Измеримые свойства алгоритмов.
Если задана реализация алгоритма на некотором языке можно идентифицировать все операнды, определенные как переменные или константы, используемые в этой реализации. Аналогично можно идентифицировать все операторы, определенные как символы или комбинации символов, влияющие на значение или на порядок операндов. Исходя из идентификации операторов и операндов, можно определить ряд измеримых категорий, обязательно присутствующих в любой версии любого алгоритма. Они определяются метриками, с помощью которых могут быть получены основные характеристики качества программ.
В состав измеримых свойств любого представления алгоритма (или программы) могут быть включены следующие метрические характеристики:
· h1 - число простых (уникальных) операторов, появляющихся в данной реализации;
· h2 - число простых (уникальных) операндов, появляющихся в данной реализации;
· N1 - общее число всех операторов, появляющихся в данной реализации;
· N2- общее число всех операндов, появляющихся в данной реализации;
· f1j - число вхождений j-го оператора, где j = 1,2,3 ... h1;
· f2j - число вхождений j-го операнда, где j = 1,2,3 ... h2.
Отправляясь от этих основных метрических характеристик для программы, удобно определить:
словарь h h = h1 + h2
и длину N N = N1 + N2
реализации программы.
В соответствии с данными определениями должны выполняться следующие три соотношения
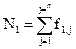
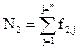

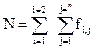
Рассмотрим пример вычисления введенных метрик для программы, реализующей широко известный алгоритм Евклида нахождения наибольшего общего делителя (НОД) двух целых чисел. Возможные варианты программы на языках Паскаль и Си приведены в таблице 1.
Таблица 1
| Программа на Паскале | Программа на Си |
| Function GCD (a,b: integer): integer; Label L1, L2; Var G, R : integer; Begin If (a=0) then L1: begin GCD := b; return end; If (b=0) then Begin GCD := a; return end; L2: G := a/b; R := a - b*G; If (R=0) GOTO L1; a :=b; b:=R; GOTO L2; End. | Int gcd ( int a, int b ) { int G; int R; if (!a) return (b); if(!b) return (a); while(1) { G = a/b; R = a – b*G; If (R) { a = b; b = R; } else return (b); } } |
Результаты подсчета числа типов операторов и операндов и их общего количества сведены в таблицу 2 для программы на Паскале и в таблицу 3 для программы на Си. При подсчете использовались следующие соображения.
В отношении классификации операторов интуитивно ясно, что символы :
:=- знак присваивания;
=- знак равенства (или знак присваивания в программе на Си);
--- знак вычитания;
/ -знак деления;
* - знак умножения
соответствуют их обычному определению.
Пара, состоящая из открывающих и закрывающих скобок ( ), { } классифицируется как один оператор группировки. Поскольку пара слов Begin ... End выполняет такую же группирующую функцию, она классифицируется как такой же оператор. Метки L1 и L2 - не переменные и не константы, поэтому они не являются операндами. Следовательно, они должны быть операторами или их составными частями. Комбинация GO TOи метки L1 определяет ход выполнения программы путем задания для нее счетчика или указателя кода; эта комбинация классифицируется как один оператор. Неиспользуемая метка трактуется всего лишь как комментарий, поэтому ее присутствие в программе необязательно. Ограничитель ;(точка с запятой) также определяет ход выполнения программы (простым продвижением счетчика), что позволяет классифицировать точку с запятой как оператор. По той же причине все управляющие структуры, например IF, IF ... THEN ... ELSE, DO ... WHILE,классифицируются как операторы. Указатель вызова функции или оператор процедуры также являются операторами. Помимо того, возможность задания помеченных участков и введение новых функций устраняют какие-либо ограничения на рост величины h1 (числа типов операторов), которые в противном случае могли бы быть наложены набором команд машины или разработкой языка.
Таблица 2
| Оператор | I | F1i | Операнд | J | F2j |
| ; | GCD | ||||
| := | G | ||||
| = | R | ||||
| () или begin end | A | ||||
| If | B | ||||
| / | |||||
| * | |||||
| - | |||||
| GOTO L1 | |||||
| GOTO L2 | |||||
| Function GCD | |||||
| Return |
Соответственно, измеримые метрики программы на Паскале будут равны
η1 = 12; N1 = 40; η2 = 6; N2 = 21; η = 18; N = N1 + N2 = 61;  58,53
58,53
Таблица 3
| Оператор | I | F1i | Операнд | J | F2j |
| ; | GCD | ||||
| = | G | ||||
| , | R | ||||
| () или {} | A | ||||
| If | B | ||||
| / | |||||
| * | |||||
| - | |||||
| ! | |||||
| Int GCD | |||||
| Return |
Соответственно, измеримые метрики программы на Си будут равны
η1 = 11; N1 = 37; η2 = 6; N2 = 18; η = 17; N = N1 + N2 = 55; 53,56
Длина программы
С использованием рассмотренных программных параметров можно получить уравнение для оценки количественного соотношения между длиной программыN и словарем h. Это уравнение на первый взгляд может показаться несколько неожиданным. Однако тщательный анализ доказывает его правомерность, кроме этого его правильность подтверждается экспериментально.
Строка длины N, образуемая символами, входящими в словарь из hсимволов, должна подчиняться ряду ограничений. Требование, согласно которому каждый символ словаря должен появиться по меньшей мере хотя бы один раз, гарантирует выполнение условия
h £ N,
что определяет нижнюю границу для N, выраженную черезh.
Найдем верхнюю границу для N. Разобьем строку длины N на подстроки длины h. Разделенная таким образом программа для ЭВМ оказывается состоящей из N/h операторов длины h каждый. Теперь если мы потребуем, чтобы строка не содержала двух одинаковых подстрок длины h, то появится искомая верхняя граница.
Требование отсутствия дубликатов подстрок длины h является весьма обоснованным в программах для ЭВМ, в которых экономия выражений приводит к тому, что общему подвыражению дается отдельное имя, поэтому его надо вычислять только один раз. Следовательно, если общее подвыражение длины h необходимо программе более одного раза, присваивание его отдельному операнду увеличит h (число типов операторов) на единицу.
Число возможных комбинаций из h элементов взятых по h за раз, хорошо известно из школьного курса математики и составляет
N £ hh+1
Если учесть, что операторы и операнды, как правило, чередуются, то можно получить другое соотношение
N £ h´h1h1´h2h2
Верхняя граница для этого неравенства должна включать не только упорядоченное множество из N элементов, представляющих исследуемую программу, но и его всевозможные подмножества. Семейство всевозможных подмножеств из N элементов содержит 2N элементов. Следовательно, мы можем приравнять число возможных комбинаций из операторов и операндов (равное числу подстрок N/h) числу подмножеств из N элементов и выразить длину реализации алгоритма через его словарь. Из уравнения
2N = h1h1´h2h2
получаем
N = log2 (h1h1´h2h2)
или
N = log2 h1h1 + log2 h2h2
Это дает нам уравнение оценки длины
h1 log2h1 + h2 log2h2 (2.1)
В этом выражении символ N снабдили Ù для того, чтобы отличать вычисленную (теоретическую) оценку длины от значения N полученного в результате непосредственного измерения (опытной длины). Эта оценка соответствует основным концепциям теории информации, по которым частота использования операторов и операндов в программе пропорциональна двоичному логарифму количества их типов. Выражение (2.1) представляет собой идеализированную аппроксимацию измеренной длины N=N1+N2 , справедливую для программ, не содержащих несовершенств (стилистических ошибок) [1]. Экспериментальные исследования ряда авторов на представительной группе программ показали, что для стилистически корректных программ отклонения в оценке их теоретической длины от опытной не превышают (10-15)% .
Объем программы.
Важной характеристикой программы является ее размер. При переводе алгоритма с одного языка на другой размер программы будет меняться. Изучение этих изменений количественными методами требует, чтобы размер был измеримой величиной.
Кроме того, метрическая характеристика размера должна быть применима к широкому кругу языков без потери общности и объективности и, следовательно, не должна зависеть от набора символов, требуемых для представления алгоритма, то есть символов, практически используемых для записи операторов или имен операндов.
Решение этой проблемы связано с тем, что можно определить абсолютный минимум длины представления самого длинного оператора или имени операнда. Минимальная длина зависит только от числа элементов в словаре h. В общем случае log2 h есть минимальная длина (в битах) всей программы. Под битом здесь понимается логическая единица информации – символ, оператор, операнд – то, чем оперирует программист при создании программы.
Соответствующая метрическая характеристика размера любой реализации какого-либо алгоритма, называемая объемом V, может быть определена как
V = N log2 h (2.2)
где N = N1 + N2 -длина реализации; а h = h1 + h2 - ее словарь.
Очевидно, что если данный алгоритм переводится с одного языка на другой, то его объем меняется. Например, при переводе алгоритма с Паскаля в машинный код какой-либо конкретной машины его объем увеличится. С другой стороны, выражение алгоритма на более развитом языке, нежели тот, на котором он исходно написан, приведет к уменьшению его объема. Последняя возможность чрезвычайно важна и заслуживает специального рассмотрения.
Потенциальный объем V*
Выражение алгоритма в наиболее сжатой форме предполагает существование языка, в котором требуемая операция уже определена или реализована, возможно, в виде процедуры или подпрограммы. Для реализации алгоритма в таком языке требуются лишь имена операндов для его аргументов и результатов.
Обозначив соответствующие программные параметры возможно кратчайшей или наиболее сжатой формы алгоритма звездочками, из уравнения (2.1) получим, что минимальный (или потенциальный ) объем равен
V* = (N1* + N2*) log2(h1* + h2*) (2.3)
Но в минимальной форме ни операторы, ни операнды не требуют повторений, поэтому
N1* = h1* ; N2* = h2*
что дает нам
V* = (h1* + h2*) log2(h1* + h2*)
Кроме того, известно минимально возможное число операторов h1* для любого алгоритма. Каждый алгоритм должен включать один оператор для имени функции или процедуры и один в качестве символа присваивания или группировки, т.е. минимальное значение h1*=2.
Уравнение теперь примет вид:
V* = (2+ h2*) log2( 2+ h2*) , (2.4)
где h2* должно представлять собой число различных входных и выходных параметров.
Из уравнения (3.4) следует, что потенциальный объем V* любого алгоритма не должен зависеть от языка, на котором он может быть выражен. Если h2* расценивается как число единых по смыслу (неизбыточных) операндов, то V* оказывается наиболее полезной мерой содержания алгоритма.
Вернемся к примеру программы для алгоритма Евклида и определим его объем для программ на Паскале и СИ.
Паскаль: V =N * log2 h = 61* log2 18 = 254.4 бита.
СИ: V =N * log2 h = 55* log2 18 = 224.8 бита.
Чтобы найти потенциальный объем, нам нужно подсчитать число требуемых входных и выходных параметров. В данном случае это А, В и GCD, так что h2*=3. Следовательно, потенциальный объем:
V* = (2 +h2*) log2( 2 + h2*) = (2+3) log2(2+3) = 11,6 бита
Как уже упоминалось выше, при переводе алгоритма с одного языка на другой его потенциальный объем V* не меняется, но действительный объем V увеличивается или уменьшается в зависимости от развитости рассматриваемых языков. Однако легко заметить, что не может быть гладкого перехода от выражения на потенциальном языке, для которого V = V* , к любому менее развитому языку, для которого V > V*. Такой резкий переход обусловлен тем, что для потенциального языка N*= h* , в то время как для всех других языков применяется уравнение длины и N > h.
Лекция 3. Уровень программ. Интеллектуальное содержание программы.
1. Уровень программы.
Понятие уровня программы известно с тех пор, как первые «языки высокого уровня» получили свое название. Однако, прежде чем это понятие сможет применяться в науке, оно должно быть выражено количественно или приведено к измеримому виду, так как в противном случае невозможно определить изменения уровня разных выражений какого либо алгоритма.
Прежде, чем вводить метрическую характеристику уровня программы, необходимо заметить, что уровень языка и уровень программы являются разными понятиями, хотя и тесно связанными. Функциональное соотношение между ними и способы измерения уровня языка будут рассмотрены позднее. Сейчас ограничимся измерением уровня отдельных программ. Ранее выведенные выражения для определения объема V программы и потенциального объема V* подсказывают простой метод количественного выражения данного понятия. Если записать уровень L программы, являющейся реализацией какого либо алгоритма, как
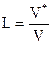 ; (3.1)
; (3.1)
то лишь наиболее сжатое выражение , какое только возможно для алгоритма, будет иметь уровень, равный единице.
Более объемные реализации будут иметь меньшие значения уровня, так что L£1.
Перестроив выражение (3.1) и выделив независящий от реализации член получим
V* = L´V (3.2)
при увеличении объема уровень программы уменьшается, и наоборот.
Обычно легче написать вызов процедуры, чем саму процедуру. С этой точки зрения проще всего было бы использовать потенциальный язык (L = 1). Однако из самого определения потенциального языка следует, что любая процедура, которая когда либо могла бы понадобиться, в нем уже присутствует. Так как число таких процедур бесконечно, процесс простого ознакомления с их списком тоже бесконечен. Поэтому реализация и использование потенциальных языков невозможны для выполнения реальных заданий.
Однако уровень программы играет двойственную роль в определении легкости или трудности ее понимания. Специалист, которому известны все используемые термины, сможет уловить идею тем быстрее, чем выше уровень ее представления. С другой стороны, чтобы сообщить подобную идею лицу, менее сведущему в данной конкретной области, требуется больший объем сведений и меньший уровень.
Дата добавления: 2021-09-25; просмотров: 511;
Поиск по сайту
Узнать еще
- ОСНОВНЫЕ ТИПЫ И СВОЙСТВА НАПОЛЬНЫХ И БОРТОВЫХ СИСТЕМ ТЕХНИЧЕСКОГО ДИАГНОСТИРОВАНИЯ
- I. Товар и его свойства.
- II.3. Физико-химические свойства нефтей и природных газов
- II.4. Классификация нефтей и газов по их химическим и физическим свойствам
- X. Электроповерхностные свойства дисперсных систем
- А) Определяется механическими и тепловыми свойствами
- Абстрактные автоматы. Методы описания и свойства
- Акустические свойства голоса

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
