Числовые характеристики вариационного ряда.
МодаМо* – значение вариационного ряда, имеющее наибольшую частоту.
Размах вариаций R = 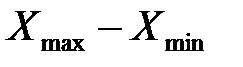 .
.
Медиана Ме* – серединное значение вариационного ряда. Если ряд имеет нечётное число членов, то медиана равна члену ряда, находящемуся посередине. Если ряд имеет чётное число членов, то медиана равна среднему арифметическому двух членов, расположенных в середине вариационного (проранжированного) ряда: 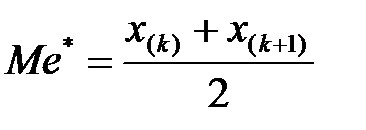 , если n=2k – чётное;
, если n=2k – чётное; 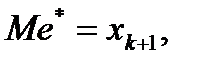 если n=2k+1 – нечётное.
если n=2k+1 – нечётное.
Если мода, медиана и среднее выборочное почти не отличаются друг от друга, то можно говорить о симметричности распределения изучаемого признака.
Пример. По данным задачи 1 вычислите очисловые характеристики статистического распределения и вариационного ряда.
Решение. 1) Используем дискретный статистический ряд, построенный в задаче 1.
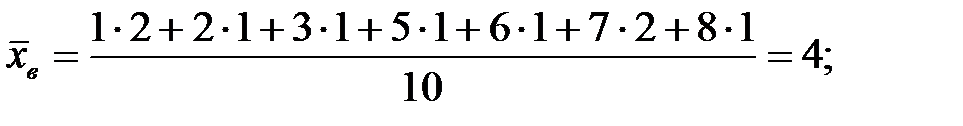
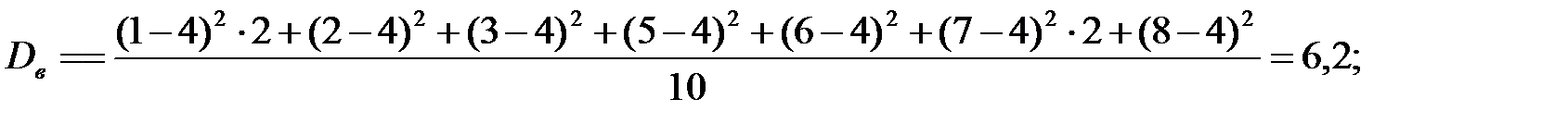
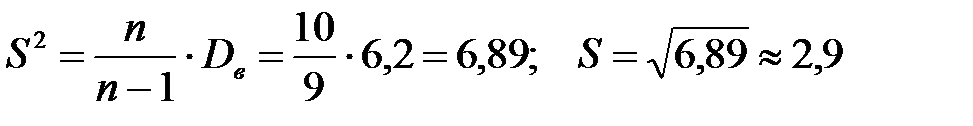
Мо=1; Ме=(3+5)/2=4; R=8-1=7.
Ответ: Средняя длина словоупотреблений в прозе Зинаиды Гиппиус равна 4 со стандартным отклонением 2,9. Так как Мо; Ме и 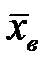 имеют не близкие значения, то длины словоупотреблений распределены неравномерно.
имеют не близкие значения, то длины словоупотреблений распределены неравномерно.
2) Используя интервальный статистический ряд, построенный в задаче 2, построим дискретный ряд из середин интервалов:
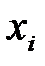
| ||||||||
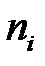
|
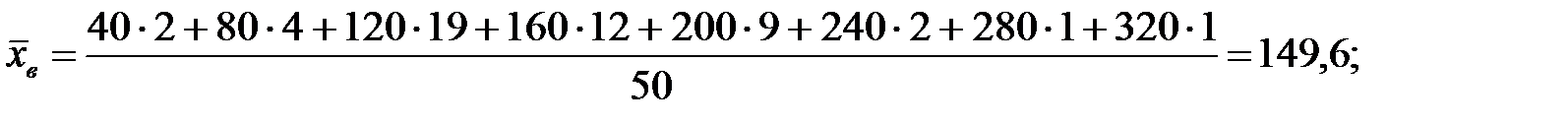 Найдём числовые характеристики для полученного ряда.
Найдём числовые характеристики для полученного ряда.
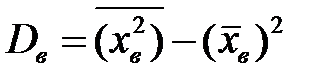 Выборочную дисперсию определим по формуле
Выборочную дисперсию определим по формуле
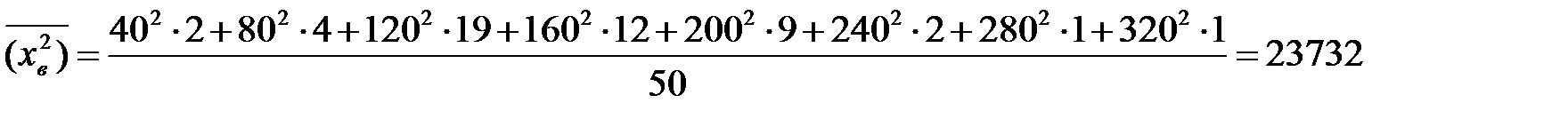
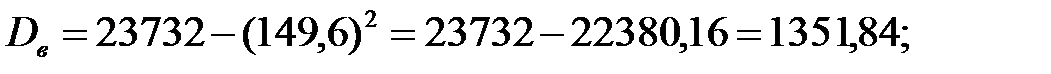
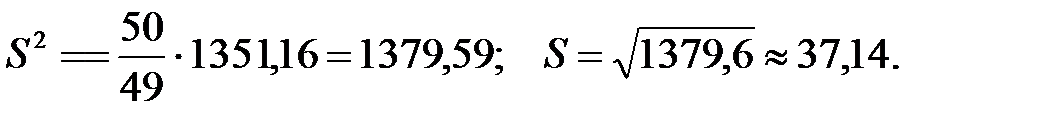
Ответ: Приближённая среднее время произношения китайского слога 150 м/с со стандартным отклонением 37 м/с.
В лингвистических исследованиях встречаются ситуации, когда дать точную количественную характеристику признака (метрическое шкалирование) невозможно или нецелесообразно. В этом случае используют порядковое или номинативное шкалирование.
Порядковое шкалирование используют в том случае, когда условие эксперимента позвляют нам ранжировать варианты. Например, при составлении частотных словарей опирающихся на малые выборки, пользоваться частотами отдельных слов нецелесообразно, поскольку статистическая ошибка при определении этих частот велика. Поэтому, здесь рассматривается порядок (ранг) расположения отдельных форм или словосочетаний.
Номинативное шкалирование применяют тогда, когда признак лингвистических единиц не может быть оценен количественно и не содержит возможности их ранжирования. Пользуясь определённым правилом, объекты группируются по разным классам так, чтобы внутри класса они были идентичны по измеряемому свойству. Каждому классу даётся наименование и обозначение, обычно числовое. Примером может служить группировка словоформ по семантическим или грамматическим классам.
Дата добавления: 2016-06-05; просмотров: 2524;
Поиск по сайту
Узнать еще
- II. Физические характеристики участников коммуникации
- U – образные и рабочие характеристики синхронного двигателя
- U – образные характеристики синхронного генератора
- U-образные характеристики
- XIII. ЭНЕРГЕТИЧЕСКИЕ ХАРАКТЕРИСТИКИ ОБОРУДОВАНИЯ
- Амплитудо-частотная и фазо - частотная характеристики усилителя .
- Анализ динамического ряда. Вычисление основных показателей динамического ряда
- Аналоговые усилители. Классификация. Основные характеристики и параметры усилителей

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
