Потоки на уровне пользователя
В программе, полностью состоящей из ULT-потоков, все действия по управлению потоками выполняются самим приложением; ядро, по сути, и не подозревает о существовании потоков. На рис. 4.6,а проиллюстрирован подход, при котором используются только потоки на уровне пользователя. Чтобы приложение было много поточным, его следует создавать с применением специальной библиотеки, представляющей собой пакет программ для работы с потоками на уровне ядра. Такая библиотека для работы с потоками содержит код, с помощью которого можно создавать и удалять потоки, производить обмен сообщениями и данными между потоками, планировать их выполнение, а также сохранять и восстанавливать их контекст.
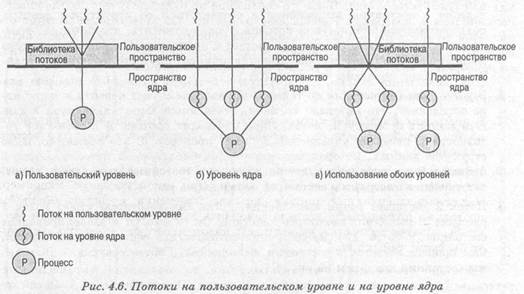
По умолчанию приложение в начале своей работы состоит из одного потока и его выполнение начинается как выполнение этого потока. Такое приложение вместе с составляющим его потоком размещается в едином процессе, который управляется ядром. Выполняющееся приложение в любой момент времени может породить новый поток, который будет выполняться в пределах того же процесса. Новый поток создается с помощью вызова специальной подпрограммы из библиотеки, предназначенной для работы с потоками. Управление к этой подпрограмме переходит в результате вызова процедуры. Библиотека потоков создает структуру данных для нового потока, а потом передает управление одному из готовых к выполнению потоков данного процесса, руководствуясь некоторым алгоритмом планирования. Когда управление переходит к библиотечной подпрограмме, контекст текущего потока сохраняется, а когда управление возвращается к потоку, его контекст восстанавливается. Этот контекст в основном состоит из содержимого пользовательских регистров, счетчика команд и указателей стека.
Все описанные в предыдущих абзацах события происходят в пользовательском пространстве в рамках одного процесса. Ядро не подозревает об этой деятельности. Оно продолжает осуществлять планирование процесса как единого целого и приписывать ему единое состояние выполнения (состояние готовности, состояние выполняющегося процесса, состояние блокировки и т.д.). Приведенные ниже примеры должны прояснить взаимосвязь между планированием потоков и планированием процессов. Предположим, что выполняется поток 2, входящий в процесс В (см. рис. 4.7). Состояния этого процесса и составляющих его потоков на пользовательском уровне показаны на рис. 4.7,а. Впоследствии может произойти одно из следующих событий.
1. Приложение, в котором выполняется поток 2, может произвести системный вызов, например запрос ввода-вывода, который блокирует процесс В. В результате этого вызова управление перейдет к ядру. Ядро вызывает процедуру ввода-вывода, переводит процесс В в состояние блокировки и передает управление другому процессу. Тем временем поток 2 процесса В все еще находится в состоянии выполнения в соответствии со структурой данных, поддерживаемой библиотекой потоков. Важно отметить, что поток 2 не выполняется в том смысле, что он работает с процессором; однако библиотека потоков воспринимает его как выполняющийся. Соответствующие диаграммы состояний показаны на рис. 4.7,6.
2. В результате прерывания по таймеру управление может перейти к ядру; ядро определяет, что интервал времени, отведенный выполняющемуся в данный момент процессу В, истек. Ядро переводит процесс В в состояние готовности и передает управление другому процессу. В это время, согласно структуре данных, которая поддерживается библиотекой потоков, поток 2процесса В по-прежнему будет находиться в состоянии выполнения. Соответствующие диаграммы состояний показаны на рис. 4.7,в.
3. Поток 2 достигает точки выполнения, когда ему требуется, чтобы поток 1процесса В выполнил некоторое действие. Он переходит в заблокированное состояние, а поток 1 — из состояния готовности в состояние выполнения. Сам процесс остается в состоянии выполнения. Соответствующие диаграммы состояний показаны на рис. 4.7,г
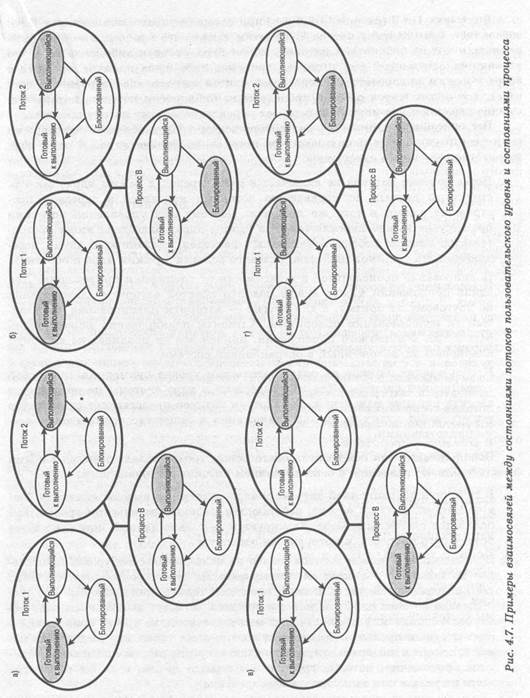
В случаях 1 и 2 (см. рис. 4.7,6 и в) при возврате управления процессу В возобновляется выполнение потока 2. Заметим также, что процесс, в котором выполняется код из библиотеки потоков, может быть прерван либо из-за того, что закончится отведенный ему интервал времени, либо из-за наличия процесса с более высоким приоритетом. Когда возобновится выполнение прерванного процесса, оно продолжится работой процедуры из библиотеки потоков, которая завершит переключение потоков и передаст управление новому потоку процесса.
Использование потоков на пользовательском уровне обладает некоторыми преимуществами перед использованием потоков на уровне ядра. К этим преимуществам относятся следующие.
1. Переключение потоков не включает в себя переход в режим ядра, так как структуры данных по управлению потоками находятся в адресном пространстве одного и того же процесса. Поэтому для управления потоками процессу не нужно переключаться в режим ядра. Благодаря этому обстоятельству удается избежать накладных расходов, связанных с двумя переключениями режимов (пользовательского режима в режим ядра и обратно).
2. Планирование производится в зависимости от специфики приложения. Для одних приложений может лучше подойти простой алгоритм планирования по круговому алгоритму, а для других — алгоритм планирования, основанный на использовании приоритета. Алгоритм планирования может подбираться для конкретного приложения, причем это не повлияет на алгоритм планирования, заложенный в операционной системе.
3. Использование потоков на пользовательском уровне применимо для любой операционной системы. Для их поддержки в ядро системы не потребуется вносить никаких изменений. Библиотека потоков представляет собой набор утилит, работающих на уровне приложения и совместно используемых всеми приложениями.
Использование потоков на пользовательском уровне обладает двумя явными недостатками по сравнению с использованием потоков на уровне ядра.
1. В типичной операционной системе многие системные вызовы являются блокирующими. Когда в потоке, работающем на пользовательском уровне, выполняется системный вызов, блокируется не только данный поток, но и все потоки того процесса, к которому он относится.
2. В стратегии с наличием потоков только на пользовательском уровне приложение не может воспользоваться преимуществами многопроцессорной системы, так как ядро закрепляет за каждым процессом только один процессор. Поэтому несколько потоков одного и того же процесса не могут выполняться одновременно. В сущности, у нас получается многозадачность на уровне приложения в рамках одного процесса. Несмотря на то, что даже такая многозадачность может привести к значительному увеличению скорости работы приложения, имеются приложения, которые работали бы гораздо лучше, если бы различные части их кода могли выполняться одновременно.
Эти две проблемы разрешимы. Например, их можно преодолеть, если писать приложение не в виде нескольких потоков, а в виде нескольких процессов. Однако при таком подходе основные преимущества потоков сводятся на нет: каждое переключение становится не переключением потоков, а переключением процессов, что приведет к значительно большим накладным затратам.
Другим методом преодоления проблемы блокирования является использование преобразования блокирующего системного вызова в не блокирующий. Например, вместо непосредственного вызова системной процедуры ввода-вывода поток вызывает подпрограмму-оболочку, которая производит ввод-вывод на уровне приложения. В этой программе содержится код, который проверяет, занято ли устройство ввода-вывода. Если оно занято, поток передает управление другому потоку (что происходит с помощью библиотеки потоков). Когда наш поток вновь получает управление, он повторно осуществляет проверку занятости устройства ввода-вывода.
Дата добавления: 2016-06-05; просмотров: 2703;
Поиск по сайту
Узнать еще
- Автокорреляция уровней временного ряда
- Адаптация человека на популяционно-видовом уровне
- Байтовые и символьные потоки
- Безрезервный профиль из привозного грунта применяют при избыточном засолении грунта, высоком уровне грунтовых вод и затруднённом отводе воды.
- Биохимический контроль развития систем энергообеспечения организма и уровнем тренированности, утомления и восстановления организма
- В противоположность этому, операционная система или инструментальное ПО не вносят прямого вклада в удовлетворение конечных потребностей пользователя.
- Взаимодействие уровней модели OSI (на примере стека TCP/IP)
- ВЗАИМООТНОШЕНИЯ В СИСТЕМЕ ПАРАЗИТ - ХОЗЯИН НА УРОВНЕ ПОПУЛЯЦИЙ

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
