База данных как основа информационного обеспечения
В состав информационного, программного и математического обеспечения принято включать следующие элементы:
*методы и модели решения задач анализа и управления;
*методы вычисления показателей, используемых для количественной характеристики отображаемых объектов;
*языки информационной системы, ее подсистем и тех систем во внешней среде, с которыми она общается;
*инструкции и программы сбора, подготовки, контроля, обработки, хранения, поиска, выпуска и передачи данных — для человека или компьютера.
Последовательность записей, размещаемых на внешних запоминающих устройствах и рассматриваемых в процессе обработки как единое целое, именуется файлом.
База данных — совокупность взаимосвязанных данных, которую можно использовать оптимальным образом для одного или нескольких приложений в определенной предметной области человеческой деятельности.
В современных системах управления БД пользователь имеет дело с содержательной стороной своих данных, а не с деталями их представления в ЭВМ. Сами системы управления базами данных выполняют следующие две основные функции:
*хранение и ведение представления структурной информации
(данных);
*преобразование по некоторому запросу хранимого представления в структурную информацию.
Каждая из систем управления базами данных (СУБД) основывается на определенной модели, отражающей взаимосвязи между объектами. Существуют иерархические, сетевые и реляционные модели данных. Большинство современных СУБД используют реляционную модель. С помощью такой модели могут быть представлены объекты предметной области и взаимосвязи между ними.
Использование БД обеспечивает независимость данных и программ, реализацию отношений между данными, совместимость компонентов БД, простоту изменения логической и физической структур БД, целостность, восстановление и защиту БД и др. К другим целям использования БД относятся: сокращение избыточности в хранимых данных, устранение несовместимости в хранимых данных с помощью автоматической корректировки и поддержки всех дублирующих записей, уменьшение стоимости разработки программ, а также программирование запросов к БД.
Любая СУБД не может одинаково успешно применяться при работе с БД разных классов. Такие системы, как СLIPPER, FOXPRO, ориентированы на первый класс БД (А), а такие СУБД, как Informix, Ingres, SyBase, создавались для второго класса (Б).
Напрашивается задача: найти «золотую середину», которая удовлетворяла бы требованиям обоих классов — А и Б. Решением является использование распределенной базы данных (РБД). Прикладные программы управления данными представляют собой необходимый инструмент для распределенной обработки. Архитектура клиент-сервера сети позволяет различным прикладным программам одновременно использовать общую базу данных.
Очевидно, что перенос программ управления данными с рабочих станций на сервер способствует высвобождению ресурсов рабочих станций, предоставляет возможность увеличить число частных, локально решаемых задач. Это позволяет также централизовать ряд самых важных функций управления данными, таких, как зашита информации баз данных, обеспечение целостности данных, управление совместным использованием ресурсов.
Одним из важных преимуществ архитектуры клиент-сервера в распределенной обработке данных является возможность сокращения времени реализации запроса. В подтверждение этому рассмотрим две базовые технологии обработки информации в архитектуре клиент-сервера сети и технологии использования традиционного файлового сервера.
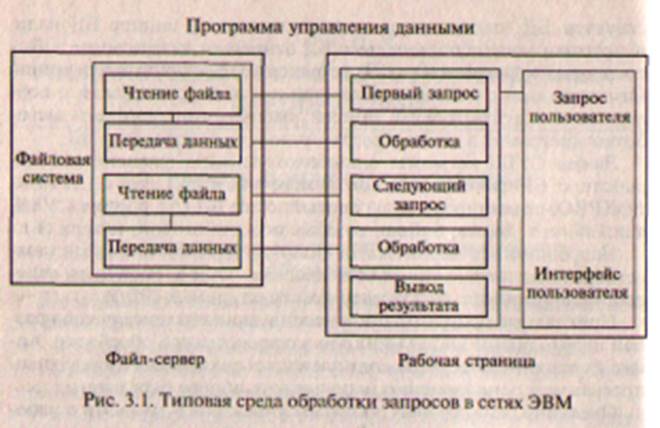
Допустим, что прикладная программа БД загружена на рабочую станцию и пользователю необходимо получить все записи, удовлетворяющие некоторым поисковым условиям. В среде традиционного файлового сервера программа управления данными, которая выполняется на рабочей станции, должна осуществить запрос к серверу каждой записи БД (рис. 3.1). Программа управления данными на рабочей станции может определить, удовлетворяет ли запись поисковым условиям, лишь после того, как она будет передана на рабочую станцию. Очевидно, что данный технологический вариант обработки информации имеет наибольшее суммарное время передачи данных по каналам сети.
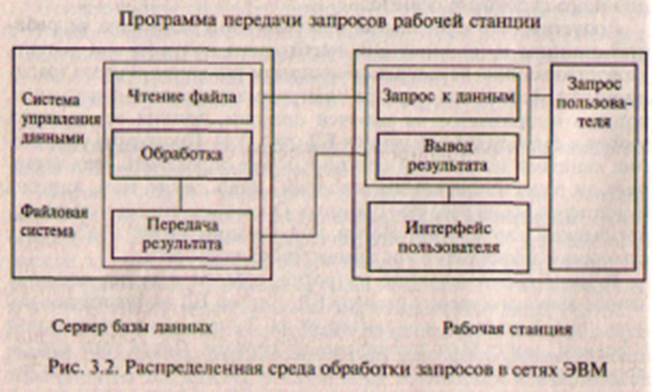
В среде клиент-сервера, напротив, рабочая станция посылает запрос высокого уровня серверу БД. Сервер БД осуществляет поиск записей на диске и анализирует их. Записи, удовлетворяющие условиям, могут быть накоплены на сервере. После того как запрос целиком обработан, пользователю на рабочую станцию передаются все записи, которые удовлетворяют поисковым условиям (рис. 3.2).
Данная технология позволяет снизить сетевой трафик и повысить пропускную способность сети. Более того, за счет выполнения операции доступа к диску и обработки данных в одной системе сервер может осуществить поиск и обрабатывать запросы быстрее, чем, если бы эти запросы обрабатывались на рабочей станции.
Работа пользователей с распределенными базами данных имеет ряд особенностей, тем более, что некоторые данные могут дублироваться. Выгоды, получаемые от дублирования, пропорциональны соотношению объемов выборки данных и их обновления. Для поддержания целостности БД требуется корректировка всех копий. Наличие копий приводит к увеличению стоимости хранения и обновления информации, но так повышается устойчивость системы
при отказах.
Эффективность работы пользователей с РБД зависит от обеспеченности информацией о содержащихся в РБД данных, их структуре и размещении. Эту задачу решает сетевой словарь-справочник данных, находящийся в одной ЭВМ сети или дублирующийся на нескольких ЭВМ. Создание РБД было вызвано двумя тенденциями обработки данных: с одной стороны — интеграцией, а с другой —
децентрализацией. Распределенная структура БД предполагает независимость конечных пользователей и программ от способа размещения информации на рабочих станциях сети, а формулирование запросов к РБД производится аналогично запросам к централизованной БД. Совместный доступ к данным подразумевает модификацию одних и тех же данных несколькими пользователями без нарушения целостности РБД.
Доступ пользователей к РБД и администрирование осуществляются с помощью системы управления распределенной базой данных (СУРБД), которая обеспечивает выполнение следующих функций:
· автоматическое определение ЭВМ, хранящей требуемые в запросе данные;
· декомпозиция распределенных запросов на частные подзапросы к БД отдельных ЭВМ;
· планирование обработки запросов;
· передача частных подзапросов и их исполнение на удаленных 1ЭВМ;
· прием результатов выполнения частных подзапросов;
· поддержание в согласованном состоянии копий дублированных данных на различных ЭВМ сети;
• управление параллельным доступом пользователей к РБД;
• обеспечение целостности РБД.
Дата добавления: 2021-01-26; просмотров: 1094;
Поиск по сайту
Узнать еще
- API как средство интеграции приложений.
- CONV(N, основание_начальное, основание_конечное)
- I. Общая характеристика категории состояния как часть речи
- II. ПОДСЛИЗИСТАЯ ОСНОВА
- IP как протокол без установления соединения
- IV. Критерии и принципы обеспечения безопасности
- MatLab как научный калькулятор
- STEP – стандарт для описания данных об изделии

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
