Модель Нельсона. Применение последовательного анализа Вальда для снижения количества прогонов программы.
Модель, предложенная Е. Нельсоном, основана на использовании структуры входных данных программы. В простейшем случае набор входных данных Ei, произвольно выбранный из пространства входных данных E, имеет равную априорную вероятность с другими наборами, входящими в E, и это дает оценку вероятности отказа по формуле (13.5).
Если рассмотреть также и случай различных вероятностей 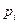 для каждого набора данных, то оценка (13.5) изменится следующим образом.
для каждого набора данных, то оценка (13.5) изменится следующим образом.
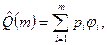
что позволяет записать следующее выражение для вероятности успешного прогона:
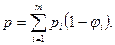 (14.1)
(14.1)
Тогда вероятность успешного выполнения m прогонов, при условии, что набор входных данных для каждого прогона выбирается независимо и в соответствии с распределением, заданным формулой (14.1), будет равна:
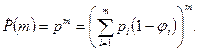 (14.2)
(14.2)
Модель (14.2) позволяет дать следующее определение надежности ПО: надежность ПО – это вероятность его m безотказных прогонов.
Следующим шагом в развитии этой модели будет признать, что, как правило, предположение о том, что выбор входных данных происходит независимо для каждого прогона, на практике неверно. Исключение могут составлять только последовательности прогонов с постепенным увеличением значения входной переменной, или с использованием определенной последовательности процедур (как в системах реального времени).
Принимая во внимание эти обстоятельства, необходимо переопределить распределение (14.1) в терминах вероятностей pij выбора набора данных Ei для j-того прогона программы из некоторой последовательности прогонов. Тогда вероятность отказа на j-том прогоне будет
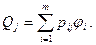
Соответственно, вероятность безотказного выполнения m прогонов можно оценить следующим выражением:
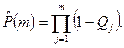
Это выражение можно записать в виде 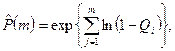
и если Qi<<1, тогда 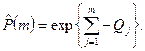
Обозначим 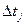 - время выполнения j-того прогона программы, и
- время выполнения j-того прогона программы, и 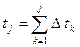 - суммарное время, потраченное на выполнение j прогонов, и будем использовать следующее выражение для функции риска
- суммарное время, потраченное на выполнение j прогонов, и будем использовать следующее выражение для функции риска
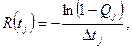
тогда мы имеем
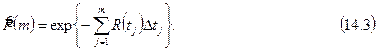
Если 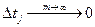 , то сумма превращается в интеграл, и формула (14.3) превращается в фундаментальное отношение (13.2):
, то сумма превращается в интеграл, и формула (14.3) превращается в фундаментальное отношение (13.2):
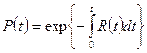
основного правила надежности.
При использовании модели Нельсона на практике встречаются две категории трудностей. Первая связана с нахождением 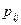 - параметров распределения входных данных. Вторая связана с необходимостью выполнения значительного количества прогонов программы (десятки и сотни тысяч) для получения приемлемой точности для соответствующих оценок вероятности (отказа или безотказной работы). Последняя проблема решается применением хорошо известного в статистике метода последовательного анализа, предложенного Вальдом.
- параметров распределения входных данных. Вторая связана с необходимостью выполнения значительного количества прогонов программы (десятки и сотни тысяч) для получения приемлемой точности для соответствующих оценок вероятности (отказа или безотказной работы). Последняя проблема решается применением хорошо известного в статистике метода последовательного анализа, предложенного Вальдом.
Модель, разработанная специалистами компании IBM.
Во время эксплуатации пользователем текущей версии ПО разработчики, как правило, занимаются активным сопровождением этого программного продукта, то есть вносят некоторые улучшения или исправления в данную версию, не дожидаясь, пока пользователь этого потребует. И это сопровождение может включать в себя также добавление новых функций в ПО. С некоторого момента, когда разработчик считает свою задачу выполненной, начинается, так называемое, пассивное сопровождение, когда исправления вносятся уже только по запросу пользователя.
В течение сопровождения в ПО вносится значительное количество новых ошибок в каждой новой версии, вместе с доработками, изменениями и исправлениями, что требует исправлений также и в следующей версии. Разработчики известной компании IBM попытались предсказать количество подобных исправлений от версии к версии, основываясь на большом количестве экспериментальных данных, собранных в ходе сопровождения операционной системы OS/360. Модель, предложенная специалистами IBM, основана на наблюдении за ходом разработки этого программного продукта, и на гипотезе о статистической стабильности зависимости между параметрами, характеризующими различные версии системы. В качестве основной единицы измерения сложности ПО был выбран программный модуль. Были стандартизованы правила создания модулей.
Объем i-той версии выражается количеством модулей Mi, входящих в данную версию. При выпуске i –той версии системы изменялся параметра СИМi (количества старых исправляемых модулей), и добавление некоторого числа новых модулей НМi , так что 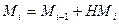 .
.
При доработке i-й версии (в период подготовки (i+1)-й) происходит дальнейшая коррекция модулей. Эти исправленный модули делятся на две группы: первая группа характеризуется параметром MИMi – многократно изменяемые модули (10 или более исправлений на модуль), и вторая группа – ИMi, модули с числом исправлений меньше 10. Эта классификация необходима для упрощения вычислений, а также из-за того факта, что небольшое число исправлений характерно для большинства модулей.
Также необходимо отметить, что группа ИM не требуют особых средств отладки, в то время как группа MИM может потребовать некоторых дополнительных усилий при отладке.
В ходе анализа истории сопровождения OS/360 фирмы IBM было установлено, что существует значительная зависимость между параметрами, характеризующими масштабы изменений и (соответственно) уровень содержания ошибок (в группах ИM и MCM), и параметрами, характеризующими сложность и объем следующей версии (СИМ, НМ). В применении к OS/VS1 это соотношение выглядело следующим образом.
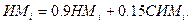 (14.7)
(14.7)
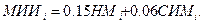 (14.8)
(14.8)
Если предположить, что термины “исправление” и “ошибка” идентичны, то тогда модель для оценивания общего количества ошибок в программе, предложенная специалистами из IBM и основанная на приведенных выше объяснениях, записывается следующим образом:
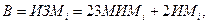 (14.9)
(14.9)
где ИЗМi - общее количество исправлений, внесенное в модули (или, другими словами, общее количество ожидаемых ошибок), а коэффициенты 23 и 2 – среднее количество исправлений на модуль для групп MИM и ИM, соответственно.
Прогноз основывается на запланированном количестве исправлений в старых модулях и на количестве добавляемых модулей (СИМi, НМi) для реализации новых требуемых функций ПО. Если количество действительно внесенных исправлений меньше, чем предсказанное количество исправлений, то можно сделать вывод, что в ПО существует еще некое количество необнаруженных ошибок. Модель фирмы IBM позволяет сделать следующие выводы:
Ø на этапе пассивного сопровождения ПО (ИMi = 0, СИМi невелико) количество исправляемых модулей и количество исправлений внутри модулей быстро убывает от версии к версии;
Ø количество ожидаемых ошибок в следующей версии может увеличится по сравнению с прошлой версией, если достаточно много старых модулей было изменено (СИМ), и/или было добавлено много новых модулей (НМ).
Ø Добавление новых модулей оказывает более сильное влияние на рост числа новых ошибок, чем исправления, вносимые в старые модули; в то же время, если есть возможность создать новый модуль вместо изменения старых модулей (5 или более), то это снижает ожидаемое количество ошибок. Другими словами, на некотором этапе сопровождения ПО изменение уже существующих модулей теряет свою эффективность, и требуется добавление вместо этого нового модуля.
Дата добавления: 2021-09-25; просмотров: 591;
Поиск по сайту
Узнать еще
- Andantino con moto А. Бородин. Для берегов отчизны дальней
- I тип реакций. Реакции, характерные для органических кислот.
- I. 5. Тесты для контроля знаний раздела I
- II раздел. Организация работы логопеда в группе для детей с ОНР
- III. Здания для проживания людей
- III. Тесты для самоконтроля студентов
- III. ТРЕБОВАНИЯ РКФ ДЛЯ ДОПУСКА СОБАК В ПЛЕМЕННОЕ РАЗВЕДЕНИЕ
- IV. Движение поездов при неисправности электрожезловой системы и порядок регулировки количества жезлов в жезловых аппаратах

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
