ОГРАНИЧЕННЫЕ СВЕДЕНИЯ О СТАТИСТИЧЕСКИХ ХАРАКТЕРИСТИКАХ
Рассмотрим теперь случай, когда в соответствии с § 3.1 ограниченные априорные сведения о l заключаются в знании ряда статистических характеристик l (а не полного распределения вероятности), таких, как среднего значения, дисперсии, корреляционной матрицы и т. д., то есть математических ожиданий некоторой совокупности функций l. Класс rо возможных распределений вероятности l в этом случае определен с помощью ограничений (3.1.4), где
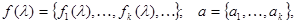 (5.4.1)
(5.4.1)
индекс k пробегает столько значений, сколько задано условий. В остальном же плотность распределения р(l) остается произвольной.
Для отыскания минимаксного правила решения с учетом заданных .ограничений на класс rо возможных распределений вероятности l воспользуемся соотношением (5.1.1) и найдем наименее предпочтительное распределение из этого класса. Тогда байесово правило решения для этого распределения l будет минимаксным. Ограничимся случаем непрерывных множеств l и u.
Пусть u = u0(х,p) - байесово правило решения относительно некоторого априорного распределения l, с плотностью р(l)Îrо, получаемое с помощью обычной процедуры минимизации среднего риска R(u(х),р).Используем для отыскания наименее предпочтительного распределения метод Лагранжа, позволяющий учесть ограничения (3.1.4) на класс допустимых распределений вероятности. При этом плотность наименее предпочтительного распределения р*(l)определяется из условия максимума функционала:
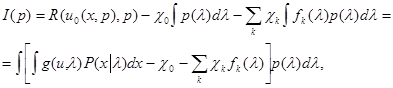 (5.4.2)
(5.4.2)
где u = u0(x,р), а c0, ck - неопределенные множители, выбор которых должен обеспечить выполнение заданных ограничений (3.1.4) на p(l), то есть
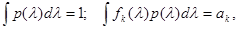 (5.4.3)
(5.4.3)
(ak - заданные значения математических ожиданий функций fk(l)).
Вычислим вариацию функционала I(p) по функции р(l)
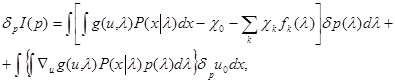 (5.4.4)
(5.4.4)
где dр(l) - вариация функции p(l);dрu0 - вариация решающей функции u0(x,р) по функции p(l), которая, очевидно, не зависит явно от l, а зависит только от х; Ñug(u,l) - градиент функции потерь по решению u. Поскольку в (5.4.2), (5.4.4) u = u0(х, р), то есть является байесовой решающей функцией относительно распределения l с плотностью р(l) и минимизирует средний риск
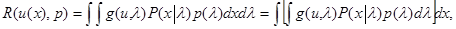
то из условия обеспечения минимума R(u(х),p) для этого решения следует выполнение равенства
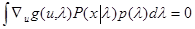 . (5.4.5)
. (5.4.5)
Поэтому второе слагаемое в (5.4.4) обращается в нуль при любой р(l). Из условия обращения в нуль вариации среднего риска (5.4.4) следует уравнение для условного риска
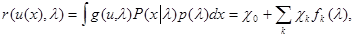 (5.4.6)
(5.4.6)
которое позволяет сформулировать следующее правило нахождения наименее предпочтительного распределения:
- для того чтобы распределение с плотностью вероятности р(l) = р*(l) было наименее предпочтительным в классе распределений rо, удовлетворяющих заданным ограничениям (5.4.3), условный риск для байесова правила решения относительно этого распределения должен иметь функциональную зависимость от l, определяемую выражением (5.4.6).
Это утверждение обобщает требование независимости условного риска от l, вытекающее из теоремы Вальда, при полном отсутствии априорных сведений о l. Последнее является естественным частным случаем (5.4.6), когда ни одной функции fk(l) - не задано и сумма по l в правой части (5.4.6) отсутствует. Конкретный вид наименее предпочтительного распределения (плотности р*(l)) и соответствующего ему минимаксного правила решения зависит от заданных ограничений, а также от вида функции правдоподобия Р(х|l) и функции потерь g(u, l), однако соотношение (5.4.6) позволяет найти р*(l) и минимаксное правило решения для многих важных с практической точки зрения случаев.
Рассмотрим один из таких примеров, когда l={l1, ... ... ln} является n-мерным вектором, решение u = {u1, ... ... un} - его оценкой, и задана корреляционная матрица l
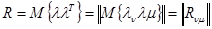 ,
,
а в остальном распределение l неизвестно и может быть произвольным.
При этом f(l) = {lnlm } - совокупность всех произведений ln и lm (n,m=1,…,n), а уравнение (5.4.6) для условного риска принимает вид
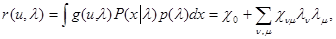 (5.4.7)
(5.4.7)
где множители c0 и cnm (n,m = 1,…,n) определяются из условий
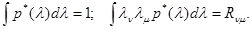 (5.4.8)
(5.4.8)
Таким образом, оценка u = u(x), соответствующая ограниченным априорным знаниям только корреляционной матрицы l, является оптимальной, если она байесова относительно априорного распределения вероятности l, для которого корреляционная матрица равна заданной, а условный риск для этой оценки представляет собой сумму постоянной, величины и квадратичной формы l, вида
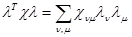 .
.
Покажем, что при некоторых предположениях наименее предпочтительным является нормальное распределение l. Пусть функция потерь квадратичная, то есть
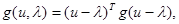 (5.4.9)
(5.4.9)
где g = ||gnm|| - произвольная матрица, и пусть существует достаточная статистика z = z(x), для которой хотя бы приближенно
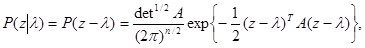 (5.4.10)
(5.4.10)
где А=||Anm||, detA - определитель матрицы А. (При этом без ограничения общности можно полагать М{l} = 0.) Достаточная статистика z(x) является оценкой максимального правдоподобия вектора l, а представление (5.4.10) требует, чтобы она была несмещенной (M{z} = l) и распределена нормально (хотя бы приближенно). Матрица А в (5.4.10) - это так называемая информационная матрица Фишера, которая определяется следующим образом:
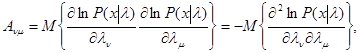 (5.4.11)
(5.4.11)
где математическое ожидание вычисляется при фиксированном l. Она. характеризует рассеяние оценки максимального правдоподобия и потенциально достижимую точность оценивания l в отсутствие всяких априорных сведений о l. Обратная ей матрица А-1 является корреляционной матрицей ошибок для эффективной оценки l, которой при данном представлении Р(z|l) является оценка максимального правдоподобия - достаточная статистика z(x).
Рассмотрим нормальное распределение вероятности l с корреляционной матрицей R и найдем для него байесову оценку. Средний риск в этом случае равен
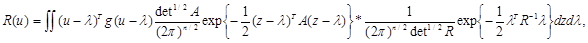 (5.4.12)
(5.4.12)
где R-1 - матрица, обратная R, и в силу того, что z = z(x) является достаточной статистикой и оптимальное решение u = u(x) может зависеть от х только посредством z = z(x), осуществлен переход от полной совокупности данных наблюдения х к достаточной статистике z - оценке максимального правдоподобия вектора l. Минимум среднего риска (5.4.12) достигается, если u является условным (при заданном значении z) математическим ожиданием l, то есть байесово правило решения имеет вид
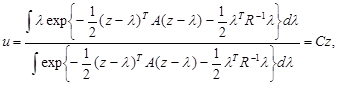 (5.4.13)
(5.4.13)
где матрица C =||Cnm||, определяется уравнением
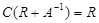 . (5.4.14)
. (5.4.14)
Найдем теперь условный риск для этого правила решения:
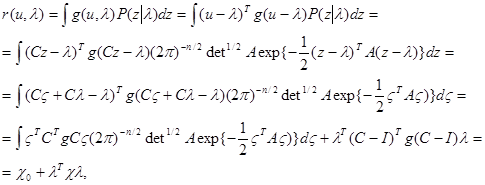 , (5.4.15)
, (5.4.15)
где I - единичная матрица; 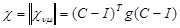 , а
, а 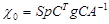 - след матрицы
- след матрицы 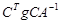 (
( 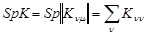 ).
).
Как видно из (5.4.15), условный риск имеет требуемый вид (5.4.7). Это означает, что нормальное распределение вероятности является наименее предпочтительным, а сама оптимальная оценка имеет вид (5.4.13), то есть является линейным преобразованием оценки максимального правдоподобия. Матрица линейного преобразования С зависит от корреляционной матрицы R вектора l и корреляционной матрицы А-1 ошибок для оценки вектора l методом максимального правдоподобия. Минимаксный риск для заданного класса r0 распределений вероятности l имеет следующее значение:
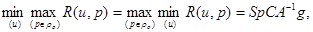 (5.4.16)
(5.4.16)
где SpCA-1g - след матрицы CA-1g, то есть сумма ее диагональных элементов. Он всегда меньше минимаксного риска при полном отсутствии сведений об априорном распределении l, который в условиях справедливости (5.4.10) равен SpCA-1g. Значение риска (5.4.16) для правила решения (5.4.13) достигается, очевидно, также при любом распределении р(l), для которого корреляционная матрица равна R.
Представление функции правдоподобия (5.4.10) заведомо выполняется в том случае, когда х = {x1,..., хn} и xv=ln+xn, a {xn} - совокупность нормальных случайных величин с корреляционной матрицей Rx = А-1, то есть если данные наблюдения х представляют собой аддитивную смесь вектора l с гауссовой помехой x = {x1,..., xn}.
Если при этом известна корреляционная матрица l, то этому случаю соответствует известная постановка задачи линейной фильтрации. Ее винеровское решение имеет вид (5.4.13), (5.4.14), а полученные выше результаты позволяют установить минимаксный смысл этого решения: если никаких других сведений о l, кроме корреляционной матрицы, нет, то никакого лучшего (в смысле квадратичной функции потерь) по сравнению с линейным оператором (5.4.13) оператора фильтрации не существует и только более подробные статистические сведения могут привести к изменению структуры оптимального оператора фильтрации.
Можно проиллюстрировать использование уравнения (5.4.6) для нахождения минимаксных оптимальных оценок еще большим количеством случаев. Например, пусть индекс n для ln и un, имеет смысл дискретного времени и для всех n = 2,…,n заданы средние квадраты изменения за один шаг, то есть
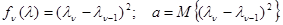 (5.4.17)
(5.4.17)
При переходе к непрерывному времени это будет означать задание среднего квадрата производной процесса l (t) для любого момента времени в интересующем нас интервале.
Уравнение (5.4.6) при этих ограничениях на распределение l принимает вид
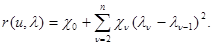
Если задан второй момент для начального значения s21 = M{l21}, то к правой части этого выражения следует прибавить еще один член c1l21. Аналогично рассмотренному выше случаю можно убедиться, что при этих ограничениях наименее предпочтительным является распределение для марковской случайной последовательности l = {l1, ... ln} с переходной плотностью вероятности
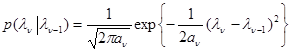 (5.4.18)
(5.4.18)
и с равномерным распределением для начального значения l1, когда величина s21 = M{l21} не задана, либо нормальным распределением вероятности для l1 с дисперсией s21, если последняя задана. В обоих случаях оптимальная минимаксная оценка (оптимальный алгоритм фильтрации) находится без труда с помощью достаточно разработанных для подобных задач методов получения байесовых оценок.
5.5. ЗАМЕЧАНИЯ О ХАРАКТЕРЕ НАИМЕНЕЕ ПРЕДПОЧТИТЕЛЬНОГО РАСПРЕДЕЛЕНИЯ
Во всех предыдущих примерах наименее предпочтительное распределение вероятностей l обладает характерной особенностью - оно является распределением с максимальной для заданного класса r0 энтропией, то есть его плотность р*(l) удовлетворяет соотношению
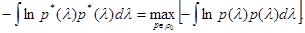 . (5.5.1)
. (5.5.1)
Этим свойствам обладает равномерное для всех значений l распределение при полном незнании статистики l, равномерное на множестве значении L: l = f( 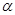 ) - распределение при ограничении допустимых значений l совокупностью гиперповерхностей l = f( ), нормальное распределение при задании только корреляционной матрицы и т. д.
) - распределение при ограничении допустимых значений l совокупностью гиперповерхностей l = f( ), нормальное распределение при задании только корреляционной матрицы и т. д.
Можно высказать гипотезу, что и в других случаях наименее предпочтительным распределением является распределение с максимальной энтропией. Хотя доказать такую гипотезу или установить достаточно общие условия, при которых она справедлива, довольно затруднительно, однако она обладает большой степенью правдоподобия. Поэтому, даже несколько вольное ее использование для более широкого круга задач, в которых прямо найти наименее предпочтительное распределение не удается, представляется довольно конструктивным. Это конструктивное содержание заключается в несравнимо большей простоте решения уравнения (5.5.1) для нахождения распределения с наибольшей энтропией.
Воспользуемся этой гипотезой для нахождения решения одной задачи распознавания образов при полном отсутствии априорной информации, в том числе и в отношении статистического описания данных наблюдения х. Пусть наблюдается некоторая совокупность признаков двух объектов, так что x = {x1, x2}, где x1 - наблюдаемая совокупность признаков первого объекта, х2 - второго. Сами объекты могут быть либо одинаковыми (обозначим это состояние l = 1), либо как-то различаться (l = 2), и на основании данных наблюдения {х1, х2} нужно решить, какое именно состояние имеет место, то есть принять одно из двух возможных решений: u1 - объекты одинаковы, u2 - объекты различны. При этом будем считать, что априорные вероятности состояний
p(l = 1) = Р1 ,
p(l = 2) = Р2 = 1-P1 ,
а также распределения вероятности признаков х (функция правдоподобия) совершенно неизвестны. Несмотря на такую крайнюю степень априорной неопределенности, задача все-таки имеет решение, поскольку она содержит некоторую, правда, весьма нечеткую априорную информацию, скрытую в самой ее постановке, предположение о том, что статистические свойства совокупностей x1 и x2 могут быть либо различными, либо одинаковыми.
Предположим, что все наблюдаемые признаки объектов имеют только дискретные значения. Тогда можно занумеровать эти значения общей нумерацией от единицы до некоторого значения N и без ограничения общности заменить все множество признаков одномерной величиной с возможными целочисленными значениями от 1 до N. Полное статистическое описание этого множества заключалось бы в задании распределения вероятностей этих значений, то есть вероятностей pi (i = l, ..., N), причем если объекты различны (l = 2), то эти вероятности для совокупностей данных x1 и х2 будут иметь разные значения:
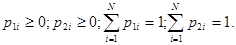 (5.5.2)
(5.5.2)
Если объекты одинаковы, то одинаковы и эти значения
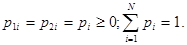 (5.5.3)
(5.5.3)
Пусть далее совокупности данных наблюдения x1 и х2 первого и второго объектов представляют собой n1- и n2-кратные повторения наблюдений признаков этих объектов. Обозначим через n1i и n2i число раз, когда для первого и второго объектов соответственно наблюдалось i-e значение признаков. При этом
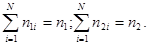 (5.5.4)
(5.5.4)
Совокупности данных наблюдения x1 и х2, очевидно, могут быть описаны совокупностью значений чисел { n1i } и { n2i }, то есть
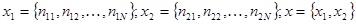 . (5.5.5)
. (5.5.5)
Если вероятности p1i, p2i известны, то эти совокупности описываются мультимиальными распределениями вероятности следующего вида:
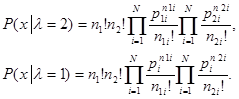 (5.5.6)
(5.5.6)
На самом деле вероятности pi, p1i, p2i (i = l, ..., N), а также априорные вероятности состояний P1 и P2 неизвестны, и для получения решения задачи нужно найти наименее предпочтительные вероятностные меры, определенные на множестве этих неизвестных величин. Совокупность этих вероятностных мер включает: m0(P1, P2) - для априорных вероятностей состояний, которая определена на множестве значений Р1 и P2, удовлетворяющем условию Р1 + P2=1, m0(p1, p2,…, pN) - для вероятностей значений признаков, если объекты одинаковы (эта мера определена на множестве значений p1, p2,…, pN, ограниченном условиями (5.5.3)); m( p11, p12,…, p1N, p21, p22,…, p2N) - для вероятностей значений признаков, если объекты различны (эта мера определена на множестве значений p11, p12,…, p1N, ограниченном условиями (5.5.2)).
Используем для нахождения всех этих мер высказанную выше гипотезу. Из принципа максимума энтропии вытекает равномерность m0, которая после усреднения величины среднего риска с произвольными: значениями Р1 и Р2 приводит к подстановке значений
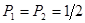 (5.5.7)
(5.5.7)
в выражении для среднего риска. Мера m1 также равномерна на множестве, заданном условиями (5.5.3), что приводит к следующему значению функции правдоподобия для i = l:
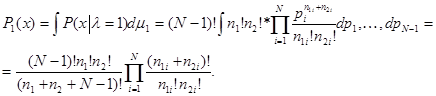 (5.5.8)
(5.5.8)
Мера m2 получается в виде произведения двух мер, одна из которых равномерна на множестве 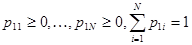 , а другая - на множестве
, а другая - на множестве 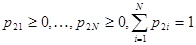 , что приводит к следующему выражению для значения функции правдоподобия при l = 2:
, что приводит к следующему выражению для значения функции правдоподобия при l = 2:
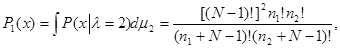 (5.5.9)
(5.5.9)
которое, естественно, не зависит от индивидуальных значений n1i, n2i. Отношение правдоподобия, которое с учетом (5.5.7) для простой функции потерь g(u, l) = g( u = j, l = I) = l - dij при сравнении с порогом, равным единице, дает окончательный вид правила принятия решения об одинаковости объектов, будет иметь значение
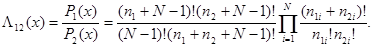 (5.5.10)
(5.5.10)
При изменении функции потерь или задании априорных вероятностей-состояний P1 и Р2, отличных от (5.5.7), изменяется только величина порога С в правиле L12(x) > C принятия решения u1. Вид достаточной статистики L12 (x) =L12 (n11, n12,…, n1N, n21, n22,…, n2N) из (5.5.10) при этом остается неизменным. Таким образом, правило решения u(х) в рассматриваемых условиях полной априорной неопределенности будет иметь следующую структуру:
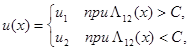 (5.5.11)
(5.5.11)
где L12(x) определяется выражением (5.5.10). (Для исключения некоторой нечеткости вида этого правила, связанной с возможностью получить значение L12(x) = C, можно любое из неравенств в (5.5.11) дополнить равенством или принять при L12(x) = C решение наугад.)
При больших значениях n1i, n2i выражение для отношения правдоподобия (5.5.10) можно заметно упростить, а если еще предположить, что возможные различия между объектами не очень велики (это наиболее трудный для правильного решения случай), то L12 (x) можно представить в виде монотонной функции следующей достаточной статистики:
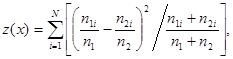 (5.5.12)
(5.5.12)
сравнение которой с порогом и дает требуемое правило решения. Величина z(x) совпадает с величиной c2 для достаточно известного критерия c-квадрат, основанного на среднеквадратичном различии двух выборочных распределений.В данном случае этот критерий получается как асимптотическое приближение (при n1i >> 1, n2i >> 1) решения (5.5.10), (5.5.11), пригодного для любых значений n1i, n2i.
Полученное решение легко обобщается на более сложные задачи распознавания образов со многими альтернативами в условиях полной априорной неопределенности. Пусть, например, имеется не два, а т объектов, которые все могут быть одинаковыми, разными или образовывать некоторое число l групп, каждая из которых содержит 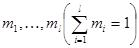 объектов (l = 1 - все объекты одинаковы; 1 = m, все mj = 1 и все объекты различны). Для каждой из таких гипотез подобно (5.5.6) можно без труда записать значение функции правдоподобия этой гипотезы при известных распределениях вероятности наблюдаемых признаков, а затем аналогично (5.5.8), (5.5.9) произвести их усреднение по соответствующим мерам, равномерным на ограниченных множествах значений этих вероятностей. В итоге получаются выражения, подобные (5.5.8), (5.5.9) и содержащие произведения факториалов для сгруппированных соответствующим образом чисел наблюдений каждого значения признака (i = l, ..., N). Совокупность этих выражений и будет являться достаточной статистикой.
объектов (l = 1 - все объекты одинаковы; 1 = m, все mj = 1 и все объекты различны). Для каждой из таких гипотез подобно (5.5.6) можно без труда записать значение функции правдоподобия этой гипотезы при известных распределениях вероятности наблюдаемых признаков, а затем аналогично (5.5.8), (5.5.9) произвести их усреднение по соответствующим мерам, равномерным на ограниченных множествах значений этих вероятностей. В итоге получаются выражения, подобные (5.5.8), (5.5.9) и содержащие произведения факториалов для сгруппированных соответствующим образом чисел наблюдений каждого значения признака (i = l, ..., N). Совокупность этих выражений и будет являться достаточной статистикой.
Дата добавления: 2018-05-10; просмотров: 1196;
Поиск по сайту
Узнать еще
- III. Старение и усталость. Вибрация. Коррозия деталей машин. Краткие сведения по теории трения. Виды трения. Основные требования и определения
- А. ПРЕДВАРИТЕЛЬНЫЕ СВЕДЕНИЯ
- А. Сведения о трубах и сварных фасонных деталях
- Введение в теорию статистических решений
- Введение, общие сведения и классификация самолетов
- Вексель. Начальные сведения об основных положениях вексельного права
- Векторная графика, общие сведения
- Вентилируемые фасады. Общие сведения

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
