Основные структуры данных
Автоматизированная обработка больших объемов данных происходит проще, когда данные упорядочены, т.е. образуют заданную структуру. Среди существующих типов структур данных можно выделить три основных [13]: линейная, иерархическая и табличная.
Линейные структуры данных могут быть представлены списками, в которых каждый элемент данных однозначно определяется своим номером в массиве. Обычный журнал посещаемости занятий, например, имеет структуру списка, т.к. все студенты группы зарегистрированы в нем под уникальными номерами.
При создании любой структуры данных надо решить два вопроса: как разделить элементы данных между собой и как находить нужные элементы. В журнале посещаемости, например, вопросы решаются так: каждый новый элемент списка заносится с новой строки, т.е. разделителем является конец строки, а каждый элемент можно найти по номеру строки.
В случае, когда все элементы списка имеют равную длину A, разделители не нужны. Для нахождения элемента с номером n надо просмотреть список с начала и отсчитать А(n-1) символов. Также упрощенные списки, состоящие из элементов равной длины, называют векторами данных. Итак, линейные структуры данных (списки) – это упорядоченные структуры, в которых адрес элемента однозначно определяется его номером.
В табличных структурах элементы данных определяются адресом ячейки, который состоит не из одного параметра, как в списках, а из нескольких. Для таблицы умножения, например, адрес ячейки определяется номерами строки и столбца. Нужные ячейки находятся на их пересечении, а элемент выбирается из ячейки.
При хранении табличных данных количество разделителей должно быть больше, чем для данных, имеющих структуру списка (строки и столбцы разделяют не одним разделителем, а двумя). Если все элементы таблицы имеют равную длину, они называются матрицами. Для хранения матриц разделители не нужны. Для нахождения элемента с адресом (m, n) в матрице, имеющей M строк и N столбцов, надо просмотреть ее с начала и отсчитать a[N(m-1)+(n-1)] символов, где a – длина одного элемента.
В практике могут быть использованы таблицы (матрицы), у которых размерность (число координат) не два ( строка и столбец), а более. Например, учет учащихся может быть организован в виде таблицы размерностью 5:
-Номер института в университете
-Номер курса (в институте)
-Номер специальности (на курсе)
-Номер группы в потоке одной специальности
-Номер учащегося в группе
Для нахождения данных об учащихся в такой структуре надо знать все пять параметров (координат).
Данные, которые трудно представить в виде списка или таблицы, часто представляют в виде иерархических структур. В иерархической структуре адрес каждого элемента определяется путем доступа (маршрутом), ведущим от вершины структуры к данному элементу. Например, пусть доступа к программе «Калькулятор» в системе Windows имеет вид: Путь -> Программы -> Стандартные -> Калькулятор.
Линейные и табличные структуры являются простыми. Ими легко пользоваться, т.к. адрес каждого элемента задается одним числом (для списка), двумя числами (для двумерной таблицы) или несколькими числами для многомерной таблицы. Они также легко упорядочиваются. Основным методом упорядочивания является сортировка. Данные можно сортировать по любому избранному критерию: по алфавиту, по возрастанию какого – либо параметра и т.п.
Несмотря на ряд достоинств простых структур данных, у них есть недостаток – их трудно обновлять. Например, при добавлении произвольного элемента в упорядоченную структуру списка может происходить изменение адресных данных у других элементов.
Иерархические структуры данных по форме сложнее, чем линейные и табличные, но они не создают проблем с обновлением данных. Их легко развивать путем создания новых уровней. Недостатком иерархических структур является относительная трудоемкость записи адреса элемента данных и сложность упорядочивания. Часто методы упорядочивания в таких структурах основываются на предварительной индексации, которая заключается в том, что каждому элементу данных присваивается свой уникальный индекс, который может использоваться при поиске, сортировке и т.д.
Особо следует сказать об адресных данных. В любой организованной структуре каждый элемент данных имеет адрес. Адреса элементов данных – это тоже данные и их тоже надо хранить и обрабатывать. Таким образом, за упорядоченность данных приходится платить их размножением – появлением адресных данных.
Как уже отмечалось ранее, наименьшей единицей измерения данных является байт. В качестве единицы хранения данных принят объект переменной длины, называемый файлом. Файл – это последовательность произвольного числа байтов, обладающая уникальным собственным именем [16]. Обычно в отдельном файле хранят данные, относящиеся к одному типу. В этом случае тип данных определяет тип файла. Имя файла несет в себе адресные данные, а также сведения о типе данных, заключенных в нем. Эти сведения важны для автоматических средств работы с данными при выборе адекватного метода извлечения информации из файла.
Хранение файлов организуется в иерархической структуре, называемой файловой структурой. Вершиной структуры является имя носителя, на котором хранятся файлы. Далее файлы группируются в папки (каталоги), внутри которых могут быть созданы вложенные папки (подкаталоги). Путь доступа к файлу начинается с имени устройства и включает все имена папок (каталогов), через которые проходит. В качестве разделителя используется символ «\». Уникальность имени файла обеспечивается тем, что полным именем файла считается собственное имя файла с путем доступа к нему. Пример записи полного имени файла. C:\информатика\задания\работа с электронными таблицами
Основные понятия баз данных и систем управления базами данных
Общие сведения
База данных – это структурированная совокупность данных, предназначенная для хранения информации.
С понятием баз данных связано понятие системы управления базой данных (СУБД). Это комплекс программных средств, предназначенных для создания и редактирования структуры базы данных, наполнения ее содержимым, редактирования содержимого и визуализации информации. Под визуализацией информации понимается отбор отображаемых данных в соответствии с заданным критерием, их упорядочение, оформление и последующая выдача на устройство вывода или передача по каналам связи.
Важным понятием баз данных является модель данных – формализованное описание, отражающее состав и типы данных, а также взаимосвязи между ними. По логической организации различают реляционные, сетевые и иерархические модели данных.
В реляционных моделях данные представляются в виде таблиц. Если данные и связи имеют структуру графа, то модель называется сетевой, если структуру дерева – иерархической.
Использование реляционных моделей позволяет наиболее удобно для пользователя описать структуру данных и манипулировать ими. На основе развитого математического аппарата реляционной алгебры можно описывать различные сложные преобразования данных. В связи с этим реляционные базы данных наиболее широко распространены и будут рассмотрены ниже.
Итак, в реляционных базах данных данные представляются в виде таблиц (отношений). Столбцы в этих таблицах называются полями (атрибутами), строки – записями (кортежами). Состав полей базовых таблиц определяет структуру базы данных. При изменении полей базовых таблиц изменяется структура базы данных. Если записей в таблице пока нет, ее структура образована только набором полей. На рис. 17 изображена простейшая таблица базы данных. AMD Athlon 1000Mhz
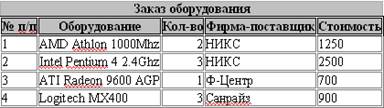
Рис. 17. Простейшая таблица базы данных
Поля базы данных определяют групповые свойства данных, записываемых в ячейки, принадлежащие каждому из полей. Ниже приводятся некоторые свойства полей таблиц баз данных на примере СУБД Microsoft Access, входящей в пакет Microsoft Office.
Имя поля – определяет, как следует обращаться к данным этого поля при автоматических операциях с базой (по умолчанию имена полей используются в качестве заголовков столбцов таблицы)
Тип поля – определяет тип данных, которые могут содержаться в данном поле
Размер поля – определяет предельную длину (в символах) данных, которые могут размещаться в данном поле (для текстового типа поля)
Формат поля – определяет способ форматирования данных в ячейках, принадлежащих полю.
Таблицы баз данных обычно допускают работу с большим количеством разных типов данных. Ниже приводятся некоторые типы данных, используемых в СУБД Microsoft Access.
Текстовый – для хранения текста, ограниченного размерами до 255 символов.
Поле MEMO – для хранения больших объемов текста (до 65535 символов), физически текст хранится не в поле, а в другом месте базы данных, а в поле хранится указатель на него, но для пользователя такое разделение заметно не всегда.
Числовой – для хранения действительных чисел.
Дата\время – для хранения календарных дат и текущего времени.
Денежный – для хранения денежных сумм
Счетчик – для не повторяющихся в поле натуральных чисел с автоматическим наращиванием (обычно используется для порядковой нумерации записей).
Логический – для хранения данных, которые могут принимать значения только «да» или «нет».
Поле объекта OLE – предназначено для хранения объектов OLE (Object Linking and Embedding) - объектов, связанных с данной таблицей, например, мультимедийных. Как и в случае с полем MEMO, они хранятся в другом месте внутренней структуры файла базы данных, а в таблице хранятся только указатели на них (иначе работа с таблицей была бы замедленной).
Гиперссылка – поле для хранения адресов Web- объектов интернета. При щелчке на ссылке автоматически происходит запуск браузера и воспроизведение объекта в его окне.
Мастер подстановки – это не специальный тип данных, а объект, настройкой которого можно автоматизировать ввод данных в поле так, чтобы не вводить их вручную, а выбирать из раскрывающегося списка.
В большинстве случаев информация, содержащаяся в базах данных, имеет значительную ценность. Поэтому целостность базы данных не должна зависеть ни от конкретных действий пользователя, забывшего сохранить файл и перед выключением компьютера, ни от «зависания» компьютера, ни от перебоев энергосети. Функции сохранения целостности базы данных осуществляет СУБД. В частности, при завершении изменений пользователем данных в доступной ему таблице или завершением им выдачи запросов (окончании транзакции) СУБД немедленно записывает эти изменения или запросы из оперативной памяти на дисковую.
Особо следует отметить проблему защиты данных от несанкционированного доступа. Эта проблема решается как с помощью паролей, присваиваемых пользователям сети администратором базы данных, так и известными методами шифрования данных.
Дата добавления: 2016-09-26; просмотров: 4688;
Поиск по сайту
Узнать еще
- Arthropoda.Систематика.Тараканы и мухи.Географическое распространение.Основные представители.Морфология,развитие,патогенное действие.Медицинское знаение.Меры борьбы.
- Cущность организации и ее основные признаки
- I. Назначение унифицированных газозарядных станций и основные тактико-технические требования, предъявляемые к ним.
- I. ОСНОВНЫЕ ПОЛОЖЕНИЯ
- I. Политический режим: понятие, сущность и основные типы.
- I.2. Основные категории водопотребления промышленных предприятий и их особенности
- ID_структуры . ID_поля
- II. Основные задачи ГО

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
