Простые структуры данных
Простой типданных определяет упорядоченное множество значений некоторого параметра. Простые типы описываются базовыми типами, к которым относятся: числовые, битовые, логические, символьные, перечисляемые, интервальные и указатели. Структура некоторых простых типов языка Паскаль приведена на рис. 2.1.
Для каждого типа указан размер памяти в байтах, требуемый для размещения переменных соответствующего типа. В других языках набор простых типов может несколько отличаться. Все простые типы, за исключением вещественных и указателей, являются порядковыми.
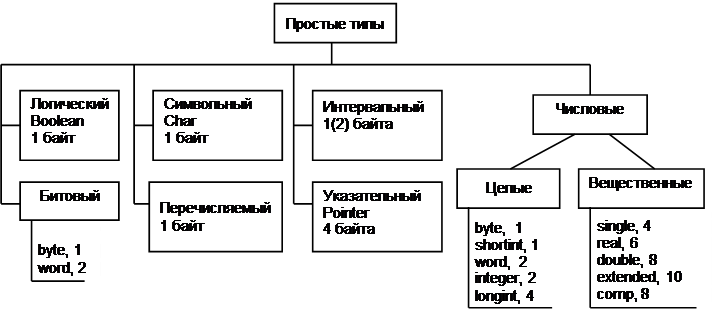
Рис. 2.1. Структура простых типов языка Паскаль.
Порядковые типы
Порядковые типыимеют конечное (счетное) множество значений, с каждым из которых соотносится целое число – порядок. Значения порядковых типов упорядочены (расположены) по возрастанию или убыванию. В табл. 2.1 приведены функции, применимые к любому порядковому типу. Для всех функций тип аргумента должен быть порядковым.
Для функций High и Low аргументом может быть переменная порядкового типа, типа-массива, типа-строки. Результат функции для величины порядкового типа – максимальное (минимальное) значение этой величины, типа-массива – максимальное (минимальное) значение индекса, типа-строки – объявленный размер строки (ноль для функции Low).
Табл. 2.1. Функции для величин порядкового типа.
| Функция | Определение | Тип результата |
| Hi | Получение максимального значения величины. | Целый |
| Lo | Получение минимального значения величины. | Целый |
| Odd | Проверка на нечетность. | Булевый |
| Ord | Порядковый номер. | Целый |
| Pred | Предшествующее значение. | Совпадает с аргументом |
| Succ | Последующее значение. | Совпадает с аргументом |
Функция Odd возвращает True для нечетного аргумента и False для четного.
Функция Ord преобразует любой порядковый тип в целый тип. Например, если x – переменная целого типа, то Ord(x) = x. Для символьного типа в соответствии со стандартом ASCII:
Ord(B) = 66, Pred(B) = A, Succ(B) = C
Для порядковых типов справедливы соотношения:
Ord(Pred(X)) = Ord(X)–1
Ord(Succ(X)) = Ord(X)+1
Целочисленный тип
С помощью целочисленного типаможет быть представлено количество объектов, являющихся дискретными по своей природе. В языке Паскаль существуют два базовых типа для работы с целочисленными значениями: Integer и Cardinal. Подтипы базовых типов включают также ShortInt, SmallInt, LongInt, Int64, Byte, Word и LongWord. В табл. 2.2 перечислены диапазон значений и формат хранения (представление) в памяти для каждого из них.
Табл. 2.2. Целые типы данных.
| Тип | Диапазон значений | Представление |
| Int64 | -263..263–1 | знаковый 64-битный |
| Integer | -2147483648..2147483647 | знаковый 32-битный |
| LongInt | -2147483648..2147483647 | знаковый 32-битный |
| Cardinal | 0..4294967295 | беззнаковый 32-битный |
| SmallInt | -32768..32767 | знаковый 16-битный |
| ShortInt | -128..127 | знаковый 8-битный |
| Byte | 0..255 | беззнаковый 8-битный |
| Word | 0..65535 | беззнаковый 16-битный |
| LongWord | 0..4294967295 | беззнаковый 32-битный |
К целочисленным операциям относятся четыре основных арифметических действия (сложение, вычитание, умножение и деление) для которых применимы математические правила старшинства операций. Для изменения порядка вычислений используются круглые скобки. Их можно использовать для составления выражений:

Результат операции над целыми числами не должен выходить за диапазон допустимых значений. В некоторых компиляторах можно задать режим проверки на переполнение каждой целочисленной операции, но это может привести к большим издержкам во время выполнения, если только данная проверка не производится аппаратными средствами.
В математике в результате деления двух целых чисел a/b получается два значения: частное q и остаток r, такие что:
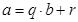
В языке Паскаль для получения частного используется оператор деления «/». Для целочисленного деления используется операция div, а для получения остатка – операция mod, которая может быть представлена через div:

Следует помнить, что арифметические операции для типа LongInt выполняются более чем вдвое дольше, нежели для типа Integer. Причина заключается в необходимости привлечения дополнительных команд для распространения переноса, возникающего из слова (двух байт) младших разрядов в слово старших разрядов.
Символьный тип
Значениями символьного типаявляются символы некоторого предопределенного множества. В основном символьный тип данных используется как базовый для построения составного типа «строка символов». В большинстве современных вычислительных машин таким множеством является кодировка ASCII или UNICODE. Множество ASCII состоит из 256 символов, упорядоченных определенным образом, и содержит символы заглавных и строчных букв, цифр и других символов, включая специальные управляющие символы.
Кодировка ASCII не является единственной. Другой схожей кодировкой является EBCDIC(Extended Binary Coded Decimal Interchange Code – расширенный двоично-кодированный десятичный код обмена), применяемый в вычислительных машинах IBM. В EBCDIC код символа также занимает один байт, но с иной кодировкой, чем в ASCII.
Кодировки ASCII и EBCDIC включают в себя буквенные символы только латинского алфавита. Символы национальных алфавитов занимают свободные места в таблицах кодов и, таким образом, одна таблица может поддерживать только один национальный алфавит. Этот недостаток преодолен в кодировке UNICODE, которая в последнее время получила большое распространение.
В кодировке UNICODEкаждый символ кодируется двумя байтами, что обеспечивает 65536 возможных кодовых комбинаций и дает возможность иметь единую таблицу кодов, включающую в себя все национальные алфавиты.
В языке Паскаль используется кодировка ASCII, а стандартным символьным типом данных является тип Char. В памяти переменная типа Char занимает 1 байт. Значениями символьного типа являются множество всех символов кодировки ASCII, включая невидимые символы клавиатуры. Каждому символу присвоен код – целое число типа Byte (0..255), который возвращает функция Ord. Например, Ord(A) = 65; Ord(F) = 70. Стандартная функция Chr(X), возвращающая символ по его коду (аргумент X должен быть байтовым), например, Chr (90) = Z.
В табл. 2.3 перечислены некоторые коды служебных символов клавиатуры. Для включения символа, не имеющего физического изображения, используется его ASCII-код с символом # перед ним.
Табл. 2.3. Специальные коды ASCII.
| Символ | Клавиша | Назначение |
| #32 | <Пробел> | Пропуск позиции |
| #27 | <Escape> | Отмена действия |
| #26 | <Ctrl+Z> | Конец файла |
| #13 | <Enter> | Возврат каретки |
| #10 | – | Конец строки |
Операция сравнения является типичной над символьным типом данных. При сравнении коды символов рассматриваются как целые числа без знака. Кодовые таблицы строятся так, что результаты сравнения подчиняются лексикографическим правилам: символы, занимающие в алфавите места с меньшими порядковыми номерами, имеют меньшие коды, чем символы, занимающие места с большими номерами, например, ‘A’ < ’Z’ (65 < 90).
Перечисляемый тип
Язык Паскаль позволяет создавать собственные типы, которые точнее соответствуют объектам решаемой задачи. Предположим, шкала некоторого устройства содержит следующие позиции: off (выключено), low (слабо), medium (средне), high (сильно). Для представления таких позиций можно объявить целочисленную переменную и для обозначения позиций четыре произвольных числа.
Однако в таком случае придется постоянно отслеживать по документации соответствие позиции и принятого для него номера, что усложнит работу с программой и ее дальнейшее сопровождение. Более того, возможно ошибочное присвоение некорректного номера, выход за диапазон или любая другая непредвиденная ситуация. Использование типа-перечисления решает эти проблемы.
Перечисляемый тип– упорядоченный набор идентификаторов, заданный их перечислением. Значение данного типа представляет собой любой идентификатор из этого набора. Перечисляемые типы аналогичны целочисленным, однако набор операций, выполняемых над ними, ограничен: допустимы операции присваивания (:=), равенства (=) и неравенства (<, >, >=, <=). Операции отношений определены потому, что набор значений в объявлении интерпретируется как упорядоченная последовательность.
В языке Паскаль перечисляемый тип является стандартным и определяется набором идентификаторов, с которыми могут совпадать значения параметра:
Type
< имя типа > = (< идентификатор 1, идентификатор 2,..., идентификатор n >)
Объявление перечисляемого типа для приведенного выше примера:
Type
TPosition = (Off, Low, Medium, High);
Порядок перечисления идентификаторов важен, т.к. им определяется порядковые номера, которые присваиваются идентификаторам. Для переменной перечислимого типа выделяется один байт, в который записывается порядковый номер присваиваемого значения. Перечисляемый тип может быть сразу описан в разделе переменных:
Var
Position: (Off, Low, Medium, High);
Перечисляемым идентификаторам ставится в соответствие последовательность целых чисел (порядок), начинающаяся с нуля. Поэтому к данным перечисляемого типа можно применять все стандартные функции и операции для порядковых типов, например:
Ord(Low) = 1
Low > Off
Succ(Medium) = High
Pred(Medium) = Low
Интервальный тип
Другой способ образования новых типов из уже существующих заключается в ограничении допустимого диапазона значений некоторого стандартного типа или границ перечисляемого. Ограничение определяется заданием минимального и максимального значений диапазона. При этом изменяется диапазон допустимых значений по отношению к базовому типу, но представление в памяти полностью соответствует базовому типу.
Таким способом формируется интервальный тип. Значения интервального типа могут принадлежать ограниченному поддиапазону некоторого базового типа. Базовым типом диапазона может быть любой порядковый тип, кроме интервального.
Для введения интервального типа необходимо указать имя типа и границы диапазона:
Type
< имя типа > = < мин. значение >..< макс. значение >
Минимальное значение при определении не может быть больше максимального:
Type
TTemp = -50..+50; { тип ShortInt }
TIndex = 1..100; { тип Byte }
Все операции, применимые к величинам базового типа, можно применять и к величинам соответствующего интервального типа с учетом его границ. Преимущества использования интервальных типов заключается в наглядности представления, экономном распределении памяти под переменные и дополнительном контроле значений переменных.
Логический тип
Логический типявляется перечисляемым с двумя возможными значениями «ложь» и «истина»:
Type
Boolean = (False, True);
Логические типы языка Паскаль приведены в табл. 2.4.
Табл. 2.4. Логические типы данных.
| Название типа | Длина, байт |
| Boolean | |
| ByteBool | |
| WordBool | |
| LongBool |
Основным типом является Boolean, для него справедливы следующие соотношения:
Ord(False) = 0; Ord(True) = 1;
Succ(False) = True; Pred(True) = False; False < True
Остальные три типа введены для совместимости с другими языками и операционной системой Windows. Для них справедливы следующие соотношения:
Ord(False) = 0;
Ord(True) <> 0 (любое целое число)
Логический тип имеет большое значение поскольку:
- операции отношения являются функциями, возвращающими значение булевого типа;
- условный оператор проверяет выражение булевого типа;
- операции булевой алгебры определены для булевого типа.
Примеры применения логических функций для сведения нескольких условий в одно логическое выражение приведены на рис. 2.2.
 |
а)
б). в).
Рис. 2.2. Одномерная (а), двухсвязная одномерная (б) и двухмерная (в) области координат.
Сформированные логические выражения по этим условиям выглядят следующим образом:
а). -1 £ x £ 1 ® (-1 <= x) and (x <= 1)
в). x < 0 или x > 1 ® (x < 0) or (x >1)
б). éx > 0 ù ® (x > 0) and (y < 0)
ëy < 0 û
Битовый тип
В ряде задач может потребоваться работа с отдельными двоичными разрядами данных. Чаще всего это возникают в системном программировании, когда, например, отдельный разряд связан с состоянием аппаратного переключателя. Данные битового типапредставляются в виде набора битов, упакованных в байты или слова, и не связанных друг с другом. Операции над такими данными обеспечивают доступ к выбранному биту. В языке Паскаль роль битовых типов выполняют беззнаковые целые типы Byte и Word. Над этими типами помимо операций, характерных для числовых типов, допускаются побитовые логические операции и операции сдвига.
Вещественный тип
В отличие от рассмотренных порядковых типов, значения которых всегда сопоставляются с рядом целых чисел и, следовательно, представляются в памяти абсолютно точно, значение вещественных типов может быть определено лишь с некоторой конечной точностью, зависящей от внутреннего формата вещественного числа. Суммарное количество байтов, диапазоны допустимых значений чисел вещественных типов и количество значащих цифр после запятой в представлении чисел приведены в табл. 2.5.
Табл. 2.5. Вещественные типы.
| Тип | Диапазон значений | Значащие цифры | Размер в байтах |
| Real | 2.9·10-39..1.7·1038 | 11-12 | |
| Single | 1.4·10-45..3.4·1038 | 7-8 | |
| Double | 4.9·10-324..1.8·10308 | 15-16 | |
| Extended | 3.1·10-4944..1.2·104932 | 19-20 |
В языке Паскаль переменные вещественного типапредставляются в форме, близкой к научной нотации:
Const
pi: Real = 3.1415926;
eq: Real = 1.19e-31;
Для вычислений с плавающей запятой необходимо минимум 32 разряда (одинарная точность, тип Single). Однако часто и одинарной точности оказывается недостаточно, поэтому языки поддерживают объявления переменных и вычисления с двойной точностью 64 разряда (тип Double).
Для переменных вещественного типа базовыми являются арифметические операции и операции отношения. Другие математические операции реализуются в разных языках по-разному. В языке Паскаль к стандартным функциям относятся также арифметические функции, перечисленные в табл. 2.6.
Табл. 2.6. Стандартные арифметические функции.
| Функция | Назначение | Тип результата |
| Abs(x) | Абсолютное значение аргумента. | совпадает с x |
| Arctan(x) | Арктангенс аргумента. | вещественный |
| Cos(x) | Косинус аргумента. | -//- |
| Exp(x) | Вычисление экспоненты. | -//- |
| Frac(x) | Дробная часть аргумента. | -//- |
| Int(x) | Целая часть числа. | -//- |
| Ln(x) | Натуральный логарифм. | -//- |
| Pi(x) | Число pi = 3.1415926535897932385. | -//- |
| Round(x) | Округление до ближайшего целого. | -//- |
| Sin(x) | Синус аргумента. | -//- |
| Sqr(x) | Квадрат аргумента. | совпадает с x |
| Sqrt(x) | Квадратный корень аргумента. | вещественный |
| Trunc(x) | Целая часть вещественного числа. | -//- |
При разработке программного обеспечения для численных расчетов не следует допускать следующие основные ошибки: исчезновение операнда, умножение ошибки и потерю значимости.
Ошибка исчезновения операнда может возникнуть в операциях сложения или вычитания, если один операнд относительно мал по сравнению с другим операндом. Например, при десятичной арифметике с пятью цифрами:
0.1234 x 103 + 0.1234 x 10-4 = 0.1234 x 103
второй операнд будет игнорирован вследствие своей малой величины.
Умножение ошибки – это большая абсолютная ошибка, которая может появиться при использовании арифметики с плавающей точкой, даже если относительная ошибка мала. Обычно это является результатом операции умножения или деления. Рассмотрим вычисление x*x:
0.1234 x 103 * 0.1234 x 103 = 0.1522 x 105
и предположим, что при вычислении x произошла ошибка на единицу младшего разряда, что соответствует абсолютной ошибке 0.1:
0.1235 x 103 * 0.1235 x 103 = 0.1525 x 105
Абсолютная ошибка теперь равна 30, что на порядок превышает исходную ошибку.
Полная потеря значимости – наиболее грубая ошибка, вызванная вычитанием почти равных чисел:
f1 = 0.12342;
f2 = 0.12346;
В математике f2 – f1 = 0.00004, что, конечно, вполне представимо как четырехразрядное число с плавающей точкой: 0.4000x10-4. Однако программа, выполняющая вычисление разности в четырехразрядном представлении с плавающей точкой даст ответ:
0.1235 – 0.1234 = 0.1000 x 10-3
что даже приблизительно не является приемлемым ответом.
Потеря значимости встречается довольно часто, поскольку проверка на равенство реализуется вычитанием и последующим сравнением с нулем. Следующее выражение для вещественных чисел f1 и f2 недопустимо:
если f1 = f2, тогда...
Правильный способ проверки равенства с плавающей точкой состоит в том, чтобы ввести малую величину epsilon:
если |f2 – f1| < epsilon, тогда...
и затем сравнивать с ней абсолютную разницу.
Ошибки в вычислениях с плавающей точкой часто можно уменьшить изменением порядка действий. Поскольку сложение производится слева направо. Например, для четырехразрядного десятичного вычисления:
1234.0 + 0.5678 + 0.5678 = 1234.0
лучше изменить порядок, чтобы не было исчезновения слагаемых:
0.5678 + 0.5678 + 1234.0 = 1235.0
В качестве другого примера рассмотрим арифметическое тождество:
(x + y)*(x – y) = x2 – y2
При вычислении выражения небольшая ошибка, являющаяся результатом сложения и вычитания, значительно возрастает при умножении. При вычислении выражения по формуле x2 – y2 ошибка уменьшается от исчезновения слагаемого, и результат получается более точным.
Указательный тип
Все рассмотренные типы данных имеют одну общую черту. Перед использованием переменная должна быть предварительно описана в разделе переменных. Переменные, определяемые в явных описаниях, называются статическими. Память для таких переменных выделяется при запуске программы (или при входе в структурный блок, в котором описана переменная, например, в подпрограммы) и освобождается при завершении ее работы (или при выходе из блока).
Указательный типданных позволяет использовать динамические переменные, когда выделение и освобождение памяти заданного объема выполняется по явному требованию. Ячейки памяти, относящейся к динамической области, могут неоднократно выделяться и освобождаться по необходимости во время выполнения программы. Выделение и освобождение динамической памяти может быть очень хаотичным.
Указатель (ссылка)– переменная, значением которой является физический адрес некоторой ячейки памяти. Адрес занимает 4 смежных байта памяти (два слова). Поскольку переменные большинства типов данных занимают несколько смежных байтов, то указатель содержит адрес первой ячейки памяти. Необходимость использования указателей при решении прикладных задач с использованием языков высокого уровня существует очень часто.
Во-первых, указатели используются для представления одной и той же области памяти, и, следовательно, одних и тех же физических данных, как данных разной логической структуры. В этом случае вводятся два или более указателей, которые содержат адрес одной и той же области памяти, но имеющих разный тип. Обращаясь к области памяти по тому или иному указателю, можно обработать ее содержимое как данные того или иного типа.
Во-вторых, указатели незаменимы при работе с динамическими структурами данных. Память под такие структуры выделяется в ходе выполнения программы. Стандартные подпрограммы выделения памяти возвращают адрес выделенной области памяти в виде указателя на нее. К содержимому динамически выделенной области памяти можно обращаться только через указатель.
Значением указательного типа (pointer type) является адрес другой переменной или константы. Объект, на который указывает указатель, называют указуемым. Указатели используются для выполнения операций над адресами ячеек (рис. 2.3).
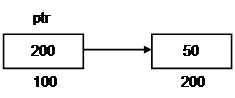 |
Рис. 2.3. Переменная-указатель и указуемая переменная.
В примере указатель ptr является переменной, расположенной в памяти по адресу 100. Содержимое этой ячейки, значение 200, является фактическим адресом переменной, которая содержит значение 50. К переменной можно получить доступ, просто обращаясь к ней по имени, но также можно использовать и разыменование указателя. При выполнении операции разыменования, получают не содержимое переменной указателя ptr, а содержимое ячейки памяти, адрес которой содержится в ptr, т.е. указуемый объект.
Операции над указателями.Указатели могут участвовать в операциях присваивания, получения адреса и выборки.
Операция присваивания – двухместная, оба операнда которой указатели. Операция присваивания копирует значение одного указателя в другой, в результате оба указателя будут содержать один и тот же адрес памяти.
Операция получения адреса – одноместная, ее операнд может иметь любой тип, результатом является типизированный (в соответствии с типом операнда) указатель, содержащий адрес объекта-операнда.
Операция выборки – одноместная, ее операндом является обязательно типизированный указатель, а результат – данные, выбранные из памяти по адресу, заданному операндом. Тип результата определяется типом указателя-операнда.
К указателю можно прибавить или вычесть целое число. Поскольку память имеет линейную структуру, прибавление к адресу числа даст адрес области памяти, смещенной на это число байт (или других единиц измерения) относительно исходного адреса.
Результат операций «указатель + целое» и «указатель – целое» имеет тип «указатель». Можно вычесть один указатель из другого (оба указателя-операнда при этом должны иметь одинаковый тип). Результат такого вычитания будет иметь тип целого числа со знаком. Его значение показывает, на сколько байт (или других единиц измерения) один адрес отстоит от другого.
Сложение указателей не имеет смысла. Поскольку программа оперирует относительными адресами и при разном исполнении может размещаться в разных областях памяти, сумма двух адресов будет давать разные результаты при разном исполнении. Смещение объектов друг относительно друга не зависит от адреса загрузки программы, поэтому результат операции вычитания указателей будет постоянным, и такая операция является допустимой.
Типизированные указатели.При объявлении типизированного указателя всегда должен быть определен тип объекта, адресуемого указателем. При определении типа-указателя используется базовый тип, перед которым ставится признак указателя «^». По соглашению, идентификаторы типа указателя и переменной-указателя начинаются с заглавной буквы P.
Описание типизированного указателя имеет вид:
Type
P = ^t;
где P – идентификатор типа указателя; t – идентификатор (не определение) типа элемента данных, на который ссылается указатель.
Типизированный указатель может быть определен в разделе переменных. Например, следующие объявления:
Var
ipt: ^Byte;
cpt: ^Char;
означают, что переменная ipt представляет адрес области памяти, в которой хранится целое число, а cpt – адрес области памяти, в которой хранится символ.
Физическая структура адреса не зависит от типа и значения данных, хранящихся по этому адресу. Тем не менее, указатели ipt и cpt имеют разный тип, и поэтому оператор присваивания:
cpt:=ipt;
недопустим.
Для типизированных указателей правильнее говорить не о едином типе данных «указатель», а о целом семействе типов: «указатель на целое», «указатель на символ» и т.д. Указатели могут быть определены и на более сложные, интегрированные структуры данных, и указатели на указатели.
Пусть имеется описание:
Type
Tarr = array[1..20] of Real;
Var
Pint: ^Integer;
Parr: ^Tarr;
Для такого описания Pint – переменная, указывающая на элемент целого типа (целое число), а Parr – указатель адреса первого элемента массива вещественных чисел. Сами указатели являются статическими переменными и располагаются в сегменте данных, а элементы, на которые ссылаются указатели, занимают место в динамической памяти (рис. 2.4).
Рассмотрим действия, которые можно выполнять с типизированными указателями. Значение переменной указательного типа можно задать процедурами по работе с динамической памятью, адресным оператором @, или операцией присваивания.
Указатели одного и того же типа можно сравнивать с помощью операций «=» и «<>». Переход от указателя к объекту ссылки производится с помощью операции разыменования, которая обозначается знаком ^, стоящим после имени указателя:
Pint^ – объект (целое число), на который указывает Pint;
Parr^ – массив вещественных чисел, на который ссылается переменная Parr.
|
 20-й элемент массива 20-й элемент массива
|
| . . . |
| 2-й элемент массива |
  1-й элемент массива 1-й элемент массива
|
   Целое число Целое число
|
|
 Pint Pint
|
 Parr Parr
|
Рис. 2.4. Размещение переменной типа Tarr в динамической памяти.
С объектами указателей можно производить действия как с обычными переменными соответствующего типа:
Pint^:=Pint^+3;
Parr^[i]:=0;
Переход от объекта к его адресу осуществляется операцией взятия адреса@ или функцией Addr. Если выполнить присваивания:
Pint:=@X;
или
Pint:=Addr(X);
то будет:
Pint^:=X
Таким образом, операция взятия адреса является обратной к операции разыменования.
Для динамического распределения памяти существуют стандартные процедуры. Процедура New(P) где P – указатель, позволяет выделить область памяти такого размера, в котором можно разместить величину базового типа. Указатель принимает значение адреса выделенной области.
Процедура Dispose(P), позволяет освободить область памяти, на которую указывает указатель P, для последующего использования. После выполнения процедуры значение указателя P становится неопределенным.
Процедура GetMem(P, Size) позволяет выделить в динамической памяти область размером Size байт, при этом адрес выделенной области присваивается переменной P.
Процедура FreeMem(P, Size) освобождает занятую область памяти с адресом, задаваемым оператором P и размером Size байт. После выполнения процедуры область памяти становится свободной, а значение указателя оказывается неопределенным.
Значение одного указателя можно присвоить другому. Указатели, ссылающиеся на объекты разных типов, сами являются разнотипными и для них недопустима операция присваивания.
Рассмотрим несколько типичных приемов работы с указателями. Пусть имеется описание:
Type
PComplex = ^TComplex; { тип-указатель }
TComplex = record { определение базового типа }
Re, Im: Real;
end;
AdrInt = ^Integer; { тип-указатель }
Var
X: TComplex;
P1,P2,P3,P4: PComplex;
Adr: AdrInt;
тогда возможны следующие операции:
New(P1); { выделение памяти для типа TComplex }
New(Adr); { выделение памяти для типа Integer }
P2:=@X; { определение адреса переменной X }
P3:=P1; { присвоение значения другого указателя }
P4:=nil; { присвоение значения nil – «пустая» ссылка, не указывающая
ни на какой объект, «адресный ноль» }
X:=P1^; { переменной X присваивается значение
элемента, на который указывает P1 }
P3^:=X; { элементу, на который указывает P3,
присваивается значение переменной X }
X:=@Y; { X – адрес параметра Y }
После работы с указателями, следует обязательно освободить память, занимаемую теми объектами, на которые они указывают:
Dispose(P1); { освобождение памяти от данных, на которые указывает P1 }
New(Adr);
Нетипизированные указатели.В языке Паскаль существует стандартный тип-указатель Pointer, не связанный с базовым типом. Нетипизированный указатель совместим с любым другим типом-указателем. Переменная типа Pointer содержит адрес объекта неопределенного типа.
Пусть имеются следующие описания:
Var
p1: ^Char;
p2: ^Boolean;
pp: Pointer;
Использование указателей типа Pointer позволяет динамически размещать с одного адреса данные различных типов. Напомним, присваивание значения одного указателя другому возможно только между указателями объектов идентичного типа. В примере символьный и булевый тип занимает одинаковый объем памяти (1 байт), однако следующая запись некорректна:
p1:=p2;
Нетипизированный указатель совместим по присваиванию с указателем любого типа, поэтому присваивание между p1 и p2 можно выполнить опосредованно:
pp:=p2;
p1:=pp;
Работа с нетипизированными указателями существенно ограничена: они могут использоваться только для сохранения адреса, а обращение по адресу, задаваемому таким указателем, невозможно (неприменима операция разыменования). Для этого необходимо привести нетипизированный указатель к конкретному типу (например, через операцию присваивания), а затем применить разыменование.
Контрольные вопросы
1. Перечислите порядковые типы. Опишите общие операции над порядковыми типами.
2. Символьный тип. Как строятся кодовые таблицы?
3. Приведите примеры создания и использования перечисляемого и интервального типа.
4. Назначение и представление логического и битового типа.
5. Перечислите наиболее грубые ошибки численных расчетов.
6. Создание и применение указателей. Виды указателей и операции.
Дата добавления: 2021-12-14; просмотров: 555;
Поиск по сайту
Узнать еще
- III. Механизм действия ионизирующих излучений на биологические структуры
- STEP – стандарт для описания данных об изделии
- АВТОМАТИЗИРОВАННАЯ ОБРАБОТКА ДАННЫХ В СЛУЖБЕ ПРИЕМА И РАЗМЕЩЕНИЯ
- Автоматизированная система технической паспортизации (АСПАД) и создание автоматизированного банка дорожных данных (АБДЦ).
- Автоматизированная система технической паспортизации дорог и создание банка дорожных данных
- АВТОМАТИЗИРОВАННЫЕ БАНКИ ДАННЫХ, ИНФОРМАЦИОННЫЕ БАЗЫ, ИХ ОСОБЕННОСТИ
- Автоматизированные банки дорожных данных.
- Адресация и протоколы данных в сети Интернет.

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
