СТАТИСТИЧЕСКИЕ МЕТОДЫ АНАЛИЗА ВЗАИМОСВЯЗЕЙ СОЦИАЛЬНО-ЭКОНОМИЧЕСКИХ ЯВЛЕНИЙ
Цель: сформировать представление о методах измерения стохастических связей, специфических черт, преимуществ и ограничений применения этих методов.
Задачи: представить классификацию видов и методов измерения связей, раскрыть особенности корреляционного и регрессионного методов анализа, а также непараметрических методов изучения связей.
Функциональные и статистические зависимости. Общие принципы и задачи статистического изучения связи. Качественный анализ при изучении зависимостей
В математическом смысле слово «зависимость» означает функциональную зависимость, при которой каждому значению признака-фактора X соответствует вполне определенное значение признака-результата Y (рис. 4.1).

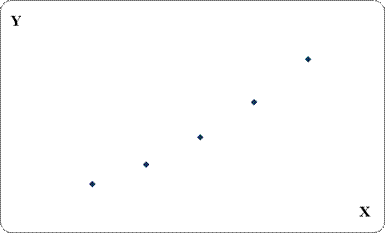
Рис. 4.1. Графическое отображение функциональной связи.
Однако функциональные зависимости не исчерпывают всех возможных видов взаимосвязи между явлениями. Большинство зависимостей, с которыми приходится сталкиваться в экономике (например, зависимость выпуска продукции предприятия от числа рабочих, прибыль предприятия от затрат на рекламу), имеют не функциональную природу. Такого рода зависимости носят название корреляционных или стохастических. Наглядное представление такой связи дает графическое построение, называемое корреляционным полем (рис. 4.2). Для изучения связи между признаками X и Y проводится статистическое наблюдение над некоторой совокупностью, в ходе которого фиксируются значения этих величин. Затем все элементы совокупности изображаются в системе координат.

Рис. 4.2. Графическое отображение стохастической связи.
Таким образом, можно дать определения различным видам связей в статистике.
Статистическая (стохастическая) связь – это такая связь между признаками, при которой для каждого значения признака-фактора Х признак-результат Y может в определенных пределах принимать любые значения с некоторыми вероятностями; при этом его статистические (обобщающие) характеристики (например, среднее значение) изменяются по определенному закону.
Модель стохастической связи может быть представлена в общем виде уравнением:
Y=f(X,u),
где Y - фактическое значение результативного признака;
f(X) - часть результативного признака, сформировавшаяся под воздействием фактора Х (или множества факторов: Y=f(X1,...,Xm);
u - случайная составляющая, часть результативного признака, возникшая вследствие действия прочих (неучтенных) факторов, а также ошибок измерения признаков.
Например, уровень успеваемость студентов по статистике стохастически связан с целым комплексом факторов: склонностью к точным наукам; временем, затраченным на подготовку к предмету; состоянием здоровья студента и др. Полный перечень факторов неизвестен. Кроме того, неодинаково действие любого известного фактора на результат. Например, при одной и той же успеваемости, разные студенты затрачивают неодинаковое время на подготовку. В результате – при одинаковых возможностях наблюдается вариация значений успеваемости студентов.
Корреляционная связь - частный случай статистической связи, при которой с изменением значения признака-фактора Х среднее значение признака-результата Y закономерно изменяется: М(YçX)=f(X) или М(YçX1, X2, .., Xm)=f(X1, X2, ...,Xm) , m – количество факторов, М (YçX)– условное математическое ожидание.
Понятие «корреляция» было введено английскими статистиками. В переводе оно означает подобие связи (в смысле функциональной связи). Relation по-английски - жестко детерминированная (функциональная) связь.
Функциональная связь – такая связь, при которой для каждого значения признака-фактора признак-результат принимает одно или несколько строго определенных значений. Она имеет место, когда все факторы, действующие на результативный признак, известны и учтены в модели и ошибки измерения отсутствуют. Модель функциональной связи может быть представлена как:
Y=f(X).
При изучении корреляционных зависимостей необходимо решать следующие задачи:
1. установление факта зависимости. На начальном этапе необходимо выяснить, существует ли какая-либо зависимость между рассматриваемыми признаками фактором (X) и результатом (Y). Если зависимости не существует, то исследование на этом заканчивается, если же зависимость существует, исследователь переходит к следующим задачам;
2. установление формы, характера зависимости и определение ее количественных характеристик. На данном этапе, во-первых, определяется направление связи: прямая или обратная. При прямойсвязи направление изменения результата совпадает с направлением изменения признака-фактора. При обратнойсвязи направление изменения результата противоположно направлению изменения признака-фактора. Например, чем выше квалификация рабочего, тем выше уровень производительности его труда (прямая связь). Чем выше производительность труда, тем ниже себестоимость единицы продукции (обратная связь). Во-вторых, определяется форма связи (вид функции f): линейная (прямолинейная) и нелинейная (криволинейная).
Линейная связь отображается прямой линией; криволинейная отображается кривой (параболой, гиперболой и т.п.). При линейной связи с возрастанием значения факторного признака происходит равномерное возрастание (убывание) значения результативного признака. При криволинейной связи с возрастанием значения фактора возрастание (убывание) результата происходит неравномерно (гиперболическая форма связи) или же направление его изменения меняется на обратное (параболическая форма связи). Наконец, определяется количество факторов, оказывающих влияние на результат, в соответствии с чем связи подразделяются на однофакторные (парные) и многофакторные;
3. оценка тесноты связи. Если задачи 1 и 2 имеют смысл и для функциональной, и для корреляционной зависимости, то измерение тесноты связи специфично именно для анализа корреляционных зависимостей. Для функциональных связей данное понятие лишено смысла, поскольку связь носит абсолютный, однозначный характер.
Порядок изучения статистической связи:
1. Качественный (содержательный) анализ связи. На этом этапе производят предварительный анализ направления и формы связи.
2. Сбор данных (статистическое наблюдение).
3. Эмпирический анализ связи.
4 Количественная оценка тесноты связи (корреляционный анализ).
5. Установление аналитической зависимости между признаками (регрессионный анализ):
5.1. выбор формы связи (вида аналитической зависимости);
5.2. оценка параметров уравнения регрессии;
5.3. оценка качества уравнения регрессии.
Эмпирическая регрессия. Дисперсионный анализ
Эмпирический анализ связисостоит в построении группировок (аналитической или комбинационной) и графиков.
Для анализа связи между признаками служат графики: корреляционного поля и эмпирической линии регрессии.
Корреляционное поле – точечный график, построенный в прямоугольной системе координат. Число точек равно числу единиц в совокупности. Каждая точка соответствует единице совокупности и имеет координаты по оси абсцисс – значение признака-фактора Х, а по оси ординат – значение признака-результата Y у данной единицы совокупности.
Для построения эмпирической линии регрессии требуются данные аналитической группировки. Эмпирическая линия регрессии – ломанная, построенная по данным аналитической группировки. Число точек у этой ломаной равно числу групп в аналитической группировке. Координаты точек: по оси Х – значение признака-фактора в группе (или середина интервала, если группировка интервальная), по оси Y – среднее значение признака-результата в группе.
Форма графиков корреляционного поля и эмпирической линии регрессии позволяет делать выводы о направлении, форме и тесноты связи. Если эмпирическая линия регрессии по своему виду приближается к прямой линии, то можно предположить наличие прямолинейной корреляционной связи между признаками. А если линия связи приближается к кривой, то это может быть связано с наличием криволинейной корреляционной связи.
Эмпирическая линия регрессии не дает значений результирующего признака, соответствующих отдельным значениям признака-фактора, данная зависимость не может быть точно описана какой-либо функцией. Эмпирическая регрессия отражает при этом главную тенденцию рассматриваемой зависимости.
Пусть, требуется построить эмпирическую линию регрессии и корреляционное поле по данным о 15 предприятиях розничной торговли для выявления зависимости между двумя признаками: Y – объем продаж за период (млн. руб.) и X – расходы на рекламу (млн. руб.). Исходные данные приведены в табл. 4.1.
Для построения корреляционного поля (рис. 4.3.) в прямоугольной системе координат отложим 15 точек, каждая из которых соответствует своей единице совокупности (предприятию). Координатами точек являются по оси абсцисс – значение признака-фактора (расходы на рекламу), по оси ординат – значение признака-результата (объем продаж за период).
Таблица 4.1
Исходные данные
| № п.п. | Расходы на рекламу, млн. руб. (X) | Объем продаж, млн. руб. (Y) |
Таблица 4.2
Аналитическая группировка предприятий
| Расходы на рекламу, млн.руб. | Середина интервала | Число предприятий | Средний по группе объем продаж, млн.руб. |
| 40—65 | 52,5 | 139,3 | |
| 65—80 | 72,5 | 166,3 | |
| 80—115 | 97,5 | 243,6 | |
| Итого | — | — |
Для построения эмпирической линии регрессии (рис. 4.3.) нам потребуются данные аналитической группировки (табл. 4.2). Число точек эмпирической линии регрессии равно числу групп (в нашем примере 3). Координатами точек являются по оси абсцисс – середина интервала по X в группе, а по оси ординат – среднее значение признака-результата Y в группе.
Результаты построения графиков корреляционного поля и эмпирической линии регрессии представлены на рис. 4.3.
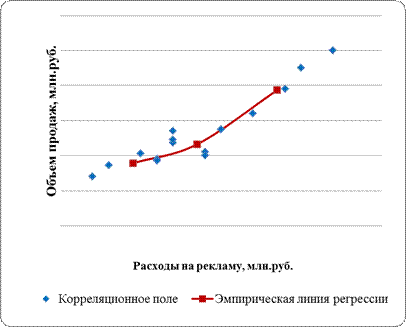
Рис. 4.3. Корреляционное поле и эмпирическая линия регрессии.
Анализируя эмпирическую линию регрессии и корреляционное поле, можно сделать вывод о прямой, близкой к линейной зависимости между признаками.
Если статистическая совокупность разбита на группы по какому-либо признаку, то для оценки влияния различных факторов, определяющих колеблемость индивидуальных значений признака, можно воспользоваться разложением дисперсии на составляющие: на межгрупповую и внутригрупповую дисперсии.
Если рассчитать дисперсию признака по всей изучаемой совокупности, т.е. общую дисперсию, то полученный показатель будет характеризовать вариацию признака, как результат влияния всех факторов, определяющих индивидуальные различия единиц совокупности. Если же поставить дальнейшую задачу - выделить в составе общей дисперсии ту ее часть, которая обусловлена влиянием какого-либо определенного фактора, то следует разбить изучаемую совокупность на группы, положив в основу группировки интересующий нас фактор. Затем нужно изучить раздельно вариацию признака внутри однородных в отношении данного фактора групп и изменения в величине признака от группы к группе. Выполнение такой группировки позволяет разложить общую дисперсию признака на две дисперсии, одна из которых будет характеризовать часть вариации, обусловленную влиянием фактора, положенного в основу группировки, а вторая – вариацию, происходящую под влиянием прочих факторов.
На основе этого подхода строится дисперсионный анализ. Он позволяет установить оказывает ли существенное влияние некоторый (чаще всего качественный) фактор (имеющий k уровней) на изучаемый признак. То есть дисперсионный анализ используется для проверки гипотезы о связи.
Дисперсионный анализ часто применяется совместно с результатами аналитической группировки. При этом ставится задача оценки существенности различий средних значений признака-результата в группах, выделенных по признаку-фактору.
Для решения данной задачи рассчитывают F-критерий:
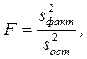
где 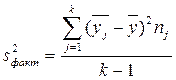 – это исправленная (скорректированная на число степеней свободы) межгрупповая дисперсия;
– это исправленная (скорректированная на число степеней свободы) межгрупповая дисперсия;
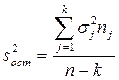 - это исправленная (скорректированная на число степеней свободы) внутригрупповая дисперсия.
- это исправленная (скорректированная на число степеней свободы) внутригрупповая дисперсия.
Эта запись предполагает, что s2факт> s2ост. Как правило, мы получаем именно такое соотношение.
По таблицам распределения Фишера находят критическое значение Fкр, задаваясь уровнем значимости (вероятностью ошибки 1-ого рода) α и числами степеней свободы: df1= k-1, df2=n-k.
Если Fнабл>F кр(a, df1, df2), то можно утверждать, что влияние признака-фактора является существенным или статистически значимым.
Результаты дисперсионного анализа заносят обычно в таблицу (табл. 4.3)
Таблица 4.3
Результаты дисперсионного анализа
| Источник вариации | SS-сумма квадратов отклонений | Df-число степеней свободы | MS-сумма квадратов на одну степень свободы | F-наблюдаемое значение критерия |
| Между группами | 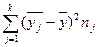
| k-1 | MSмгр= SSмгр/dfмгр | MSмгр/MSвгр |
| Внутри групп | 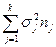
| n-k | MSвгр= SSвгр/dfвгр | |
| Итого | 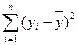
| n-1 |
Корреляционный анализ
Количественная оценка тесноты связи по эмпирическим данным состоит в расчете показателей тесноты связи:эмпирического коэффициента детерминации, эмпирического корреляционного отношения, коэффициента Фехнера, коэффициента линейной парной корреляции.
Эмпирический коэффициент детерминации или эмпирическое дисперсионное отношение, r2-показатель, характеризующий процент (долю) вариации признака-результата, обусловленную признаком-фактором. Рассчитывается по данным аналитической группировки, как отношение межгрупповой дисперсии признака-результата (dy2) к общей дисперсии признака-результата (sy2):
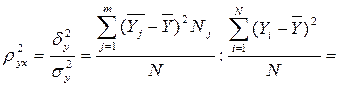
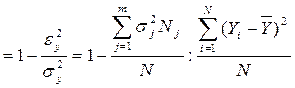 .
.
Эмпирическое корреляционное отношение, r - показатель тесноты связи, рассчитываемый как корень из эмпирического коэффициента детерминации. Область допустимых значений эмпирического корреляционного отношения от 0 до +1. При достаточно тесной связи между признаками эмпирический коэффициент детерминации стремится к 1. При слабой связи – к нулю.
Заметим, что сама по себе величина показателя силы влияния фактора на результат не является доказательством наличия причинно-следственной связи между исследуемыми признаками, а является оценкой степени взаимной согласованности в изменениях признаков. Установлению причинно-следственной зависимости должен обязательно предшествовать анализ качественной природы явлений.
Пусть, имеется аналитическая группировка предприятий розничной торговли по расходам на рекламу (X) (признак-результат – объем продаж (Y)) (табл. 4.2). Требуется оценить тесноту связи между признаками X и Y с помощью коэффициента детерминации и эмпирического корреляционного отношения. Решение:
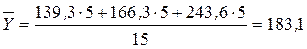 .
.
Рассчитаем межгрупповую дисперсию:
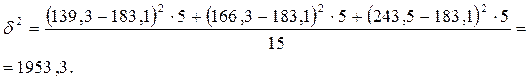
Рассчитаем внутригрупповые дисперсии:
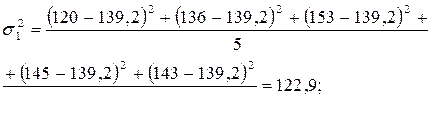
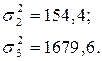
Рассчитаем остаточную дисперсию:
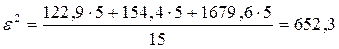
Общая дисперсия равна 1953,3+652,3=2605,6(полученное значение совпадает со значением дисперсии, рассчитанным по несгруппированным данным).
Коэффициент детерминации рассчитывается следующим образом:
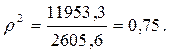
Эмпирическое корреляционное отношение рассчитывается следующим образом:
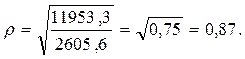
Так как значение r близко к единице, то связь между признаками Расходы на рекламу и Объем продаж довольно тесная.
Коэффициент Фехнера, Кф - показатель тесноты линейной связи, рассчитываемый по формуле:
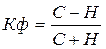 ,
,
где С/Н – число совпадений / несовпадений знаков отклонений Х от своего среднего значения и Y от своего среднего значения. Значения данного показателя изменяются в пределах от -1 до +1.
Если |Кф|→1 , то связь близка к линейной функциональной. Если признаки X и Y взаимно независимы, то |Кф|→0 .
Но равенство нулю коэффициента корреляции означает отсутствие только линейной связи. Если Кф<0,то связь между признаками обратная. Если Кф>0, то связь - прямая.
Коэффициент линейной парной корреляции, rx,y - используется для оценки степени тесноты линейной связи. Строится как отношение показателя ковариации к произведению среднеквадратических отклонений признаков X и Y:
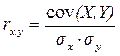 .
.
Ковариация, cov(X,Y) – это показатель совместной вариации признаков; вычисляется он следующим образом:
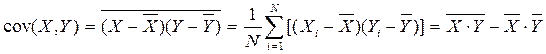 .
.
Это размерный показатель; его единицы измерения равны произведению единиц измерения Х на единицы измерения Y.
Свойства ковариации:
1. cov(X,X)=sх2 ;
2. cov(X,A)=0, где A-const;
3. cov(X, Y+Z)= cov(X,Y) + cov(X,Z), где X,Y,Z – случайные величины.
Линейный коэффициент корреляции в отличие от ковариации – показатель безразмерный и поэтому легко интерпретируемый. Он может быть рассчитан также по формуле:
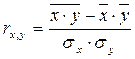 ,
,
где 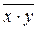 – среднее из произведения значений признака-фактора и признака-результата;
– среднее из произведения значений признака-фактора и признака-результата;
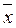 ,
, 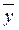 - средние значения признака-фактора и признака-результата;
- средние значения признака-фактора и признака-результата;
sх , sy – средние квадратические отклонения признака-фактора и признака-результата.
Область допустимых значений линейного коэффициента корреляции от -1 до +1. Если значение коэффициента корреляции по модулю близко к единице, то связь близка к линейной функциональной. Если признаки Х и Y взаимно независимы, то значение коэффициента корреляции близко к нулю. Равенство нулю коэффициента корреляции означает отсутствие только линейной связи. Признаки же могут быть связаны тесной нелинейной связью и при этом иметь нулевой коэффициент корреляции (например, в случае параболической формы связи).
Отрицательные значения коэффициента корреляции свидетельствуют об обратной зависимости признаков, положительные значения свидетельствуют о прямой зависимости.
Линейный коэффициент парной корреляции может быть рассчитан по сгруппированным данным, а именно, по данным комбинационной группировки.
 |
В этом случае формула расчета линейного парного коэффициента корреляции следующая:
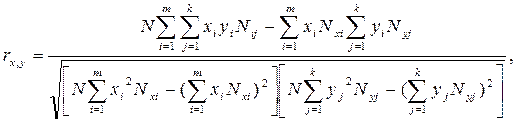
где N – объем совокупности;
Nij, Nxi, Nyj – частоты распределения значений признаков.
Если сравнить значения эмпирического корреляционного отношения r с абсолютным значением линейного парного коэффициента корреляции │r│, то можно сделать вывод о форме связи. Если r-|r|>0,1, то связь скорее нелинейная, если данное неравенство не выполняется, то связь скорее линейная.
Рассчитаем коэффициент Фехнера и линейный парный коэффициент корреляции между признаками Расходы на рекламу (X) и Объем продаж (Y) по данным наблюдений 15 предприятий. Исходные данные представлены в табл. 4.1.
Расчеты представлены в табл. 4.4. Кф=(13-2)/(13+2)=0,735. Так как значение Кф стремится к единице, то связь тесная, а положительное значение Кф свидетельствует о прямой зависимости.
Рассчитаем коэффициент линейной парной корреляции:
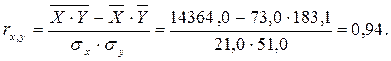
Вывод: зависимость между признаками Расходы на рекламу и Объем продаж можно характеризовать как довольно тесную (r→1) и возрастающую (т.к. r >0).
Сравним значения эмпирического корреляционного отношения r и линейного парного коэффициента корреляции |r|.
Значение эмпирического корреляционного отношения для наших данных составило: r=0,87 (см. пример выше).
Так как r - |r| =0,87 – 0,94 = - 0,07 < 0,1 , то связь между признаками расходы на рекламу и объем продаж скорее линейная, чем нелинейная.
Таблица 4.4
Расчет коэффициента Фехнера
| № | y | x | x- 
| y- 
| С- совпадение; Н- несовпадение знаков отклонений | x∙y |
| – | – | С | ||||
| – | – | С | ||||
| – | – | С | ||||
| – | – | С | ||||
| – | – | С | ||||
| – | – | С | ||||
| – | – | С | ||||
| – | – | С | ||||
| – | + | Н | ||||
| – | + | Н | ||||
| + | + | С | ||||
| + | + | С | ||||
| + | + | С | ||||
| + | + | С | ||||
| + | + | С | ||||
| Среднее | 183,1 | 73,0 | С= 13; Н=2 | |||
| Дисперсия | 2605,6 | 438,6 | ||||
| С.К.О. (s) | 51,0 | 21,0 |
Регрессионный анализ. Метод наименьших квадратов. Линейная однофакторная регрессия
Регрессия – зависимость среднего значения какой-либо случайной величины от одной или нескольких независимых величин.
Термин «регрессия» (спад) впервые ввели шведские статистики (Френсис Гамильтон) в работе, в которой исследовалась зависимость х (отклонения роста отца от среднего уровня) от y (отклонение роста взрослого сына от среднего уровня). Оказалось, что эта зависимость обратная. Т.е. наблюдалась тенденция к регрессии: у очень высоких отцов дети в среднем ниже ростом, а у очень низкорослых отцов дети в среднем значительно выше своих родителей.
Уравнение регрессии – уравнение связи в среднем (описываемое графически аналитической линией регрессии) – это уравнение, описывающее корреляционную зависимость между признаком-результатом y и признаками факторами (одним или несколькими).
Наиболее часто для описания статистической связи признаков используется линейное уравнение регрессии. Внимание к линейной форме связи объясняется четкой экономической интерпретацией параметров линейного уравнения регрессии, ограниченной вариацией переменных и тем, что в большинстве случаев нелинейные формы связи для выполнения расчетов преобразуют (путем логарифмирования или замены переменных) в линейную форму.
Методы выявления формы связи:
- графический (вид корреляционного поля и эмпирической линии регрессии);
- опыт предыдущих аналогичных исследований;
- перебор всевозможных видов функций и выбор наилучшей по показателю качества.
Линейное парное (однофакторное) уравнение регрессии имеет вид:
M(y│x=xi)=b0+b1·xi ,
где M(y│x=xi) – условное мат. ожидание зависимой переменной y при значении независимой переменной х равном хi;
b0, b1 – параметры (коэффициенты) уравнения регрессии.
При построении уравнения регрессии y=f(x) мы должны определить вид уравнения (вид функциональной связи) и оценить параметры регрессии по имеющимся данным наблюдений y, x.
Оценки параметров линейной регрессии (b0 и b1) могут быть найдены разными методами: методом наименьших квадратов; методом максимального правдоподобия; примитивными методами. Требование к методам оценивания: они должны быть по возможности просты, давать состоятельные, эффективные и несмещенные оценки.
Наиболее распространенным методом оценки параметров является метод наименьших квадратов (МНК), который при определенных условиях дает состоятельные эффективные и несмещенные оценки. Данный метод используют для оценивания не только параметров регрессии, но и других статистических характеристик (параметров), например, среднего значения.
Суть МНК:
Пусть имеются n наблюдений признаков х и y. Причем известен вид уравнения регрессии: f(x, bj) (известен вид функции -f), bj - параметры функции. Задача состоит в оценке параметров (т.е. определении значений оценок – 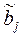 ), которые подбираются таким образом, чтобы минимизировать сумму квадратов отклонений фактических значений результативного признака – yi от расчетных (теоретических) значений – f(xi) (рассчитанных по уравнению регрессии):
), которые подбираются таким образом, чтобы минимизировать сумму квадратов отклонений фактических значений результативного признака – yi от расчетных (теоретических) значений – f(xi) (рассчитанных по уравнению регрессии):
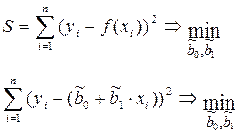 .
.
Проиллюстрируем суть данного метода графически (рис. 4.4.). Попытаемся подобрать прямую линию, которая ближе всего расположена к точкам корреляционного поля. Согласно методу наименьших квадратов прямая подбирается так, чтобы сумма квадратов расстояний по вертикали между точками корреляционного поля и этой линией была бы минимальной.
 y
y


 f(xi)
f(xi)
yi
 X
X
x i
Рис. 4.4. Линия регрессии с минимальной суммой квадратов отклонений.
Значения yi и xi i=1;n нам известны, это данные наблюдений. В функции S они представляют собой константы. Переменными в данной функции являются искомые оценки параметров – 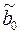 и
и 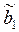 . Чтобы найти минимум функции двух переменных необходимо вычислить частные производные данной функции по каждому из параметров и приравнять их нулю, т.е.
. Чтобы найти минимум функции двух переменных необходимо вычислить частные производные данной функции по каждому из параметров и приравнять их нулю, т.е. 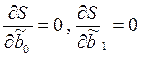 .
.
В результате получим систему из двух нормальных линейных уравнений:
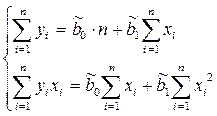
Решая данную систему, найдем искомые оценки параметров:
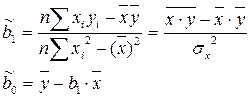
Правильность расчета параметров уравнения регрессии может быть проверена сравнением сумм 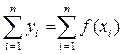 (возможно некоторое расхождение из-за округления расчетов).
(возможно некоторое расхождение из-за округления расчетов).
Оценка параметра b1 может быть рассчитана также через коэффициент корреляции: 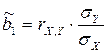 . Знак коэффициента регрессии b1 указывает направление связи (если b1>0, связь прямая, если b1<0, то связь обратная). Величина b1 показывает на сколько единиц изменится в среднем признак-результат – y при изменении признака-фактора – х на 1 единицу своего измерения.
. Знак коэффициента регрессии b1 указывает направление связи (если b1>0, связь прямая, если b1<0, то связь обратная). Величина b1 показывает на сколько единиц изменится в среднем признак-результат – y при изменении признака-фактора – х на 1 единицу своего измерения.
Формально значение параметра b0 – среднее значение признака-результата y при значении признака-фактора х равном нулю. Если признак-фактор не имеет и не может иметь нулевого значения, то вышеуказанная трактовка параметра b0 не имеет смысла. Данный параметр имеет также смысл среднего значения результата, сформировавшегося под влиянием неучтенных в модели факторов.
МНК-оценки параметров являются «наилучшими» (состоятельными, несмещенными и эффективными) оценками параметров уравнения регрессии.
Построим аналитическое уравнение регрессии, описывающее зависимость объема продаж, (y) от расходов на рекламу (х) по данным о 15 предприятиях:
f(xi) = b0+b1·xi.
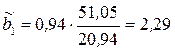 ;
;
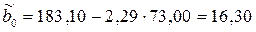 .
.
Окончательно аналитическое уравнение регрессии примет вид:
f(xi)= 16,30+2,29·хi
Параметр b1 = 2,29 показывает, что при увеличении расходов на рекламу на 1 млн. руб. объем продаж возрастает в среднем на 2,29 млн. руб.
Параметр b0 = 16,3 можно проинтерпретировать следующим образом – при отсутствии расходов на рекламу объем продаж предприятия составит 16,3 млн. руб., однако такая интерпретация не вполне корректна, поскольку среди исходных данных нет предприятий с расходами на рекламу равными или близкими к нулю.
Графическое отображение полученного уравнения регрессии представлено на рис. 4.5.
После построения уравнения регрессии следует оценить его качество.
Оценка качества уравнения осуществляется в два этапа:
1) Оценивается адекватность уравнения регрессии данным наблюдений (т.е. степень близости рассчитанных по данному уравнению значений признака-результата f(x) к фактическим значениям y).
2) Оценивается надежность уравнения регрессии (то есть возможность использовать данное уравнение для данных наблюдений другой выборки).
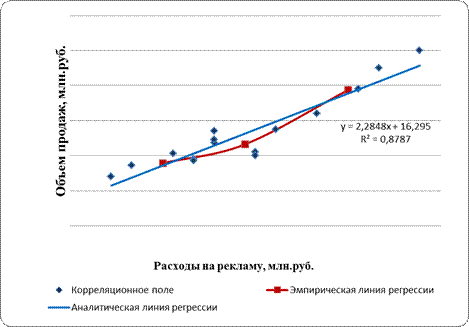
Рис. 4.5. Корреляционное поле, эмпирическая и аналитическая линии регрессии
Для оценки адекватности качества полученного уравнения регрессии используется ряд показателей.
Наиболее широкое применение из них получил теоретический коэффициент детерминации, R2yx. Теоретический коэффициент детерминации рассчитывается, как отношение объясненной уравнением дисперсии признака-результата - d2, к общей дисперсии признака-результата s2y :
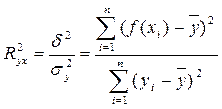 ,
,
где d2 – объясненная уравнением регрессии дисперсия y, 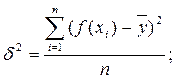
s2y - общая (полная) дисперсия y.
В силу теоремы о сложении дисперсий общая дисперсия результативного признака равна сумме объясненной уравнением регрессии d2 и остаточной (необъясненной) e2 дисперсий: s2y=d2+e2. Поэтому коэффициент детерминации может быть рассчитан через остаточную и общую дисперсии:
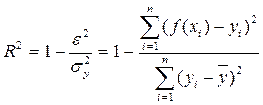 ,
,
где e2- остаточная дисперсия y, 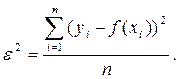
Данный показатель характеризует долю вариации (дисперсии) результативного признака y, объясняемую уравнением связи (а, следовательно, и фактором х), в общей вариации (дисперсии) y. Коэффициент детерминации R2yx принимает значения от 0 до 1. Соответственно величина 1-R2yx характеризует долю дисперсии y, вызванную влиянием прочих неучтенных в уравнении факторов и ошибками измерений. При парной линейной регрессии R2yx=r2yx.
Средняя квадратическая ошибка уравнения регрессии, se - представляет собой среднее квадратическое отклонение наблюдаемых значений результативного признака от теоретических значений, рассчитанных по модели, т.е.:
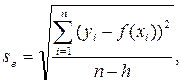
где h – число параметров в модели регрессии.
В случае линейной парной регрессии h = 2 (b0, b1). Величину средней квадртической ошибки можно сравнить со средним квадратическим отклонением результативного признака sy. Если se окажется меньше sy, то использование модели регрессии является целесообразным.
Средняя ошибка аппроксимации, А:
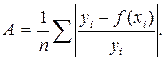
Чем меньше рассеяние эмпирических точек вокруг теоретической линии регрессии, тем меньше средняя ошибка аппроксимации. Ошибка аппроксимации меньше 7% свидетельствует о хорошем качестве модели.
Выбор вида уравнения регрессии (вида функции) обычно осуществляется методом сравнения величины показателя адекватности, рассчитанного при разных видах зависимости. Если показатели адекватности оказываются примерно одинаковыми для нескольких функций, то предпочтение отдается более простым видам функций, ибо они в большей степени поддаются интерпретации и требуют меньшего объема наблюдений.
Оценим качество уравнения регрессии для данных предыдущего примера:
R2yx = r2yx = 0,942 = 0,88.
Это означает, что 88% вариации объема продаж предприятия объясняется уравнением регрессии f(xi)= 16,30+2,29·xi. То есть уравнение достаточно качественное.
При оценки надежности уравнения регрессии используют статистические методы проверки гипотез. Предполагается, что данные наших наблюдений неполные, т.е. выборочные. При переходе от одной выборки наблюдений к другой значения оценок параметров и признака-результата будут меняться. Насколько сильна вариация этих оценок? Если вариация умеренная, то уравнение регрессии, полученное по данным конкретных наблюдений, можно использовать и для генеральной совокупности, т.е. уравнение надежно.
Для проверки гипотезы о надежности уравнения регрессии используют статистику, рассчитываемую по следующей формуле:
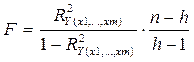 ,
,
где n - число наблюдений;
h – число оцениваемых параметров (в случае парной линейной регрессии h=2);
R2y(x1,...,xm) - выборочный коэффициент детерминации.
Данная статистика имеет F-распределение (Фишера-Снедоккора). Поэтому для поиска критического значения - Fкр пользуются таблицами распределения Фишера-Снедоккора, задаваясь при этом уровнем значимости a (обычно его берут равным 0,05) и двумя числами степеней свободы k1=h-1 и k2=n-h.
Сравнивая фактическое значение F-статистики критерия, вычисленное п
Дата добавления: 2020-10-25; просмотров: 639;
Поиск по сайту
Узнать еще
- I. Гидрометаллургические методы
- I. Погрешности механической обработки. Точность обработки. Методы их расчёта
- II. Методы исследования истории медицины.
- II. Пирометаллургические методы.
- II.II. Репродуктивные методы.
- II.III. Частично - поисковые или эвристические методы.
- II.V. Проблемные методы обучения.
- III. Методы изучения коллектива.

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
