Лекция 23. Классификация систем параллельной обработки данных.
На протяжении всей истории развития вычислительной техники делались попытки найти какую-то общую классификацию, под которую подпадали бы все возможные направления развития компьютерных архитектур. Ни одна из таких классификаций не могла охватить все разнообразие разрабатываемых архитектурных решений и не выдерживала испытания временем. Тем не менее в научный оборот попали и широко используются ряд терминов, которые полезно знать не только разработчикам, но и пользователям компьютеров.
Любая вычислительная система (будь то супер-ЭВМ или персональный компьютер) достигает своей наивысшей производительности благодаря использованию высокоскоростных элементов и параллельному выполнению большого числа операций. Именно возможность параллельной работы различных устройств системы (работы с перекрытием) является основой ускорения основных операций.
Параллельные ЭВМ часто подразделяются по классификации Флинна на машины типа SIMD (Single Instruction Multiple Data - с одним потоком команд при множественном потоке данных) и MIMD (Multiple Instruction Multiple Data - с множественным потоком команд при множественном потоке данных). Как и любая другая, приведенная выше классификация несовершенна: существуют машины прямо в нее не попадающие, имеются также важные признаки, которые в этой классификации не учтены. В частности, к машинам типа SIMD часто относят векторные процессоры, хотя их высокая производительность зависит от другой формы параллелизма - конвейерной организации машины. Многопроцессорные векторные системы, типа Cray Y-MP, состоят из нескольких векторных процессоров и поэтому могут быть названы MSIMD (Multiple SIMD).
Классификация Флинна не делает различия по другим важным для вычислительных моделей характеристикам, например, по уровню "зернистости" параллельных вычислений и методам синхронизации.
Можно выделить четыре основных типа архитектуры систем параллельной обработки:
1) Конвейерная и векторная обработка.
Основу конвейерной обработки составляет раздельное выполнение некоторой операции в несколько этапов (за несколько ступеней) с передачей данных одного этапа следующему. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняются несколько операций. Конвейеризация эффективна только тогда, когда загрузка конвейера близка к полной, а скорость подачи новых операндов соответствует максимальной производительности конвейера. Если происходит задержка, то параллельно будет выполняться меньше операций и суммарная производительность снизится. Векторные операции обеспечивают идеальную возможность полной загрузки вычислительного конвейера.
При выполнении векторной команды одна и та же операция применяется ко всем элементам вектора (или чаще всего к соответствующим элементам пары векторов). Для настройки конвейера на выполнение конкретной операции может потребоваться некоторое установочное время, однако затем операнды могут поступать в конвейер с максимальной скоростью, допускаемой возможностями памяти. При этом не возникает пауз ни в связи с выборкой новой команды, ни в связи с определением ветви вычислений при условном переходе. Таким образом, главный принцип вычислений на векторной машине состоит в выполнении некоторой элементарной операции или комбинации из нескольких элементарных операций, которые должны повторно применяться к некоторому блоку данных. Таким операциям в исходной программе соответствуют небольшие компактные циклы.
2) Машины типа SIMD.
SIMD компьютер имеет N идентичных процессоров, N потоков данных и один поток команд. Каждый процессор обладает собственной локальной памятью. Процессоры интерпретируют адреса данных либо как локальные адреса собственной памяти, либо как глобальные адреса, возможно, модифицированные добавлением локального базового адреса. Процессоры получают команды от одного центрального контроллера команд и работают синхронно, то есть на каждом шаге все процессоры выполняют одну и ту же команду над данными из собственной локальной памяти.
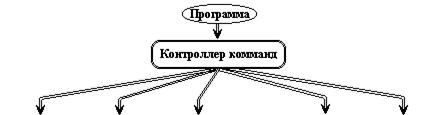
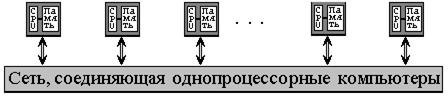
Машины типа SIMD состоят из большого числа идентичных процессорных элементов, имеющих собственную память. Все процессорные элементы в такой машине выполняют одну и ту же программу. Очевидно, что такая машина, составленная из большого числа процессоров, может обеспечить очень высокую производительность только на тех задачах, при решении которых все процессоры могут делать одну и ту же работу. Модель вычислений для машины SIMD очень похожа на модель вычислений для векторного процессора: одиночная операция выполняется над большим блоком данных.
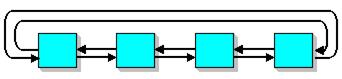
Такая архитектура с распределенной памятью часто упоминается как архитектура с параллелизмом данных(data-parallel), так как параллельность достигается при наличии одиночного потока команд, действующего одновременно на несколько частей данных. Сеть, соединяющая процессоры, обычно имеет регулярную топологию такую как кольцо SLAP:
Дата добавления: 2016-11-26; просмотров: 1928;
Поиск по сайту
Узнать еще
- Arthropoda. Клещи. Систематика. Морфология. Медицинское значение.
- Arthropoda. Паукообразные. Систематика. Географическое распространение. Морфология. Скорпионы. Пауки. Медицинское значение.
- Arthropoda..Систематика.Насекомые.Морфология.Классификация.Медицинское значение.
- Arthropoda.Систематика.Блохи.Виды блох.Географическое распространение.Морфология,развитие,патогенное действие.Медицинское и эпидемиологическое значение.Меры борьбы.
- Arthropoda.Систематика.Мошки,мокрецы,слепни,оводы.Географическое распространение.Морфология,развитие,патогенное действие.Медицинское значение,меры борьбы.
- Arthropoda.Систематика.Тараканы и мухи.Географическое распространение.Основные представители.Морфология,развитие,патогенное действие.Медицинское знаение.Меры борьбы.
- Cимпатическая нервная система. Центральный и периферический отдел симпатической нервной системы.
- Cистеми числення і способи переведення чисел із однієї системи числення в іншу

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
