Модель Шика-Уолвертона.
Эта модель основана на предположении, что функция риска пропорциональна не только количеству ошибок в программе, но и продолжительности процесса тестирования. Кроме того, предполагается, что чем дольше ПО тестируется, тем больше появляется шансов на обнаружение последующих ошибок, поскольку в процессе отладки некоторые участки программы «подчищаются», что облегчает ее дальнейшее тестирование.
Модель основана на следующих предположениях:
- Все ошибки в программе равновероятны и независимы друг от друга.
- Все ошибки считаются одинаково серьезными.
- Исправление ошибок происходит без внесения в программу новых ошибок.
Функция риска для данной модели:
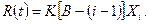
В этой формуле Xi - время между моментом 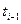 обнаружения (i-1)-й ошибки до текущего момента
обнаружения (i-1)-й ошибки до текущего момента 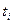 .
.
Вероятность безотказного функционирования программы на интервале Xi равна:
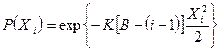 ,
,
что дает плотность вероятности отказа
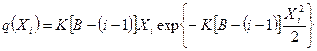
Модели Липова
Эти модели являются обобщением моделей Джелинского-Моранды и Шика-Уолвертона. В отличие от этих моделей, модели Липова допускают более одной ошибки в интервале тестирования, и кроме того, допускают, что не все из ошибок, обнаруженных а этом интервале, могут быть исправлены. Первая модель Липова (обобщение модели Джелинского-Моранды) основана на следующих предположениях:
1. Все ошибки равновероятны и независимы друг от друга.
2. Все ошибки считаются одинаково серьезными.
3. Интенсивность обнаружения ошибок постоянна на всем интервале тестирования.
4. На i-том интервале тестирования обнаруживается 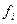 ошибок, но только
ошибок, но только 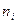 из них исправляется.
из них исправляется.
Последнее предположение значительно отличает данную модель от всех моделей, рассмотренных ранее. Таким образом, функция риска определяется следующим выражением: 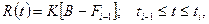 где
где 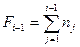 - общее количество ошибок, исправленных к моменту времени , а - это время окончания i-го интервала тестирования (измеренное обычным способом или таймером процессора). Еще одно отличие данной модели от модели Джелинского-Моранды в том, что интервалы фиксированные, а не произвольные.
- общее количество ошибок, исправленных к моменту времени , а - это время окончания i-го интервала тестирования (измеренное обычным способом или таймером процессора). Еще одно отличие данной модели от модели Джелинского-Моранды в том, что интервалы фиксированные, а не произвольные.
Вторая модель Липова (обобщение модели Шика-Уолвертона) основана на следующих предположениях. Интенсивность обнаружения ошибок пропорциональна текущему количеству ошибок в ПО и общему времени, затраченному на его тестирование, включая также «среднее» время поиска ошибки, обнаруженной на интервале тестирования. С учетом этих предположений, функция риска задается следующим выражением:
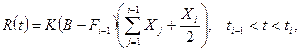 (13.12)
(13.12)
где 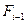 - общее количество ошибок, исправленных к моменту времени
- общее количество ошибок, исправленных к моменту времени 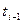 . Формула (13.12) отличается от первой модели Липова вторым множителем -
. Формула (13.12) отличается от первой модели Липова вторым множителем - 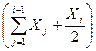 , отражающем изменение интервала тестирования.
, отражающем изменение интервала тестирования.
Геометрические модели
В этом разделе рассмотрен пример геометрической модели, предложенной П. Б. Морандой и являющейся модификацией модели Джелинского-Моранды.
Модель основана на предположении, что начальное количество ошибок в программе B не является фиксированным значением (не ограничено), более того, не все ошибки встречаются с одинаковой вероятностью. Также предполагается, что чем дольше длится процесс отладки ПО, тем труднее становится обнаруживать в нем ошибки, и , таким образом, ПО никогда полностью не освобождается от ошибок. Основные предположения в этой модели следующие:
1. Общее количество ошибок в программе неограниченно;
2. Ошибки встречаются с разной вероятностью;
3. Процесс обнаружения ошибок не зависит от самих ошибок;
4. Интенсивность обнаружения ошибок изменяется по закону геометрической прогрессии, но между моментами обнаружения ошибок интенсивность постоянна.
Исходя из этих предположений, функцию риска можно записать следующим выражением:
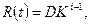
где t – временной интервал между обнаружением (i-1)-ой и i-той ошибок. Начальное значение этой функции R(0) = D, и функция риска убывает со скоростью геометрической прогрессии (0<K<1) по ходу процесса обнаружения ошибок. Скорость изменения R(t) пропорциональна инвертированному значению константы K:
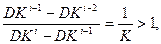
что приводит к убыванию шага изменения R(t) в процессе обнаружения ошибок. Таким образом, более поздние ошибки труднее обнаружить, и они оказывают меньшее влияние на уменьшение потока ошибок, чем предыдущие ошибки. Если снова положить 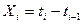 (временной интервал между обнаружением (i-1)-ой и i-той ошибок), тогда, согласно второму и третьему предположению, Xi распределены экспоненциально с плотностью распределения
(временной интервал между обнаружением (i-1)-ой и i-той ошибок), тогда, согласно второму и третьему предположению, Xi распределены экспоненциально с плотностью распределения
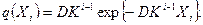
Эта модель не позволяет определить, сколько ошибок осталось в ПО, но с ее помощью можно найти его "уровень чистоты". “Уровень чистоты” - это отношение
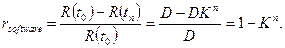 (13.13)
(13.13)
Оценка максимального правдоподобия для этого значения будет 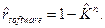
Модель Шнейдевинда
Эта модель основана на подходе, что чем позже встречаются ошибки, тем большее значение они имеют для процесса предсказания ошибок в программе. Предположим, что есть m интервалов тестирования, и пускай на i-том интервале обнаружено ошибок. Тогда возможно три различных подхода:
1. Использовать данные об ошибках на всех интервалах;
2. Не рассматривать данные об ошибках, обнаруженных на первых (s-1) интервалах, и использовать только данные с s-того по m-тый;
3. Использовать суммарное количество ошибок, обнаруженных с первого по (s-1)-ый интервал, т.е. 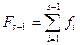 , и отдельные ошибки с s-того по m-тый интервалы.
, и отдельные ошибки с s-того по m-тый интервалы.
Подход 1 предлагается использовать в тех случаях, когда для предсказания будущего состояния ПО необходимы данные со всех интервалов тестирования. Подход 2 – когда есть причины полагать, что произошел некий перелом в процессе обнаружения ошибок, и только данные последних m – (s-1) интервалов имеет смысл учитывать в прогнозах на будущее. И наконец, подход 3 является компромиссом между первыми двумя подходами.
Модель основана на следующих предположениях:
1. Количество ошибок на интервале тестирования не зависит от количества ошибок на остальных интервалах;
2. Количество обнаруженных ошибок убывает от одного интервала к другому;
3. Все интервалы тестирования имеют одинаковую длину;
4. Интенсивность обнаружения ошибок пропорциональна количеству ошибок, содержащихся в программе в текущий момент времени.
Лекция 14. Модели, основанные на методе "посева" и разметки ошибок, и модели на основе учета структуры входных данных
Методы оценки надежности программ, основанные на моделях "посева" и разметки ошибок, рассмотрены на примере трех моделей: Милза, Бейзина и простой эвристической модели. Согласно методике, предложенной Милзом, программа изначально “засевается” известным количеством некоторых ошибок - M. Главное предположение модели в том, что "засеянные" ошибки распределены таким же образом, как и естественные ошибки программы, и, следовательно, вероятность обнаружения для "засеянной" ошибки такая же, как и для естественной. После этого начинается процесс тестирования ПО. Пусть во время тестирования было обнаружено (m+v) ошибок, из которых m ошибок было искусственно "засеяно", а v ошибок содержалось в ПО изначально. Тогда, согласно методу максимального правдоподобия, начальное количество ошибок в программе можно оценить следующим образом: 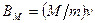 .
.
Серьезным недостатком этой модели является предположение об одинаковости распределения сгенерированных и естественных ошибок, которое невозможно проверить, особенно на более поздних стадиях разработки ПО, когда многие простые ошибки (такие, как синтаксические ошибки, например) уже исправлены, и только наиболее сложные для обнаружения ошибки еще остаются в ПО.
Теперь рассмотрим модель Бейзина. Пусть программный продукт содержит Nk команд. Из этих Nk команд произвольно выбираются n команд, и в каждую из этих n команд заносится ошибка. После этого для тестирования случайным образом выбирается r команд. Если в процессе тестирования было случайным образом обнаружено m “засеянных” и v естественных ошибок, это означает, что, согласно методу максимального правдоподобия, начальное количество ошибок в программе можно оценить следующим образом:
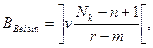 где скобками ][ обозначена целая часть числа.
где скобками ][ обозначена целая часть числа.
При использовании такой процедуры уровень пометки (т.е. среднее количество помеченных команд) должен превышать 20, чтобы полученную оценку можно было считать достаточно объективной. Эти процедуры могут применяться на любой стадии после того, как написание кода программы закончено.
Теперь рассмотрим простую эвристическую модель. Эта модель была предложена Б. Руднером. Она позволяет избавиться от главного недостатка модели Милза. Здесь тестирование производится параллельно, двумя независимыми группами разработчиков ПО.
Пусть 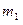 и
и 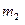 - количество ошибок, обнаруженных, соответственно, первой и второй группами, а
- количество ошибок, обнаруженных, соответственно, первой и второй группами, а 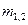 - количество общих ошибок, то есть обнаруженных обеими группами, первой и второй. Начальное количество ошибок, содержащихся в программе, можно оценить, используя гипергеометрическое распределение и метод максимального правдоподобия
- количество общих ошибок, то есть обнаруженных обеими группами, первой и второй. Начальное количество ошибок, содержащихся в программе, можно оценить, используя гипергеометрическое распределение и метод максимального правдоподобия
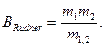
Дата добавления: 2021-09-25; просмотров: 576;
Поиск по сайту
Узнать еще
- IV. Структурно-иерархическая модель личности Реймонда Кеттела
- АВТОРИТАРНАЯ МОДЕЛЬ
- АДАПТИВНАЯ ИНТЕРПРЕТАЦИОННАЯ МОДЕЛЬ ННМ
- Адаптивное управление с авторегрессивной моделью
- Американская модель
- Аналитическая модель производительности дискового зубчатого бункерного загрузочного устройства с кольцевым ориентатором
- Архитектура, управляемая моделью MDA
- Б) Модель сопротивления деформации

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
