Суть вибіркового спостереження
§ Вибірковим називається таке спостереження, яке дає характеристику всієї сукупності одиниць на основі дослідження її частини.
Не завжди можна використовувати суцільне спостереження і тоді використовують вибіркове спостереження. Крім того воно використовується для уточнення результату суцільного спостереження (наприклад, при переписі 1979 року поруч із суцільним спостереженням певну групу людей досліджували спеціально за більш розширеними анкетами). Крім того вибіркове спостереження використовується при експериментах в природничих науках. Має воно використання і в таких економічних галузях дослідження, як митне обстеження якості продукції.
Основні завдання вибіркового спостереження такі:
1) вивчення середнього розміру досліджуваної ознаки;
2) вивчення питомої ваги (частки) досліджуваної ознаки в сукупності.
Основні поняття вибіркового методу такі.
Розрізняють генеральну сукупність і вибіркову сукупність. Генеральна сукупність – це загальна сукупність одиниць, з якої проводиться відбір. А вибірковою називається частина генеральної сукупності, яка підлягає обстеженню.
Обсяг генеральної сукупності позначають через літеру N. Обсяг вибіркової сукупності – n. Відповідно генеральна середня позначається: 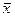 , а середня вибіркова -
, а середня вибіркова - 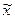 . Звісно, що генеральна і вибіркова середні не співпадають. Це пов'язано з помилкою репрезентативності.
. Звісно, що генеральна і вибіркова середні не співпадають. Це пов'язано з помилкою репрезентативності.
Гранична помилка репрезентативності 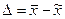 , або
, або 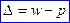 , де w – частка досліджуваної ознаки в генеральній сукупності, а p – частка досліджуваної ознаки в вибірковій сукупності).
, де w – частка досліджуваної ознаки в генеральній сукупності, а p – частка досліджуваної ознаки в вибірковій сукупності).
Точність результатів вибіркового методу залежить від
- способу відбору одиниць,
- ступеня коливання ознаки у сукупності,
- числа одиниць, що спостерігаються.
Отже, вибіркове спостереження— такий вид несуцільного спостереження, при якому обстежуються не всі елементи сукупності, що вивчається, а лише певним чином дібрана їх частина. Сукупність, з якої вибирають елементи для обстеження, називається генеральною, а сукупність, яку безпосередньо обстежують, — вибірковою. Статистичні характеристики вибіркової сукупності розглядаються як оцінки відповідних характеристик генеральної сукупності.
Практика вибіркових спостережень досить різноманітна. Це обстеження домогосподарств, маркетингові дослідження, аудиторські перевірки великих фірм, вивчення громадської думки тощо. При обстеженні невеликої частини генеральної сукупності зменшуються помилки реєстрації, можна розширити й деталізувати програму обстеження. З іншого боку, вибіркове спостереження забезпечує економію матеріальних, трудових, фінансових ресурсів і часу.
При вивченні певного кола соціально-економічних явищ вибіркове спостереження єдино можливе. Це стосується передусім перевірки якості продукції (жирності молока, чистоти та вологості зерна, міцності пряжі тощо). Часом вибіркове спостереження поєднується із суцільним. Наприклад, при перепису населення кожна четверта одиниця спостереження дає докладнішу інформацію. Крім того, вибірковий метод використовують для прискореної обробки матеріалів суцільного спостереження та перевірки правильності даних переписів і одноразових обстежень.
Об’єктивною гарантією того, що вибірка репрезентує (представляє) всю сукупність, є додержання наукових принципів організації та проведення спостереження, насамперед неупередженого, об’єктивного підходу до вибору елементів для обстеження. Принцип випадковості вибору забезпечує всім елементам генеральної сукупності рівні можливості потрапити у вибірку.
Якщо генеральна сукупність містить N елементів, а для обстеження потрібно вибрати з них частину n, то кількість можливих вибірок становить:
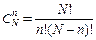 .
.
Усі вони мають однакову ймовірність 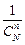 , але кожна з них несе в собі певну похибку, що відбиває факт випадковості вибору. Оскільки вибіркова сукупність не точно відтворює склад генеральної сукупності, то й вибіркові оцінки не збігаються з відповідними характеристиками генеральної сукупності. Розбіжності між ними називають похибками репрезентативності: для середньої — це різниця між генеральною
, але кожна з них несе в собі певну похибку, що відбиває факт випадковості вибору. Оскільки вибіркова сукупність не точно відтворює склад генеральної сукупності, то й вибіркові оцінки не збігаються з відповідними характеристиками генеральної сукупності. Розбіжності між ними називають похибками репрезентативності: для середньої — це різниця між генеральною 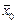 та вибірковою
та вибірковою 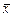 середніми, для частки — різниця між генеральною
середніми, для частки — різниця між генеральною 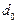 і вибірковою р частками, для дисперсії — відношення генеральної
і вибірковою р частками, для дисперсії — відношення генеральної 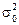 та вибіркової
та вибіркової 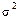 дисперсій тощо.
дисперсій тощо.
За причинами виникнення похибки репрезентативностіподіляються на тенденційні(систематичні) та випадкові. Тенденційні похибки виникають, коли при формуванні вибіркової сукупності порушений принцип випадковості (упереджений вибір елементів, недосконала основа вибірки тощо). Ці похибки для всіх елементів сукупності однонапрямлені і призводять до зсунення результатів обстеження.
Випадкові похибки — це наслідок випадковості вибору елементів для дослідження і пов’язаних з цим розбіжностей між структурами вибіркової та генеральної сукупностей щодо ознак, які вивчаються.
При організації вибіркового обстеження важливо уникнути тенденційних похибок. Незсуненість — одна з вимог до будь-якої вибіркової оцінки. Притаманних вибірковому спостереженню випадкових похибок уникнути неможливо, проте теорія вибіркового методу дає математичну основу для обчислення таких похибок та регулювання їх розміру.
Згідно з генеральною граничною теоремою за умови достатньо великого обсягу вибірки розподіл вибіркових середніх (і часток), незалежно від розподілу генеральної сукупності, асимптотично наближається до нормального. Більшість значень вибіркових середніх зосереджується навколо генеральної середньої, а отже, найбільшу ймовірність мають відхилення, близькі до нуля. Чим більше відхилення, тим менша його ймовірність. Для будь-якої ймовірності існує межа відхилень вибіркової середньої від генеральної. Використовуючи властивості нормального розподілу, для однієї конкретної вибірки можна визначити:
· похибки репрезентативності — середню та граничну для взятої ймовірності;
· імовірність того, що похибка вибірки не перевищить допустимого рівня;
· обсяг вибірки, який забезпечить потрібну точність результатів для взятої ймовірності.
Кінцева мета будь-якого вибіркового спостереження — поширення його характеристик на генеральну сукупність. Для середньої та частки визначаються межі можливих їх значень у генеральній сукупності з певною ймовірністю — довірчі межі. Якщо метою вибіркового обстеження є визначення обсягових показників генеральної сукупності — обсягів значень ознаки 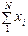 , то вибіркова середня поширюється на генеральну сукупність прямим перерахунком:
, то вибіркова середня поширюється на генеральну сукупність прямим перерахунком: 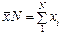 .
.
Наприклад, загальна посівна площа під круп’яними культурами в районі становить 2000 га. За даними вибіркового обстеження середня врожайність круп’яних культур — 22,5 ц/га, похибка середньої — 0,5 ц/га. Отже, можливий обсяг валового збору зерна з цієї площі буде не менший за 44 тис. ц [(2000 (22,5 – 0,5)]. Максимальний валовий збір — 46 тис. ц [(2000 (22,5 + 0,5)].
коли вибіркове спостереження проводиться з метою уточнення результатів суцільного спостереження, застосовується метод коефіцієнтів. Наприклад, після щорічного перепису худоби, що належить населенню, проводиться 10%-ний вибірковий контроль, мета якого — визначити частку недообліку худоби. За даними перепису в районі налічується 10000 корів. У домогосподарствах, які потрапили до контрольної вибірки, за переписом 200 корів, а за даними перевірки — 205. Отже, частка недообліку корів становить 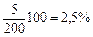 . Це і є той коефіцієнт, на який слід скоригувати результати перепису: 10000 · 1,025 = 10250 корів.
. Це і є той коефіцієнт, на який слід скоригувати результати перепису: 10000 · 1,025 = 10250 корів.
5.2. Вибіркові оцінки середньої та частки
У статистиці використовують два типи оцінок параметрів генеральної сукупності — точкові та інтервальні. Точкова оцінка — це значення параметра за даними вибірки: вибіркова середня 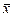 та вибіркова частка р. Інтервальною оцінкою називають інтервал значень параметра, розрахований за даними вибірки для певної ймовірності, тобто довірчий інтервал. Чим менший довірчий інтервал, тим точніша вибіркова оцінка.
та вибіркова частка р. Інтервальною оцінкою називають інтервал значень параметра, розрахований за даними вибірки для певної ймовірності, тобто довірчий інтервал. Чим менший довірчий інтервал, тим точніша вибіркова оцінка.
Межі довірчого інтервалу визначаються на основі точкової оцінки та граничної похибки вибірки 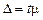 :
:
для середньої
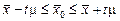 ;
;
для частки
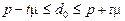 ,
,
де m — стандартна (середня) похибка вибірки; t — квантиль розподілу ймовірностей (довірче число).
Стандартна похибка вибірки m є середнім квадратичним відхиленням вибіркових оцінок від значення параметра в генеральній сукупності. Як доведено в теорії вибіркового методу, дисперсія вибіркових середніх у n раз менша від дисперсії ознаки в генеральній сукупності, тобто 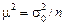 . Оскільки на практиці генеральна дисперсія ознаки невідома, у розрахунках можна використати вибіркову незсунену оцінку дисперсії: для повторної вибірки
. Оскільки на практиці генеральна дисперсія ознаки невідома, у розрахунках можна використати вибіркову незсунену оцінку дисперсії: для повторної вибірки 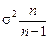 , для безповторної
, для безповторної 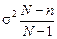 . Отже, формули стандартної похибки:
. Отже, формули стандартної похибки:
для повторної вибірки
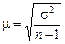 ,
,
для безповторної вибірки
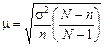 .
.
Щодо практичного використання наведених формул слід урахувати таке:
а) дисперсія частки 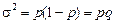 , де р і q — частки вибіркової сукупності, яким відповідно властива і невластива ознака;
, де р і q — частки вибіркової сукупності, яким відповідно властива і невластива ознака;
б) у великих за обсягом сукупностях (30 і більше одиниць) поправка 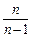 не вносить істотних змін у розрахунки, а тому береться до уваги лише у вибірках з невеликою кількістю елементів;
не вносить істотних змін у розрахунки, а тому береться до уваги лише у вибірках з невеликою кількістю елементів;
в) коригуючий множник для безповторної вибірки 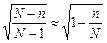 , тобто при малих величинах
, тобто при малих величинах 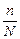 (наприклад, для 2 чи 5%-ної вибірки) наближається до 1, а тому розрахунок можна виконувати за формулою для повторної вибірки; при 10%-ній вибірці коригуючий множник становить 0,949, при 20%-ній — 0,894.
(наприклад, для 2 чи 5%-ної вибірки) наближається до 1, а тому розрахунок можна виконувати за формулою для повторної вибірки; при 10%-ній вибірці коригуючий множник становить 0,949, при 20%-ній — 0,894.
Гранична похибка вибірки 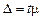 — це максимально можлива похибка для взятої ймовірності F(x). Довірче число t показує, як співвідносяться гранична та стандартна похибки. Як бачимо з рис. 6.1, з імовірністю 0,683 гранична похибка не вийде за межі стандартної
— це максимально можлива похибка для взятої ймовірності F(x). Довірче число t показує, як співвідносяться гранична та стандартна похибки. Як бачимо з рис. 6.1, з імовірністю 0,683 гранична похибка не вийде за межі стандартної 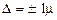 , з імовірністю 0,954 вона не перевищить ± 2m, з імовірністю 0,997 — ± 3m. На практиці найчастіше застосовують імовірність 0,954 (на рис. 6.1 незаштрихована частина площини).
, з імовірністю 0,954 вона не перевищить ± 2m, з імовірністю 0,997 — ± 3m. На практиці найчастіше застосовують імовірність 0,954 (на рис. 6.1 незаштрихована частина площини).
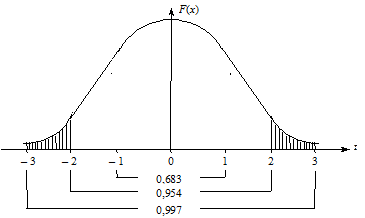
Рис. 6.1. Співвідношення ймовірностей та ширини довірчих меж
З урахуванням сказаного формули граничних похибок середньої та частки записують так:
| Повторна вибірка | Безповторна вибірка | |
| для середньої | 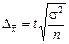 ; ;
| 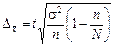 ; ;
|
| для частки | 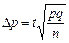 ; ;
| 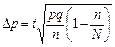 . .
|
Як видно з формул, розмір граничної похибки залежить:
· від варіації ознаки s2;
· обсягу вибірки n;
· частки вибірки в генеральній сукупності 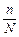 ;
;
· узятого рівня ймовірності, якому відповідає квантиль t.
Чим більша варіація ознаки в генеральній сукупності, тим більша в середньому похибка вибірки. Залежність похибки від обсягу вибіркової сукупності обернено пропорційна. Щоб зменшити похибку вибірки вдвічі, обсяг останньої має зрости в 4 рази. При безповторному доборі похибка буде тим менша, чим більша частка обстеженої сукупності . Очевидно, при суцільному спостереженні похибка репрезентативності відсутня (D = 0).
При малих вибірках (n < 30 ), у розрахунках стандартних похибок використовують вибіркові оцінки дисперсій 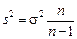 . Квантилі t визначають за розподілом імовірностей Стьюдента. У табл. 6.3 наведено деякі значення квантилів t розподілу Стьюдента для ймовірності 0,95 і числа ступенів свободи, тобто числа незалежних величин, необхідних для визначення даної характеристики, k = n – 1. При n > 30 квантилі розподілу Стьюдента і нормального розподілу збігаються.
. Квантилі t визначають за розподілом імовірностей Стьюдента. У табл. 6.3 наведено деякі значення квантилів t розподілу Стьюдента для ймовірності 0,95 і числа ступенів свободи, тобто числа незалежних величин, необхідних для визначення даної характеристики, k = n – 1. При n > 30 квантилі розподілу Стьюдента і нормального розподілу збігаються.
Розглянемо методику вибіркового оцінювання середньої та частки на прикладі обстеження 225 домогосподарств регіону. За результатами 1%-ної вибірки 70% грошового доходу домогосподарства витрачають на харчування. Середньодушові витрати на харчування за місяць становлять 82 грн. при дисперсії 8510.
Визначимо межі середньодушових витрат на харчування з імовірністю 0,954 (t = 2).
Гранична похибка
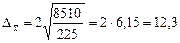 грн.
грн.
Це дає підставу стверджувати з імовірністю 0,954, що середньодушові витрати на харчування в цілому по регіону щонайменше 69,7 грн. і не перевищують 94,3 грн.:
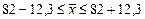 .
.
Перш ніж визначити граничну похибку частки витрат на харчування, необхідно обчислити її дисперсію:
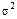 = 0,7(1 – 0,7) = 0,21.
= 0,7(1 – 0,7) = 0,21.
Гранична похибка
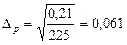 або 6,1%.
або 6,1%.
Щодо інтервалу можливих значень частки витрат на харчування в генеральній сукупності, то межі його становлять 63,9 і 76,1%:
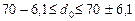 .
.
У статистичному аналізі часто постає потреба порівняти похибки вибірки різних ознак або однієї і тієї самої ознаки в різних сукупностях.
Такі порівняння виконують за допомогою відносної похибки, яка показує, на скільки процентів вибіркова оцінка може відхилятися від параметра генеральної сукупності. Відносна стандартна похибка середньої — це коефіцієнт варіації вибіркових середніх:
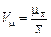
 .
.
Її розмір можна визначити також на основі коефіцієнта варіації ознаки Vx:
для повторної вибірки
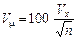 ;
;
для безповторної вибірки
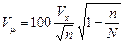 .
.
Так, у нашому прикладі відносна похибка середньодушових витрат на харчування
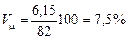 .
.
Такий самий результат дає розрахунок відносної похибки на основі коефіцієнта варіації :
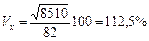 ;
;
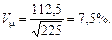
Вибіркову похибку частки 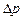 також слід порівнювати з часткою р. Адже одна і та сама похибка
також слід порівнювати з часткою р. Адже одна і та сама похибка 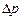 = 2% для р = 80% є малою, для р = 40% — допустимою, для р = 10% — завеликою. Відносну похибку частки обчислюють за формулою
= 2% для р = 80% є малою, для р = 40% — допустимою, для р = 10% — завеликою. Відносну похибку частки обчислюють за формулою
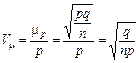 .
.
У нашому прикладі відносна похибка частки витрат на харчування становить 4,36%:
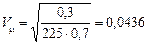 ,
,
що значно менше порівняно з похибкою середньодушових витрат на харчування (7,5%).
Отже, відносну похибку можна використати для порівняння вибіркових оцінок різних ознак. На практиці достатнім рівнем точності вважається 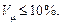 Іноді використовують граничну відносну похибку, яка враховує ймовірність статистичного висновку
Іноді використовують граничну відносну похибку, яка враховує ймовірність статистичного висновку 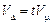 .
.
5.3. Різновиди вибірок і способи відбору одиниць з генеральної сукупності
Формування вибірки — не безладний процес. Ця дія виконується за певними правилами. Передусім визначається основа вибірки. У сукупностях, які складаються з «фізичних» елементів, одиниця основи може репрезентувати або окремий елемент сукупності, або певне їх угруповання. Наприклад, вивчається використання комбайнів. Загальна їх кількість N розподілена за М бригадами, кожна з них має Nj комбайнів. Одиницею основи вибірки може бути комбайн або бригада. Відповідно формується вибіркова сукупність: у першому випадку вибирається n комбайнів із загального їх числа N, у другому — m бригад із загального їх числа M.
Найпростішою основою вибірки є перелік елементів генеральної сукупності, пронумерований від 1 до N. Простими вважаються також набори звітів, анкет, карток тощо.
На практиці досліджувані сукупності мають, як правило, не одну, а низку альтернативних основ для вибірки. Наукове обґрунтування та правильний вибір основи — перша передумова забезпечення репрезентативності результатів вибіркового спостереження.
Від основи вибірки залежить спосіб добору елементів сукупності для обстеження. Найчастіше використовують способи добору: простий випадковий, механічний, розшарований (районований), серійний.
Простий випадковий добір провадиться жеребкуванням або за допомогою таблиць випадкових чисел. Це класичний спосіб формування вибіркової сукупності, який передбачаєпопередню досить складну підготовку до формування вибірки. Для жеребкування на кожну одиницю генеральної сукупності необхідно заготувати відповідну фішку; при використанні таблиць випадкових чисел усі елементи цієї сукупності мають бути пронумеровані. У великих за обсягом сукупностях така робота здебільшого недоцільна, а часом і неможлива. Тому на практиці застосовуються інші різновиди випадкових вибірок.
Механічний добір. Основа вибірки — упорядкована множина елементів сукупності. Добір елементів здійснюється через рівні інтервали. Крок інтервалу обчислюється діленням обсягу сукупності N на передбачений обсяг вибірки n. Початковий елемент вибірки визначається як випадкове число всередині першого інтервалу, другий елемент залежить від початкового числа й кроку інтервалу. Так, для частки вибірки 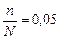 кроком інтервалу є число =
кроком інтервалу є число = 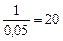 , тобто у вибірку має потрапити кожний двадцятий елемент. Якщо початковий елемент — випадкове число 7, то другим елементом буде 7 + 20 = 27, третім — 27 + 20 = 47 і т. д.
, тобто у вибірку має потрапити кожний двадцятий елемент. Якщо початковий елемент — випадкове число 7, то другим елементом буде 7 + 20 = 27, третім — 27 + 20 = 47 і т. д.
Механічна вибірка порівняно з простою випадковою ефективніша, її простіше здійснити. Проте за наявності циклічних коливань значень ознаки, цикл коливань яких збігається з інтервалом, можливий зсув вибіркових оцінок. Похибку механічної вибірки обчислюють за формулою похибки безповторної вибірки.
Вивчаючи безперервні в часі процеси, зокрема технологічні (структури затрат робочого часу, використання виробничого устаткування), проводять моментні спостереження. Суть їх — у періодичній фіксації стану процесу на певні моменти часу, які вибирають за схемою випадкової або механічної вибірки (через певні інтервали часу).
На етапі підготовки моментних спостережень визначають перелік можливих варіантів стану процесу, наприклад перелік причин простоїв устаткування. Під час обстеження певної сукупності одиниць устаткування, скажімо, верстатів, у визначені моменти часу фіксується, працює r-й верстат чи ні (якщо ні, зазначаються причини простою). Припустимо, що в цеху працюють 10 верстатів і за 8-годинну зміну через кожні півгодини проводилась реєстрація використання цих верстатів. Було зроблено 160 записів (2 · 8 · 10), у 144 випадках зазначено, що верстат працював, у 16 — не працював. Частка працюючих верстатів становить 0,9, дисперсія частки — 0,9 × 0,1 = 0,09. Із імовірністю 0,954 гранична похибка вибірки 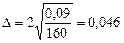 , або 4,6%. Отже, частка працюючих верстатів за зміну становила не менш як 90 – 4,6 = 85,4%.
, або 4,6%. Отже, частка працюючих верстатів за зміну становила не менш як 90 – 4,6 = 85,4%.
Щодо повноти охоплення елементів сукупності, то моментне спостереження суцільне, воно вибіркове впродовж часу, бо охоплює не весь час роботи устаткування, а лише певні моменти. У разі правильної організації моментні обстеження забезпечують досить точні результати швидко і з меншими витратами, ніж при суцільному спостереженні.
Розшарований (районований, типовий) добір — це спосіб формування вибірки з урахуванням структури генеральної сукупності. На відміну від простого випадкового та механічного добору, які проводяться в цілому по генеральній сукупності, розшарований передбачає її попередню структуризацію й незалежний добір елементів у кожній складовій. Обсягом розшарованої вибірки є сума частинних вибірок 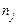 , тобто
, тобто 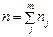 , де m — число складових (груп, типових районів тощо).
, де m — число складових (груп, типових районів тощо).
Похибку розшарованої вибірки обчислюють, використовуючи середню з групових дисперсій 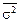 . Якщо сформовані групи об’єднують «схожі» елементи, а групові середні величини помітно різні, варіація ознаки в групах буде значно меншою, ніж по сукупності. У такому разі <
. Якщо сформовані групи об’єднують «схожі» елементи, а групові середні величини помітно різні, варіація ознаки в групах буде значно меншою, ніж по сукупності. У такому разі < 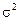 , а отже, похибка розшарованої вибірки порівняно з простою випадковою чи механічною буде менша:
, а отже, похибка розшарованої вибірки порівняно з простою випадковою чи механічною буде менша:
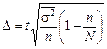 .
.
Для того щоб забезпечити більшу точність розшарованої вибірки, слід обґрунтувати ознаку розшарування сукупності, число складових частин m, обсяг частинних вибірок 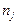 і спосіб добору. Зменшення варіації ознаки при розшаруванні сукупності можливе за умови, що ознака розшарування сукупності корелює з ознакою, характеристики якої оцінюються. ці ознаки співвідносяться як причина й наслідок.
і спосіб добору. Зменшення варіації ознаки при розшаруванні сукупності можливе за умови, що ознака розшарування сукупності корелює з ознакою, характеристики якої оцінюються. ці ознаки співвідносяться як причина й наслідок.
Відповідно до правила розкладання дисперсій 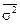 =
= 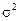 –
– 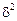 або
або 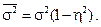 Отже, розшарування сукупності зменшує похибку вибірки на частку (
Отже, розшарування сукупності зменшує похибку вибірки на частку ( 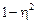 ). Чим щільніший зв’язок між ознаками, тим помітніше зменшення похибки. При
). Чим щільніший зв’язок між ознаками, тим помітніше зменшення похибки. При 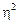 = 0,50 похибка вибірки зменшується вдвічі, при = 0,66 — утричі.
= 0,50 похибка вибірки зменшується вдвічі, при = 0,66 — утричі.
У практиці вибіркових спостережень застосовують різні способи визначення обсягу вибіркової сукупності n та її складових nj. Найпростіший з них, коли всі m груп подані однаковою кількістю елементів:
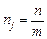 .
.
Проте застосування цього способу обмежене. Якщо чисельності груп у генеральній сукупності Nj дуже різні, може виникнути ситуація, коли nj > Nj.
Найчастіше застосовують пропорційний добір, який передбачає однакове для всіх складових представництво, тобто частки 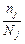 однакові й обсяг частинної вибірки залежить від обсягу відповідної складової сукупності:
однакові й обсяг частинної вибірки залежить від обсягу відповідної складової сукупності:
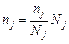 .
.
Оптимальним щодо мінімізації похибки є добір, пропорційний до середнього квадратичного відхилення:
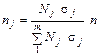 .
.
Очевидно, що обсяг вибірки залежить від рівня варіації ознаки в окремих складових генеральної сукупності. Однорідні групи подаються меншим числом елементів, неоднорідні — більшим. Відсутність даних про варіацію ускладнює практичну реалізацію такого способу вибірки.
Різновидом розшарованої вибірки є метод квот, коли обсяг частинних вибірок nj визначається завчасно. Цей спосіб поширений при вивченні громадської думки, ринку тощо. Так, при вивченні громадської думки тому, хто має брати інтерв’ю, установлюються квоти, наприклад обстежити двох фермерів-чоловіків віком 30—40 років, трьох мешканців міста віком 20—30 років і т. ін. В який спосіб «заповнити квоти», він вирішує сам. Метод квот не гарантує незсуненості вибіркових оцінок.
Серійна вибірка. Одиниця основи вибірки — серія елементів. Серії складаються з одиниць, які пов’язані або територіально (райони, селища), або організаційно (фірми, акціонерні товариства). Вибіркова сукупність серій формується за схемами механічної або простої випадкової вибірки. Дібрана серія розглядається як одне ціле, обстеженню підлягають усі без винятку елементи серії. При обчисленні похибки вибірки враховується міжсерійна варіація:
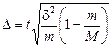 ,
,
де d2 — міжсерійна дисперсія; m та М — число серій відповідно у вибірці та генеральній сукупності.
Похибка серійної вибірки буде меншою порівняно з похибкою простої випадкової чи механічної вибірки в тому разі, якщо серії більш-менш однорідні й варіація серійних середніх незначна. Зростання міжсерійної варіації призводить до збільшення похибки вибірки.
Використання того чи іншого способу формування вибіркової сукупності залежить від мети вибіркового обстеження, можливостей його організації та проведення. Іноді поєднуються різні способи добору: механічний і серійний, розшарований і механічний, випадковий і серійний.
Таке поєднання можливе в рамках багатоступеневої вибірки. Ступенів може бути два, три й більше. Кожний із них має свою, відмінну від інших основу вибірки. Відповідно поділяються й одиниці вибірки: першого ступеня, другого і т. ін. Повнота охоплення основи й схема добору одиниць на різних ступенях різняться.
Наприклад, сукупність містить K одиниць першого ступеня, які складаються з M одиниць другого ступеня, ті, у свою чергу, об’єднують Nj одиниць третього ступеня. Саме така триступенева вибірка застосовується при організації обстеження домогосподарств. Наприклад, у сільській місцевості одиниці першого ступеня — це райони області; одиниці другого ступеня — селища; одиниці третього ступеня — домогосподарства.
Отже, вибір елементів для безпосереднього обстеження здійснюється на останньому, третьому ступені формування вибіркової сукупності. Частка її відносно до генеральної сукупності залежить від часток вибірки на всіх ступенях. Якщо припустити, що до вибірки потрапив один з десяти районів (d1 = 0,10), у цих районах відібране кожне п’яте селище (d2 = 0,20), а у відібраних селищах обстежується 4% домогосподарств (d3 = 0,04), то частка вибіркової сукупності в генеральній становить:
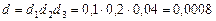 ,
,
тобто обстеженню підлягає 0,08% домогосподарств.
Багатоступенева вибірка значно зменшує витрати на обстеження й порівняно з іншими вибірками більш ефективна.
Якщо обстежують сукупність за двома й більше ознаками, які різняться варіацією, ефективною є багатофазна вибірка. Суть її в тому, що для різних ознак формуються вибіркові сукупності різного обсягу. На відміну від багатоступеневої вибірки багатофазна використовує для всіх ознак одну й ту саму основу вибірки, проте програма обстеження різна.
Вибіркові сукупності формуються поетапно — фазами. З генеральної сукупності утворюється первинна вибірка, а з первинної — підвибірка і т. д. На кожній наступній фазі обсяг підвибірки зменшується, а програма обстеження розширюється. Вибіркові оцінки кожної фази використовуються як додаткова інформація на наступних фазах, що підвищує точність результатів вибіркового обстеження.
При організації багатофазної вибірки можливі комбінації різних способів і видів вибірки. Багатофазна вибірка поєднується з багатоступеневою, а також із суцільним спостереженням.
За способами відбору одиниць розрізняють такі види вибіркового спостереження:
1) власне випадкова вибірка – така вибірка, при якій відбір одиниць з усієї генеральної сукупності є ненавмисним (випадковим). Для цієї вибірки характерне жеребкування.
Розрізняють повторну і безповторну випадкову вибірку. При повторній виборцікожна одиниця може бути вибрана декілька разів, а при безповторнійкожна одиниця сукупності обирається лише один раз. Найчастіше застосовується повторна випадкова вибірка.
2) механічна вибірка – це така вибірка, при якій відбір одиниць проводиться механічно через певний інтервал. Механічна вибірка завжди безповторна.
Недоліком механічної вибірки є те, що перед вибіркою необхідно мати повий облік одиниць сукупності, потім потрібно провести ранжування і лише після цього можна проводити вибірку з певним інтервалом.
3) типова (районована) вибірка – це така вибірка, при якій генеральну сукупність поділяють на однорідні групи за певною ознакою (або на райони і зони). Потім з кожної групи у випадковому порядку відбирається певна кількість одиниць, пропорційно питомій вазі групи в загальній сукупності.
Типова вибірка часто здійснюється в декілька ступенів.
4) серійна вибірка – це така вибірка, при якій відбір одиниць проводиться групами (серіями) і обстеженню підлягають усі одиниці відібраної групи (серії).
Перевагою серійної вибірки є те, що інколи відібрати окремі одиниці складніше, ніж серії. Прикладом є 10% відбори певної серії випуску продукції (напр. зернових).
5) В статистичній практиці часто застосовується не один, а декілька видів вибірки. Таке спостереження називається комбінаційним.
Помилки вибірки
Помилки репрезентативності можуть бути систематичні і випадкові. Систематичні помилки виникають внаслідок порушення принципів проведення вибіркового спостереження. Випадкові помилкирепрезентативності зумовлені тим, що вибіркова сукупність не відображає точно середні і відносні показники генеральної сукупності.
Фактори, що впливають на помилки репрезентативності:
- показники варіації певної ознаки (напр. дисперсії): чим більший показник варіації – тим більше розмір помилки
- від чисельності вибірки: чим більша вибірка – тим менша вірогідність помилки (розмір помилки).
- від способу відбору (повторний чи безповторний).
Середня помилка репрезентативності (інша назва – стандарт). Позначається 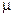 (мю).
(мю).
Формули для обрахування середньої помилки репрезентативності для механічної і випадкової вибірки (див. таблицю)
| Спосіб відбору | ||
| Повторний | Безповторний | |
| При визначенні середньої розміру досліджуваної ознаки (x) | 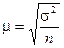
| 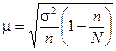
|
| При визначенні частки досліджуваної ознаки (w) | 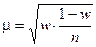
| 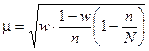
|
n – кількість одиниць вибіркової сукупності
N – кількість одиниць генеральної сукупності
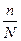 - частка одиниць сукупності, що досліджуються
- частка одиниць сукупності, що досліджуються
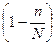 - частка одиниць сукупності, що не досліджуються.
- частка одиниць сукупності, що не досліджуються.
Приклад-Задача. При проведення 5% механічної вибірки дістали дані про врожайність нового сорту пшениці:
| Урожайність, ц/га | 20-22 | 22-24 | 24-26 | 26-28 | 28-30 | Всього |
| Посівна площа, га |
Визначити середню помилку репрезентативності:
1) при встановленні середньої очікуваної врожайності нового сорту пшениці;
2) при визначенні питомої ваги посівної площі нового сорту пшениці урожайність якої перевищує 26 ц/га .
Розв’язання. 1) Для даної вибірки середня врожайність 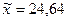 ц/га, дисперсія
ц/га, дисперсія 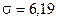 .
.
За умовою 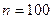 . Оскільки маємо 5% вибірку, то
. Оскільки маємо 5% вибірку, то 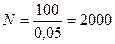 .
.
Тоді 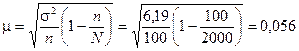
Отже, 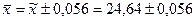 Þ
Þ 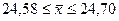
2) Питома вага посівної площі з врожайністю більше 26 ц/га:
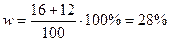
Тоді середня помилка репрезентативності становить:
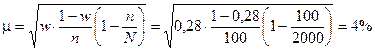
Отже питома вага посівної площі, на якій врожайність перевищуватиме 26 ц/га, становить 28% ± 4%.
Дата добавления: 2016-07-27; просмотров: 6740;
Поиск по сайту
Узнать еще
- Інфляція: суть, види та наслідки.
- В чем суть явления релаксации напряжения?
- Види статистичного спостереження та способи одержання інформації
- Дайте определение полевого опыта и сельскохозяйственного производственного опыта. Если между ними имеются различия, то в чем их суть?
- Економічна суть інфляції
- Економічна суть грошей
- Економічна суть грошового ринку
- Економічна суть кредиту

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
