Основные функции MPI
Наиболее распространенной технологией программирования для параллельных систем с распределенной памятью в настоящее время является MPI (Message Passing Interface). Основным способом взаимодействия параллельных процессов друг с другом в таких системах является передача сообщений (Message Passing). По сути MPI – это библиотека и среда исполнения для параллельных программ на языках C или Fortran. В данном пособии будут описаны примеры программ на языке С.
Изначально MPI позволяет использовать модель программирования MIMD (Multiple Instruction Multiple Data) – много потоков инструкций и данных, т.е. объединение различных программ с различными данными. Но программирование для такой модели на практике оказывается слишком сложным, поэтому обычно используется модель SIMD (Single Program Multiple Data) –одна программа и много потоков данных. Здесь параллельная программа пишется так, чтобы разные ее части могли одновременно выполнять свою часть задачи, таким образом, достигается параллелизм. Поскольку все функции MPI содержаться в библиотеке, то при компиляции параллельной программы необходимо будет прилинковать соответствующие модули.
Под параллельной программой в рамках MPI понимается множество одновременно выполняемых процессов. Процессы могут выполняться на разных процессорах, но на одном процессоре могут располагаться и несколько процессов (в этом случае их исполнение осуществляется в режиме разделения времени). При запуске MPI – программы на кластере на каждом из его узлов будет выполняться своя копия программы, выполняющая свою часть задачи, из этого следует, что параллельная программа – это множество взаимодействующих процессов, каждый из которых работает в своем адресном пространстве. В предельном случае для выполнения параллельной программы может использоваться один процессор - как правило, такой способ применяется для начальной проверки правильности параллельной программы.
Количество процессов и число используемых процессоров определяется в момент запуска параллельной программы средствами среды исполнения MPI - программ и в ходе вычислений меняться не может. Все процессы программы последовательно перенумерованы от 0 до np-1, где np есть общее количество процессов. Номер процесса называется рангом процесса.
Взаимодействуют параллельные процессы между собой при помощи посылки сообщений. Методы посылки (их называют коммуникации) бывают двух видов – коллективные(collective) и “точка-точка” (point-to-point). При коллективных коммуникациях процесс посылает нужную информацию одновременно целой группе процессов, еще есть более общий случай, когда внутри группы процессов передача информации идет от каждого процесса к каждому. Более простыми коммуникациями являются коммуникации типа ”точка-точка”, когда один процесс посылает информацию второму или они оба обмениваются информацией. Функции коммуникаций – основные функции библиотеки MPI. Кроме этого, обязательными функциями являются функции инициализации и завершения MPI – MPI_Init и MPI_Finalize. MPI_Init должна вызываться в самом начале программ, а MPI_Finalize – в самом конце. Все остальные функции MPI должны вызываться между этими двумя функциями.
Как процесс узнает о том, какую часть вычислений он должен выполнять? Каждый процесс, исполняющийся на кластере, имеет свой уникальный номер – ранг. Когда процесс узнает свой ранг и общее количество процессов, он может определить свою часть работы. Для этого в MPI существуют специальные функции – MPI_Comm_rank и MPI_Comm_size. MPI_Comm_rank возвращает целое число - ранг процесса, вызвавшего ее, а MPI_Comm_size возвращает общее число работающих процессов.
Процессы отлаживаемой параллельной программы пользователя объединяются в группы. Под коммуникатором в MPI понимается специально создаваемый служебный объект, объединяющий в своем составе группу процессов и ряд дополнительных параметров (контекст), используемых при выполнении операций передачи данных. Коммуникатор, автоматически создаваемый при запуске программы и включающий в себя все процессы на кластере, называется MPI_COMM_WORLD. В ходе вычислений могут создаваться новые и удаляться существующие группы процессов и коммуникаторы. Один и тот же процесс может принадлежать разным группам и коммуникаторам. Коллективные операции применяются одновременно для всех процессов коммуникатора, поэтому для них одним из параметров всегда будет выступать коммуникатор.
При выполнении операций передачи сообщений в функциях MPI необходимо указывать тип пересылаемых данных. MPI содержит большой набор базовых типов данных, основанных на стандартных типах данных языка С. Кроме того, программист может конструировать свои типы данных при помощи специальных функций MPI. Ниже приведена таблица соответствия для базовых типов данных.
| Константы MPI | ТИП данных языка С |
| MPI_INT | signed int |
| MPI_UNSIGNED | unsigned int |
| MPI_SHORT | signed int |
| MPI_LONG | signed long int |
| MPI_UNSIGNED_SHORT | unsigned int |
| MPI_UNSIGNED_LONG | unsigned long int |
| MPI_FLOAT | float |
| MPI_DOUBLE | double |
| MPI_LONG_DOUBLE | long double |
| MPI_UNSIGNED_CHAR | unsigned char |
| MPI_CHAR | signed char |
Пример запуска библиотеки MPI: логин student, пароль s304.
#include <stdio.h>
#include <mpi.h>
int main (int argc, char *argv[])
{
int rank, size;
/* Инициализация MPI */
MPI_Init (&argc, &argv);
/* получение ранга процесса */
MPI_Comm_rank (MPI_COMM_WORLD, &rank);
/* получение общего числа процессов */
MPI_Comm_size (MPI_COMM_WORLD, &size);
printf( "Hello world from process %d of %d\n", rank, size );
/* завершение MPI */
MPI_Finalize();
return 0;
}
Для компиляции используется компилятор и линковщик. Командная строка mpicc. (см. mpicc….- help)
Каждый из запущенных процессов должен вывести на экран свой ранг и общее число процессов. Попробуем откомпилировать и запустить эту программу.
$ mpicc hello.c –o hello.o
$ mpicc hello.o –o hello
Файл hello и будет исполняемым файлом примера. Можно запустить его на одной машине и посмотреть, что число процессоров будет равно 1, а ранг процесса 0:
$ ./hello
Hello world from process 0 of 1
При работе на сервере для запуска используется команда mpirun. У нее есть два основных аргумента – имя файла, содержащего адреса узлов и число узлов, на котором будет запущена программа.
$ mpirun n0-6 –v hosts hello
Hello world from process 0 of 7
Hello world from process 3 of 7
Hello world from process 5 of 7
Hello world from process 4 of 7
Hello world from process 2 of 7
Hello world from process 6 of 7
Hello world from process 1 of 7
Программа будет запущена на 7 узлах (включая сервер), а адреса этих узлов находятся в файле hosts. Печать на экран осуществлялась процессами не по порядку их рангов. Это связано с тем, что запуск процессов не синхронизирован, однако в MPI существуют специальные функции для синхронизации процессов.
Простейшая программа не содержит функций передачи сообщений. В реальных же задачах процессам требуется взаимодействовать друг с другом. Естественно, на передачу сообщений тратится время, что снижает коэффициент распараллеливания задачи. Чем выше скорость интерфейса передачи сообщений (например Ethernet 10Mb/sec и Gigabit Ethernet), тем меньше будут затраты на передачу данных. Т.к. время обмена данными между процессами намного (на порядки) больше времени доступа к собственной памяти, распределение работы между процессами должно быть ‘крупнозернистым’, нужно избегать ненужных пересылок данных.
Среди задач численного анализа встречается немало задач, распараллеливание которых очевидно. Например, численное интегрирование сводится фактически к (многочисленному) вычислению подинтегральной функции (что естественно доверить отдельным процессам), при этом главный процесс управляет процессом вычислений (определяет стратегию распределения точек интегрирования по процессам и собирает частичные суммы). Подобным же распараллеливанием обладают задачи поиска и сортировки в линейном списке, численного нахождения корней функций, поиск экстремумов функции многих переменных, вычисление рядов и другие. В этой лабораторной работе мы рассмотрим два параллельных алгоритма вычисления числа π.
Вычисление числа π методом численного интегрирования
Известно, что 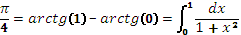
Заменяя вычисление интеграла конечным суммированием, имеем  , где
, где 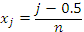 , n-число участков суммирования при численном интегрировании. Площадь каждого участка вычисляется как произведение ширины ‘полоски’ на значение функции в центре ‘полоски’, далее площади суммируются главным процессом (используется равномерная сетка).
, n-число участков суммирования при численном интегрировании. Площадь каждого участка вычисляется как произведение ширины ‘полоски’ на значение функции в центре ‘полоски’, далее площади суммируются главным процессом (используется равномерная сетка).
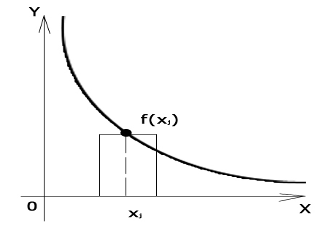
Очевидно, что распараллеливание этой задачи легко сделать, если каждый процесс будет считать свою частичную сумму, а затем передаст результат вычислений главному процессу. Как избежать здесь повторяющихся вычислений? Процесс должен знать свой ранг, общее число процессов и число интервалов, на которое будет разбит отрезок (чем больше интервалов, тем выше будет точность). Тогда в цикле от 1 до числа интервалов процесс будет вычислять площадь полоски на i-ом интервале, а затем переходить не на следующий i+1интевал, а на интервал i+m, где m-число процессов. Как мы уже знаем, для получения ранга и общего числа процессов существуют функции MPI_Comm_rank и MPI_Comm_size. Перед началом вычислений главный процесс должен передать всем остальным число интервалов, а после вычислений собрать у них полученные частичные суммы и просуммировать их, в MPI это реализуется передачей сообщений. Для передачи сообщений здесь удобно использовать функцию коллективного взаимодействия MPI_Bcast, которая рассылает одинаковые данные от одного процесса всем остальным. Для сбора частичных сумм есть 2 варианта - можно использовать MPI_Gather, которая собирает данные со всех процессов и отдает их одному (получается массив из m элеменов, где m-число процессов) или MPI_Reduce. MPI_Reduce действует аналогично MPI_Gather – собирает данные от всех процессов и отдает одному, но не в виде массива, а предварительно производит определенную операцию между элементами массива, например, суммирование и после этого отдает один элемент. Для этой задачи более удобным выглядит использование MPI_Reduce. Текст программы приведен ниже
#include "mpi.h"
#include <stdio.h>
#include <math.h>
double f(double a)
{
return (4.0 / (1.0 + a*a));
}
int main(int argc, char *argv[])
{
int n, myid, numprocs, i;
double PI25DT = 3.141592653589793238462643;
double mypi, pi, h, sum, x;
double startwtime, endwtime;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
n = 0;
if (myid == 0)
{
n=100;
startwtime = MPI_Wtime();
}
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
h = 1.0 / (double) n;
sum = 0.0;
for (i = myid + 1; i <= n; i += numprocs)
{
x = h * ((double)i - 0.5);
sum += f(x);
}
mypi = h * sum;
MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
if (myid == 0)
{
printf("pi is approximately %.16f, Error is %.16f\n",
pi, fabs(pi - PI25DT));
endwtime = MPI_Wtime();
printf("wall clock time = %f\n",
endwtime-startwtime);
}
MPI_Finalize();
return 0;
}
Рассмотрим подробнее вызовы функий MPI_Bcast и MPI_Reduce:
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD) – содержимое переменной n и одного элемента типа MPI_INT из процесса с рангом 0 посылается всем остальным процессам (MPI_COMM_WORLD – все процессы в коммуникаторе ) в ту же переменную n. После этого вызова каждый процесс будет знать общее число интервалов. По окончании вычислений MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD) суммирует (параметр MPI_SUM) значения из переменных mypi типа MPI_DOUBLE каждого процесса и записывает результат в переменную pi процесса с рангом 0. Для замера времени вычислений главный процесс использует функцию MPI_Wtime.
double MPI_Wtime();
MPI_Wtime возвращает число секунд в формате числа с плавающей точкой, представляющее время, прошедшее с момента старта программы.
Вычисление числа π методом Монте-Карло
Для вычисления значения πможно использовать метод ‘стрельбы’. В применении к данному случаю метод заключается в генерации равномерно распределенныхна двумерной области [0 ≤ x ≤ 1, 0 ≤ y ≤ 1] точек и определении 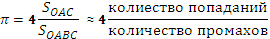 .
.
Вычисленное таким образом значение π является приближенным, в общем случае точность вычисления искомого значения повышается с увеличением числа ‘выстрелов’ и качества генетатора случайных чисел; подобные методы используются в случае трудностей точной числовой оценки.
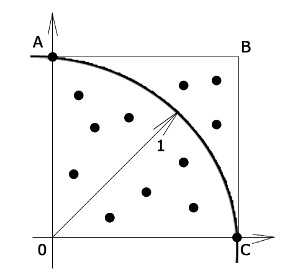
Параллельный алгоритм вычисления числа π данным методом во многом похож на предыдущий рассмотренный нами алгоритм. Для генерации случайных чисел нужно использовать функцию srand, которой в качестве агрумента (семени последовательности) задавать ранг процесса, таким образов, у каждого процесса будет своя последовательность.
#include <stdlib.h>
void srand(unsigned seed);
Функция srand() устанавливает исходное число для последовательности, генерируемой функцией rand().
#include <stdlib.h>
int rand(void);
Функция rand() генерирует последовательность псевдослучайных чисел. При каждом обращении к функции возвращается целое в интервале между нулем и значением RAND_MAX.
Для сбора результата здесь также удобно использовать MPI_Reduce с заданием операции суммирования (MPI_SUM), затем разделить полученную сумму на число процессоров, получив среднее арифметическое.
int MPI_Reduce(void* sendbuf, void* recvbuf, int count,
MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm);
Параметры:
sendbuf адрес посылающего буфера
recvbuf адрес принимающего буфера
count количество элементов в посылающем буфере (целое)
datatype тип данных элементов посылающего буфера
op операция редукции
root номер главного процесса (целое)
comm коммуникатор
int MPI_Bcast( void *buffer, int count, MPI_Datatype datatype, int root,
MPI_Comm comm );
Параметры:
buffer адрес посылающего/принимающего буфера
count количество элементов в посылающем буфере (целое)
datatype тип данных элементов посылающего буфера
root номер главного процесса (целое)
comm коммуникатор
Задание: в соответствии с номером варианта откомпилировать и запустить параллельную программы, вычисляющую число π по заданному алгоритму.
Запустить задачу на одном узле и с кластера, на заданном количестве узлов. Оценить время выполнения вычислений, точность и коэффициент распараллеливания Амдала с учетом сетевой задержки теоретически и по результатам выполнения работы.
Варианты заданий
| № Варианта | Алгоритм | Число процессоров | Число итераций на каждом процессоре |
| Численное интегрирование | |||
| Монте-Карло | |||
| Численное интегрирование | |||
| Монте-Карло | |||
| Численное интегрирование | |||
| Монте-Карло | |||
| Численное интегрирование | |||
| Монте-Карло | |||
| Численное интегрирование | |||
| Монте-Карло | |||
| Численное интегрирование | |||
| Монте-Карло | |||
| Численное интегрирование | |||
| Монте-Карло | |||
| Численное интегрирование | |||
| Монте-Карло | |||
| Численное интегрирование | |||
| Монте-Карло | |||
| Численное интегрирование | |||
| Монте-Карло |
Содержание отчета
· Постановка задачи, вариант.
· Текст параллельной программы на языке С согласно заданию.
· Результаты запуска программы на одном узле, время выполнения ti, результат вычислений, ошибка.
· Результаты запуска программы на сервере, время выполнения, результат вычислений, ошибка.
· Описать параллельный алгоритм, информационные потоки при выполнении программы и загрузку КЭШ-памяти узлов. Вычислить по результатам работы программы коэффициент Амдала - Кj.
· Учитывая результаты работы группы студентов, построить гистограмму зависимости Кj , ti от количества процессоров участвующих в вычислениях.
· Выводы. Рекомендации по улучшению быстродействия программы.
Дата добавления: 2016-05-31; просмотров: 4748;
Поиск по сайту
Узнать еще
- Arthropoda.Систематика.Тараканы и мухи.Географическое распространение.Основные представители.Морфология,развитие,патогенное действие.Медицинское знаение.Меры борьбы.
- Cущность организации и ее основные признаки
- I. Назначение унифицированных газозарядных станций и основные тактико-технические требования, предъявляемые к ним.
- I. Общие принципы структурно-функциональной организации клетки и её компоненты. Плазмолемма, её структура и функции.
- I. ОСНОВНЫЕ ПОЛОЖЕНИЯ
- I. Политический режим: понятие, сущность и основные типы.
- I.2. Основные категории водопотребления промышленных предприятий и их особенности
- II. Митохондрии (строение и функции)

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
