полученный остаток Ri(x) суммируется по модулю два с многочленом F2(x), соответствующим информации второй строки. Сумма снова умножается на x и далее приводится по модулю g(x), в результате чего определяется остаток R2(x). Применив этот алгоритм последовательно ко всем строкам кодируемого кадра информации, получим R1(x) — многочлен степени не выше n-1, который и записывается в конце кадра (при нечетном числе строк в нем), в качестве символов контроля по дорожкам
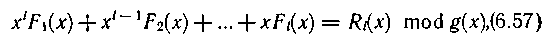
где Ri(x) mod (x) означает величину Ri(x), приведенную по модулю g(x).
Декодирование производится аналогично кодированию, причем участвует и контрольная строка — Ri(x). Процесс декодирования можно записать следующим образом:
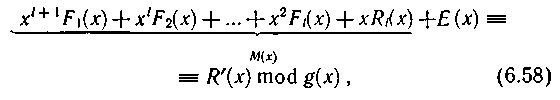
где Ε (x) — некоторый многочлен, определяющий ошибку. Выражение M(х) можно представить в виде
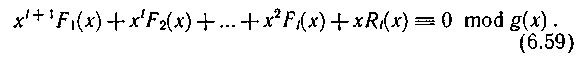
Сравнивая его с выражением (6.58), можно заключить, что при отсутствии ошибки будет фиксироваться значение R'(x), равное нулю. Случай R'(x) неравна 0 соответствует обнаружению ошибки. Если имела место пачка ошибок вдоль одной из дорожек, то она может быть исправлена. Многочлен ошибки в этом случае имеет вид Ε (x) = xje(х), где е(х) отражает поразрядную структуру, а хj — адрес ошибки. Так как справедливо равенство (6.59), то
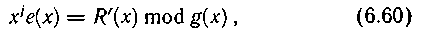
причем е(х) определяется по результатам проверок строк на нечетность.
Номер дорожки с искаженными символами может быть найден теперь, исходя из следующих соображений. Предположив, что на ленте была записана информация, состоящая из одних нулей, т. е. F1(x) = 0...Fl(x) = 0, Rl(x) = 0 и при считывании на дорожке с выбранным известным номером n возникла пачка ошибок с точно такой же структурой е(х), в результате декодирования получим некоторый многочлен R"(x), причем
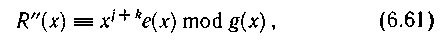
где k — число дорожек, на которое отстоит дорожка с известным номером η от дорожки, где возникла пачка ошибок.
Таким образом, если пачка ошибок возникла только по одной дорожке, то, умножив R'(x) на xk с приведением по модулю g(x), получим R"(x). Поэтому при декодировании одновременно с вычислением R'(x) осуществляется вычисление R"(x). Для определения номера дорожки с искаженными символами производится последовательное домножение R'(x) на х, х2, ..., хn-1.
На каждом шаге, начиная с R'(x), результат приводится по модулю g(x) и затем сравнивается с R"(x). Процесс прекращается, как только на каком-либо i-м шаге зафиксировано равенство (в этом случае k = i— 1 и известная величина n определяет номер искомой дорожки) или после проведения n сравнений. В последнем случае фиксируется наличие неисправимой ошибки.
При четном числе строк кодируемой информации l образующий многочлен типа g(x) = (х + 1 )g'(x) обеспечивает Rl(x) всегда с четным числом членов. Суммирование этого многочлена с g'(x) позволяет получить результирующий многочлен R'l(x), удовлетворяющий проверке по нечетности вдоль строки.
Описанные коды способны исправлять все пачки ошибок, возникающие по одной дорожке, за исключением пачек вила
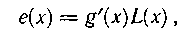
где L(x) — произвольный многочлен.
Кодирование и декодирование информации с использованием рассматриваемых кодов относительно просто реализуется как программными, так и аппаратными средствами [4].
§ 6.11 СВЕРТОЧНЫЕ КОДЫ
Для сверточных (рекуррентных) кодов характерно, что операции кодирования и декодирования осуществляются над непрерывной последовательностью символов. Такой метод имеет определенные преимущества, так как предоставляет большие возможности для использования вводимой избыточности.
 В общем случае сверточному кодированию могут подвергаться последовательности символов, являющихся элементами произвольного конечного поля GF(q). Мы ограничимся рассмотрением двоичных сверточных кодов. Принцип кодирования поясняется рис. 6.28. В каждый дискретный момент времени на вход кодирующего устройства поступают k информационных последовательностей символов, а с его выхода в канал связи выдаются η последовательностей, причем n>k. Проверочные символы, как и в блоковых кодах, получаются в результате проведения линейных операций над определенными информационными символами.
В общем случае сверточному кодированию могут подвергаться последовательности символов, являющихся элементами произвольного конечного поля GF(q). Мы ограничимся рассмотрением двоичных сверточных кодов. Принцип кодирования поясняется рис. 6.28. В каждый дискретный момент времени на вход кодирующего устройства поступают k информационных последовательностей символов, а с его выхода в канал связи выдаются η последовательностей, причем n>k. Проверочные символы, как и в блоковых кодах, получаются в результате проведения линейных операций над определенными информационными символами.
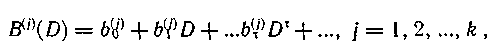
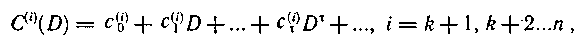
Дата добавления: 2016-10-18; просмотров: 2072;
Поиск по сайту
Узнать еще
- Анализ качества САУ с помощью метода коэффициентов ошибок
- Аналого-цифровые преобразователи: назначение, ошибки преобразования, способы уменьшения динамических ошибок преобразования. Виды АЦП, сравнительная оценка.
- АЦП последовательного счета с предварительным преобразованием напряжения во временной интервал: схема, работа, достоинства, недостатки.
- Б) Классификация ошибок измерений
- Векторы для клонирования ДНК
- ВЕКТОРЫ И ДЕЙСТВИЯ С НИМИ
- Векторы и линейные операции над ними
- Векторы и простейшие действия над ними

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
