Глава 12. ПРОЕКТИРОВАНИЕ КЛИЕНТ-СЕРВЕРНЫХ КОРПОРАТИВНЫХ ЭИС
Основные понятия и особенности проектирования клиент-серверных экономических информационных систем (КЭИС)
Архитектура современных КЭИС базируется на принципах клиент-серверного взаимодействия программных компонентов информационной системы.
Под сервером обычно понимают процесс, который обслуживает информационную потребность клиента. В различных архитектурах в качестве процесса может быть поиск или обновление в базе данных, и тогда сервер называется сервером базы данных, или процесс может выполнять некоторая процедура обработки данных, и тогда сервер называется сервером приложения.
Клиентом является приложение, посылающее запрос на обслуживание сервером. Задачей клиента являются инициирование связи с сервером, определение вида запроса на обслуживание, получение от сервера результата обслуживания, подтверждение окончания обслуживания.
Клиент-серверная архитектура реализует многопользовательский режим работы и является распределенной, когда клиенты и серверы располагаются на разных узлах локальной или глобальной вычислительной сети. Пример локальной сети с одним сервером представлен на рис. 12.1.
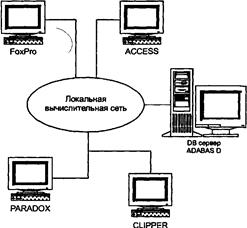
Рис. 12.1.Структура локальной вычислительной сети
Преимущество локальной сети перед централизованной вычислительной системой заключается в открытом подключении и использовании вычислительных ресурсов с помощью единой передающей среды без пересмотра принципов взаимодействия ранее установленного вычислительного оборудования, то есть простой масштабируемости КЭИС.
В общем случае схема клиент-серверной архитектуры включает три уровня представления: уровень представления (презентации) данных пользователем; уровень обработки данных приложением и уровень взаимодействия с базой данных.
По этой схеме пользователь (клиент) в одном случае вводит данные, которые после контроля и преобразования некоторым приложением попадают в базу данных, а в другом случае запрашивает обработку данных приложением, которое обращается за необходимыми данными к базе данных. Получив необходимые данные, сервер их обрабатывает, а результаты или помещает в базу данных, или выдает пользователю (клиенту) в удобном для него виде, например, в виде текстового документа, электронной таблицы, графика, или делает то и другое вместе.
Клиент-серверная архитектура в вычислительной сети может быть реализована по-разному. Выбор конкретной схемы определяется различными вариантами территориального распределения удаленных подразделений предприятия, требованиями эксплуатационной надежности, быстродействием, простотой обслуживания. Рассмотрим различные схемы клиент-серверной архитектуры (рис. 12.2).
Файл-серверная архитектура представляет наиболее простой случай распределенной обработки данных, согласно которой на сервере располагаются только файлы данных, а на клиентской части находятся приложения пользователей вместе с СУБД. Файл-сервер представляет собой достаточно мощную по производительности и оперативной памяти компьютера, являющуюся центральным узлом локальной сети. Файл-сервер в среде сетевой операционной системы организует доступ к файлам, полностью эквивалентным файлам операционной системы и расположенным во внешней памяти файл-сервера.
При данном подходе программы СУБД располагаются в оперативной памяти рабочих станций локальной сети, а файлы базы данных - на магнитных дисках файл-сервера. Специальный интерфейсный модуль распознает, где находятся файлы, к которым осуществляется обращение.
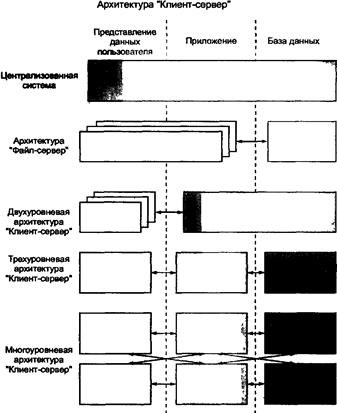
Рис. 12.2. Варианты клиент-серверной архитектуры КЭИС
В связи с этим данная СУБД может работать как с локальными базами данных, так и с центральной базой данных. Синхронизация совместного использования базы данных файл-сервера возлагается на систему управления базами данных, которая должна обеспечивать блокирование записей на время их корректировки, чтобы сделать их недоступными с других рабочих станций.
Использование файл-серверов предполагает, что вся обработка данных выполняется на рабочей станции, а файл-сервер лишь выполняет функции накопителя данных и средств доступа.
Двухуровневая клиент-серверная архитектура основана на использовании только сервера базы-данных (DB-сервера), когда клиентская часть содержит уровень представления данных, а на сервере находится база данных вместе с СУБД и прикладными программами.
DB-сервер отличается от файл-сервера тем, что в его оперативной памяти, помимо сетевой операционной системы, функционирует централизованная СУБД, которая обеспечивает совместное использование рабочими станциями базы данных, размещенной во внешней памяти этого DB-сервера.
DB-сервер дает возможность отказаться от пересылки по сети файлов данных целиком и передавать только ту выборку из базы данных, которая удовлетворяет запросу пользователя. При этом возможно разделение пользовательского приложения на две части: одна часть выполняется на сервере и связана с выборкой и агрегированием данных из базы данных, а вторая часть по представлению данных для анализа и принятия решения выполняется на клиентской машине. Таким образом, увеличивается общая производительность информационной системы в результате объединения вычислительных ресурсов сервера и клиентской рабочей станции.
Обращение к базе данных осуществляется на языке SQL, который фактически стал стандартом для реляционных баз данных. Отсюда сервер баз данных часто называют SQL-сервером, который поддерживается всеми реляционными СУБД: Oracle, Informix, MS SQL, ADABAS D, InterBase, SyBase и др. Клиентское приложение может быть реализовано на языке настольных СУБД (MS Access, FoxPro, Paradox, Clipper и др.). При этом взаимодействие клиентского приложения с SQL-сервером осуществляется через ODBC-драйвер (Ореn Data Base Connectivity), который обеспечивает возможность пересылки и преобразования данных из глобальной базы данных в структуру базы данных клиентского приложения. Применение этой технологии позволило разработчикам не заботиться о специфике работы с той или иной СУБД и делать свои системы переносимыми между базами данных. За время своего существования ODBC стал стандартом де-факто на алгоритм доступа к разнородным базам данных, и на сегодняшний день насчитывается более 160 прикладных систем, которые работают с источниками информации через драйверы ODBC.
Трехуровневая клиент-серверная архитектура позволяет помещать прикладные программы на отдельные серверы приложений, с которыми через API-интерфейс (Application Program Interface) устанавливается связь клиентских рабочих станций. Работа клиентской части приложения сводится к вызову необходимых функций сервера приложения, которые называются «сервисами». Прикладные программы в свою очередь обращаются к серверу базы данных с помощью SQL запросов. Такая организация позволяет еще более повысить производительность и эффективность КЭИС за счет:
· многократности повторного использования общих функций обработки данных во множестве клиентских приложений при существенной экономии системных ресурсов;
· параллельности в работе сервера приложений и сервера базы данных, причем сервер приложений может быть менее мощным по сравнению с сервером базы данных;
· оптимизации доступа к базе данных через сервер приложений из клиентских мест путем диспетчеризации выполнения запросов в вычислительной сети;
· повышения скорости/и надежности обработки данных в результате дублирования программного обеспечения на нескольких серверах приложений, которые могут заменять друг друга в сети в случае перегрузки или выхода из строя одного из них;
· переноса функций администрирования системы по проверке полномочий доступа пользователей с сервера базы данных на сервер приложений.
Многоуровневая архитектура «Клиент-сервер» создается для территориально-распределенных предприятий. Для нее в общем случае характерны отношения «многие ко многим» между клиентскими рабочими станциями и серверами приложений, между серверами приложений и серверами баз данных. Такая организация позволяет более рационально организовать информационные потоки между структурными подразделениями в процессе выполнения общих деловых процессов. Так, каждый сервер приложений, как правило, обслуживает потребности какой-либо одной функциональной подсистемы и сосредоточивается в головном для подсистемы структурном подразделении, например, сервер приложения по управлению сбытом - в отделе сбыта, сервер приложения по управлению снабжением - в отделе закупок и т.д. Естественно, что локальная сеть каждого из подразделений обеспечивает более быструю реакцию на запросы основного контингента пользователей из соответствующего подразделения. Интегрированная база данных находится на отдельном сервере, на котором обеспечиваются централизованное ведение и администрирование общих данных для всех приложений.
Выделение нескольких серверов баз данных особенно актуально для предприятий с филиальной структурой, когда в центральном офисе используется общая база данных, содержащая общую нормативно-справочную, планово-бюджетную информацию и консолидированную отчетность, а в территориально-удаленных филиалах поддерживается оперативная информация о деловых процессах. При обработке данных в филиалах для контроля используется плановая и нормативно-справочная информация из центральной базы данных, а в центральном офисе получение консолидированной отчетности сопряжено с обработкой оперативной информации филиалов.
Для сокращения объема передачи данных по каналам связи в распределенной информационной системе предлагается репликация данных, то есть тиражирование данных на взаимодействующих серверах баз данных с автоматическим поддержанием соответствия копий данных. При этом возможны следующие режимы репликации:
· синхронный режим, когда тиражируемые данные обновляются по мере возникновения необходимости одновременно на серверах баз данных во всех копиях. Требуемое быстродействие каналов для синхронного режима - единицы Мбит в секунду;
· асинхронный режим, когда тиражирование данных выполняется в строго определенные моменты времени, например каждый час работы информационной системы. Требуемое быстродействие каналов для асинхронного режима - единицы Кбит в секунду. Асинхронный режим может вызывать откладывание выполнения транзакций до момента обновления данных.
Направление тиражирования между серверами баз данных может быть:
· равноправным, т.е. в обоих направлениях;
· сверху-вниз типа «ведущий/ведомый», когда на серверах филиалов содержатся только некоторые подмножества данных центральной базы данных;
· снизу-вверх по консолидирующей схеме, когда при обновлении данных в филиалах в определенные моменты времени обновляется центральная база данных.
Рассмотрим технологическую сеть техно-рабочего проектирования трехуровневой клиент-серверной КЭИС (рис. 12.3).
Дата добавления: 2022-02-05; просмотров: 615;
Поиск по сайту
Узнать еще

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
