Функции хеширования
Рассмотрим примеры реализации хеш-функций. Функция должна принимать ключ элемента и преобразовывать его в значение индекса. Если в таблице предусмотрено место для n элементов, то функция хеширования должна генерировать значения индексов, лежащих в диапазоне 0..n-1. Кроме того, для различных типов ключей должны быть использованы различные функции. В идеале функция хеширования должна создавать значение индексов, которые никак не связаны с ключами. В определенном смысле хеш-функция должны быть подобна функции рандомизации, т.е. очень похожие ключи должны приводить к созданию совершенно различных хеш-значений.
Простейший случай – использование целочисленных ключей, когда элемент уникально идентифицируется целочисленным значением. Самой простой функцией будет операция деления по модулю. Если хеш-таблица содержит n элементов, хеш-значение ключа k равно:
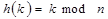
Для случае равномерного распределения значений ключей такая функция вполне подходила бы, но в общем случае множество не столь равномерно распределенное, и поэтому в качестве размера таблицы необходимо использовать простое число. Математическое обоснование этого утверждения можно найти в [6].
Для строковых ключей следует использовать метод преобразования строки в целочисленное значение. Один из таких способов заключается в расчете суммы всех ASCII-значений кодов символов строки. Однако ключи могут быть анаграммами друг друга, и применение такой схемы приводило бы к конфликтам. Для исключения влияния анаграмм при их использовании в качестве ключей применяют весовые коэффициенты, соответствующие позиции каждого символа в строке.
Пример реализации простой функции хеширования строковых ключей приведен ниже.
function SimpleHash(aKey: string; aTableSize: Integer): Integer;
Var
i: Integer;
Hash: LongInt;
Begin
Hash:=0;
for i:=1 to Length(aKey) do
Hash:=((Hash*17)+ord(aKey[i])) mod aTableSize;
Result:=Hash;
if Result < 0 then
Inc(Result, aTableSize);
end;
Функция принимает в качестве параметров значение строкового ключа и размер таблицы. Алгоритм поддерживает постоянно изменяющееся хеш-значение, изначально установленное равным нулю. Это значение изменяется для каждого символа в строке путем его умножения на небольшое простое число, добавления кода следующего символа и деления по модулю на размер таблицы. Если конечное значение окажется отрицательным (особенность операции деления по модулю в Delphi), к результату добавится значение размера таблицы.
Другая известная функция, именуемая ELF-хешем (формат исполняемых и компонуемых модуле, Executable and Linking Foramt), была предложена П.Дж.Вайнбергером. Отличие алгоритма от приведенного выше заключается в применении эффекта рандомизации, когда операция XOR вновь загружает старший полубайт действующей рабочей переменной хеша (полубайт, который должен исчезнуть в результате переполнения при выполнении следующей операции умножения), если он не равен нулю, в младшую часть переменной. Затем старший полубайт устанавливается в ноль, в результате чего хеш-значение никогда не будет неотрицательным.
function SimpleHash(aKey: string; aTableSize: Integer): Integer;
Var
i: Integer;
G,Hash: LongInt;
Begin
Hash:=0;
for i:=1 to Length(aKey) do
Hash:=(Hash shl 4)+ord(aKey[i]);
G:=Hash and LongInt($F0000000);
if G <> 0 then
Hash:=(Hash xor (G shr 24)) xor G;
Result:=Hash mod aTableSize;
end;
Функция превосходит предыдущую реализацию благодаря эффекту рандомизации и выполнении для каждого символа только операций поразрядного сдвига и логических операций. В общем случае ее можно считать наилучшей.
Дата добавления: 2021-12-14; просмотров: 469;
Поиск по сайту
Узнать еще
- F06 Другие психические расстройства вследствие повреждения или дисфункции головного мозга, либо вследствие физической болезни
- I. 2. Функции крови
- I. 3. Функции минеральных веществ плазмы крови
- I. 4. Функции белков плазмы крови
- I. Кейнсианские функции потребления и сбережений.
- I. ФУНКЦИИ ЦЕНТРАЛЬНОГО БАНКА.
- III. Основные функции ГФС России
- III.1.3. ПРИЧИНЫ НАРУШЕНИЙ СЛУХА. ПСИХОЛОГО-ПЕДАГОГИЧЕСКАЯ КЛАССИФИКАЦИЯ НАРУШЕНИЙ СЛУХОВОЙ ФУНКЦИИ У ДЕТЕЙ

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
