Информационная технология обработки данных
Информационная технология обработки данных [12,13] предназначена для решения хорошо структурированных задач, по которым имеются необходимые входные данные и известны алгоритмы и другие стандартные процедуры их обработки. Эта технология применяется на уровне операционной (исполнительской) деятельности персонала невысокой квалификации в целях автоматизации некоторых рутинных постоянно повторяющихся операций управленческою труда. Поэтому внедрение информационных технологий и систем на этом уровне существенно повысит производительность труда персонала, освободит его от рутинных операций, возможно, даже приведет к необходимости сокращения численности работников.
Примером может послужить ежедневный отчет о поступлениях и выдачах наличных средств банком, формируемый в целях контроля баланса наличных средств, или же запрос к базе данных по кадрам, который позволит получить данные о требованиях, предъявляемых к кандидатам на занятие определенной должности.
Существует несколько особенностей, связанных с обработкой данных, отличающих данную технологию от всех прочих:
· выполнение необходимых организации задач по обработке данных. Каждой организации предписано законом иметь и хранить данные о своей деятельности, которые можно использовать как средство обеспечения и поддержания контроля в организации. Поэтому, в любой организации обязательно должна быть информационная система обработки данных и разработана соответствующая информационная технология;
· решение только хорошо структурированных задач, для которых можно разработать алгоритм;
· выполнение стандартных процедур обработки. Существующие стандарты определяют типовые процедуры обработки данных и предписывают их соблюдение организациями всех видов;
· выполнение основного объема работ в автоматическом режиме с минимальным участием человека;
· использование детализированных данных. Записи о деятельности фирмы имеют детальный (подробный) характер, допускающий проведение ревизий. В процессе ревизии деятельность фирмы проверяется хронологически от начала периода к его концу и от конца к началу;
· акцент на хронологию событий;
· требование минимальной помощи в решении проблем со стороны специалистов других уровней.
Хранение данных. Многие данные на уровне операционной деятельности необходимо сохранять для последующего использования либо здесь же, либо на другом уровне. Для их хранения создаются базы данных.
Создание отчетов (документов). В информационной технологии обработки данных необходимо создавать документы для руководства и работников фирмы, а также для внешних партнеров. При этом документы могут создаваться как по запросу или в связи с проведенной фирмой операцией, так и периодически в конце каждого месяца, квартала или года.
1.7 Информационная технология управления
Целью информационной технологии управления [15,17] является удовлетворение информационных потребностей всех без исключения сотрудников фирмы, имеющих дело с принятием решений. Она может быть полезна на любом уровне управления.
Эта технология ориентирована на работу в среде информационной системы управления и используется при худшей структурированности решаемых задач, если их сравнивать с задачами, решаемыми с помощью информационной технологии обработки данных.
Информационная технология управления идеально подходит для удовлетворения сходных информационных потребностей работником различных функциональных подсистем (подразделений) или уровней управления фирмой. Поставляемая ими информация содержит сведения о прошлом, настоящем и вероятном будущем фирмы. Эта информация имеет вид регулярных или специальных управленческих отчетов.
Для принятия решений на уровне управленческого контроля информация должна быть представлена в агрегированном виде, так, чтобы просматривались тенденции изменения данных, причины возникших отклонений и возможные решения. На этом этапе решаются следующие задачи обработки данных:
• оценка планируемого состояния объекта управления;
• оценка отклонений от планируемого состояния;
• выявление причин отклонений;
• анализ возможных решений и действий.
Информационная технология управления направлена на создание различных видов отчетов. Регулярные отчеты создаются в соответствии с установленным графиком, определяющим время их создания, например месячный анализ продаж компании.
Специальные отчеты создаются по запросам управленцев или когда в компании произошло что-то незапланированное. И те, и другие виды отчетов могут иметь форму суммирующих, сравнительных и чрезвычайных отчетов.
В суммирующих отчетах данные объединены в отдельные группы, отсортированы и представлены в виде промежуточных и окончательных итогов по отдельным полям.
Сравнительные отчеты содержат данные, полученные из различных источников или классифицированные по различным признакам и используемые для целей сравнения.
Чрезвычайные отчеты содержат данные исключительного (чрезвычайного) характера.
Использование отчетов для поддержки управления оказывается особенно эффективным при реализации так называемого управления по отклонениям. Управление по отклонениям предполагает, что главным содержанием, получаемых менеджером данных, должны являться отклонения состояния хозяйственной деятельности фирмы от некоторых установленных стандартов (например, от ее запланированного состояния). При использовании в организации принципов управления по отклонениям к создаваемым отчетам предъявляются следующие требования:
• отчет должен создаваться только тогда, когда отклонение произошло;
• сведения в отчете должны быть отсортированы по значению критического для данного отклонения показателя;
• все отклонения желательно показать вместе, чтобы менеджер мог уловить существующую между ними связь;
• в отчете необходимо показать количественное отклонение от нормы.
Основные компоненты
Входная информация поступает из систем операционного уровня. Выходная информация формируется в виде управленческих отчетов в удобном для принятия решения виде. Содержимое базы данных при помощи соответствующего программного обеспечения преобразуется в периодические и специальные отчеты, поступающие к специалистам, участвующим в принятии решений в организации. База данных, используемая для получения указанной информации, должна состоять из двух элементов:
1) данных, накапливаемых на основе оценки операций, проводимых фирмой;
2) планов, стандартов, бюджетов и других нормативных документов, определяющих планируемое состояние объекта управления (подразделения фирмы).
1.8. Сферы применения информационных технологий
Более полувека тому назад Норберт Винер опубликовал книгу "Кибернетика, или управление и связь в животном и машине", возвестившую о становлении новой науки – кибернетики, в которой информационно–управленческая связь в явлениях материального мира выступает как его фундаментальное свойство. Это понимание дало мощный толчок развитию вычислительных систем и их применению во многих отраслях знания и бизнеса.
Сферы применения информационных технологий в современном обществе чрезвычайно велики. В таблице 2.1 приведены основные и производные сферы использования ИТ.
В современном обществе основным технологическим средством накопления, переработки и защиты информации служит корпоративный и/или персональный компьютер и программная среда, которые существенно повлияли как на концепцию построения и использования технологических процессов, так и на качество результата. Внедрение персонального компьютера в информационную сферу и применение телекоммуникационных средств связи определили новый этап развития ИТ и, как следствие, изменение названия технологии за счет присоединения одного из символов: «новая», «компьютерная» или «современная» (таблица 2.2).
Таблица 1.1.
Сферы применения информационных технологий
| Экономика | Политика | Культура | Наука |
| Производственные отношения | Государство | Эпохи | Теория |
| Производство | Власть | Уклады | Методы |
| Финансы | Общество | Традиции | Средства |
| Бизнес–правила | Международные и региональные организации и отношения | Религия | Систематизация |
| Взаимодействие | Партии | Национальные ценности | Научно–технические революции |
| Продукт | Общественные организации | Этика | Применение |
| Услуга | Искусство | Результаты | |
| Система | Образование | Последствия | |
| Качество | Спорт | ||
| Потребитель |
Таблица 1.2
Изменения названия технологии
| Методология | Основной признак | Результат |
| Целенаправленные создание, хранение, передача и отображение информации | Учет закономерностей изменения социальной среды и бизнеса. Ориентация на знания | Новые подходы к организации производства. Смещение фокуса на потребителя |
| Новая технология обработки информации | Целостные технологические информационные системы | Интеграция функций специалистов и менеджеров |
| Принципиально новые средства обработки информации | "Встраивание" в технологию управления | Новые технологии принятия управленческих решений |
Таким образом, понятие информационная технология является емким понятием, отражающим современное представление о процессах преобразования и потребления информации в информационном обществе.
1.8.1. Обработка информации
Понятие обработки информации является весьма широким. Ведя речь об обработке информации, следует дать понятие инварианта обработки. Обычно им является смысл сообщения (смысл информации, заключенной в сообщении). При автоматизированной обработке информации объектом обработки служит сообщение, и здесь важно провести обработку таким образом, чтобы инварианты преобразований сообщения соответствовали инвариантам преобразования информации.
Цель обработки информации в целом определяется целью функционирования некоторой системы, с которой связан рассматриваемый информационный процесс. Однако для достижения цели всегда приходится решать ряд взаимосвязанных задач.
К примеру, начальная стадия информационного процесса – рецепция. В различных информационных системах рецепция выражается в таких конкретных процессах, как сбор и/или отбор информации (в системах научно–технической информации), преобразование физических величин в измерительный сигнал (в информационно–измерительных системах), раздражимость и ощущения (в биологических системах) и т. п.
Процесс рецепции начинается на границе, отделяющей информационную систему от внешнего мира. Здесь, на границе, сигнал внешнего мира преобразуется в форму, удобную для дальнейшей обработки. Для биологических систем и многих технических систем, например читающих автоматов, эта граница более или менее четко выражена. В остальных случаях она в значительной степени условна и даже расплывчата. Что касается внутренней границы процесса рецепции, то она практически всегда условна и выбирается в каждом конкретном случае исходя из удобства исследования информационного процесса.
Следует отметить, что, независимо от того, как «глубоко» будет отодвинута внутренняя граница, рецепцию всегда можно рассматривать как процесс классификации.
Формализованная модель обработки информации.Обратимся теперь к вопросу о том, в чем сходство и различие процессов обработки информации, связанных с различными составляющими информационного процесса, используя при этом формализованную модель обработки. Прежде всего, нельзя отрывать этот вопрос от потребителя информации (адресата), а также от семантического и прагматического аспектов информации. Наличие адресата, для которого предназначено сообщение (сигнал), определяет невозможность установления однозначного соответствия между сообщением и содержащейся в нем информацией. Совершенно очевидно, что одно и то же сообщение может иметь различный смысл для разных адресатов и различное прагматическое значение.
Используемые в производственной сфере такие технологические понятия, как "технологический процесс", "технологическая операция", "метрика", "норматив" и т. п. могут применяться и в ИТ. Для этого нужно начинать с определения цели. Затем следует попытаться провести структурирование всех предполагаемых действий, приводящих к намеченной цели, и выбрать необходимый программный инструментарий.
1–й уровень – этапы, где реализуются базовые технологические процессы, состоящие из операций и действий последующих уровней.
2–й уровень – операции, в результате выполнения которых будет создан конкретный объект в выбранной на 1–м уровне программной среде.
3–й уровень – действия, совокупность стандартных для каждой программной среды приемов работы, приводящих к выполнению поставленной в соответствующей операции цели.
4–й уровень – элементарные операции по управлению элементарными действиями объектов.
ИТ, как и другие технологии, должны отвечать следующим требованиям:
· обеспечивать высокую степень расчленения всего процесса обработки информации на этапы, операции, действия;
· включать весь набор элементов, необходимых для достижения поставленной цели;
· иметь регулярный и масштабируемый характер;
· этапы, действия, операции технологического процесса должны быть стандартизированы и унифицированы, что позволит более эффективно осуществлять целенаправленное управление информационными процессами.
Традиционно в процессе обработки информации используются как измерительная аппаратура, обеспечивающая входные данные, так и собственно обрабатывающие (вычислительные) системы. И те и другие прошли длинную дорогу развития вместе с человеческой цивилизацией. В следующем пункте будут перечислены основные вехи их истории.
Если раньше обрабатывающей системой был человек или какие–то механические приспособления, то для проведения процесса обработки было достаточно сформулировать набор правил (инструкций). Давно подметили, что повторяющиеся операции целесообразно автоматизировать в первую очередь и желательно перепоручить машинам. При этом человек, задавая циклическое правило работы машине, колоссально выигрывает в трудозатратах.
Предположим, вам надо сложить 1000 последовательных данных измерений. Заводим специальный счетчик–сумматор и присваиваем ему значение 0. Для каждого из данных надо получить результат измерений и добавить его к счетчику, то есть вам надо сделать 2001 операцию при "ручном" счете. Другой вариант – написать шесть инструкций для машины:
1. завести счетчик–сумматор и присвоить ему значение 0;
2. завести индекс (номер) текущей операции и присвоить ему значение 0;
3. получить новый результат измерений;
4. добавить его к счетчику–сумматору;
5. увеличить на 1 индекс текущей операции;
6. если он меньше 1000, то перейти к шагу 3.
За прошедшее время существенно усложнились задачи обработки информации, развились способы формулировки и записи правил работы машин (программ работы). Вычислительные устройства превратились в компьютеры, а правила работы – в компьютерные программы.
Программирование – процесс создания компьютерных программ с помощью языков программирования. Программирование сочетает в себе элементы искусства, науки, математики и инженерии.
В узком смысле слова программирование рассматривается как кодирование – реализация одного или нескольких взаимосвязанных алгоритмов на некотором языке программирования. Под программированием также может пониматься разработка логической схемы для интегральной микросхемы, а также процесс записи информации в микросхему ПЗУ (Постоянного Запоминающего Устройства) некоторой электронной системы. В более широком смысле программирование – процесс создания программ, то есть разработка программного обеспечения.
Составителями программ являются программисты. Большая часть работы программиста связана с написанием и отладкой исходного кода на одном из языков программирования.
Различные языки программирования поддерживают различные стили программирования (или парадигмы программирования). Отчасти искусство программирования состоит в том, чтобы на одном из языков эффективно реализовать алгоритм, наиболее полно подходящий для решения имеющейся задачи. Разные языки требуют от программиста различного уровня внимания к деталям при реализации алгоритма, результатом чего часто бывает компромисс между простотой и производительностью (или между временем программиста и временем пользователя).
Единственный язык, напрямую выполняемый процессором, – это машинный язык (также называемый машинным кодом). Изначально все программисты прорабатывали весь алгоритм в машинном коде, но сейчас эта трудная работа уже не делается. Вместо этого программисты пишут исходный код на языке высокого уровня (например, С, С++, С#, Java), а компьютер, используя компилятор или интерпретатор и уточняя все детали, транслирует его за один или несколько этапов в машинный код, готовый к исполнению на целевом процессоре. Если требуется полный низкоуровневый контроль над системой, программисты пишут программу на языке ассемблера, мнемонические инструкции которого преобразуются один к одному в соответствующие инструкции машинного языка целевого процессора.
В некоторых языках вместо машинного кода генерируется интерпретируемый двоичный код "виртуальной машины", также называемый байт–кодом (byte–code). Такой подход применяется в языке Forth, некоторых реализациях языков Lisp, Java, Perl, Python, а также в языках платформы Microsoft .NET.
Типичный процесс разработки программ состоит, в общем, из семи этапов:
· постановка задачи;
· формализация и специфицирование;
· выбор или составление алгоритма;
· программирование;
· компиляция (трансляция);
· отладка и тестирование;
· запуск в эксплуатацию.
Эксплуатируемая программа имеет дело с данными различных типов, предназначенных для решения конкретных задач.
1.9. Хранение информации. Базы и хранилища данных.
Предметная область какой–либо деятельности – часть реального мира, подлежащая изучению с целью организации управления процессами и объектами для получения бизнес–результата. Предметная область может быть разделена (декомпозирована) на фрагменты: например, предприятие – это дирекция, плановые отделы, бухгалтерия, цеха, отделы маркетинга, логистики и продаж, клиенты, поставщики и т. д. Каждый фрагмент предметной области характеризуется множеством объектов и процессов, использующих объекты, а также множеством пользователей, характеризуемых различными взглядами на предметную область и данными, которые описывают указанные составляющие предметной области. Эти данные отражают динамичную внешнюю и внутреннюю среды предприятия, поэтому в специальных разделах информационной системы необходимо создавать динамически обновляемые модели отражения внешнего мира с использованием единого хранилища – базы данных.
База данных, БД (Data Base) – структурированный организованный набор данных, объединенных в соответствии с некоторой выбранной моделью и описывающих характеристики какой–либо физической или виртуальной системы
Понятие «динамически обновляемая БД» означает, что соответствие базы данных текущему состоянию предметной области обеспечивается не периодически, а в режиме реального времени. При этом одни и те же данные могут быть по–разному представлены в соответствии с потребностями различных групп пользователей.
Система управления базами данных, СУБД (Data Base Management System) – специализированная программа или комплекс программ, предназначенные для манипулирования базой данных. Для создания информационной системы и управления ею СУБД необходима в той же степени, как для разработки программы на алгоритмическом языке необходим транслятор.
СУБД часто упрощенно или ошибочно называют «базой данных». Нужно различать набор данных (собственно БД) и программное обеспечение, предназначенное для организации и ведения баз данных (СУБД).
Отличительной чертой баз данных следует считать то, что данные хранятся совместно с их описанием, а в прикладных программах описание данных не содержится. Независимые от программ пользователя данные обычно называются метаданными или данными о данных. В ряде современных систем метаданные, содержащие также информацию о пользователях, форматы отображения, статистику обращения к данным и др. сведения, хранятся в специальном словаре базы данных.
Организация структуры БД формируется исходя из следующих соображений:
· адекватность описываемому объекту/системе – на уровне концептуальной и логической моделей;
· удобство использования для ведения учета и анализа данных – на уровне так называемой физической модели.
Виды концептуальных и логических моделей БД:
· картотеки;
· сетевые;
· иерархические;
· реляционные;
· дедуктивные;
· объектно–ориентированные;
· многомерные.
На уровне физической модели электронная БД представляет собой файл или набор данных в dbf–форматах приложений Excel, Access либо в специализированном формате конкретной СУБД. Также в СУБД в понятие физической модели включают специализированные виртуальные понятия, существующие в ее рамках, – «таблица», «табличное пространство», «сегмент», «куб», «кластер» и т. д.
В настоящее время наибольшее распространение получили реляционные базы данных. Картотеками пользовались до появления электронных баз данных. Сетевые и иерархические базы данных считаются устаревшими, объектно–ориентированные пока никак не стандартизированы и не получили широкого распространения.
Реляционная база данных – база данных, основанная на реляционной модели. Слово «реляционный» происходит от английского «relation» (отношение).
Теория реляционных баз данных была разработана доктором Эдгаром Коддом из компании IBM в 1970 году. В реляционных базах данных все данные представлены в виде простых таблиц, разбитых на строки и столбцы, на пересечении которых расположены данные. Запросы к таким таблицам возвращают таблицы, которые сами могут становиться предметом дальнейших запросов. Каждая база данных может включать несколько таблиц. Кратко особенности реляционной базы данных можно сформулировать следующим образом:
· данные хранятся в таблицах, состоящих из столбцов («атрибутов») и строк («записей»);
· на пересечении каждого столбца и строчки стоит в точности одно значение;
· у каждого столбца есть свое имя, которое служит его названием, и все значения в одном столбце имеют один тип;
· запросы к базе данных возвращают результат в виде таблиц, которые тоже могут выступать как объект запросов;
· строки в реляционной базе данных неупорядочены, упорядочивание производится в момент формирования ответа на запрос.
Общепринятым стандартом языка работы с реляционными базами данных в настоящее время является язык структурированных запросов (Structured Query Language – SQL). Это универсальный компьютерный язык, применяемый для создания, модификации и управления данными в реляционных базах данных. Вопреки существующим заблуждениям, SQL является информационно–логическим языком, а не языком программирования.
SQL основывается на реляционной алгебре. Язык SQL делится на три части:
· операторы определения данных;
· операторы манипуляции данными (Insert, Select, Update, Delete);
· операторы определения доступа к данным.
Основные функции системы управления базами данных:
· управление данными во внешней памяти (на различных носителях);
· управление данными в оперативной памяти;
· журналирование изменений и восстановление базы данных после сбоев;
· поддержка языков БД (язык определения данных, язык манипулирования данными, язык определения доступа к данным).
Обычно современная СУБД содержит следующие компоненты:
· ядро, которое отвечает за управление данными во внешней и оперативной памяти и журналирование;
· процессор языка базы данных, обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание, как правило, машинно–независимого исполняемого внутреннего кода;
· подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД;
· сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы.
По типу управляемой базы данных СУБД разделяются на иерархические, реляционные, объектно–реляционные, объектно–ориентированные, сетевые.
По архитектуре организации хранения данных:
· локальные СУБД (все части локальной СУБД размещаются на одном компьютере);
· распределенные СУБД (части СУБД могут размещаться на двух и более компьютерах).
Классификация СУБД по способу доступа к БД:
· файл–серверные;
· клиент–серверные;
· трехзвенные;
· встраиваемые.
Файл–серверные СУБД. Архитектура «файл–сервер» не имеет сетевого разделения компонентов диалога и использует компьютер для функции отображения, что облегчает построение графического интерфейса. «Файл–сервер» только извлекает данные из файлов, так что дополнительные пользователи добавляют лишь незначительную нагрузку на центральный процессор, и каждый новый клиент добавляет вычислительную мощность сети. Минус – высокая загрузка сети. На данный момент файл–серверные СУБД считаются устаревшими. Примеры: Microsoft Access, MySQL (до версии 5.0).
Клиент–серверные СУБД. Такие СУБД состоят из клиентской части (которая входит в состав прикладной программы) и сервера. Клиент–серверные СУБД, в отличие от файл–серверных, обеспечивают разграничение доступа между пользователями и меньше загружают сеть и клиентские машины. Сервер является внешней по отношению к клиенту программой, и по мере надобности его можно заменить другим. Недостаток клиент–серверных СУБД – в самом факте существования сервера (что плохо для локальных программ – в них удобнее встраиваемые СУБД) и больших вычислительных ресурсах, потребляемых сервером. Примеры: Firebird, Interbase, MS SQL Server, Oracle, DB2, PostgreSQL, MySQL (старше версии 5.0).
Существенным недостатком клиент–серверной архитектуры является необходимость установления прямого соединения между клиентским компьютером и базой данных. При трехзвенной архитектуре пользовательское приложение (клиент) соединяется со специально выделенным сервером приложений, и только он уже соединяется с базой данных. Кроме повышения уровня безопасности трехзвенная архитектура позволяет более гибко модернизировать приложения. Как правило, в массовой клиентской части оставляют только минимальный набор функций по доступу и отображению информации, а основную бизнес–логику реализуют в программах, запускаемых на серверах приложений. При этом модернизация обычно затрагивает только сервер приложений, а на массовых клиентских местах переустанавливать ПО не приходится.
Встраиваемая СУБД – это, как правило, «библиотека», которая позволяет унифицированным образом хранить большие объемы данных на локальной машине. Доступ к данным может происходить через SQL либо через особые функции СУБД. Встраиваемые СУБД быстрее обычных клиент–серверных и не требуют установки сервера, поэтому востребованы в локальном ПО, которое имеет дело с большими объемами данных – например, геоинформационные системы (Geographic Informational System – GIS). Примеры: SQLite, BerkeleyDB, один из вариантов Firebird, один из вариантов MySQL.
В общем случае СУБД могут быть классифицированы в системе координат «Неоднородность – Автономность –Распределенность».
Таким образом, распределенная обработка данных в обязательном порядке предполагает наличие банков и баз данных. Но база данных – это не просто место, куда складывают данные, ими нужно пользоваться, актуализировать, изменять форматы и связи, совершать множество других действий. Если бессистемно наполнять базу данных информацией, то через некоторое время ее невозможно будет использовать – времени на поиск нужных данных будет уходить все больше и больше, физическое пространство базы переполнится. Чтобы этого избежать, данные необходимо "очищать" и структурировать, а для эффективной работы с ними необходимы системы управления работой баз данных.
Индустрия создания баз данных и СУБД берет свое начало в 60–х годах прошлого века и к настоящему времени достаточно развита, однако понятие «хранилище данных» в современном понимании его появилось относительно недавно.
Идея хранилищ данных оказалась востребованной, так как во многих видах государственной, деловой, научной, социальной деятельности необходимы тематически объединенные и исторически очищенные совокупности данных, при этом постоянно возрастала потребность:
· в более дешевых данных;
· в точных и структурированных данных;
· в большей оперативности получения и обработки данных;
· в интегрированных данных.
К концу 1980–х годов, когда была в полной мере осознана необходимость интеграции корпоративной информации и надлежащего управления этой информацией, появились технические возможности для создания соответствующих систем, которые первоначально были названы "хранилищами информации" (Information Warehouse – IW). И лишь в 1990–е годы, с выходом книги Уильяма (Билла) Инмона, хранилища получили свое нынешнее наименование «хранилища данных» (Data Warehouse – DW) [25].
Билл Инмон определил хранилища данных как «предметно–ориентированные, интегрированные, неизменные, поддерживающие хронологию наборы данных, организованные для целей поддержки управления, призванные выступать в роли единого и единственного источника истины, обеспечивающего менеджеров и аналитиков достоверной информацией, необходимой для оперативного анализа и принятия решений».
В основе концепции хранилищ данных лежат следующие основополагающие идеи:
· интеграция ранее разъединенных детализированных данных (исторические архивы, данные из традиционных систем обработки документов, разрозненных баз данных, данные из внешних источников) в едином хранилище данных;
· тематическое и временное структурирование, согласование и агрегирование;
· разделение наборов данных, используемых для операционной (производственной) обработки, и наборов данных, используемых для решения задач анализа.
Данные, помещаемые в хранилище, должны отвечать определенным требованиям – предметной ориентированности, интегрированности, поддержки хронологии и неизменяемости (таблица 2.3).
Таблица 1.3.
Требования к данным
| Предметная ориентированность | Все данные о некоторой сущности (бизнес–объекте, бизнес–процессе и т. д.) из некоторой предметной области собираются из множества различных источников, очищаются, согласовываются, дополняются, агрегируются и представляются в единой, удобной для их использования в бизнес–анализе форме |
| Интегрированность | Все данные о различных бизнес–объектах взаимно согласованы и хранятся в едином общекорпоративном хранилище |
| Поддержка хронологии | Данные хронологически структурированы и отражают историю за период времени, достаточный для выполнения задач бизнес–анализа, прогнозирования и подготовки принятия решения |
| Неизменяемость | Исходные (исторические) данные, после того как они были согласованы, верифицированы и внесены в общекорпоративное хранилище, остаются неизменными и используются исключительно в режиме чтения |
Хранилище данных выполняет множество функций, но его основное предназначение – предоставление точных данных и информации в кратчайшие сроки и с минимумом затрат.
Понятие хранилище данных в первоначальном понимании было основано на понятии распределенной витрины данных (Distributed Data Mart – DDM). Поэтому в классическом исполнении хранилище данных было прежде всего репозиторием (сквозной базой данных) данных и информации предприятия.
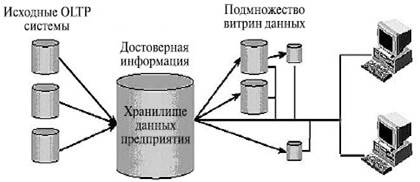
Рис. 1.2. Схема организации данных в хранилище
Среда хранилища была предназначена только для чтения и состояла из детальных и агрегированных данных, которые полностью очищены и интегрированы; кроме того, в репозитории хранилась обширная и детальная история данных на уровне транзакций. С точки зрения архитектурного решения такое хранилище данных реализует свои функции через подмножество зависимых витрин данных (рис. 1.2).
Достоинствами архитектуры классического хранилища данных являются:
· общая семантика;
· централизованная, управляемая среда;
· согласованный набор процессов извлечения и бизнес–логики использования;
· непротиворечивость содержащейся информации;
· легко создаваемые по шаблонам и наполняемые витрины данных;
· единый репозиторий метаданных;
· многообразие механизмов обработки и представления данных.
К недостаткам можно отнести большие затраты по реализации, высокую ресурсоемкость в масштабе всего предприятия, потребность в сложных сервисных системах, рискованный сценарий развития, когда все данные и метаданные находятся в одном репозитории и в неблагоприятном случае могут быть потеряны. Кроме того, при фильтрации, агрегировании и рафинировании «сырых» данных для такого хранилища обычно теряется очень много информации, которая может быть чрезвычайно полезной при бизнес–анализе. В связи с этим возникло понимание того, что хранилище, помимо механизмов размещения и извлечения данных (On Line Transactional Processing – OLTP), репозитория и витрин, должно иметь соответствующее пространство для организации «сырых» данных и их многомерного анализа в режиме реального времени (On Line Analytical Processing – OLAP).
Современный компьютер принято разделять на аппаратную часть («железо» – Hardware) и программное обеспечение (ПО – Software). В физическом исполнении на системной («материнской») плате имеются соответствующие разъемы (слоты) для размещения процессора, модулей оперативной памяти, подключения устройств ввода/вывода.
Интерфейс между процессором, внутренними и внешними устройствами осуществляется с помощью шин и совокупности устанавливаемых на плате специальных микросхем (Chipset). На плате размещается также специализированный блок (Basic Input/Output System –– BIOS), который предназначен для хранения параметров конфигурации персонального компьютера, аппаратных драйверов и программы POST, проверяющей при включении компьютера работоспособность его различных устройств.
Научно–технический прогресс в первую очередь влияет на развитие аппаратной части: уменьшаются геометрические размеры транзисторов, увеличивается быстродействие, растет скорость передачи данных и т. п.; но новые аппаратные возможности дают импульс созданию новых программ. Покупатель компьютера в основном платит за стоимость аппаратуры, которую, один раз купив, нельзя бесплатно много раз обновлять. "Мягкость" составной части программного обеспечения, разработанного на базе принципа "открытых систем", обеспечивается возможностью "загрузки" разных программ на одну и ту же аппаратную платформу. Это позволяет многократно увеличить скорость обновления
функциональных возможностей компьютеров (скорость предоставления новых сервисов для пользователей).
Программное обеспечение обычно разделяют на системное и прикладное.
Операционная система (ОС) – базовый комплекс компьютерных пр
Дата добавления: 2017-01-08; просмотров: 12769;
Поиск по сайту
Узнать еще
- D-технология построения чертежа. Типовые объемные тела: призма, цилиндр, конус, сфера, тор, клин. Построение тел выдавливанием и вращением. Разрезы, сечения.
- IDEA NXT - новый подход в технологиях блочного симметричного шифрования
- II. Технология производства ДСП. Шлифованное ДСП.
- III Раздел: ЭЛЕКТРОТЕХНОЛОГИЯ НА СТРОИТЕЛЬНОЙ ПЛОЩАДКЕ.
- WORLD-WIDE-WEB (Всемирная информационная сеть)
- А и Б – базы механической обработки
- Автоматизация и механизация токарной обработки
- Автоматизация обработки снимков на фотограмметрическом оборудовании

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
