LANGUAGE AS A BI-DIRECTIONAL TRANSFORMER
The main purpose of human communication is transferring some information—let us call it Meaning[6]—from one person to the other. However, the direct transferring of thoughts is not possible.
 FIGURE IV.2. Language functions like encoder / decoder in a communication channel.
FIGURE IV.2. Language functions like encoder / decoder in a communication channel.
|
Thus, people have to use some special physical representation of their thoughts, let us call it Text.[7] Then, language is a tool to transform one of these representations to another, i.e. to transform Meanings to words when speaking, and the words to their Meaning when listening (see Figure IV.1).
It is important to realize that the communicating persons use the same language, which is their common knowledge, and each of them has a copy of it in the brain.
If we compare this situation with transferring the information over a communication channel, such as a computer network, the role of language is encoding the information at the transmitting end and then decoding it at the receiving end.[8] Again, here we deal with two copies of the same encoder/decoder (see Figure IV.2).
Thus, we naturally came to the definition of natural language as a transformer of Meanings to Texts, and, in the opposite direction, from Texts to Meanings (see Figure IV.3).
 FIGURE IV.3. Language as a Meaning Û Text transformer.
FIGURE IV.3. Language as a Meaning Û Text transformer.
|
This transformer is supposed to reside in human brain. By transformation we mean some form of translation, so that both the Text and the corresponding Meaning contain the same information. What we specifically mean by these two concepts, Text and Meaning, will be discussed in detail later.
Being originally expressed in an explicit form by Igor Mel’čuk , this definition is shared nowadays by many other linguists. It permits to recognize how computer programs can simulate, or model, the capacity of the human brain to transform the information from one of these representations into another.
Essentially, this definition combines the second and the third definitions considered in the previous section. Clearly, the transformation of Text into Meaning and vice versa is obligatory for any human communication, since it implies transferring the Meaning from one person to another using the Text as its intermediate representation. The transformation of Meaning into Text is obligatory for the generation of utterances. To be more precise, in the whole process of communication of human thoughts the definition 1 given earlier actually refers to Meaning, the definition 2 to Text, and the definition 3 to both mentioned aspects of language.
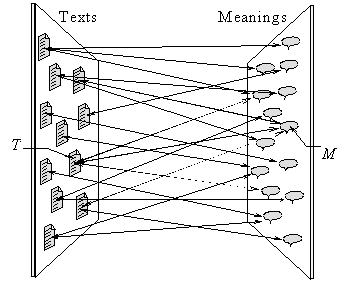 FIGURE IV.4. Meaning Û Text many-to-many mapping.
FIGURE IV.4. Meaning Û Text many-to-many mapping.
|
With our present definition, language can be considered analogous to a technical device, which has input and output. Some information, namely Text, being entered to its input, is transformed into another form with equivalent contents.
The new form at the output is Meaning. More precisely, we consider a bi-directional transformer, i.e., two transformers working in parallel but in opposite directions. Text is the result of the activity of one of these transformers, and Meaning, of the other.
Programmers can compare such a device with a compiler, let us say, a C++ compiler, which takes a character file with the ASCII text of the program in the input and produces some binary code with machine instructions, as the output. The binary code corresponds to the meaning of the program. However, a compiler usually cannot translate the machine instructions back to a C++ program text.
As a mathematical analogy to this definition, we can imagine a bi-directional mapping between one huge set, the set of all possible Texts, and another huge set, the set of all possible Meanings (see Figure IV.4).
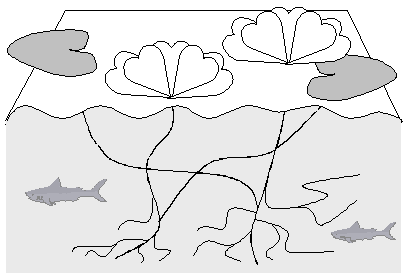 FIGURE IV.5. Metaphor of surface and deep structures.
FIGURE IV.5. Metaphor of surface and deep structures.
|
The two sets, Texts and Meanings, are not quite symmetric in their properties. Only the Texts have an explicit expression, only they can be immediately observed or directly transferred from one person to another, while the Meanings reside in the brain of each person independently and cannot be immediately observed or assessed.
This is similar to the front panel of an electrical device: the lights and switches on its surface can be observed, while the electrical processes represented by the lights and controlled by the switches are deep[9] under the cover of the device, and can only be guessed by watching the lights or experimenting with the switches.
Another metaphor of surface and deep structures of language is shown in Figure IV.5. We can directly observe the surface of water, but in order to learn what leaf is connected to what flower through common roots, we need to analyze what is under the surface. There is much more below the surface than on top of it, and only analysis of the deeper phenomena gives us understanding of the whole thing.
 FIGURE IV.6. Two levels of representation.
FIGURE IV.6. Two levels of representation.
|
All this is often considered as surface and deep levels of the representation of utterances (see Figure IV.6). The man on the picture cannot see the meaning of the text immediately and has to penetrate below the surface of the text to find its meaning.
Thus, the set of Texts is considered the surface edge of the Meaning Û Text transformer, while the set of Meanings gives its deep edge. The Meaning corresponding to the given Text at the depth is also called its semantic representation.
The transformation of Meaning into Text is called synthesis of the Text. The transformation to the inverse direction, that is from Text into Meaning, is called analysis of Text. Thus, according to our basic definition, natural language is both analyzer and synthesizer of Texts, at the same time.
This definition uses the notions of Text and Meaning, although they have been neither defined nor described so far. Such descriptions will be given in the following sections.
TEXT, WHAT IS IT?
The empirical reality for theoretical linguistics comprises, in the first place, the sounds of speech. Samples of speech, i.e., separate words, utterances, discourses, etc., are given to the researchers directly and, for living languages, are available in an unlimited supply.
Speech is a continuous flow of acoustic signals, just like music or noise. However, linguistics is mainly oriented to the processing of natural language in a discrete form.
The discrete form of speech supposes dividing the flow of the acoustic signals into sequentially arranged entities belonging to a finite set of partial signals. The finite set of all possible partial signals for a given language is similar to a usual alphabet, and is actually called a phonetic alphabet.
For representation of the sound of speech on paper, a special phonetic transcription using phonetic symbols to represent speech sounds was invented by scientists. It is used in dictionaries, to explain the pronunciation of foreign words, and in theoretical linguistics.
A different, much more important issue for modern computational linguistics form of speech representation arose spontaneously in the human practice as the written form of speech, or the writing system.
People use three main writing systems: that of alphabetic type, of syllabic type, and of hieroglyphic type. The majority of humankind use alphabetic writing, which tries to reach correspondence between letters and sounds of speech.
Two major countries, China and Japan,[10] use the hieroglyphic writing. Several countries use syllabic writing, among them Korea. Hieroglyphs represent the meaning of words or their parts. At least, they originally were intended to represent directly the meaning, though the direct relationship between a hieroglyph and the meaning of the word in some cases was lost long ago.
Letters are to some degree similar to sounds in their functions. In their origin, letters were intended to directly represent sounds, so that a text written in letters is some kind of representation of the corresponding sounds of speech. Nevertheless, the simple relationship between letters and sounds in many languages was also lost. In Spanish, however, this relationship is much more straightforward than, let us say, in English or French.
Syllabic signs are similar to letters, but each of them represents a whole syllable, i.e., a group of one or several consonants and a vowel. Thus, such a writing system contains a greater number of signs and sometimes is less flexible in representing new words, especially foreign ones. Indeed, foreign languages can contain specific combinations of sounds, which cannot be represented by the given set of syllables. The syllabic signs usually have more sophisticated shape than in letter type writing, resembling hieroglyphs to some degree.
In more developed writing systems of a similar type, the signs (called in this case glyphs) can represent either single sounds or larger parts of words such as syllables, groups of syllables, or entire words. An example of such a writing system is Mayan writing (see Figure I.2). In spite of their unusual appearance, Mayan glyphs are more syllabic signs than hieroglyphs, and they usually represent the sounds of the speech rather than the meaning of words. The reader can become familiar with Mayan glyphs through the Internet site [52].
Currently, most of the practical tasks of computational linguistics are connected with written texts stored on computer media. Among written texts, those written in alphabetic symbols are more usual for computational linguistics than the phonetic transcription of speech.[11] Hence, in this book the methods of language processing will usually be applied to the written form of natural language.
For the given reason, Texts mentioned in the definition of language should then be thought of as common texts in their usual written form. Written texts are chains of letters, usually subdivided into separate words by spaces[12] and punctuation marks. The combinations of words can constitute sentences, paragraphs, and discourses. For computational linguistics, all of them are examples of Texts.[13]
Words are not utmost elementary units of language. Fragments of texts, which are smaller than words and, at the same time, have their own meanings, are called morphs. We will define morphs more precisely later. Now it is sufficient for us to understand that a morph can contain an arbitrary number of letters (or now and then no letters at all!), and can cover a whole word or some part of it. Therefore, Meanings can correspond to some specially defined parts of words, whole words, phrases, sentences, paragraphs, and discourses.
It is helpful to compare the linear structure of text with the flow of musical sounds. The mouth as the organ of speech has rather limited abilities. It can utter only one sound at a time, and the flow of these sounds can be additionally modulated only in a very restricted manner, e.g., by stress, intonation, etc. On the contrary, a set of musical instruments can produce several sounds synchronously, forming harmonies or several melodies going in parallel. This parallelism can be considered as nonlinear structuring. The human had to be satisfied with the instrument of speech given to him by nature. This is why we use while speaking a linear and rather slow method of acoustic coding of the information we want to communicate to somebody else.
The main features of a Text can be summarized as follows:
· Meaning. Not any sequence of letters can be considered a text. A text is intended to encode some information relevant for human beings. The existing connection between texts and meanings is the reasonfor processing natural language texts.
· Linear structure. While the information contained in the text can have a very complicated structure, with many relationships between its elements, the text itself has always one-dimensional, linear nature, given letter by letter. Of course, the fact that lines are organized in a square book page does not matter: it is equivalent to just one very long line, wrapped to fit in the pages. Therefore, a text represents non-linear information transformed into a linear form. What is more, the human cannot represent in usual texts even the restricted non-linear elements of spoken language, namely, intonation and logical stress. Punctuation marks only give a feeble approximation to these non-linear elements.
· Nested structure and coherence. A text consists of elementary pieces having their own, usually rather elementary, meaning. They are organized in larger structures, such as words, which in turn have their own meaning. This meaning is determined by the meaning of each one of their components, though not always in a straightforward way. These structures are organized in even larger structures like sentences, etc. The sentences, paragraphs, etc., constitute what is called discourse, the main property of which is its connectivity, or coherence: it tells some consistent story about objects, persons, or relations, common to all its parts. Such organization provides linguistics with the means to develop the methods of intelligent text processing.
Thus, we could say that linguistics studies human ways of linear encoding[14] of non-linear information.
Дата добавления: 2016-09-06; просмотров: 1490;
Поиск по сайту
Узнать еще
- ANALOGY IN NATURAL LANGUAGES
- Chief characteristics of the Germanic languages
- Chief characteristics of the Germanic Languages.
- COMMON FEATURES OF MODERN MODELS OF LANGUAGE
- Formation of the National language
- Geographical Expansion of the English Language from the 17th to 19th c. English Outside Great Britain
- GRAMMAR IN THE SYSTEMIC CONCEPTION OF LANGUAGE
- Inner and outer history of the language

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
