Класс моделей полигональных объектов
Полигональный объект (полигон) в векторном формате пространственных данных определяется через замкнутую полилинию, которая представляет собой границу части территории, имеющую определенные свойства. Следовательно, описание полигона Vj совпадает с описанием полилинии Lj (49). Отличие в данном случае заключается в замкнутости Lj, т.е. первый и последний узлы совпадают.
Свойства данной части территории (полигонального объекта) будем определять как множество сгруппированных узловых точек сети участков, имеющих один и тот же коэффициент веса:
 для
для 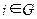 , (44)
, (44)
где G – множество узловых точек ЭУ wi, находящихся на территории, ограниченной полилинией – границей полигона.
Выражение (44) дает следующий алгоритм построения модели полигонального объекта. Необходимо определить, лежит ли текущая i-я точка внутри j-го полигонального объектаVj, представляющего собой участок территории, ограниченный замкнутой полилинией Lj. Если да, то Sij ® Sj, иначе Sij ® 0 (см. также выражение (25).
Сложность реализации данного алгоритма обусловлена необходимостью решения топологической задачи по определению принадлежности текущей точки полигональному объекту. Возможно несколько способов решения данной задачи. Рассмотрим два наиболее перспективных.
Суть первого способа заключается в следующем (рис. 26):
1. Вычисляется площадь исходного полигона Vj.
2. На основе исходного полигона строится новый, границы которого представляют собой полилинию, проходящую через все исходные узлы и текущую Pi точку.
3. Вычисляется площадь полученного полигона Vjp.
4. Если Vjp > Vj, то точка Pi лежит вне полигона,
если Vjp£ Vj, то точка Pi принадлежит полигону Vj.
Реализация этого способа связана с построением нового полигона и вычислением площади фигуры произвольной формы, что при невыпуклых конфигурациях полигонов делает необходимым решение нетривиальной задачи выбора узлов для такого построения.
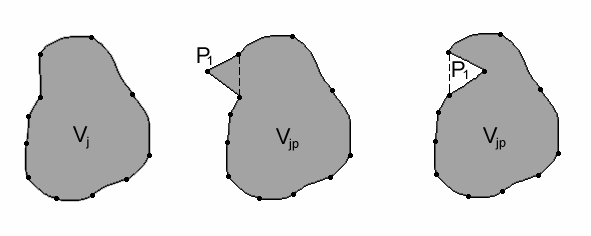
Рис. 26. Определение принадлежности текущей точки полигональному объекту (первый способ)
Второй способ выглядит более перспективным. Его идея заключается в определении числа пересечений m луча произвольного направления из точки Pi с линией границы полигона. Алгоритм следующий:
1. Если m – четное число, то Pi лежит вне полигона Vj.
2. Если m – нечетное, то Pi принадлежит полигону Vj.
Из рис. 27 видно, что это справедливо для любой формы полигона, в том числе и квазикольцеобразной формы.
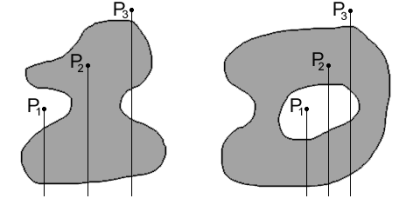
Рис. 27. Определение принадлежности текущей точки полигональному объекту (второй способ)
Наиболее просто задача решается, если лучи опускать перпендикулярно. Последовательность операций при решении топологической задачи принадлежности точки Pi полигону Vj заключается в следующем:
1. Определить, является ли полилиния Lj замкнутой; если да, то объект – полигон.
2. Исключить из рассмотрения отрезки ljn полилинии Lj, которые лежат выше точки Pi.
3. Определить для оставшихся отрезков, лежит или нет точка Pi на одном из них; если да, то Pi принадлежит Vj.
4. При несоблюдении условия из п. 3 определяется количество пересечений m вертикали, проходящей через точку Pi, с отрезками полилинииLj, лежащими ниже точки Pi. Если число m – нечетное, то Pi принадлежит Vj .
Кроме того, необходимо выделить предельные случаи, когда вертикальный луч проходит через узел, т.к. вопрос четного или нечетного пересечения сходящихся в этом узле отрезков является неопределенным. На рис. 28 представлены типичные примеры взаимного положения полигона Vj, заданного замкнутой полилинией в виде списка узловых точек P1–P10, и текущих точек рассматриваемой территории P13–P17. Реализацию алгоритма принадлежности текущих точек полигону Vj целесообразно осуществлять так же, как и при построении модели влияния полилинии с последовательного определения взаимного положения отрезков ljn и точек Pi.
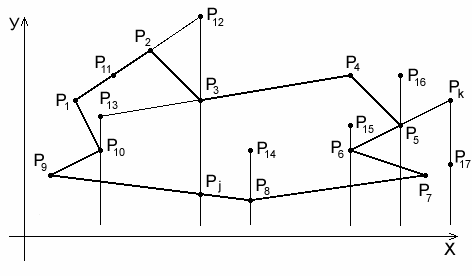
Рис. 28. Типичные примеры взаимного положения полигона Vj, заданного
замкнутой полилинией в виде списка узловых точек P1–P10 и точек P13–P17
При этом в первую очередь определяется, лежит ли текущая точка на границе полигона, т.е. на отрезке ljn. Вычисляется коэффициент наклона отрезков ljn и линии, соединяющей текущую точку с одной из вершин по выражению (53). Если, например, для отрезка l12
kl=kn+1 и (X3–X1)(X3–X2)<0,
или в общем виде
(Xi–Xn)(Xi–Xn+1)<0, (45)
то точка Pi лежит на отрезке ln,n+1 (P3 на l12) и принадлежит Vj.
Если условие (45) не соблюдается, то вопрос о принадлежности остается открытым. Например, P12 не принадлежит Vj, а точка P13, лежащая на продолжении линии l34, принадлежит Vj. Для определения принадлежности, как было показано выше, необходимо подсчитать количество пересечений m вертикального луча из Pi с отрезками полилинии Lj. При реализации данного этапа алгоритма определяется, проходит ли вертикаль, опущенная из текущей точки, через узел полилинии Lj, или нет. Если проходит, т.е. Xi=Xn, например, для точки P12 X12=X4 и для точки P13 X13=X10, то необходимо определить, рассматривать ли это пересечение, или нет. Из рис. 28 видно, что когда отрезки сходятся в узел с разных сторон вертикали (точки P12, P14), то пересечение с такими узлами (P3, P8) необходимо учитывать (т.е. m®m +1).
В том случае, когда отрезки лежат по одну сторону от вертикали (точки P13, P15, P16), то пересечения с их узлами (P10, P6, P5) необходимо отбросить при подсчете общего числа пересечений, т.е. m®m. Признак такого взаимоположения, например, отрезков l56, l67 и вертикали из точки P15 дает выражение (X5–X15)(X7–X15)>0.
В общем виде:
если (Xn–Xi) (Xn+2–Xi)<0, то m®m+1
если (Xn–Xi)(Xn+2–Xi)>0, то m®m.
И, наконец, рассмотрим наиболее часто встречающийся случай определения пересечения вертикали с отрезками полилинии Lj (например, (см. рис. 28) для точек P12, P13 пересечение с l67, для P16 пересечение с l67 и l78). В начале определяется координата Y точки пересечения Pj с отрезком ln,n+1 и вертикалью из точки Pi:
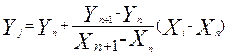 .
.
Затем определяется, лежит ли точка пересечения ниже текущей точки путем сравнения их координат: Yj < Yi. Если да (это условие совпадения), то определяется, пересекает ли вертикаль отрезок ln,n+1. Признак пересечения определяет выполнение условия:
если (Xi–Xn) (Xi–Xn+1)< 0, то m®m +1, иначе m®m.
Эти операции включают в себя процедуру проверки: расположен ли отрезок полилинии выше или ниже точки Pi. На рис. 28 показан для примера случай определения взаимоположения точки P17 и лежащего выше отрезка l56. Для точки пересечения Pk вертикали с линией, являющейся продолжением этого отрезка, справедливо выражение:
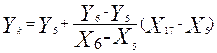 .
.
Так как Yk > Y17 , то точка пересечения игнорируется.
Полный последовательный перебор всего множества отрезков ljn даст исчерпывающую картину взаимного положения текущей точки территории Pi и полигона Vj. Рассмотрение всех текущих точек Pi, где iÎI, даст, в свою очередь, полную структурно-позиционную модель пространственного влияния полигонального объекта.
Наиболее часто встречается на практике модель, отражающая, например, занятость конкретного участка территории каким-либо зданием или сооружением, физические свойства грунта, как в рассмотренном в гл. II примере, и т.д. Однако имеется значительное количество полигональных объектов, пространственное влияние которых не ограничивается размерами этого объекта. Например, влияние на экологическую обстановку зеленого массива. Модель таких объектов будет представлять собой комбинацию модели полигона (44) и линейной модели (41) для точек, лежащих вне полигона. Алгоритм получения такой модели, очевидно, будет представлять комбинацию алгоритмов для полигона и полилинии. На рис. 29 представлена иерархическая система класса моделей полигональных объектов.

Простая модель без функции внешнего влияния
 |  |


Простая модель с симметричным Простая модель с асимметричным
законом влияния законом влияния
 |  |



| Комбинационная модель без функции внешнего влияния | Комбинационная модель с симметричным законом влияния | Комбинационная модель с асимметричным законом влияния |
Рис. 29. Класс моделей пространственного влияния полигональных объектов
Она построена по принципу «от простого к сложному», когда последующая модель является модификацией (наследницей) моделей, находящихся на предыдущем уровне.
Рассмотренный способ получения позиционного описания свойств территории не накладывает ограничения на величину wi. Однако с уменьшением размеров wi в квадратичной зависимости растет количество точек ri, а, следовательно, и объем расчетных задач. Поэтому определение оптимальных размеров ЭУ является самостоятельной задачей.
§ 3. Методы определения величины квантования модели
исследуемой территории
В первом приближении величина ЭУ (ячеек) может быть определена на основе размеров исследуемой территории и требуемой точности моделирования
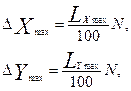 (46)
(46)
где LXmax и LYmax – максимальный размер территории по соответствующим координатам, N – требуемая точность разбивки территории, %.
Для нахождения оптимального значения величин DX и DY используем спектральный метод. Представим функцию fV(r) в виде спектра пространственных («застывших») волн, расходящихся от объекта на прилегающую территорию.
Проблему представления непрерывного рельефа в численно-матричном виде без потери полезной информации, т.е. определения оптимального периода квантования (в нашем случае величины шага сетки), можно решить использованием теоремы Котельникова.
Согласно теореме любой непрерывный процесс с ограниченным спектром может быть полностью описан дискретной последовательностью его мгновенных значений, следующих с частотой, как минимум вдвое превышающей частоту наивысшей гармоники процесса. Частота выборки мгновенных значений (отсчетов) называется частотой дискретизации (квантования). Она должна быть больше 2fmax, где fmax– максимальная присутствующая в спектре сигнала частота (частота среза).
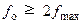 , (47)
, (47)
где fо– оптимальная частота квантования по времени; fmax – частота среза.
Выражение (47) применяется для временных рядов. В данном случае изменение функции происходит в пространстве, а не во времени. Поэтому проводится замена обозначения используемых переменных: f (временная частота) на φ (пространственная частота); Т (период) на L (длина отрезка повторения функции); 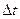 (шаг измерения во времени) на
(шаг измерения во времени) на 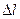 (шаг измерения в пространстве). Таким образом, выражение (47) трансформируется в
(шаг измерения в пространстве). Таким образом, выражение (47) трансформируется в
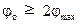 (48)
(48)
где φо – оптимальная частота квантования в пространстве; φmax – частота среза.
Если представить 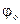 (w) в показательной форме относительно длины волны
(w) в показательной форме относительно длины волны 
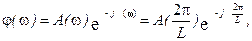 (49)
(49)
тогда выражение 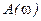 , учитывая, что
, учитывая, что 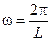 , будет представлять величины амплитуд пространственных волн для конкретных значений
, будет представлять величины амплитуд пространственных волн для конкретных значений 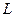 .
.
Задав минимальное значение амплитуды Amin(wmax) из выражения (49),например, 0,01 от максимального значения функции пространственного влияния, получим минимальное значение длины волны 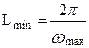 , которую необходимо учитывать при моделировании. Тогда по теореме Котельникова – Шенона максимальное расстояние между текущими точками, определяется следующим выражением:
, которую необходимо учитывать при моделировании. Тогда по теореме Котельникова – Шенона максимальное расстояние между текущими точками, определяется следующим выражением:
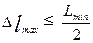 .
.
То есть размеры DXmin и DYmin ЭУ wi, на которые разбивается исследуемая территория, должны равняться 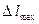 .
.
Как правило, на практике используют частоту, превышающую частоту Котельникова в 2–5 раз.
Проделав элементарные преобразования, получим, что для повторяющихся (в классическом случае – периодических) функций наибольшим периодом квантования является половина длины волны гармоники с наибольшей частотой. Исходя из этого и найдя гармоническую составляющую с наименьшей длиной волны, можно определить оптимальный шаг задания функции.
Исключение из спектра функции составляющих с небольшой амплитудой позволяет добиться увеличения шага квантования при несущественных потерях информации.
Для решения поставленных проблем используем математический аппарат спектрального анализа функции, трансформировав его также из временной области в пространственную.
Сущность гармонического анализа заключается в представлении функций в виде суммы гармонических колебаний. Классический гармонический анализ состоит в разложении периодических функций в сходящийся ряд Фурье. В нашем случае обрабатывается непериодическая (финитная) функция, т.е. ряд функций, полностью определенных на отрезке [0, l0].
Функция Y(x)раскладывается в ряд вида:
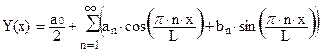 ; (50)
; (50)
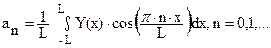 ; (51)
; (51)
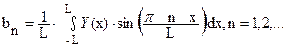 , (52)
, (52)
где anи bnназывают коэффициентами Фурье.
В большинстве случаев, например, когда анализируемая функция задана сложным аналитическим выражением, таблицей или графиком, для определения коэффициентов ряда используются либо численные методы, основанные на квадратурных формулах, либо графические приемы, либо специальные приборы (гармонические анализаторы). В этом случае используем разложение в ряд следующего вида:
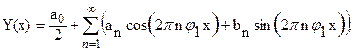 (53)
(53)
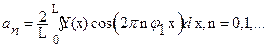 ; (54)
; (54)
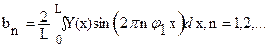 , (55)
, (55)
где L – отрезок повторения функции, 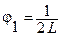 – частота повторения (или частота первой гармоники), n – номер гармоники.
– частота повторения (или частота первой гармоники), n – номер гармоники.
В формулах (69, 70, 71) диапазон повторения функции составлял 2L, а в формулах (72, 73, 74) – 1L.
Спектром функциональной зависимости Y(x) называется совокупность ее гармонических составляющих (гармоник), образующих ряд Фурье. Спектральный анализ повторяющихся функций заключается в нахождении коэффициентов an и bn ряда Фурье.
Обобщенный спектральный анализ базируется на том, что повторяющиеся функции Y(x) являются частными случаями финитных функций. Действительно, полагая l0= L (этим мы условно приписываем финитным функциям диапазон изменения L) и считая 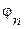 = n
= n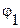 (при финитных функциях n – любые, а при периодических – целые числа), получаем:
(при финитных функциях n – любые, а при периодических – целые числа), получаем:
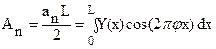 ;
;
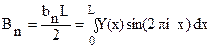 .
.
Численный спектральный анализ заключается в нахождении коэффициентов a0,..., an, b1,...,bn для повторяющейся (периодической) функции у(х), заданный на отрезке [0, L] дискретными отсчетами.
При применении численных методов коэффициенты An и Bn будут находиться следующим образом:
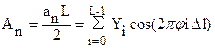 ;
;
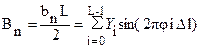 .
.
Аппарат гармонического анализа применяется к функции одной переменной. Применительно к пространственно распределенной информации (в нашем случае она представлена в виде функции двух переменных) необходимо адаптировать методику. Возможны различные варианта приведения функции двух переменных к функции одной переменной.
«Строчный» метод заключается в преобразовании трехмерного рельефа к непрерывной линии путем свертки участков, когда вслед за последним значением i-го участка считывается последнее значение i+1 участка. Движение считывания: слева направо, затем справа налево. Кроме того, задается некоторое значение величины в процентах от максимальной амплитуды и отбрасываются гармоники с меньшим значением амплитуды.
«Последовательный» метод заключается в преобразовании трехмерного рельефа к непрерывной линии путем свертки участков, когда вслед за последним значением i-го участка считывается первое значение i+1 участка. Движение считывания всегда проходит слева направо.
§ 4. Интерполяция пространственных моделей
Квантование исследуемой территории максимально допустимыми по размерам ЭУ в значительной степени ускоряет процессы пространственного анализа и моделирования. Однако это приводит к тому, что получаемая модель свойств территории будет представляться статистической поверхностью (рельефом), имеющей ступенчатый вид. Для сглаживания этой поверхности необходимо применить интерполяцию, т.е. сглаживание рельефа за счет вычисления промежуточных точек между уже имеющимися. Получаем рельеф, хотя и рассчитанный по разреженной системе точек, принадлежащих ЭУ, но имеющий близкий к непрерывной поверхности вид. Такой рельеф будет более информативен в том случае, если интерполяция осуществлена методом, обеспечивающим представление объектов или поверхностей между имеющимися точками близко к реальному виду. Интерполяция наиболее эффективна тогда, когда известно, что между имеющимися расчетными точками объектов нет резких изменений, т.е. наблюдается плавный переход. Технология определения размеров ЭУ, описанная в § 2 данной главы, как раз и обеспечивает выполнение этого условия.
Наиболее эффективным для интерполяции в рассматриваемых случаях является использование сплайнов. Методы, основанные на сплайнах, заняли прочное место среди наиболее мощных средств вычислительной математики. В настоящее время они стали общепринятым не только среди специалистов по теории приближения и вычислительной математики, но и среди инженеров, связанных с решением прикладных задач на ЭВМ. Популярность сплайнов объясняется в основном двумя причинами.
Во-первых, сплайны представляют собой чрезвычайно мощное и гибкое средство решения разнообразных задач приближения функций. Эти задачи, помимо их самостоятельного значения, лежат в основе многих методов вычислительной математики.
Во-вторых, математический аппарат, используемый для данного вида интерполяции, хорошо проработан и широко освещен в специальной литературе [23, 24].
В-третьих, алгоритмы, построенные с помощью сплайнов, эффективно реализуются на ЭВМ.
По сравнению с другими интерполяционными полиномами сплайн-функция отвечает следующим условиям:
1. Функция F(x) непрерывна на исследуемом отрезке[a,b]вместе со своими производными F'(x), F''(x),..., F(p) (x) до некоторого порядкаp.
2. На каждом отрезке [xi-1, xi] функция F(x) совпадает с некоторым многочленом степени m.
Наиболее распространены кубические сплайны, которые эффективны и в рассматриваемом случае. При этом получаются непрерывными и функция, и ее производные до второго порядка включительно.
Технология интерполяции кубическими сплайнами следующая. Интерполяционный кубический сплайн F(x) состоит из отдельных сегментов F0(x), F1(x), ..., Fn-1(x), каждый из которых определен на соответствующем отрезке, т.е. сегмент Fi(x) относится к отрезку [xi, xi+1]. Функции Fi(x) являются многочленами 3-й степени
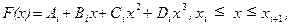
гдеi = 0, 1,…, n-1, так что в целом сплайн-функция F(x) содержит 4n коэффициентов Ai, Bi, Ci, Di.
Методики вычисления коэффициентов весьма разнообразны, но при любых обстоятельствах они отвечают условиям, указанным выше в данном параграфе. В нашем случае использовались следующие выражения:
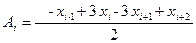 ,
,
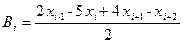 ,
,
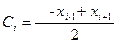 ,
,
 .
.
Технология и результаты применения интерполяции показаны на рис. 29. Как видно из рис. 29, после применения интерполяции, представление исходной поверхности в графическом виде несколько трансформировалась, теперь она стала более сглаженной. Это проявилось в том, что изменились вид и границы эквидистантных линий.
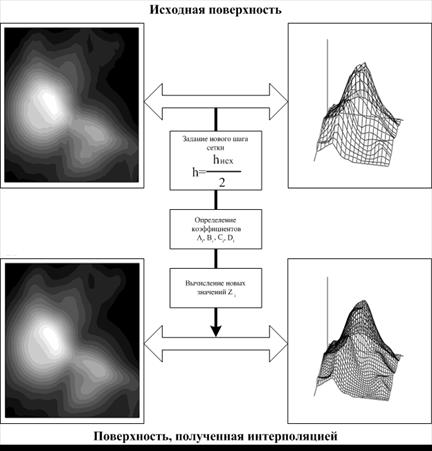
Рис. 29. Интерполяция поверхности бикубическими сплайнами
Таким образом, применение интерполяции бикубическими сплайнами позволяет привести все используемые модели тематических слоев к одному минимальному шагу задания сетки.
§ 5. Фильтрация пространственных моделей
Свойства территории, получаемые с помощью функций пространственного влияния объектов, хранится в памяти компьютера в виде двумерного массива чисел, в котором каждое число определяет свойство территории в соответствующем ЭУ. При проведении анализа этих свойств необходимо убрать незначительные изменения этих свойств (отфильтровать шумы) и выявить зоны особых «всплесков», например, резких изменений свойств территории. Для этого необходимо осуществить фильтрацию получаемого в результате моделирования числового двумерного массива.
Фильтрация поверхности имеет много общего с хорошо известной в радиотехнике фильтрацией сигналов. Отличие состоит в том, что вместо «одномерного» фильтра, предназначенного для фильтрации зашумленного сигнала одной переменной (обычно – времени), для фильтрации поверхности применяются двумерные фильтры, которые представляют собой прямоугольный участок плоскости (апертуру), состоящий из ЭУ с определенными весовыми коэффициентами (коэффициентами фильтрации). Процедура фильтрации состоит в том, что данная апертура (двумерный фильтр) накладывается на фильтруемую поверхность (двумерный массив чисел свойств территории), и численные значения соответствующего ЭУ умножаются на весовой коэффициент совпадающего ЭУ апертуры. Затем полученные произведения суммируются и делятся на число ЭУ фильтра. Это среднеарифметическое значение присваивается центральному ЭУ. Фильтрация всей территории (всего массива) осуществляется путем перемещения апертуры по поверхности. В каждом положении апертуры выполняются однотипные действия, которые и определяют отклик фильтра. Данный тип фильтрации относят к пространственно-инвариантным операциям. Апертура вместе с заданной на ней весовой функцией часто называется маской [25].
Минимальный размер апертуры равен 3´3. Он обеспечивает локальную фильтрацию. Увеличение размера апертуры усиливает действие фильтра, но при этом может произойти существенное искажение информации. Это обусловлено тем, что если размер числового массива много больше размера апертуры (окна), то доля площади профильтрованного поля, на которой заметны краевые эффекты, очень мала.
Рассматриваемый механизм позволяет реализовать следующие группы фильтров: низкочастотные, высокочастотные, операторы Лапласа, курсовые градиентные.
Рассмотрим подробнее каждую из них.
Низкочастотные фильтры применяются для отсечения из спектра высокочастотных составляющих, что позволяет исключить из временного ряда или, как в нашем случае, пространственного изображения, пиковые всплески малой площади.
На рис. 30 представлены результаты работы группы низкочастотных фильтров, имеющих следующие маски:
Фильтр 1: 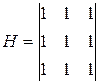 ; Фильтр 2:
; Фильтр 2: 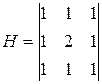 ;
;
Фильтр 3: 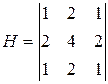 ; Фильтр 4:
; Фильтр 4: 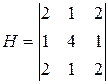 .
.
На исходной модели буквами обозначены зоны, которые не несут практически значимой информации. Все предложенные фильтры «справились» с поставленной задачей. Необходимость введения в систему нескольких однотипных фильтров объясняется тем, что помимо исследуемых зон фильтр также затрагивает и оставшиеся участки, изменяя их значения в большей или меньшей степени, в зависимости от маски.
Высокочастотные фильтры по своему функциональному предназначению составляют противоположность предыдущей группе. В этом случае значения на участках модели после фильтрации выделяются увеличением их амплитуды. Степень интенсивности изменения определяется выбранной маской.
|
|
|
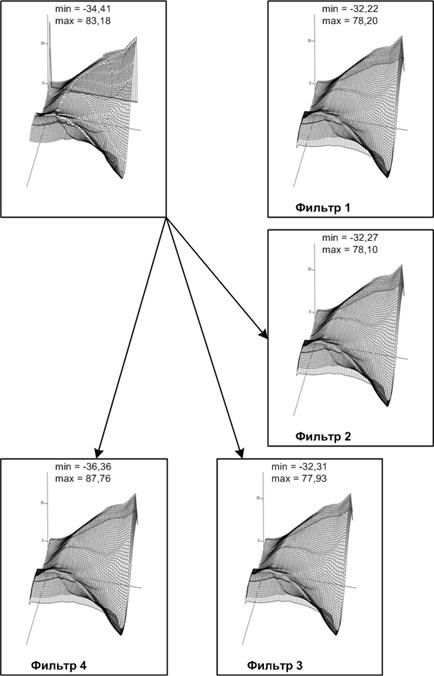
Рис. 30. Обработка модели низкочастотными фильтрами
Использовались следующие значения масок:
Дата добавления: 2016-06-15; просмотров: 2112;
Поиск по сайту
Узнать еще
- Allegro С. Прокофьев. Классическая симфония, Гавот
- Arthropoda..Систематика.Насекомые.Морфология.Классификация.Медицинское значение.
- I класс - ОКСИДОРЕДУКТАЗЫ.
- I. КЛАССИФИКАЦИЯ ПО ИСПОЛЬЗОВАНИЮ.
- I. Классификация углеводов.
- I.4. Классификация групп крови
- IA класс — блокаторы натриевых каналов, удлиняющие ЭРП
- IB класс — блокаторы натриевых каналов, укорачивающие ЭРП

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
