Тема 3.8 MySQL. Выборка данных. Многотабличные запросы
Рассмотренные до этой главы SQL-запросы использовали одну таблицу. Но в реальныхприложениях часто требуется использовать сразу несколько таблиц базы данных. Запросы, которые обращаются одновременно к нескольким таблицам, называются многотабличными запросами. Именно в таких запросах проявляется одно из преимуществ реляционных баз данных — связь таблиц друг с другом.
Перекрестное объединение таблиц
Для обсуждения многотабличных запросов создадим две таблицы: tbll и tbl2, каждая из которых будет содержать два столбца — числовой и текстовый. В листинге 22.1 представлены операторы create table, создающие указанные таблицы.
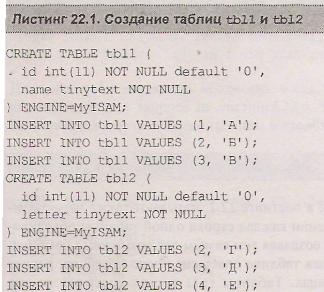
После создания таблиц заполним каждую таблицу тремя записями, состоящими из целого числа и соответствующей ему буквы русского алфавита.
Для осуществления запроса сразу к нескольким таблицам их имена перечисляются после ключевого слова from через запятую. В листинге 22.2 представлена выборка из каждой таблицы, а также двухтабличный запрос с использованием оператора select к таблицам tbll, tbl2.

Двухтабличный запрос, представленный в листинге 22.2, называют также перекрестным объединением. При таком объединении каждая строка одной таблицы объединяется с каждой строкой другой таблицы, создавая тем самым все возможные комбинации строк обеих таблиц. Результирующая таблица содержит число столбцов, равное сумме столбцов в объединяемых таблицах. Таблицы tbll иtbl2 содержат по два столбца, поэтому результирующая таблица содержит 4 столбца (2 + 2 = 4). Число записей в результирующей таблице определяется произведением числа записей в таблицах, участвующих в многотабличном запросе (3*3 = 9).

Однако если в результирующую таблицу добавить столбец id, который входит в состав обеих таблиц, СУБД MySQL вернет ошибку — неоднозначность поля id в списке полей (листинг 22.4).

Для того чтобы исключить неоднозначность, т. е. определить, поле id какой таблицы имеется в виду в запросе из листинга 22.4, прибегают к полным именам столбцов. Полное имя включает имена таблицы и столбца, разделенные точкой (листинг 22.5).


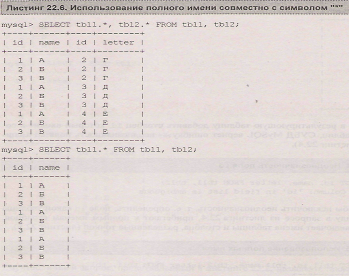
Для символа "*", указывающего на необходимость выборки всех столбцов таблицы, также можно использовать полное имя: tbll. * и tbi2. * (листинг 22.6).
Замечание_____________________________________________
Полные имена можно использовать для обращения не только в пределах одной базы данных, но и для объединения таблиц из двух разных баз данных. Для этого полное имя столбца предваряется именем базы данных. Если таблицы tbll и ti: расположены в базах данных dbl и db2, то к столбцам name и letter можно осветиться по именам dbl.tbll.name и db2.tbl2.letter соответственно. При этог.' ш звания таблиц следует также записывать полным именем: dbl. tbll и db2. tbl2.

Еще одним эффективным способом ограничения числа столбцов является группировка результата выборки по одному из полей при помощи конструкции group by (листинг22.8).

При работе с результирующей таблицей в прикладных программах часто бывает неудобно работать с полными именами столбцов. Поэтому прибегают к назначению псевдонимов при помощи оператора as. В листинге 22.9 полному имени tbll.id назначается псевдоним id, имени tbll.name — name, a tbl2. letter — letter.

Оператор as может использоваться не только для назначения псевдонимов столбцам, но и для назначения псевдонимов таблицам. В листинге 22.10 таблицам tbll и tbl2 назначаются псевдонимы tl и t2 соответственно. Такой подход позволяет использовать в качестве имен таблиц более короткие имена, что приводит к более короткому SQL-запросу.

Замечание_______________________________________
После назначения псевдонимов таблицам, участвующим в запросе, использовать исходные имена таблиц в конструкциях where, group by, order by исписке столбцов после ключевого слова select уже не допускается.
Кроме того, такое назначение псевдонимов позволяет осуществлять многотабличные запросы к одной таблице. Такие запросы называют еще самообъединением таблицы. Для этого достаточно назначить одной и той же таблице разные псевдонимы (листинг 22. 11).

Рассмотрим более реальный пример. Пусть требуется вывести названия и цены всех товарных позиций каталога, которому принадлежит товарная позиция 'Maxtor 6Y120PO'. I То есть, обнаружив в нашем магазине один жесткий диск, мы хотим выяснить, какие еще жесткие диски имеются в продаже и сравнить их по цене. Данную задачу решает запрос, представленный в листинге 22.12.
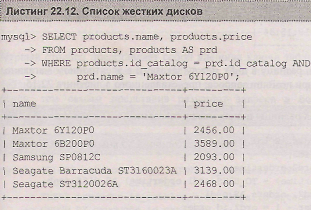
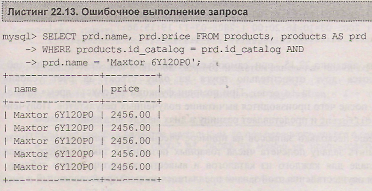
В листинге 22.12 происходит самообъединение таблицы products, при этом в полных именах списка столбцов после ключевого слова select следует использовать имя таблицы, не участвующей в сравнении со строкой 'Maxtor 6Y120P0', иначе будет возвращено пять строк с данным названием (листинг 22.13).
Другим применением самообъединения является вычисление разницы между последовательными строками. В листинге 22.14 представлено содержимое таблицы orders.
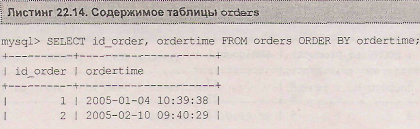

Пусть требуется вычислить разницу в днях между заказами в электронном магазине. Решить эту задачу можно при помощи запроса, представленного в листинге 22.15.
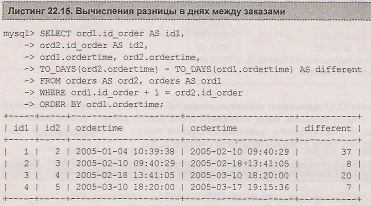
Как видно из листинга 22.15, при самообъединении таблицы orders копии таблицы смещаются друг относительно друга на одну строку за счет условия ordl. id_order + 1 = ord2. id_order. При помощи функции TO_DAYS () время приводится к дням, после чего производится вычитание полученных результатов. Полученное значение different и представляет разницу в днях между заказами.
Рассмотрим еще несколько запросов на примере учебной базы данных shop. Пусть требуется решить задачу подсчета числа товарных позиций, а также общего числа товара на складе для каждого из каталогов и вывести результирующую таблицу. В главе 19 для осуществления этой задачи предлагался запрос, представленный в листинге 22.16.


Первый столбец представляет собой внешние ключи таблицы catalogs, по которым можно восстановить названия каталогов. При помощи многотабличного запроса к таблицам products иcatalogs вместо данного столбца можно вывести названия каталогов, тем самым представив результат запроса в более удобном виде (листинг 22.17).

Обязательным условием в данном запросе является равенство полей id_catalog таблиц products и catalogs (products.id_catalog = catalogs.id_catalog). Именно при помощи данного условия осуществляется связь этих двух таблиц.
Замечание_________________________________________
Если имя столбца является уникальным, то при перечислении его в списке столбцов и конструкциях where, GROUP BY, order BY можно не использовать полное имя столбца.
Среди таблиц учебной базы данных shop примечательной таблицей является таблица orders (листинг 22.18), которая содержит внешний ключ id_product для связи с таблицей products и внешний ключ id_user для связи с таблицей users. Поэтому, чтобы результирующая таблица содержала данные заказа, фамилию покупателя и название товара, требуется осуществить трехтабличный запрос.
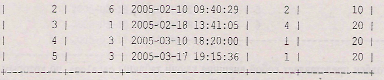
Запрос, результирующая таблица в результате выполнения которого содержит вместо внешних ключей id_user и id_product фамилию покупателя и название товарной позиции, представлен в листинге 22.19.
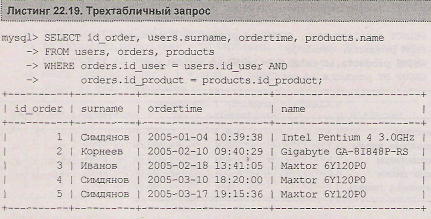
Помимо того, что после ключевого слова from требуется указать три таблицы: users, orders и products, WHERE-условие должно включать две связи: таблицы order; с users и orders с products.
Если, кроме представленной в листинге 2.19 информации, в результирующую таблицу необходимо поместить столбец с названием каталога, к которому относится выбранный товар, потребуется осуществить четырехтабличный запрос, представление в листинге 22.20.
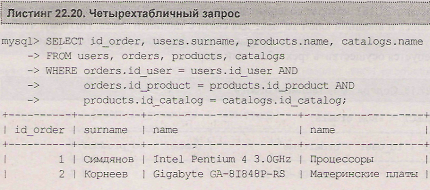

Здесь, помимо связи таблицы orders с таблицами users и products, добавляется третья связь таблицы products с таблицей catalogs (products.id_catalog = catalogs. id__catalog).
С увеличением количества таблиц в запросе резко возрастает объем работы, необходимой для выполнения запроса, поэтому по возможности в запросе не следует использовать больше трех-четырех таблиц.
22.2. Объединение таблиц при помощи JOIN
Оператор join позволяет объединять таблицы и имеет многочисленные варианты использования, которые будут рассмотрены далее на протяжении данного раздела.ВSQL-запросе данный оператор располагается между именами объединяемых таблиц [осле ключевого слова from. Без дополнительных ключевых слов объединение при помощи ключевого слова join аналогично перекрестному объединению таблиц, рассмотренному в разделе 22.1.

Запросы, представленные в листинге 22.21, полностью идентичны. Для формирования условия в запросах, использующих объединение join, вместо ключевого слова ere предпочтительно использовать ключевое слово on, как это продемонстрированыв листинге 22.22

Замечание_____________________________________
Ключевое слово join имеет два синонима: CROSS JOIN и INNER JOIN.
Помимо перекрестного объединения таблиц, предусмотрено левое и правое объединение таблиц, которое осуществляется при помощи конструкций left join right join соответственно.
В листинге 22.21 продемонстрировано перекрестное объединение таблиц tbll и tb.При этом результирующая таблица содержит комбинации строк обеих таблиц, удовлетворяющих условию tbll.id = tbi2.id. Левое объединение (left join) позволяет включить в результирующую таблицу строки "левой" таблицы tbll, которым не нашлось соответствия в "правой" таблице tbl2 (листинг 22.23).

Как видно из листинга 22.23, записи в таблице tbll со значением id = 1 не нашло соответствия в таблице tbl2, т. к. поле id в ней принимает значения 2, 3, 4. Тем менее в результирующую таблицу запись включена, при этом значения полей из таблицы tbl2 принимают значение null. Следует заметить, что для задания условия вместо ключевого слова where при левом и правом объединениях используется ключе! слово on.
В листинге 22.24 демонстрируется "правое" объединение при помощи конструктора
RIGHT JOIN.


Как видно из листинга 22.24, при правом объединении возвращаются строки, удовлетворяющие условию tbii.id = tbi2.id, и строки "правой" таблицы tbi2, которым не нашлось соответствия в "левой" таблице tbil.
Замечание________________________________________
Ключевые слова left join и right join имеют синонимы left outer join и right outer join соответственно.
Другим способом установки связи между таблицами tbil и tbl2 при правом и левом объединениях является использование ключевого слова usingo. В круглых скобках, следующих за этим ключевым словом, перечисляются имена столбцов, которые должны присутствовать в обеих таблицах и для которых необходимо соблюдение равенства. Данный оператор предназначен для создания более компактных SQL-запросов. Так, следующие два выражения идентичны:

Принимая во внимание синтаксис ключевого слова usingo, левое и правое объединения, показанные в листингах 22.23 и 22.24, можно представить так, как это сделано в листинге 22.25.

Для каждой из таблиц, участвующих в объединении с использованием SQL-оператора join, можно ввести подсказку о том, как СУБД MySQL должна использовать индексы при извлечении данных из таблицы. Указав после имени таблицы ключевое слово USE index (list), в скобках можно задать список индексов list, которые СУБД MySQL должна использовать при поиске записей в таблице. Ключевое слово ignore index (list) предназначено для того, чтобы запретить СУБД MySQL использовать какой-то отдельный индекс. Ключевое слово force index (list) подобно use index (list), но с тем отличием, что сканирование таблицы расценивается как очень дорогая операция. Это учитывается оптимизатором MySQL, и полное сканирование таблицы производится только в том случае, если нет возможности использовать индекс.
Возвращаясь к учебной базе данных shop, рассмотрим несколько запросов к таблицам, входящим в ее состав. В листинге 22.26 при помощи конструкции join ... using () извлекается число товарных позиций в каталогах.

Допустим, происходит расширение ассортимента товарных позиций и в списке каталогов появляется новый каталог 'Периферия. SQL-запрос, добавляющий данный каталог, представлен в листинге 22.27.

Однако запрос из листинга 22.26 не отражает наличие нового каталога в электронном магазине, т. к. таблица products еще не содержит ни одной записи, относящейся к новому каталогу. Для того чтобы название каталога 'Периферия' появилось в результирующей таблице, необходимо провести левое объединение таблиц catalogs и products, причем таблица catalogs должна выступать в качестве "левой" таблицы.

Как видно из листинга 22.28, левое объединение позволило включить каталог 'Периферия', товарные позиции в котором пока отсутствуют.
Пусть требуется вывести список покупателей и число осуществленных ими покупок, причем покупателей необходимо отсортировать в порядке убывания числа оплаченных ими заказов. Для решения этой задачи можно воспользоваться запросом, представленным в листинге 22.29.
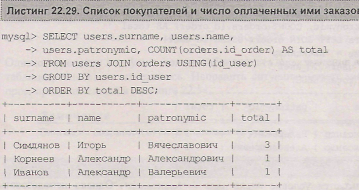
Как видно из листинга 22.29, в списке присутствуют только те покупатели, которые оплатили хотя бы одну покупку, покупатели, на счету у которых нет ни одной покупки, в список не входят. Для того чтобы вывести полный список покупателей, необходимо вместо перекрестного объединения таблиц users и orders воспользоваться левым объединением, где в качестве "левой" таблицы выступит таблица users (листинг 22.30).
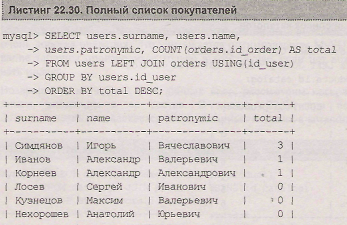
Помимо условия on или using, в запросах на объединение могут использоваться традиционные конструкции условия. Например, запрос, представленный в листинге 22.31, извлекает список покупателей и число их покупок при условии, что покупателя зовут "Александр".

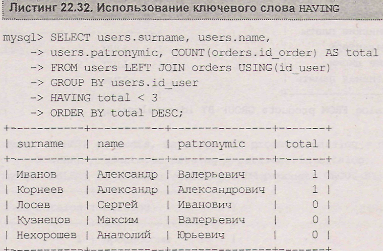
Для этого используется условие WHERE name = 'Александр'. Однако использовать столбец total в условии where уже не получится, т. к. это групповой столбец, сформированный агрегатной функцией count () и конструкцией group by. Для формирования условия с его участием необходимо использовать условие having. Пусть требуется извлечь всех покупателей магазина, число покупок (total) у которых меньше трех (листинг 22.32)
Обновление нескольких таблиц
Помимо оператора select, в многотабличных запросах можно использовать оператор update. Для этого имена таблиц перечисляются через запятую. Пусть требуется изменить первичный ключ id^catalog таблицы catalogs для каталога 'Оперативная память' с 5 на 10. Для этого можно использовать запрос, представленный в листинге 22.33.

Однако изменения коснулись только таблицы catalogs, значения внешних ключей в таблице products не изменились. Исправить ситуацию может многотабличный запрос, представленный в листинге 22.34.

Замечание_______________________________________
Синтаксис оператора update описывается в главе 9.

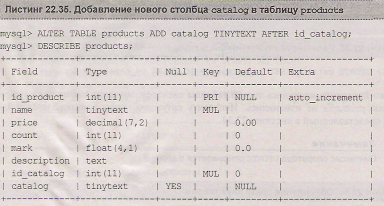
Пусть в таблицу products требуется добавить столбец catalog, который необходимо заполнить названиями каталогов из таблицы catalogs. Добавить новый столбец можно при помощи оператора alter table (листинг 22.35), синтаксис которого подробно рассматривается в главе 10.
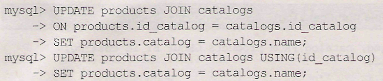
Однако поле catalog внастоящий момент является пустым, для того чтобы заполнить его, можно прибегнуть к многотабличному запросу update (листинг 22.36).

Как видно из листинга 22.36, таблица catalogs не подвергается изменениям, но активно участвует в многотабличном запросе с участием оператора update.
Замечание________________________________________
В многотабличных запросах с участием SQL-оператора update не допускается использование конструкций ORDER BY И LIMIT.
Замечание _________________________
Многотабличные запросы с участием SQL-оператора UPDATE введены в СУБД MySQL, начиная с версии 4.0.0.
Рассмотренные выше примеры используют перекрестное объединение, но многотабличные запросы с участием оператора update допускают любой тип объединения, продемонстрируемте ранее на примере оператора select. В листинге 22.37 приводятся три запроса, идентичные представленному в листинге 22.36.

Точно так же, как и в случае оператора select, допускается использование псевдонимов для таблиц, которые назначаются при помощи оператора as (листинг 22.38).

22.4. Удаление из нескольких таблиц
Многотабличное удаление из таблиц при помощи оператора delete во многом аналогично операторам select и update.
Замечание________________________________________
В многотабличных запросах с участием SQL-оператора delete не допускается использование конструкций ORDER BY И LIMIT.
Замечание________________________________________
Многотабличные запросы с участием SQL-оператора DELETE введены в СУБД MySQL, начиная с версии 4.0.0.
При использовании многотабличных запросов с помощью оператора delete допустимы две формы, представленные в листинге 22.39, где из таблицы products удаляются все записи, для которых имеется соответствие в таблице catalogs.

Следует отметить, что записи касаются только таблицы products — удаление производится лишь из таблиц, перечисленных после ключевого слова delete в первой форме запроса, и после ключевого слова from во второй форме запроса. Запросы, представленные в листинге 22.40, затронут уже обе таблицы.


Продемонстрированные выше примеры используют перекрестное объединение, хотя многотабличные запросы с участием оператора delete допускают любой тип объединения, рассмотренные ранее на примере оператора select.
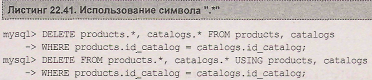
Для достижения совместимости с Access в многотабличных операторах delete допускается использование символа ".*" после имени таблицы (листинг22.41).
При использовании псевдонимов таблиц, назначаемых оператором as, в СУБД MySQL 4.0 необходимо обращаться к таблицам с помощью реальных имен (листинг 22.42).

Начиная с версии СУБД MySQL 4.1, псевдонимы требуется использовать в тексте всего оператора delete (листинг 22.43).

Дата добавления: 2020-11-18; просмотров: 1327;
Поиск по сайту
Узнать еще
- Altium Designer (Protel) - сквозная система проектирования печатных плат
- B). Система относительных координат.
- DSM — система классификации Американской психиатрической ассоциации
- I. Математические понятия
- II. НАЛОГОВАЯ СИСТЕМА В СОВРЕМЕННОЙ РОССИИ
- II. Научность, систематичность и последовательность обучения.
- II. Формализация процесса формирования математических моделей
- Mатематическое определение ОС.

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
