Пример построения выборки для контент-анализа
С помощью компьютерной программы отбираются объявления таким образом, что в каждый из дней исследуемого периода получаются четыре комбинации из 7 телевизионных каналов и пяти отрезков времени. Каналы: ОРТ, РТР, НТВ, ТВЦ, СТС, Рен-ТВ и кабельный канал. Каналы были отобраны по рейтингу просмотра каналов в Москве. Отрезки времени 7:00-11:00,11:00-16:00,16:00-19:00,19:00-22:00,22:00-24:00. Период — сентябрь 2002 г. Рассматриваются все объявления, попавшие в выбранные комбинации, в том числе дублированные.
Приведенный пример достаточно прост. Нередко выборки строятся на основе многоступенчатой процедуры с различными алгоритмами отбора на каждом шаге.
Этап 4. Определение способа обработки дублированных рекламных сообщений
Часто рекламные объявления появляются в СМИ неоднократно за исследуемый период времени. Даже в течение одной телевизионной программы и даже в одном рекламном блоке может выйти несколько одинаковых рекламных роликов. Понятно, что это ведет к их дублированию в выборке. Решение о дальнейшей обработке таких сообщений (считать каждое из них отдельным или исключать дубликаты), зависит от задач, стоящих перед исследователем. В ряде случаев наличие дубликатов игнорируется и обрабатываются все данные, т.е. каждый дубль считается самостоятельным отдельным объявлением. Данный подход справедлив в том случае, когда предметом анализа являются аспекты влияния всего массива объявлений. Например, необходимо выявить использование сексуальных мотивов в мужских иллюстрированных журналах, тогда дублированные объявления важны с точки зрения их веса и зрительской экспозиции. Однако, если фокус исследования сосредоточен на рекламе конкретного конкурента или стратегии продвижения, дублированные сообщения должны быть проигнорированы, так как нас интересуют содержательные элементы рекламных сообщений, а не частота их появления.
Этап 5. Создание системы категорий
Создание системы категорий состоит из двух этапов: 5.а) идентификация интересующих нас категорий и 5.6) создание для них списка характерных измерений.
5а. Идентификация категорий
На данном этапе необходимо идентифицировать все содержательно значимые категории. Набор категорий должен быть всеобъемлющим, т.е. охватывать все особенности рассматриваемых объявлений. Категории должны иметь четкие названия, непосредственно связанные с предметом исследования и выдвинутыми гипотезами. Б. Берельсон обращает особое внимание на прямую связь между конечным успехом контент-анализа и ясной формулировкой и адаптированностью категорий к исследуемым проблеме и содержанию объявлений.
Приведем примеры набора категорий для изучения:
1) конкурентной рекламы
2) рекламной кампании женщин-политиков (табл. 3.1) ;
Таблица 3.1.. Сравнение двух категорий
| Конкурентная реклама | Политическая реклама |
| Формат объявлений | Формат объявлений |
| Структура объявлений | Стиль изложения |
| Основная выгода продукта | Длина выступления |
| Дополнительные выгоды продукта | Декорации |
| Тип торгового предложения | Тип оратора |
| Тон изложения | Тип голоса за кадром |
| Музыкальное сопровождение | Фасон одежды |
| Тип идентификации торговой марки | Упомянутые политические темы |
| Демонстрация продукта | Доминирующая тема |
| Окружение продукта | |
| Использование сравнительной рекламы |
5б. Создание размерностей категорий
На данном этапе каждая категория развертывается во множество размерностей, ее определяющих. Кроме того, неизбежно устанавливаются правила, по которым будет происходить измерение категории после определения ее размерностей. Размерности категорий могут браться из самых разных источников: из маркетинговой теории, из предыдущих исследований, из личного опыта исследователя в данной продуктовой группе и т.д. В любом случае, независимо от происхождения, размерности должны задавать последовательно непротиворечивую систему измерения. Вполне очевидно, что они могут быть различных типов. Главное, чтобы они адекватно описывали наличие или отсутствие того или иного признака, количество признака или его типологию, например см. табл. 2.
Таблица 3.2. Пример задания размерности категорий
| Представление продукта | Время показа продукта в секундах |
| Использование женских сексапильных образов | • да • нет |
| Формат рекламы | • только диктор • стилевая • бытовая сценка • рекомендательная • одобряемая знаменитостью |
| Степень эмоциональности — рациональности | • только рациональные мотивы • скорее рациональные мотивы • и рациональные, и эмоциональные мотивы • скорее эмоциональные мотивы • только эмоциональные мотивы |
Как видно из приведенного выше перечня, категории и их размерности можно трактовать как типы вопросов и ответов в анкетах или типы переменных (категориальные, порядковые, интервальные) в статистическом анализе. Поэтому не будем подробно рассматривать категории, остановимся лишь на вопросе о количестве размерностей в категориях. Здесь нет однозначного ответа. С одной стороны, количество размерностей должно быть достаточным для определения значимых различий внутри категории. Допустим, вы хотите проанализировать рекламу некоторого продовольственного товара в категории «Здоровая пища». Тогда такие размерности категории, как «Отсутствие жира», «Отсутствие холестерина», «Полезно для здоровья», не позволят вам в полной мере охватить такое понятие, как «Здоровая пища». С другой стороны, чрезмерное дробление категории, например, «Наличие витамина А», «Наличие витамина В4», «Наличие витамина С» и т.д. — явно не улучшит понимания данной категории и скорее приведет лишь к трудностям при кодировке. Поэтому при создании единой системы категорий и размерностей приходится руководствоваться тремя банальными вещами, о которых не вправе забывать ни один исследователь: элементарным здравым смыслом, имеющимся опытом и обязательным пилотажем.
1Здесь авторы допустили умышленную фактическую ошибку. В целях, так сказать, наглядной демонстрации того, что, приступая к контент-анализу, неплохо бы самому «быть в контенте». Например, вопреки широко распространенному заблуждению, холестерин бывает как вредный, так и полезный: так называемый холестерин высокой плотности и холестерин низкой плотности. Поэтому, формулируя категории и задавая им размерности, всегда полезно для начала осуществить своего рода погружение (immersion) в изучаемую проблематику.
В завершение темы укажем, что многие специалисты рекомендуют при наличии сомнений на всякий случай трактовать их в сторону большего числа размерностей. Их можно понять: объединить размерности в более крупную группу после кодировки можно, а вот разделить на более мелкие — уже нет.
Этап 6. Подготовка кодовых книг и кодовых страниц
По сути, кодовая книга — это словарь проводимого вами контент-анализа. Она должна содержать определения всех терминов, которые используются в анализе. Создание кодовых книг необходимо для того, чтобы все кодировщики понимали анализируемые сообщения максимально одинаково. Принципы создания кодировочных листов аналогичны принципам создания вопросников, только записываются в них не ответы респондентов, а результаты анализа кодировщиками рассматриваемых рекламных объявлений (табл. 3).
Таблица 3.3 Пример кодовой книги
| Категория: Структура объявления в 3040-секундном телевизионном ролике. Использование неожиданных и непредсказуемых элементов в рекламе. Пять размерностей. | |
| Неожиданность в начале | Использование элементов, привлекающих внимание (непонятность, сюрприз, напряженное состояние, неявные вопросы) в первые 10 сек. рекламы |
| Неожиданность в середине | То же, но в середине рекламы (10—20 сек) |
| Неожиданность в конце | То же, но в конце рекламы (последние 10 сек) |
| Неожиданное окружение, применение | Показ продукта в неожиданном интерьере, ракурсе, применении |
| Использование юмора | Использование шуток, каламбуров, гэгов, фарса или других элементов юмора |
| Категория: Основные и дополнительные рекламируемые выгоды продукта. Основной выгоде в рекламе уделяется максимум внимания. Дополнительные выгоды упоминаются только в качестве добавленных к основной выгоде. | |
| Цена | Продукт имеет низкую или наименьшую цену в данной категории |
| Соотношение цена/качество | Наилучшее соотношение цена/качество |
| Чистящие способности | Удаляет как жир, так и пятна от вина, соков и т.п. |
| Концентрация | Результаты достигаются при меньшем расходе продукта |
Таблица 3.4. Пример кодировочного листа
| Реклама № __________ Код марки ___________ Код торговой категории _______ |
| 30-сек. телевизионный ролик Инструкции: Отмотайте пленку на начало. Обнулите секундомер. Просмотрите весь ролик. Отметьте время появления всех наблюдаемых элементов структуры рекламы. Если таких элементов в рекламе нет, отметьте код «Нет таких элементов в рекламе». Неожиданность в начале Неожиданность в середине Неожиданность в конце Неожиданное окружение, применение Использование юмора Нет таких элементов в рекламе |
| Основная рекламируемая выгода Инструкции: Просмотрите все объявление. Отметьте галочкой только одну рекламируемую выгоду, на которой сосредоточено основное время рекламы. Цена Соотношение цена/качество Чистящие способности Концентрация Другое |
| Дополнительные выгоды. Инструкции: Просмотрите все объявление. Отметьте галочкой каждую рекламируемую выгоду, упомянутую в рекламе, кроме основной рекламной выгоды (см. предыдущую категорию). Цена Соотношение цена/качество Чистящие способности Концентрация Другое. |
Этап 7. Отбор и обучение кодировщиков
Из всего вышеизложенного следует, что к отбору и обучению кодировщиков надо подходить со всей тщательностью. Во-первых, кодировщиков должно быть не менее двух. Во-вторых, это должны быть люди с примерно одинаковым опытом и навыками кодировки. В-третьих, важным условием является независимость этих кодировщиков друг от друга и от исследователя, подготавливающего кодовый план. К. Криппендорф особенно отмечал это условие, настаивая, что не может быть ничего хуже, когда кодировкой занимается сам исследователь или же при помощи своих коллег, также участвующих в данном исследовании.
Процесс обучения состоит из ряда этапов. Вначале кодировщики внимательно знакомятся с категориями, их определениями и размерностями категорий, которые представлены в кодовой книге. Это часто игнорируемый, но очень важный этап. Ниже у нас будет возможность проиллюстрировать насущность погружения в исследуемую категорию. После инструктажа кодировщики переходят к практическим занятиям, на которых 1) им показывают образцы объявлений, отобранных для кодировки; 2) которые они кодируют в соответствии с полученными инструкциями; 3) по результатам практической работы проводится обсуждение возникших проблем, оценивается качество кодировки и, при необходимости, проводится дополнительный тренинг.
Этап 8. Пилотаж и коррекция плана исследования
Любой план может быть усовершенствован или скорректирован. Не является исключением и контент-анализ, в котором обязательной стадией является пилотаж кодового плана. Предметом пилотажа является усовершенствование категорий, размерностей, кодировочных листов и инструкций кодировщикам. Обычно пилотаж проводится после обучения кодировщиков на одном и том же наборе объявлений.
Рассмотрим гипотетическую ситуацию. Три кодировщика проанализировали 10 рекламных объявлений и отнесли их к той или иной размерности некой категории (табл. 5)
Таблица 3.5. Пример кодировочного листа
| Кодировщик | Размерность 1 | Размерность 2 | Размерность 3 | Размерность 4 |
| 2,3,6 | 1,4,8 | 5,7,10 | ||
| 1,4,8 | 5,10 | |||
| 2,3,6 | 1,4,8 | 5,7,9 |
Как видно, размерности 1 и 2 хорошо определены: у кодировщиков не возникло разногласий по поводу того, какие объявления отнести к этим размерностям. Однако для размерностей 3 и 4 мнения кодировщиков не совпали, причем весьма кардинально. Следовательно, дефиниции размерностей 3 и 4 должны быть пересмотрены до начала основного анализа.
Вторая задача, которую решает пилотаж, — это оценка степени готовности самих кодировщиков. При затруднении кодировки той или иной категории возможен дополнительный тренинг отдельных кодировщиков. При систематическом несовпадении мнения одного из кодировщиков с остальными он может быть полностью исключен из процесса кодировки.
Этап 9. Кодирование собранного материала и оценка валидности данных
Обучив персонал и отладив кодовый план, можно проводить кодировку основной выборки рекламных объявлений. После того как этот процесс завершен, необходимо оценить надежность кодировки. Под надежностью (достоверностью) в контент-анализе понимается высокая вероятность того, что два и более кодировщика, работая независимо друг от друга, присвоили одни и те же коды одним и тем же элементам в каждом из проанализированных рекламных объявлений. Данный тип надежности, называемый межкодировочной надежностью, может вычисляться по разным методам, но должен быть обязательно проверен до анализа полученных данных. Низкий уровень вычисленной надежности свидетельствует о том, что полученным данным доверять нельзя.
Холсти для вычисления межкодировочной надежности для номинальных категорий рекомендует крайне простую формулу:
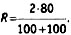
Как видно, метод понятный, простой в вычислениях, однако имеющий тенденцию завышать надежность кодировки, так как не учитывает, что коды могут совпасть и случайно. Допустим, у нас категория имеет две размерности (да — нет). Нетрудно видеть, что, закодировав выборку два раза (имитируя работу двух кодировщиков) с помощью генератора случайных чисел, мы получим надежность, равную примерно 50%. Для решения этой проблемы существуют и другие, более сложные формулы. Однако и они не универсальны, поскольку чувствительны к другим аспектам кодировки. Например, в π-индексе надежность вычисляется с коррекцией на случайные совпадения:
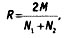
где R — показатель надежности (Reliability), M — общее количество совпавших кодовых элементов у двух кодировщиков, Nl N2 — общее количество закодированных элементов у 1-го и 2-го кодировщика соответственно. Например, если в 80 случаях из 100 мнения кодировщиков совпали, то надежность по Холсти составляет:
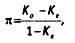
где π — оценка надежности, К0 — процент наблюдаемых совпадений кодировщиков, Ке — процент ожидаемых совпадений. Недостаток данного индекса состоит в его чувствительности к виду распределения закодированных элементов. Хотя методика его подсчета крайне проста: на первом этапе вычисляется процент ожидаемых совпадений, далее по формуле Холсти вычисляется процент наблюдаемых совпадений. Подставляя эти величины в формулу, мы и получим π-индекс. Например, в нашем гипотетическом примере с чистящими средствами основные рекламируемые выгоды распределились следующим образом (%):
- цена — 30,
- соотношение цена/качество — 25,
- чистящие способности — 15,
- концентрация —10,
- другое —10,
- не обнаружено — 10.
Тогда процент ожидаемых совпадений равен 0,205 (0,302 + 0,252 + 0,152 + 0,1002 + 0,102 + 0,102 = 0,205), а процент наблюдаемых совпадений возьмем из предыдущего примера — 80%. Тогда:
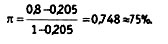
Перро и Лей разработали другой подход к коррекции межкодировочной надежности. Эта формула также не свободна от недостатков, в частности, она зависит от количества размерностей в категории. В каноническом виде она выглядит следующим образом:
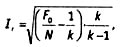
где F0 — количество совпавших кодовых элементов, N — общее количество кодовых элементов, k — количество размерностей в категории. Например, взяв предыдущие данные, мы получим F0 = 80, N = 100, k = 6. Оценка надежности по Перро-Лею составит:
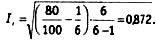
Но, пожалуй, одной из наиболее часто применяемых мер согласия является «каппа Коэна» (Cohen's kappa), вычисляемая по формуле:
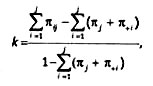
где πjj — вероятность того, что кодировщик 1 закодирует объект размерностью і, а кодировщик 2 закодирует этот же объект размерностью j. Или, другими словами, это разность между долями согласных и несогласных ответов, деленная на разность между 1 и долей несогласных ответов:
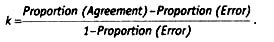
Понятно, что каппа (() может изменяться от 1 (полное согласие двух кодировщиков в оценке объектов) до -1 (полное несогласие). Особый случай, когда каппа равна 0. Это означает, что с таким же успехом можно было бы попросить оценить объекты два генератора случайных чисел.
Все вышеприведенные формулы предназначены для номинальных категорий, и все в той или иной мере используются в контент-анализе. Но, независимо от используемой формулы, приемлемым считается уровень надежности не менее 80%.
Для оценки надежности порядковых и интервальных категорий используются обычные корреляции и ранговые корреляции. Однако здесь существует опасность ошибки при оценке надежности, связанная с тем, что корреляционные коэффициенты указывают направление связи, ничего не говоря о самих значениях. Предположим, мы оцениваем по 5-балльной шкале уровень эмоциональных мотиваций в рекламе, где 1 — «полное отсутствие эмоциональных мотиваций», а 5 — «наличие только эмоциональных мотиваций» (табл. 6):
Таблица 6. Пример таблицы сопоставления оценок различных кодировщиков
| № ролика | Оценка кодировщика 1 | Оценка кодировщика 2 |
Считаем коэффициент ранговой корреляции. Получаем +1.0, надежность стопроцентная, хотя даже на глаз видно, что кодировщик 1 гораздо ниже оценивает наличие эмоциональных мотивов в рекламе.
Дата добавления: 2016-07-22; просмотров: 2843;
Поиск по сайту
Узнать еще
- A ... метка (без метки) на шатуне (стрелка) для 26.20b Измерение внутреннего диаметра
- Andante cantabile con espressione В. Моцарт. Соната для ф-п. № 8, ч. II
- Andantino con moto А. Бородин. Для берегов отчизны дальней
- Audit Trail - Материалы для проведения аудиторской проверки
- D-технология построения чертежа. Типовые объемные тела: призма, цилиндр, конус, сфера, тор, клин. Построение тел выдавливанием и вращением. Разрезы, сечения.
- I. Установка для исследования сдвига фаз колебаний силы тока и напряжения с помощью компьютера и осциллографа-приставки
- I.10. Тесты для контроля знаний
- II.1.2 ПРИМЕРЫ РЕШЕНИЯ ЗАДАЧ

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
