Определение объема выборки
Для определения необходимой численности выборки следует задать уровень точности выборочной совокупности с определенной вероятностью. В частности, объем выборочной совокупности в простой вероятностной выборке определяется по формуле:
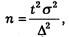
которая следует из формулы предельной ошибки выборки:
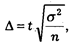
где п — объемвыборочной совокупности,
s2 — дисперсия изучаемого параметра в генеральной совокупности,*
t — коэффициент доверия — показатель, который характеризует вероятность реализации той или иной выборки,
D — предельная ошибка выборки.
* Дисперсия — величина, которая характеризует меру однородности генеральной совокупности. Чем дисперсия больше, тем меньше мера однородности генеральной совокупности. Чем дисперсия меньше, тем однородность генеральной совокупности больше.
Предельная ошибка содержит информацию о точности выборки с определенной вероятностью.
Вероятность задается коэффициентом доверия. В эту формулу не входит объем генеральной совокупности (N), что не случайно. В математической статистике установлено, что для выборок из большой генеральной совокупности объем исходного материала не оказывает влияния на объем выборочной совокупности (те).
Как правило, объем генеральной совокупности в правовых исследованиях очень большой, поэтому нет оснований определять объем выборки в долях. Определение необходимого объема выборки часто составляет серьезную проблему. Это связано, в частности, с неразработанностью ряда вопросов (оценка вариации изучаемых признаков, обоснование численности выборки при изучении нескольких признаков и др.).
Виды выборки
В правовых исследованиях применяются следующие виды выборки:*
простая вероятностная (или собственно случайная) выборка,
систематическая вероятностная,
типическая выборка,
многоступенчатая выборка,
квотная выборка.
* Различные авторы при классификации видов выборок применяют различную терминологию, но суть этих классификаций остается одной и той же.
Простая вероятностная (собственно случайная) выборка применяется в тех случаях, когда объем генеральной совокупности относительно невелик и есть возможность доступа к каждому элементу. В этом случае каждый элемент генеральной совокупности имеет равные шансы попасть в выборочную совокупность.
Объектов, которые наиболее часто встречаются в генеральной совокупности, будет больше и в выборке, и наоборот.
Отбор элементов в выборочную совокупность чаще всего производится методом жеребьевки или по таблице случайных чисел.
При отборе с помощью жеребьевки следят за тем, чтобы количество жребиев соответствовало объему генеральной совокупности. Каждый из элементов жеребьевки (шары, карточки, фишки) должен содержать информацию об отдельной единице совокупности (номер, название или какой-либо другой отличительный признак).
Количество жребиев, установленное в соответствии с определенным процентом отбора, извлекается из общей их совокупности в случайном порядке. При использовании для отбора таблиц случайных чисел каждая единица генеральной совокупности должна иметь порядковый номер.*
* Таблицы случайных чисел представляют собой абсолютно произвольные столбцы цифр, полученные с помощью датчика случайных чисел на ЭВМ.
Систематическая вероятностная выборка используется в тех случаях, когда генеральная совокупность носит упорядоченный характер, например списки гражданских дел; число работников государственного органа; список депутатов законодательного (представительного) органа; список мер наказаний, назначенных определенной группе осужденных; список хозяйствующих субъектов на территории района и др.
При организации систематической выборки устанавливается пропорция отбора путем соотношения выборочной и генеральной совокупностей. В качестве примера возьмем генеральную совокупность в 10 тыс. уголовных дел осужденных за умышленное убийство и 5% выборку. Пропорция отбора составит:
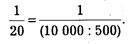
Отбор единиц осуществляется в соответствии с установленной пропорцией через равные интервалы. В данном случае отбирается каждое 20-е уголовное дело.
Средняя ошибка систематической выборки рассчитывается по формуле для простой вероятностной выборки. Так, при изучении личности повторных правонарушителей в двух индустриально-аграрных районах РФ применялась простая вероятностная выборка. Из общего массива статистических карточек была получена выборочная совокупность объемом в 4 тыс. единиц.
Для обеспечения такого отбора была получена последовательность случайных чисел, т. е. чисел, в чередовании которых нет никакой закономерности. Эта последовательность строилась с применением специальной программы на ЭВМ БЭСМ-ЗМ. Затем полученные числа были упорядочены по возрастанию, т. е. ранжированы по величине. Для уточнения выборки были сформированы группы объемом соответственно 500, 1000, 1500, 2000, 3000 и 4000 карточек, образованные по принципу случайного отбора.
Воспользуемся данным примером и выполним некоторые расчеты. Вычислим максимальную ошибку выборки.*
* Максимальной ошибкой выборки называется величина наибольшего отклонения генеральной средней от выборочной, которая может иметь место с заданной доверительной вероятностью.
С этой целью возьмем формулу предельной ошибки для простой вероятностной выборки:
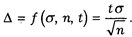
Обычно коэффициенту доверия t придают значения 1, 2, 3. При t = 1 вероятность, P(t) отклонения выборочных характеристик от генеральных средних на величину одного среднеквадратичного отклонения равна 0,683.
При вычислении объема выборки в нашем примере воспользуемся следующими значениями параметров, входящих в формулу объема выборки:
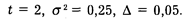
Подставим эти значения в нашу формулу и выполним вычисления:
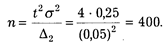
Мы видим, что необходимый объем выборки при заданных условиях является относительно небольшим.
В нашем примере объем выборки равен 4000 карточек — с учетом того, что достаточным должен быть объем и для таких показателей, которые имеют весьма небольшой удельный вес во всей генеральной совокупности.*
* В математической статистике разработана теория так называемых "малых выборок" (В. Госсет, Р. Фишер, А, Колмогоров). Согласно этой теории при выполнении определенных условий выборка может быть достаточно представительной при объеме в 20 наблюдаемых единиц.
Таким образом, из этой формулы видно, что для увеличения точности выборочной совокупности необходимо соблюдение двух требований:
1) изучаемый признак в генеральной совокупности должен быть как можно более однородным;
2) объем выборочной совокупности должен быть как можно большим.
В правовых исследованиях простая вероятностная выборка имеет ограниченное применение, что связано со сложной иерархической структурой изучаемых социальных объектов.
Это заставляет использовать комбинированные выборки, сочетающие элементы различных приемов.
Типическая выборка применяется в том случае, когда генеральная совокупность неоднородна с точки зрения социально-демографических, экономических или иных признаков. Причем все единицы генеральной совокупности можно разбить на несколько типических групп. Типический отбор предполагает выборку единиц из каждой группы с использованием простой или систематической вероятностной выборки.
Отбор единиц в такую выборку может производиться пропорционально либо объему типических групп, либо внутригрупповой дифференциации признака.
Например, при изучении личности преступника всю совокупность осужденных обычно разбивают по возрастам, выделив такие группы, как несовершеннолетние, осужденные среднего и старшего возраста. Образованные подобным образом группы неравны между собой. Поэтому отбор выполняется пропорционально объему групп.
При данном отборе в выборку попадают представители всех типических групп. Вследствие этого достигается большая точность выборки.
Необходимость применения многоступенчатой выборки вызвана, как правило, отсутствием информации обо всех единицах наблюдения генеральной совокупности.
Для организации первой ступени достаточно иметь информацию о распределении признака отбора. Для проведения отбора во второй ступени используется информация об отобранных единицах первой ступени.
Таким образом, на каждой ступени меняется единица отбора. На первой ступени обычно используется строго случайный, а на последующих (начиная со второй) — вероятностный пропорциональный отбор, т. е. учитывается размер единиц первой ступени, попавших в выборку.
Доли отбора на каждой ступени комбинируются таким образом, чтобы всем единицам генеральной совокупности были обеспечены равные шансы попасть в выборку.
В правовых исследованиях наиболее часто используется производственно-территориальная выборка: на первых ступенях отбора в качестве гнезд выступают регионы (области, города, районы и т. д.), а на последних — производственные единицы (предприятия, заводы, цехи, бригады и т. д.).
Как видим, многоступенчатый отбор по своей природе является гнездовым. Под гнездом понимается тот промежуточный объект исследования, который отбирается на каждой ступени для того, чтобы служить исходной совокупностью для последующего отбора.
При многоступенчатом отборе (начиная с двухступенчатой выборки) необходимо учитывать специфику расчета ошибки репрезентативности. Каждая ступень отбора вносит свои отклонения в истинные параметры генеральной совокупности. Расчет ошибок многоступенчатой выборки связан с большими трудностями.
Для достаточно объемной выборки существуют упрощенные формулы расчета ошибки репрезентативности. Упрощение состоит в том, что в математической статистике принято производить расчеты внутригрупповых дисперсий первой ступени отбора после того, как из нее отобраны единицы второй ступени.
Ошибка двухступенчатой выборки исчисляется по формуле:
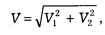
где V1 — ошибка первой ступени, V2 — ошибка второй ступени.
Двухступенчатый отбор был применен в ходе изучения уровня юридических знаний и источников правовой информации населения Ленинграда.*
* Работа проводилась в Научно-исследовательском институте комплексных социальных исследований в 80-х годах.
За основу выборочного исследования были приняты списки жителей в домовых книгах.
Исследователи исходили из предположения, что население города распределяется по районам в относительно случайном порядке. Домовые хозяйства города отбирались в соответствии с таблицами случайных чисел. Из полученных в результате списков отбирался каждый девятый человек. Конечный объем выборки был определен в 3 тыс. человек с учетом того, чтобы в ней были представлены различные группы лиц по социальному положению, полу, возрасту, образованию.
Многоступенчатый отбор использовался при изучении правосознания граждан.*
* В работе принимали участие сотрудники Института государства и права РАН совместно с ВНИИ советского законодательства.
Классические выборочные схемы сформировались под определяющим влиянием запросов экономической и технической практики. Специфика выборочного исследования правовых объектов отражена в этих методах в недостаточной мере. В условиях интенсивного развития социологических исследований возникает потребность в разработке новых приемов и новых математических средств получения выборочных совокупностей.
Совокупность социально-экономических и демографических признаков, детерминирующих исследуемый правовой показатель, должна находиться в выборке в тех же соотношениях, в тех же пропорциях и связях, что ив генеральной совокупности. Достичь такого формирования выборки можно различными путями. При чисто случайном отборе пропорции детермирующих факторов осуществляются автоматически. Однако можно пойти другим путем и отбирать из состава генеральной совокупности такие единицы, которые обладают заданными признаками, и затем из них формировать выборочную совокупность. В этом случае речь идет о методе квот ("квотной выборке").
Для применения метода квот необходимо привлекать обширную статистическую информацию, характеризующую генеральную совокупность. При этом составляются так называемые расчетные таблицы населения по полу, возрасту, образованию и другим признакам. Таблицы показывают, в какой именно пропорции должны быть отобраны единицы выборочного наблюдения.
Метод квот не позволяет использовать аппарат математической статистики, рассчитанный на случайный отбор. Вместе с тем в практике конкретных правовых исследований сформировалось положительное отношение к использованию этого метода как одного из способов отбора единиц наблюдения.
Заключительным этапом выборочного наблюдения является распространение его результатов на генеральную совокупность. При этом необходимо учитывать полноту выборки, т. е. наличие в ней всех типов или групп данной генеральной совокупности. Заметим, что неполнота выборки может привести к нарушению репрезентативности, а стало быть, и к неправильным выводам. В этих случаях прибегают к корректировке выборки.
§ 3. Методы изучения взаимосвязей социально-правовых явлений
Известно, что в явлениях природы существует всеобщая связь. Такая связь наблюдается и в общественных явлениях, включая государство и право. Одна из важных задач правовых конкретно-социологических исследований состоит в изучении причинных и обусловливающих связей. Особая роль здесь принадлежит многофакторному анализу — комплексному исследованию воздействия различных экономических, политических, социальных и иных факторов на социальную обусловленность правовых норм, действенность правовой пропаганды, правового воспитания и т. д.
Математика различает функциональные и статистические связи между величинами. Функциональными называют однозначные связи между двумя и более величинами. В основе математического понятия функциональной связи лежит фундаментальное понятие функции как однозначного соответствия между элементами различных множеств. Функциональные связи более распространены в области естественных и технических наук и только отчасти — в общественных науках.
В отличие от функциональной статистическая связь между величинами представляет собой связь неоднозначную, вероятностную, "размытую" действием различных побочных для данного процесса факторов (так называемых случайных связей). При статистической связи вполне определенному значению одной переменной соответствует одновременно несколько значений другой переменной. Результативный признак реагирует на изменения факторного признака статистическим распределением своих показателей. Эти связи более распространены в общественных науках. Так, для взятого наугад индивида набор параметров, характеризующих его правовые ориентации, знание правовых норм и т. д., не будет однозначно определенным. Данный набор значительно варьирует в пределах группы индивидов с заранее взятыми социально-демографическими характеристиками. Аналогичным образом можно констатировать статистическую связь между возрастом индивидов и степенью приобщенности их к деятельности средств массовой информации и т. д.
Статистическая связь существует между тяжестью совершенного преступления и назначенным наказанием. Факторами, которые делают подобного рода связь статистической, являются: личность осужденного, реальная тяжесть содеянного, условия вынесения приговора по данному делу, учет смягчающих и отягчающих обстоятельств и т. д.
При этом необходимо различать качественные и количественные признаки.
Качественный признак характеризует наличие или отсутствие какого-либо свойства у единиц наблюдения. Например, качественными признаками являются пол, место жительства, семейное положение, социальный статус гражданина. К их числу относится юридическая квалификация действий субъекта по какой-либо статье нормативного акта. В этих случаях нет возможности установить количественный характер исследуемых данных применительно к каждому изучаемому объекту. Он устанавливается только при обсчете единиц всей совокупности.
Примерами количественных признаков могут служить: размер наказания в годах лишения свободы, численность аппарата управления, численность населения, размер территории.
Математические методы и ЭВМ нужны главным образом для того, чтобы изучать социальные явления во взаимосвязи.
Речь идет, например, о разработке таких алгоритмов и программ, которые дали бы возможность изучать количественно меру влияния различных экономических, демографических и иных факторов на государственно-правовые явления. Следовательно, основная задача при разработке программы машинной обработки юридических данных — это автоматизация научного статистического анализа (синтеза) в области права.
В основе многих правовых конкретно-социологических исследований лежит упорядочение исходных данных путем различных статистических группировок. Эти группировки разнообразны: простые, вторичные, аналитические, комбинационные.
Для широкого практического применения в программу ЭВМ следует включить такой относительно простой метод обработки информации и установления связи между параметрами, входящими в предмет исследования проблемы, как метод комбинационных статистических группировок. В этих группировках единицы, образованные сначала по одному признаку, делятся затем на подгруппы по значениям другого признака, т. е. дается "разрез" признаков по различным комбинациям.
В случае многозначности признака исследуемая совокупность может быть разделена на n частей (A1, А2, ... An по признаку А, и затем каждая из полученных групп делится по второму признаку В на т частей: B1, B2,... , Вm. Итого имеем пт заключающих численностей.
Примером комбинационной таблицы может служить корреляция между образованием и предпочтением источника массовой информации о праве (см. табл. 1).
Таблица 1.Образование и предпочтение источника массовой информации о праве*
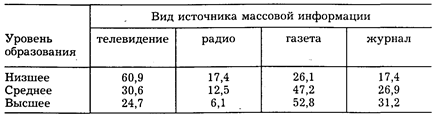
* Сумма процентов на строке превышает 100, так как некоторые респонденты называли одновременно несколько источников.
Метод комбинационных статистических таблиц в некоторых случаях может содержать более полезную информацию, чем коэффициенты связи. При вычислении коэффициентов связи происходит некоторая потеря информации. Так, в строках таблицы могут содержаться весьма характерные распределения статистических показателей, которые нивелируются при исчислении коэффициентов связи.
Метод парных комбинационных группировок дает возможность получить первоначальную информацию о взаимосвязи отдельных статистических показателей, проследить тенденцию изменения результативного признака в зависимости от факторного признака.
Использование количественного подхода и количественных критериев в процессе социологического исследования проблемы эффективности правовой нормы часто требует, получения труднодоступной статистической информации. Надо доказать, что количественные изменения в объекте правового регулирования произошли именно в результате действия этой правовой нормы, а не по каким-либо другим причинам. Собранные статистические данные целесообразно свести в следующую таблицу (см. табл. 2).
Таблица 2.Таблица связи правовой нормы и регулируемых общественных отношении

Перед нами — известная схема математической статистики. В математической статистике такие таблицы используются для исследования взаимосвязи дихотомических признаков.*
* Латинская буква, взятая в скобки, означает число. Латинская буква, стоящая без скобок, означает наименование признака. Так, (А) — число, А — признак.
Первая строка таблицы (строка А) представляет случаи, когда действует новая правовая норма (новый вариант правовой нормы).
Вторая строка таблицы (строка А) представляет случаи, когда новая правовая норма не действует, т. е. когда либо действовала старая правовая норма, либо данное общественное отношение вообще не было урегулировано правом.
Столбец В включает случаи, когда цель правового регулирования достигнута, а столбец 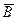 — все остальные случаи.
— все остальные случаи.
Символы во внутренних клетках таблицы имеют значения:
(АВ) — число наблюдаемых случаев достижения цели при условии действия новой нормы;
(А 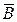 ) — число наблюдаемых случаев недостижения цели при условии действия новой нормы;
) — число наблюдаемых случаев недостижения цели при условии действия новой нормы;
( 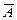 В) — число наблюдаемых случаев достижения цели при условии действия старой нормы;
В) — число наблюдаемых случаев достижения цели при условии действия старой нормы;
( ) — число наблюдаемых случаев недостижения цели при условии действия старой нормы.
При отсутствии зависимости между А и B распределение альтернатив В и в подмножествах (А) и ( ) идентично, и наоборот, изменение распределений В в строках таблицы свидетельствует о наличии зависимости между альтернативами А и В.
Количественным критерием позитивной связи между А и В является выполнение соотношений
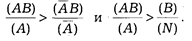
Аналогично для случаев отрицательной связи
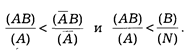
Таблица связи дихотомических признаков дает возможность не только наглядно представить социологические данные, но и сконструировать показатель эффективности — единообразный метод сравнения эффективности одной и той же нормы в разных социальных условиях или же эффективности разных норм в одних и тех же условиях.
Наиболее приемлемым будет такой коэффициент, который равен 0, если новая норма не изменяет состояния регулируемого объекта, и равен +1 при ее полной эффективности. Он будет иметь отрицательные значения, когда норма приводит к обратным по сравнению с намеченными результатам. Наконец, он. будет равен -1 в случаях, когда между действием нормы и состоянием регулируемого объекта имеется полная отрицательная связь.
Таким условием в наибольшей степени удовлетворяет коэффициент взаимосвязи дихотомических признаков, предложенный известным английским статистиком Юлом:
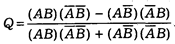
Приведем условный пример расчета коэффициента Юла на практике. Пусть в нашу задачу входит измерение эффективности применения к нарушителям дисциплины труда некоторой санкции: например выговора. Индикатором достижения цели в данном случае может быть уровень повторных нарушений дисциплины труда, допущенных теми же лицами. В нашем распоряжении имеются следующие данные (см. табл. 3).
Таблица 3.Эмпирические данные, характеризующие связь между действием санкции и совершением нового нарушения (пример)

Сначала проведем испытание наших данных на независимость. Критерием независимости двух признаков является выполнение соотношения
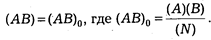
Испытание на независимость сводится к следующему. Сначала мы найдем величину (АВ)0, затем (АВ). Если они не равны друг другу, то можно говорить о том, что исследуемые нами явления независимы. По данным таблицы 3 имеем:
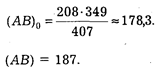
Величина (АВ)0 показывает, по существу, какой должна быть численность лиц, повторно совершивших нарушения дисциплины труда, если уровень рецидива не зависел бы от применения санкции.
В нашем примере величины (АВ) и (АВ)0 не равны.* Следовательно, гипотеза о независимости исследуемых признаков не подтверждается. Между действием санкции и вероятностью последующего правонарушения имеется статистическая связь.
* Для подтверждения неслучайного характера, несовпадения (АВ) и (АВ)д следует прибегнуть к применению методов проверки статистических гипотез.
Из соотношения
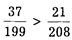
следует сделать вывод о том, что в данном случае связь между признаками А и В положительная.
Рассчитаем теперь точную меру эффективности данной санкции. Используем для этого формулу коэффициента Юла:
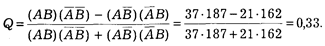
Мы видим, что положительная связь между действием санкции и числом повторных нарушений является довольно ощутимой.
Математическая статистика располагает обширным аппаратом измерения статистических связей. Так, в социально-правовом исследовании довольно часто возникает задача измерения связей многозначных признаков, т. е. таких, каждый из которых имеет несколько значений (градаций). В математической статистике разработан комплекс методов измерения взаимосвязи многозначных признаков. Применяются следующие меры оценки взаимосвязи:
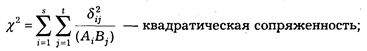
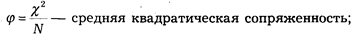
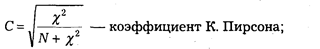
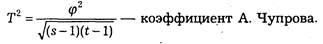
При составлении программного задания для ЭВМ некоторые исследователи стремятся включить как можно большее число сопоставлений одних показателей с другими. К такой тенденции следует относиться с осторожностью.
При обработке социологической анкеты с та признаками число коэффициентов связи, которые могут быть вычислены, равно:
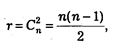
где 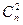 — число сочетаний из n элементов по 2. Так, n = 10, r = 45; n = 20, r = 190 и т. д.
— число сочетаний из n элементов по 2. Так, n = 10, r = 45; n = 20, r = 190 и т. д.
Отсюда видно, какой огромный запас производной информации скрыт даже в небольшой социологической анкете.
В ряде случаев исходные эмпирические данные имеют количественный характер, который допускает непосредственное измерение какого-либо свойства у каждого из наблюдаемых индивидов или объектов (возраст, образование, душевой доход, число совершенных в определенной местности и за определенный период преступлений и т. д.).
Показателем связи количественных признаков является коэффициент корреляции. Он вычисляется по формуле:
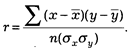
В этой формуле приняты следующие обозначения:
r — коэффициент корреляции;
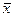 — значение первого признака;
— значение первого признака;
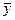 — значение второго признака;
— значение второго признака;
х — средняя величина из значений первого признака;
у — средняя величина из значений второго признака;
å — знак суммирования;
sx — отклонение от средней величины первого признака;
sy — отклонение от средней величины второго признака;
п — общее число наблюдений.
Корреляционный анализ дает ответ на вопрос, какова степень тесноты связи. Используя коэффициент корреляции, можно определить роль каждого фактора в формировании результативного признака.
Вместе с тем, в процессе исследования взаимосвязей количественных показателей можно поставить и другую задачу. Это задача определения формы связи двух переменных. Необходимо решить вопрос: как, исходя из наблюдений над факторным признаком, определить соответствующее значение результативного признака? Это задача регрессионного анализа.
Уравнение регрессии устанавливает форму связи между факторным и результативным признаками. Эта связь может быть линейной или криволинейной. Если линия регрессии прямая, то говорят, что она линейна. Если линии регрессии имеют ту или иную форму кривых линий, то говорят, что регрессия криволинейна.
Используя данную и подобные ей модели, можно дать, например, математическое описание взаимосвязи между ростом численности населения определенного региона и динамикой соответствующего числа преступных проявлений.
Для того чтобы составить уравнение регрессии, надо найти его коэффициенты. Для нахождения коэффициентов уравнения регрессии в математической статистике используется особый метод, который называется методом наименьших квадратов. Он позволяет наилучшим образом подобрать к эмпирическим данным описывающую их линию (кривую, прямую).
Методы корреляционного анализа применялись для изучения связей между жесткостью судебной репрессии и состоянием судимости.* В целях количественного выражения жесткости применялся особый коэффициент, который вычислялся по формуле
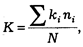
где ki — коэффициент жесткости отдельных видов наказания; пi — число осужденных к каждому виду наказания; N — общее число осужденных.
* Одной из ранних работ по применению корреляционного анализа в сфере права было криминологическое исследование В. Н. Куфаева (1929 г.). На большом эмпирическом материале он вычислил коэффициенты корреляции между неурожаями и состоянием преступности в дореволюционной Самарской губернии. Эти коэффициенты оказались довольно высокими.
В этом исследовании использовались статистические данные четырех стран. СНГ за девять лет. Коэффициенты корреляции по каждой из взятых стран оказались следующими:
+0,07; -0,40; -0,63; -0,65.
Из приведенных данных вытекает; что в двух странах СНГ имеется четко выраженная обратная корреляционная связь между коэффициентами судимости и жесткостью судебной репрессии.
Методы корреляционного анализа использовались также для изучения статистической зависимости, которая существует между сроком отбытого наказания и совершением нового преступления. В результате обработки эмпирических данных методами математической статистики было получено уравнение регрессии, характеризующее связь между числом лиц,. не совершивших нового преступления после отбытия наказания, и сроком отбытого наказания. Это уравнение имеет следующий вид:
у = 65,0 – 4,3x,
где у — удельный вес лиц, не совершивших нового преступления после отбытого наказания; х — срок отбытого наказания. В соответствии с данным уравнением увеличение срока отбытого наказания на один год приводит к повышению доли лиц, не совершивших нового преступления, на 4,3%. В целях измерения тесноты связи между указанными переменными было также рассчитано корреляционное отношение, которое в данном случае оказалось равным 0,9898. Другими словами, установлена такая связь, которая практически является функциональной.
Сотрудники НИИ проблем укрепления законности и правопорядка Генеральной прокуратуры РФ В. И. Шинд и В. П. Рябцев выполнили большое статистическое исследование по определению штатной численности прокурорских работников районного (городского) звена территориальных органов прокуратуры.
В результате расчетов на ЭВМ было получено уравнение регрессии.
Формула уравнения регрессии имеет следующий вид:
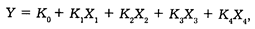
где Y — искомая штатная численность прокурорских работников районного (городского) звена территориальных органов прокуратуры;
X1 — число зарегистрированных преступлений за год;
Х2— численность населения (в тыс. чел.);
Х3 — число юридических лиц;
Х4 — размер территории (площадь в тыс. кв. км);
К0 — свободный член для расчета штатной численности прокурорских работников районного звена;
К1, К2, К3, К4 — коэффициенты при численном значении каждого фактора.
В результате применения ЭВМ были получены следующие коэффициенты уравнения регрессии:
К0 — 0,8 — величина' свободного члена;
К1 — 0,004710 — коэффициент при численном значении преступности;
К2 — 0,009550 — коэффициент при численном значении населения;
K3 — 0,00910 — коэффициент при численном значении юридических лиц;
К4 — 0,027120 — коэффициент при численном значении территории региона.
Зная официальные статистические данные (число районов, преступность, численность населения, число юридических лиц — "поднадзорных объектов", площадь региона) и перемножив эти факторы —аргументы на приведенные коэффициенты по указанной выше формуле, можно рассчитать потребную штатную численность прокуроров, их заместителей и помощников для любого региона Российской Федерации. Выполненная работа позволила сделать очень важные практические выводы.
§ 4. Создание и эксплуатация автоматизированных информационно-поисковых систем (АИПС) по статистике
Для эффективного использования данных правовой статистики в правотворческой деятельности принципиальное значение имеет компьютеризация данной сферы. Федеральная целевая программа "Реформирование статистики в 1997—2000 гг." предусматривает в числе других мероприятий компьютеризацию всех отраслей социальной статистики, включая правовую.*
* Утверждена постановлением Правительства РФ № 1410 от 23 ноября 1996 г. // СЗ РФ. 1996. № 50. Ст. 5657.
Применение в сфере правовой статистики средств вычислительной техники позволяет:
1. Устранить противоречие между огромным количеством "сырых" статистических материалов, которые могут быть использованы в правотворческом процессе, и реальным объемом информации, привлекаемой в данную сферу для повышения эффективности правотворческих решений.
2. Существенно расширить применение для обработки статистических данных современных математических методов. Алгоритм обработки статистической информации включает:
упорядочение (ранжирование) статистических данных по какому-либо показателю;
построение рядов распределений;
вычисление средних величин и мер, характеризующих отклонение от средней (дисперсий и средних квадратических отклонений);
применение методов факторного анализа или распознавания образов.
3. Выполнить в кратчайшие сроки громоздкие подсчеты, касающиеся отдельных статистических показателей (например, подсчет числа отдельных видов преступлений — краж, убийств и т. д.).
4. Эффективно использовать метод моделирования, основанный на действии в статистических совокупностях закона больших чисел.
5. Проверять на большом статистическом материале некоторые параметры законопроекта (вновь вводимых понятий) в целях уточнения их количественных характеристик (например, понятий "тяжкое преступление", "рецидивист", число пенсионеров определенной категории).
6. Делать выборку из больших массивов статистической информации.
7. Накапливать статистическую информацию за многие годы и выдавать ее для использования в деятельности законодательных органов.
Математические средства и ЭВМ применяются для обработки массовой криминологической информации, получения сводных данных о состоянии преступности, личности преступника, причинах преступлений, эффективности мер уголовного наказания и др.
В правоохранительных органах все методы обработки статистических данных основаны на использовании автоматизированных информационных систем.
Процесс обработки статистической информации представляется в виде тех
Дата добавления: 2020-12-11; просмотров: 737;
Поиск по сайту
Узнать еще
- I. Определение и структура методов обучения.
- I. Определение условий выполнения рукописи.
- I. Определение, виды радиоактивности, радиоактивные семейства
- Mатематическое определение ОС.
- А) Деградация почв и определение ее скорости
- Аксиоматическое определение множества действительных чисел
- АЛГОРИТМ И ЕГО СВОЙСТВА. Определение алгоритма
- Анализ влияния показателей интенсификации на изменение объема выпуска продукции

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
