Система поиска документов
Архитектура. Хотя архитектура различных веб-поисковых систем может отличаться, типичная система поиска документов обычно состоит из следующих четырех основных компонентов, как показано на рисунке. 1: Поисковый робот, индексатор, индексная база данных и механизм запросов. Веб-сканер, также известный как веб-паук или веб-робот, перемещается по Сети для поиска веб-страниц, следуя их URL-адресам.
Индексатор отвечает за разбор текста каждой веб-страницы на лексемы word, а затем создает индексную базу данных, используя все выбранные веб-страницы. Когда пользователь получает запрос, механизм запросов выполняет поиск в индексной базе данных, чтобы найти веб-страницы, соответствующие запросу.
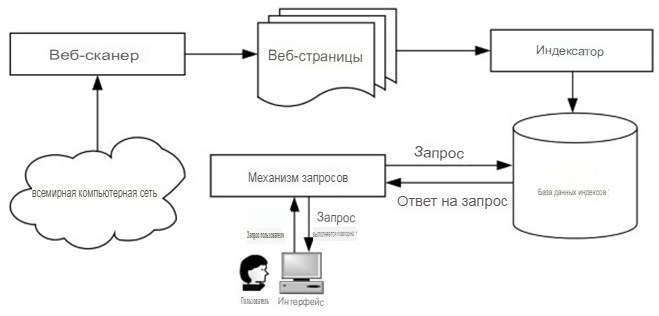
Рисунок 1. Общая архитектура системы поиска документов
Поиск в Интернете. Поисковый робот - это компьютерная программа, которая извлекает веб-страницы с удаленных веб-серверов. URL-адрес каждой веб-страницы определяет местоположение страницы в Интернете. Учитывая URL-адрес веб-страницы, ее можно загрузить с веб-сервера, используя HTTP (протокол передачи гипертекста). Начиная с некоторых исходных URL-адресов, поисковый робот повторно выбирает веб-страницы на основе их URL-адресов и извлекает новые URL-адреса из загруженных страниц, чтобы можно было загрузить больше страниц.
Этот процесс завершается, когда выполняются некоторые условия завершения. Некоторые возможные условия завершения включают в себя отсутствие новых URL-адресов и загрузку заданного количества страниц. Поскольку веб-сканер может взаимодействовать с множеством автономных веб-серверов, важно разработать масштабируемые и эффективные поисковые роботы.
Для быстрого сканирования веб-страниц можно использовать несколько сканеров. Эти сканеры могут работать двумя различными способами (т.е. централизованно и распределенно). Централизованные сканеры расположены в одном и том же месте и работают параллельно на разных компьютерах.
Распределенные поисковые роботы расположены в разных точках Интернета и управляются центральным координатором; каждый поисковый робот просто обрабатывает веб-сайты, географически близкие к местоположению поискового робота. Наиболее существенным преимуществом распределенных поисковых систем является снижение затрат на связь, связанных с поиском. Однако централизованные поисковые роботы проще внедрять и контролировать, чем распределенные.
Поскольку сеть растет и постоянно меняется, необходимо, чтобы поисковые роботы регулярно выполняли повторный поиск в Интернете и обновляли содержимое базы данных index. Частый повторный обход веб-страниц приведет к потере значительных ресурсов и перегрузке сети и веб-серверов.
Поэтому следует использовать несколько стратегий поэтапного обхода. Одна из стратегий заключается в повторном обходе только измененных или недавно добавленных веб-страниц с момента последнего обхода.
Другая стратегия заключается в использовании тематических сканеров для обхода веб-страниц, относящихся к заранее определенному набору тем. Тематический обход также может быть использован для создания специализированных поисковых систем, которые заинтересованы только в веб-страницах определенной тематики.
Обычные веб-сканеры способны сканировать только веб-страницы в поверхностной сети. Поисковые роботы Deep Web предназначены для поиска информации в глубокой сети. Поскольку информация в Deep Web часто скрыта за поисковыми интерфейсами источников данных Deep Web, поисковые роботы Deep Web обычно собирают данные, отправляя запросы в эти поисковые интерфейсы и собирая возвращаемые результаты.
Индексация веб-страниц. После того, как веб-страницы собраны на сайте поисковой системы, они предварительно обрабатываются в формате, который подходит для эффективного поиска поисковыми системами. Содержимое страницы может быть представлено словами, которые на ней есть.
Слова, не связанные с содержанием, такие как ‘the’ и ‘is’, обычно не используются для отображения на странице. Часто слова преобразуются в их основы с помощью программы для определения основы, чтобы облегчить сопоставление различных вариантов одного и того же слова. Например, ‘вычислять’ - это общая основа слов ‘вычислять’ и ‘computing’.
После удаления на странице слов, не являющихся содержательными, и их перестановки для представления страницы используются оставшиеся слова (называемые терминами или индексными терминами). Фразы также могут быть распознаны как специальные термины. Кроме того, каждому термину присваивается определенный вес, чтобы отразить его важность для представления содержимого страницы.
Вес термина t на странице p в пределах заданного набора страниц P может быть определен несколькими способами. Если мы рассматриваем каждую страницу как обычный текстовый документ, то вес термина t обычно вычисляется на основе двух статистических данных. Первое - это частота использования термина (tf) в P (т.е. количество раз, когда t появляется в p), а второе - частота использования документа (df) в P (т.е. количество страниц в P, содержащих t). Интуитивно понятно, что чем чаще термин встречается на странице, тем важнее он для представления содержимого страницы.
Следовательно, значение t в p должно быть монотонно возрастающей функцией частоты встречаемости термина. С другой стороны, чем больше страниц содержит термин, тем менее полезен термин для дифференциации различных страниц. В результате вес термина должен быть монотонно убывающей функцией его частоты использования в документах.
В настоящее время большинство веб-страниц отформатированы в формате HTML, который содержит набор тегов, таких как заголовок. Информация о тегах может использоваться для определения значимости терминов для представления веб-страниц. Например, термины в заголовке страницы или выделенные жирным шрифтом и курсивом, вероятно, будут более важны для представления страницы, чем термины в основной части страницы обычным шрифтом.
Чтобы обеспечить эффективный поиск веб-страниц по любому заданному запросу, представления выбранных веб-страниц организованы в виде перевернутой файловой структуры. Для каждого термина t генерируется и сохраняется инвертированный список формата [(p1, w1),..., (pk, wk)], где каждый pj является идентификатором страницы, содержащей t, а wj - весом t в pj, 1≤j≤k. Сохраняются только записи с положительными весами.
Дата добавления: 2024-07-23; просмотров: 522;
Поиск по сайту
Узнать еще
- Автоматизированная система наблюдения за состоянием кардиологических больных
- Амортизационная система шасси
- Балочная инженерно-биологическая система. Усиление аккумулирующей способности насаждений – илофильтров
- Врожденный иммунитет. Система приобретенного иммунитета животных
- Головной мозг. Нервная система человека
- Деятельность мозга – нормального и эпилептического. Система передачи и интерпретации данных сознания
- Динамический анализ. Продвижение разломов в сложных системах
- Дыхательная система человека. Частота дыхания

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
