Функциональное назначение и лингвистическое обеспечение систем машинного перевода
В данной лекции будут рассмотрены функциональное назначение и лингвистическое обеспечение систем машинного перевода, а также принципы организации систем понимания речи.
Машинный перевод (МП), или автоматический перевод (АП) – интенсивно развивающаяся область научных исследований, экспериментальных разработок и уже функционирующих систем (СМП), в которых к процессу перевода с одного естественного языка на другой привлекается вычислительная система. СМП открывают быстрый и систематический доступ к информации на иностранном языке, обеспечивают оперативность и единообразие в переводе больших потоков текстов, в основном научно-технических. Работающие в промышленном масштабе СМП опираются на большие терминологические банки данных и, как правило, требуют привлечения человека в качестве пред-, интер- или постредактора. Современные СМП, и в особенности те, которые опираются при переводе на базы знаний в определенной предметной области, относят к классу систем искусственного интеллекта.Основные сферы использования МП:1. В отраслевых службах информации при наличии большого массива или постоянного потока иноязычных источников. Если СМП используются для выдачи сигнальной информации, постредактирование не требуется.2. В крупных международных организациях, имеющих дело с многоязычным политематическим массивом документов. Поскольку требования к переводу здесь высоки, МП нуждается в постредактировании.3. В службах, осуществляющих перевод технической документации, сопровождающей экспортируемую продукцию. Структура и язык технической документации достаточно стандартны, что облегчает МП и даже делает его предпочтительным перед ручным переводом, так как гарантирует единый стиль всего массива. Поскольку перевод спецификаций должен быть полным и точным, продукция МП нуждается в постредактировании.Помимо практической потребности делового мира в СМП, существуют и чисто научные стимулы к развитию МП: стабильно работающие экспериментальные системы МП являются опытным полем для проверки различных аспектов общей теории понимания, речевого общения, преобразования информации, а также для создания новых, более эффективных моделей самого МП.В классических СМП, осуществляющих непрямой перевод по отдельным предложениям (пофразный перевод), каждое предложение проходит последовательность преобразований, состоящую из трех этапов: АНАЛИЗ→ТРАНСФЕР (межъязыковые операции)→СИНТЕЗ. В свою очередь, каждый из этих этапов представляет собой достаточно сложную систему промежуточных преобразований.Цель этапа анализа - построить структурное описание (промежуточное представление, внутреннее представление) входного предложения. Задача этапа трансфера (перевода) - преобразовать структуру входного предложения во внутреннюю структуру выходного предложения. К этому этапу относятся и замены лексем входного языка их переводными эквивалентами (лексические межъязыковые преобразования). Цель этапа синтеза - на основе полученной в результате анализа структуры построить правильное предложение выходного языка.Лингвистическое обеспечение стандартной современной СМП включает:- словари;- грамматики;- формализованные промежуточные представления единиц анализа на разных этапах преобразований.Помимо стандартных, в отдельных СМП могут иметься и некоторые нестандартные компоненты. Так, экспертные знания о предметной области могут задаваться с помощью специальных концептуальных сетей, а не в виде словарей и грамматик.Механизмы (алгоритмы, процедуры) оперирования с имеющимися словарями, грамматиками и структурными представлениями относят к математико-алгоритмическому обеспечению СМП.Одно из необходимых требований к современным СМП - высокая модульность. С лингвистически содержательной точки зрения это означает, что анализ и следующие за ним процессы строятся с учетом теории лингвистических уровней. В практике создания СМП различают четыре уровня анализа (рис. 3).Синтез теоретически проходит те же уровни, что и анализ, но в обратном направлении. В работающих системах обычно реализован только путь от синтаксического представления до цепочки слов выходного предложения.Лингвистическое разграничение разных уровней может проявляться также в разграничении используемых в соответствующих описаниях формальных средств (набор этих средств задается для каждого уровня отдельно). На практике часто задаются отдельно лингвистические средства морфологического анализа и совмещаются средства двух остальных этапов. Но разграничение уровней может оставаться только содержательным при использовании в их описаниях единого формализма, пригодного для представления информации всех выделяемых уровней.С технической точки зрения модульность лингвистического обеспечения означает отделение структурного представления фраз и текстов (как текущих, временных знаний о тексте) от «постоянных» знаний о языке, а также языковых знаний - от знаний ПО; отделение словарей от грамматик, грамматик - от алгоритмов их обработки, алгоритмов – от программ.Словари анализа, как правило, одноязычные. Они должны содержать всю информацию, необходимую для включения данной лексической единицы (ЛЕ) в структурное представление. Часто разделяют словари основ (с морфолого-синтаксической информацией: часть речи, тип словоизменения, подкласс, характеризующий синтаксическое поведение ЛЕ и т. п.) и словари словозначений, содержащие семантическую и концептуальную информацию: семантический класс ЛЕ, семантические падежи (валентности), условия их реализации во фразе и т. д.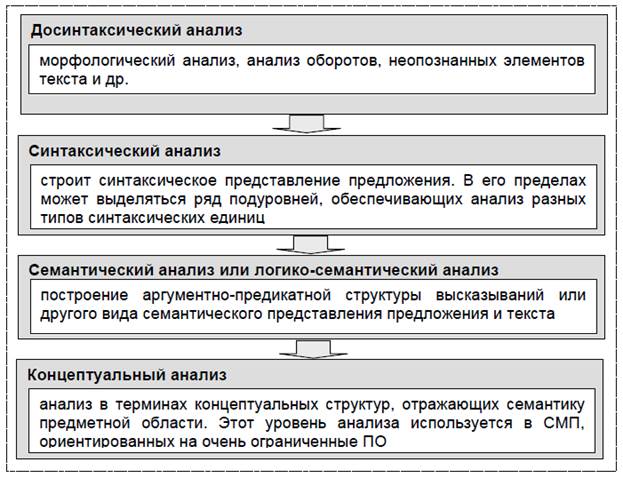 Рис. 3.1. Основные уровни анализа в СМП Во многих системах разделены словари общеупотребительной и терминологической лексики. Такое разделение дает возможность при переходе к текстам другой предметной области ограничиваться лишь сменой терминологических словарей. Словари сложных ЛЕ (оборотов, конструкции) образуют обычно отдельный массив, словарная информация в них указывает на способ «собирания» такой единицы при анализе. Часть словарной информации может задаваться в процедурной форме, например, многозначным словам могут сопоставляться алгоритмы разрешения соответствующего типа неоднозначности.Грамматика и словарь задают лингвистическую модель, образуя основную часть лингвистических данных. Алгоритмы их обработки, т. е. соотнесения с текстовыми единицами, относят к математико-алгоритмическому обеспечению системы.Разделение грамматик и алгоритмов важно в практическом смысле тем, что позволяет менять правила грамматики, не меняя алгоритмов (и соответственно программ), работающих с грамматиками. Но далеко не всегда такое разделение возможно. Так, для системы с процедурным заданием грамматики и тем более с процедурным представлением словарной информации такое разделение нерелевантно. Алгоритмы принятия решений в случае недостаточной (неполнота входных данных) или избыточной (вариантность анализа) информации в большой мере эмпиричны, их формулировка требует лингвистической интуиции.Наиболее четко разделение грамматик и алгоритмов наблюдается в системах, работающих с контекстно-свободными (КС) грамматиками (КСГ), где модель языка - грамматика с конечным числом состояний, а алгоритм должен обеспечить для произвольно взятого предложения дерево его вывода по правилам грамматики, и если таких выводов несколько, то перечислить их. Такой алгоритм, представляющий собой формальную (в математическом смысле) систему, называется анализатором. Описание грамматики служит для анализатора, обладающего универсальностью, таким же входом, как и анализируемое предложение. Анализаторы строятся для классов грамматик, хотя учет специфических особенностей грамматики может повысить эффективность анализатора.Грамматики синтаксического уровня — наиболее разработанная часть и с точки зрения лингвистики, и с точки зрения их обеспечения формализмами. Укажем основные типы грамматик и реализующих их алгоритмов (в литературе по МП их часто описывают как одну совокупность).Цепочечная грамматика фиксирует порядок следования элементов, т. е. линейные структуры предложения, задавая их в терминах грамматических классов слов (артикль+существительное+предлог...) или в терминах функциональных элементов (подлежащее+сказуемое). Примером реализации такой языковой модели является предсказуемостный синтаксический анализ: идентифицированная грамматическая категория слова предсказывает (с определенной долей вероятности) появление грамматической категории следующего за ним слова. Стратегия анализа — «слева направо»: перебор слов, проверка предсказаний, их изменение и добавление новых предсказаний регулируются механизмом «магазинной памяти» (last in first out).Грамматика составляющих (или грамматика непосредственно составляющих - НСГ) фиксирует лингвистическую информацию о группировке грамматических элементов, например, именная группа (состоит из существительного, артикля, прилагательного и других модификаторов), предложная группа (состоит из предлога и именной группы) и т.д. до уровня предложения. Грамматика строится как набор правил подстановки, или исчисление продукций вида А →В→...С. НСГ представляют собой грамматики порождающего типа и могут использоваться как при анализе, так и при синтезе: предложения языка порождаются многократным применением таких правил.Грамматика зависимостей (ГЗ) задает иерархию отношений элементов предложения (главное слово определяет форму зависимых). Анализатор в ГЗ основан на идентификации хозяев и их зависимых (слуг). Главным в предложении является глагол в личной форме, так как он определяет число и характер зависимых существительных. Стратегия анализа в ГЗ — сверху вниз (top-down): сначала идентифицируются хозяева, затем слуги, или снизу вверх: (bottom-up): хозяева определяются процессом подстановки.Новым и, сразу завоевавшим популярность, методом грамматического описания является лексико-функциональная грамматика (ЛФГ). Она устраняет необходимость трансформационных правил. Хотя ЛФГ основывается на КСГ, проверочные условия в ней отделены от правил подстановки и «решаются» как автономные уравнения.Все описанные уровни анализа используют системы понимания речи (СПР).
Рис. 3.1. Основные уровни анализа в СМП Во многих системах разделены словари общеупотребительной и терминологической лексики. Такое разделение дает возможность при переходе к текстам другой предметной области ограничиваться лишь сменой терминологических словарей. Словари сложных ЛЕ (оборотов, конструкции) образуют обычно отдельный массив, словарная информация в них указывает на способ «собирания» такой единицы при анализе. Часть словарной информации может задаваться в процедурной форме, например, многозначным словам могут сопоставляться алгоритмы разрешения соответствующего типа неоднозначности.Грамматика и словарь задают лингвистическую модель, образуя основную часть лингвистических данных. Алгоритмы их обработки, т. е. соотнесения с текстовыми единицами, относят к математико-алгоритмическому обеспечению системы.Разделение грамматик и алгоритмов важно в практическом смысле тем, что позволяет менять правила грамматики, не меняя алгоритмов (и соответственно программ), работающих с грамматиками. Но далеко не всегда такое разделение возможно. Так, для системы с процедурным заданием грамматики и тем более с процедурным представлением словарной информации такое разделение нерелевантно. Алгоритмы принятия решений в случае недостаточной (неполнота входных данных) или избыточной (вариантность анализа) информации в большой мере эмпиричны, их формулировка требует лингвистической интуиции.Наиболее четко разделение грамматик и алгоритмов наблюдается в системах, работающих с контекстно-свободными (КС) грамматиками (КСГ), где модель языка - грамматика с конечным числом состояний, а алгоритм должен обеспечить для произвольно взятого предложения дерево его вывода по правилам грамматики, и если таких выводов несколько, то перечислить их. Такой алгоритм, представляющий собой формальную (в математическом смысле) систему, называется анализатором. Описание грамматики служит для анализатора, обладающего универсальностью, таким же входом, как и анализируемое предложение. Анализаторы строятся для классов грамматик, хотя учет специфических особенностей грамматики может повысить эффективность анализатора.Грамматики синтаксического уровня — наиболее разработанная часть и с точки зрения лингвистики, и с точки зрения их обеспечения формализмами. Укажем основные типы грамматик и реализующих их алгоритмов (в литературе по МП их часто описывают как одну совокупность).Цепочечная грамматика фиксирует порядок следования элементов, т. е. линейные структуры предложения, задавая их в терминах грамматических классов слов (артикль+существительное+предлог...) или в терминах функциональных элементов (подлежащее+сказуемое). Примером реализации такой языковой модели является предсказуемостный синтаксический анализ: идентифицированная грамматическая категория слова предсказывает (с определенной долей вероятности) появление грамматической категории следующего за ним слова. Стратегия анализа — «слева направо»: перебор слов, проверка предсказаний, их изменение и добавление новых предсказаний регулируются механизмом «магазинной памяти» (last in first out).Грамматика составляющих (или грамматика непосредственно составляющих - НСГ) фиксирует лингвистическую информацию о группировке грамматических элементов, например, именная группа (состоит из существительного, артикля, прилагательного и других модификаторов), предложная группа (состоит из предлога и именной группы) и т.д. до уровня предложения. Грамматика строится как набор правил подстановки, или исчисление продукций вида А →В→...С. НСГ представляют собой грамматики порождающего типа и могут использоваться как при анализе, так и при синтезе: предложения языка порождаются многократным применением таких правил.Грамматика зависимостей (ГЗ) задает иерархию отношений элементов предложения (главное слово определяет форму зависимых). Анализатор в ГЗ основан на идентификации хозяев и их зависимых (слуг). Главным в предложении является глагол в личной форме, так как он определяет число и характер зависимых существительных. Стратегия анализа в ГЗ — сверху вниз (top-down): сначала идентифицируются хозяева, затем слуги, или снизу вверх: (bottom-up): хозяева определяются процессом подстановки.Новым и, сразу завоевавшим популярность, методом грамматического описания является лексико-функциональная грамматика (ЛФГ). Она устраняет необходимость трансформационных правил. Хотя ЛФГ основывается на КСГ, проверочные условия в ней отделены от правил подстановки и «решаются» как автономные уравнения.Все описанные уровни анализа используют системы понимания речи (СПР).
Дата добавления: 2019-09-30; просмотров: 987;
Поиск по сайту
Узнать еще
- ОСНОВНЫЕ ТИПЫ И СВОЙСТВА НАПОЛЬНЫХ И БОРТОВЫХ СИСТЕМ ТЕХНИЧЕСКОГО ДИАГНОСТИРОВАНИЯ
- Altium Designer (Protel) - сквозная система проектирования печатных плат
- B). Система относительных координат.
- CASE-технология создания информационных систем
- DSM — система классификации Американской психиатрической ассоциации
- F45.38 другие органы или системы
- I Этапы развития САSЕ-систем
- I. История возникновения и развития классно-урочной системы.

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
