Архитектура вычислительных систем
В настоящее время достигнут физический предел роста производительности однопроцессорных компьютеров. Ряд методов повышения быстродействия основан на расширениях традиционной фон-неймановской архитектуры [48]. Среди них:
· конвейерная обработка данных и команд;
· Параллельное выполнение команд и использование RISC-процессоров с сокращенным набором команд, выполняющихся обычно за 1-2 такта;
· векторная обработка данных;
· использование многоядерных процессоров и многопроцессорных систем.
Конвейер предусматривает разбиение сложной операции на несколько более простых, которые могут выполняться одновременно на отдельных аппаратных блоках. Увеличение производительности достигается за счет параллельного выполнения команд при движении объекта по конвейеру (конвейеры команд) и в арифметических операциях, когда при сложении данных, хранящихся в представлении с плавающей точкой отдельно обрабатываются порядки и мантиссы (конвейеры данных). Конвейерная обработка усложняет структуру процессора, поэтому эффект ускорения обработки данных может проявляться при выполнении векторных операций. Для отсутствия конфликтов, приводящих к простоям конвейера, обрабатываемые им объекты должны быть независимыми. Выделяют три типа конфликтов конвейерной обработки:
· структурные конфликты (одновременный запрос на использование одного ресурса (например, памяти) несколькими командами, для их устранения используется дублирование ресурсов (например, кэш-память), что усложняет конструкцию процессора и его стоимость;
· конфликты по данным из-за логической зависимости команд между собой (для выполнения одной команды требуется результат другой);
· конфликты по управлению из-за условных операторов (ветвлений), для устранения простоев специальные устройства выполняют выборку команд и помещают их в специальные очереди до того, как они могут понадобиться. При этом в блоках предсказания переходов [64] “про запас” может выполняться обработка данных для каждой возможной ветви алгоритма.
Для организации параллельной обработки данных используются два подхода:
· в суперскалярных процессорах реализована динамическая загрузка команд, основанная на анализе программного кода во время его выполнения, почти все современные процессоры - суперскалярные;
· в процессорах со сверхдлинным командным словом реализован статический подход, поддерживаемый компилятором, выполняющим предварительное выявление команд, которые могут выполняться параллельно и “упаковываются” в одну большую команду.
RISC-архитектура (Reduced Instruction Set Computer), основанная на ускорении работы процессора за счет упрощения набора команд противоположна CISC-архитектуре (Complete Instruction Set Computer) процессоров со сложным набором команд. Простые RISC-команды реализуются аппаратно, упрощают процесс управления, позволяют эффективно реализовать выполнение команд и конвейерную обработку данных. Реализация более сложных CISC-команд требуют микропрограммирования. В настоящее время вычислительные системы с RISC-архитектурой лидируют на компьютерном рынке рабочих станций и серверов, в то время как в персональных компьютерах используется CISC-архитектура.
Современные CISC-процессоры способны выполнять несколько инструкций за такт: Athlon 64 – три инструкции за такт (Pentium 4 – от 2 до 4), одовременно производя три (Р4 – две) операции по адресации и выборке данных из оперативной памяти. Во всех современных серверных, десктопных и мобильных процессорах AMD используется архитектура К8. Эффективная длина конвейера варьируется от 10-12 стадий (для целочисленных, логических вычислений и обращений к оперативной памяти) до 17 стадий (вычисления с плавающей точкой) [64]. В основе процессоров Pentium 4, Xeon и Celeron лежит архитектура NetBurst. Эффективная длина конвейера в зависимости от варианта составляет 20 или 31 стадию. Для резкого повышения тактовых частот ядра процессора использована асинхронность – независимость работы всех стадий конвейера.
Векторные процессоры позволяют в одной команде выполнять операции над элементами массивов, например, произвести поэлементное сложение двух массивов. Каждый операнд при этом хранится в особом векторном регистре. С точки зрения программиста, при работе на компьютере с векторной архитектурой операции, применимые к обычным переменным, можно использовать для массивов. Алгоритмические реализации такой технологии включены в математическую систему MathCAD и в язык программирования Fortran-90. Это упрощает этап программирования и решения задач на компьютерах с обычными процессорами.
Организацию многопроцессорных систем характеризуют:
· количество и архитектура индивидуальных процессоров;
· структура и организация доступа к оперативной памяти;
· топология коммуникационной сети и ее быстродействие;
· работа с устройствами ввода/вывода.
Дальнейший рост производительности вычислений и обработки данных связывается с вычислительными системами (в первую очередь многопроцессорными) и с распределенными вычислениями в компьютерных сетях (локальных и глобальных). Основными типами архитектуры вычислительных систем являются [48]:
| 1. SISD (Single Instruction stream – Single Data stream) – один поток команд и один поток данных (ОКОД – Одна Команда, Одни Данные), рис. 3.1. Такой тип имеют однопроцессорные персональные компьютеры. 2. SIMD (Single Instruction stream – Multipe Data stream) – один поток команд и несколько потоков данных (ОКМД - Одна Команда, Много Данных). SIMD-компьютеры (рис. 3.2) состоят из одного командного процессора (контроллера) и нескольких | 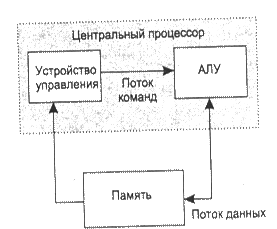 Рис. 3.1. Схема SISD-компьютера
Рис. 3.1. Схема SISD-компьютера
|
модулей обработки данных (процессорных элементов, ПЭ) с числом от 1024 до 16384. Контроллер принимает, анализирует и выполняет команды. Если в команде встречаются данные, контроллер рассылает на все ПЭ команду и она выполняется на нескольких или всех ПЭ. Примерами SIMD-компьютеров являются векторные и матричные процессоры.


Рис. 3.2. Схемы SIMD-компьютеры с разделяемой (слева) и распределенной (справа) памятью
3. MISD (Multipe Instruction stream – Single Data stream) – несколько потоков команд и один поток данных (МКОД - Много Команд, Одни Данные). Один набор данных по конвейеру передается от одного устройства (специализированного на выполнении одной команды или одного типа команд) к другому, рис. 3.3. Вычислительных машин такого класса мало.
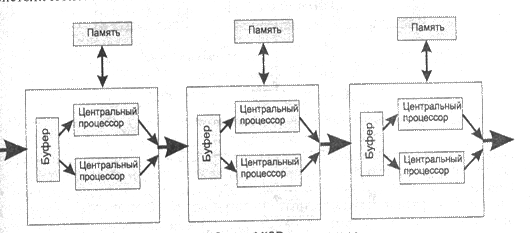
Рис. 3.3. Схема MISD-компьютера
4. MIMD (Multipe Instruction stream – Multipe Data stream) – несколько потоков команд и несколько потоков данных (МКМД – Много Команд Много Данных). Выполняется сложная (многокомандная) параллельная обработка большого потока данных. Для этой архитектуры известно наибольшее число успешных реализаций [48].

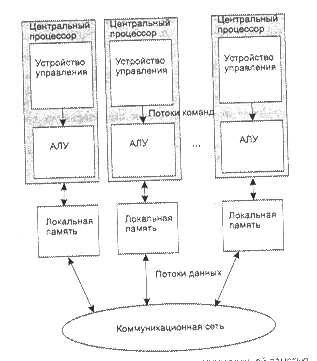
Рис. 3.4. Схемы МIMD-компьютеры с разделяемой (выше) и распределенной (ниже) памятью
Развитием MIMD-архитектуры является распределенная обработка данных, когда вместо набора процессоров в одном корпусе используются компьютеры, связанные достаточно быстрой сетью.
Важнейшим элементом архитектуры любого компьютера, в особенности высокопроизводительных вычислительных систем, является коммуникационная сеть, связывающая процессоры (ПЭ) с оперативной памятью, процессоры между собой, процессоры с другими устройствами. Ее производительность определяет производительность всей системы. Трафик в такой сети состоит из пересылаемых данных и команд. Приведем определения основных понятий [48]:
· Топологией вычислительной системы называется организация ее внутренних коммуникаций.
· Соседними узлами называются узлы с прямым соединением.
· Порядком узла называется количество его соседей.
· Коммуникационным диаметром сети называется наибольший из путей между любыми двумя узлами.
· Масштабируемость характеризует возрастание сложности соединений при добавлении в конфигурацию новых узлов. Если система обладает высокой степенью масштабируемости, ее сложность будет незначительно изменяться при наращивании системы, неизменным будет и диаметр сети.
Есть два типа топологий коммуникационных сетей:
· статические, при которых все соединения фиксированы, и
· динамические с переключателями в межпроцессорных соединениях.
Примерами статических топологий являются:
· соединение с помощью одиночной шины (рис. 3.5а) – в каждый момент возможна только одна пересылка данных/команд, пропускная способность обратно пропорциональна числу ПЭ, применяется при числе ПЭ не более 10;
· одномерная решетка (рис. 3.5б) и кольцо (рис. 3.5в) эффективнее предыдущего способа;
· двумерная решетка (рис. 4.5г) обеспечивает хорошее быстродействие, распространенность двумерной и трехмерной решеток обусловлена подобной структурой многих научно-технических задач;
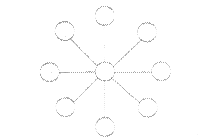
· топология “звезда” (рис. 3.5д) с центральным ПЭ, соединенным с остальными ПЭ, поскольку слабым звеном оказывается центральный ПЭ, эта топология не применяется для больших систем;
· полносвязная топология, в которой все ПЭ связаны друг с другом, что требует маршрутизации пакетов с данными. Быстродействие и стоимость велики, причем стоимость быстро растет с ростом числа ПЭ;
· топология “гиперкуб” (рис. 3.5ж-и) является хорошо масштабируемой и поэтому распространенной, также требуется маршрутизация пакетов.
·

а

б в

г д
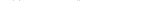

е ж з и
Рис. 3.5. Статические топологии: соединение с помощью шины (а), одномерная решетка (б), кольцо (в), плоская решетка (в), соединение “звезда”, сеть с полносвязной топологией (е), гиперкубы: одномерный (ж), двумерный (з), четырехмерный (и)
Примерами динамических топологий являются:
· перекрестное соединение (рис. 4.6 вверху), обеспечивающее полную связность;
· многокаскадные сети, основанные на использовании 2х2 перекрестных переключателей – коммутаторов (рис. 3.6 внизу).
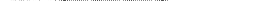
Рис. 3.6.Динамические топологии: схема перекрестного соединения

Рис. 3.7.Динамические топологии: переключатели без широковещательной рассылки (а) и с широковещательной рассылкой (б)
Дата добавления: 2017-01-16; просмотров: 3724;
Поиск по сайту
Узнать еще
- Arthropoda. Клещи. Систематика. Морфология. Медицинское значение.
- Arthropoda. Паукообразные. Систематика. Географическое распространение. Морфология. Скорпионы. Пауки. Медицинское значение.
- Arthropoda..Систематика.Насекомые.Морфология.Классификация.Медицинское значение.
- Arthropoda.Систематика.Блохи.Виды блох.Географическое распространение.Морфология,развитие,патогенное действие.Медицинское и эпидемиологическое значение.Меры борьбы.
- Arthropoda.Систематика.Мошки,мокрецы,слепни,оводы.Географическое распространение.Морфология,развитие,патогенное действие.Медицинское значение,меры борьбы.
- Arthropoda.Систематика.Тараканы и мухи.Географическое распространение.Основные представители.Морфология,развитие,патогенное действие.Медицинское знаение.Меры борьбы.
- Cимпатическая нервная система. Центральный и периферический отдел симпатической нервной системы.
- Cистеми числення і способи переведення чисел із однієї системи числення в іншу

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
