Метод мониторинга лесов на основе дистанционно-ориентированных выделов (ДОВ). Модель формирования ДОВ.
Текущее состояние тематической обработки дистанционных данных лесов во многом определяется разработкой и валидацией вегетационных индексов. Вегетационный индекс (ВИ) – это показатель, рассчитываемый в результате операций с разными спектральными диапазонами (каналами) и имеющий отношение к параметрам растительности в данном пикселе снимка. Эффективность ВИ определяется особенностями отражения электромагнитных волн. Индексы выведены, главным образом, эмпирически, применяются на каждом конкретном участке с определёнными особенностями. Существует большое число различных ВИ (Таблица 2), многие прикладные программы позволяют создавать удобные для пользователя собственные ВИ (ENVI, ERDAS IMG). Известно более 150 видов различных ВИ, однако из опыта мониторинга лесов центрального региона РФ число ключевых и самых распространенных ВИ сокращается до 5-10.
Основное предположение по использованию ВИ состоит в том, что некоторые математические операции с разными каналами ДЗЗ могут дать полезную информацию о растительности. Это подтверждается множеством опытов. Второе предположение – это идея, что открытая почва на снимке будет формировать в спектральном пространстве прямую линию (почвенную линию). Почти все распространенные вегетационные индексы используют только соотношение красного и ближнего инфракрасного каналов, предполагая, что в ближней инфракрасной области лежит линия открытой почвы. Подразумевается, что эта линия означает нулевое количество растительности.
Большинство вегетационных индексов очень плохо работают для территорий с разреженным растительным покровом, спектр снимка в этом случае в основном зависит от почвы. Почвы могут различаться очень сильно по отражению, даже если для анализа используются очень широкие спектральные диапазоны.
Таблица 2
Основные вегетационные индексы, применяемые на практике при обработке данных ДЗ.
| Вегетационный индекс | Особенности |
| NDVI | Нормализованный относительный индекс растительности. 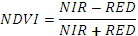
|
| RVI | Относительный ВИ. 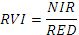
|
| IPVI | Инфракрасный ВИ. 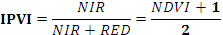
|
| WDVI | Взвешенный разностный ВИ.
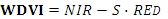 ,
S - наклон почвенной линии ,
S - наклон почвенной линии
|
| SAVI | Почвенный ВИ 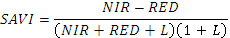 Где L – корректирующий коэффициент
Где L – корректирующий коэффициент
|
| TSAVI | Трансформированный почвенный ВИ
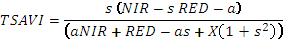 где, a - координата пересечения почвенной линии с осью NIR, S - наклон почвенной линии, ,X - коэффициент коррекции, для уменьшения почвенного шума, (в статье о первоначальном упоминании X=0.08)
где, a - координата пересечения почвенной линии с осью NIR, S - наклон почвенной линии, ,X - коэффициент коррекции, для уменьшения почвенного шума, (в статье о первоначальном упоминании X=0.08)
|
| MSAVI | Модифицированный почвенный ВИ. 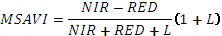 где, L = 1-2·S·NDVI·WDVI
S - наклон почвенной линии.
где, L = 1-2·S·NDVI·WDVI
S - наклон почвенной линии.
|
| MSAVI2 | Модифицированный почвенный ВИ – 2 𝑆𝐴𝑉𝐼= 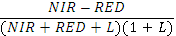 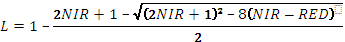
|
| GEMI | Индекс глобального мониторинга окружающей среды.
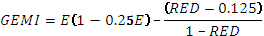
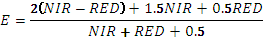
|
| ARVI | ВИ устойчивый к влиянию атмосферы.
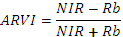 где,
Rb = RED - A·(RED-BLUE).
Как правило, А=1, но при малом покрытии растительности и неизвестном типе атмосферы А=0.5 где,
Rb = RED - A·(RED-BLUE).
Как правило, А=1, но при малом покрытии растительности и неизвестном типе атмосферы А=0.5
|
| SARVI | Почвенный ВИ устойчивый к влиянию атмосферы:
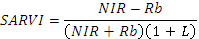
|
| GVI | ВИ зелёности. GVI = -0.29·MSS4 - 0.56·MSS5 + 0.6·MSS6 + 0.49·MSS7 GVI = -0.2848·TM1 - 0.2435·TM2 - 0.5436·TM3 + 0.7243·TM4 + 0.0840·TM5 - 0.1800·TM7 где MSSn – в n канале сенсора MSS, аналогично для сенсора TM. |
| SVI | Спектральный вегетационный индекс. Обобщает спектральный образ растительного полога, характеризуя состояние его зеленой биомассы. |
| SWVI | Индекс вариации влажности почвы. Участвует в детектировании повреждений лесов пожарами по данным SPOT-Vegetation (Барталёв С.А.) |
| EVI | Расширенный вегетационный индекс. Усовершенствованный вариант NDVI, который рассчитывается по формуле: 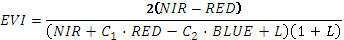 где NIR, RED и BLUE – коэффициенты спектральной яркости в ближней инфракрасной (0,840-0,876 мкм), красной (0,620-0,670 мкм) и голубой (0,459-0,479 мкм) зонах; L – корректирующий коэффициент для учета характера подстилающей растительностью поверхности (
где NIR, RED и BLUE – коэффициенты спектральной яркости в ближней инфракрасной (0,840-0,876 мкм), красной (0,620-0,670 мкм) и голубой (0,459-0,479 мкм) зонах; L – корректирующий коэффициент для учета характера подстилающей растительностью поверхности (  ); С1 ( ); С1 (  ) и С2 ( ) и С2 ( 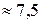 ) – коэффициенты, регулирующие степень использования голубой спектральной зоны в атмосферной коррекции красной спектральной зоны. ) – коэффициенты, регулирующие степень использования голубой спектральной зоны в атмосферной коррекции красной спектральной зоны.
|
| DVI | Разностный ВИ. DVI = NIR – RED |
| PVI | Перпендикулярный ВИ PVI = sin(a)·NIR - cos(a)·RED a - угол между почвенной линией и осью NIR. |
| PRI | Фотохимический индекс отражения Индекс используется при оценке производительности растительности и выявлению стрессового состояния. Применяется для измерения изменений в каратоноидной пигментации (чувствителен к пигменту ксантофил) в живой листве. Каратоноидный пигмент может указывать на фотосинтетическую эффективность света или скорость поглощения углекислого газа листвой на единицу поглощённой энергии.
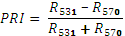 , R - КСЯ соответствующих частот , R - КСЯ соответствующих частот
|
| TVI | Трансформированный ВИ. |
| MTVI | Модифицированный трансформированный индекс. MTVI(m) = 1.5[1.2(Rband5 – Rband2) – 2.5(Rband3 – Rband2)]/ [(2Rband5 + 1)2 – (6Rband5 – 5 Rband3) – 0.5] m –измерение мультиспектральным датчиком RapidEyeTM. |
| MCARI | Модифицированный показатель поглощения хлорофилла. MCARI(m) = [((Rband4 – Rband3) – 0.2) (Rband 4-Rband 2)] (Rband 4/Rband 3) m –измерение мультиспектральным датчиком RapidEyeTM. |
Исходя из основного определения лесного выдела в лесоустроительных работах и учёта методов ДЗЗ, предлагается создание специально адаптированных для космического мониторинга выделов на основе классификации полей значений ВИ лесного участка без участия эксперта в автоматическом режиме. Формирование дистанционно-ориентированных выделов (ДОВ) осуществляется алгоритмами кластеризации на заранее определённом участке леса, который классифицирован методами управляемой классификации с участием эксперта. Учитывая наибольшую популярность и проведя сравнительный анализ преимуществ и недостатков основных алгоритмов кластеризации (PAM, k-means, CURE, MST, Fuzzy C-means, HCM), был выбран алгоритм ISODATA (Iterative Self-Organizing Data Analysis Techniques). Его осуществление подразумевает первоначальное определение некоторого числа параметров при участии эксперта:
1. K – число возможных кластеров;
2. I – максимальное число итераций;
3. QN – пороговый уровень для минимального числа пикселей в каждом кластере (необходимо для отбраковки кластеров);
4. QS – пороговый уровень для среднеквадратического отклонения значений ВИ (необходимо для разделения пикселей);
5. QC – пороговый уровень разницы (расстояния в пространстве значений) между двумя значениями пикселя поля ВИ (необходимо для слияния пикселей).
Алгоритм ISODATA в задаче формирования ДОВ выглядит следующим образом:
Шаг1. Произвольно выбирается k (оно может и не равняться K), инициализируются кластерные центры: m1, m2,… mk из общего набора значений ВИ {xi, i=1, 2,…,N}.
Шаг2: Для каждого из N значений определяются наиболее корректные кластерные центры исходя из того, что:
x 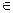 Wj, если DL (x, mj)= min{ DL (x, mi), i=1,…,k},
Wj, если DL (x, mj)= min{ DL (x, mi), i=1,…,k},
где Wj – кластер, DL – разность значений или расстояние в пространстве значений). То есть определяется близость значений к произвольно выбранному кластерному центру.
Шаг 3: Затем отбрасываются кластеры с количеством пикселей меньше QN, т.е. если для какого-то j, Rj< QK, то кластер Wj отбрасывается и k←k-1, где Rj – пиксели в окрестности кластера mj, QK – пороговое число пикселей k-го кластера.
Шаг 4: Выполняется преобразование кластерных центров согласно:
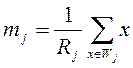 , (j=1,…,k);
, (j=1,…,k);
Шаг 5: Вычисляется среднее расстояние Dj в пространстве значений кластера Wj с полученными кластерными центрами:
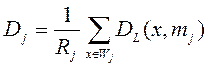 , (j=1,…,k)
, (j=1,…,k)
Шаг 6: Рассчитывается общее среднее расстояние значений по всем кластерам:
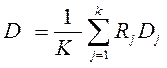
Шаг 7: Проверяется условие: Если k≤K/2 (т.е. слишком мало кластеров), то выполняются операции расщепления полученных кластеров (Шаг 8), а если k≥2K (слишком много кластеров), то операции слияния кластеров (Шаг 9):. В иных случаях проверяется условие порога итераций (Шаг 14) кластеризации, если оно достигает I, то процесс прекращается, иначе всё выполняется заново (Шаг 2).
Шаг 8: Операции расщепления кластеров проходят в несколько этапов:
Формируется вектор значений среднеквадратических отклонений 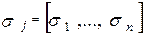 для каждого кластера:
для каждого кластера:
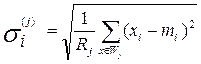 , (i=1,…,n, j=1,…,k),
, (i=1,…,n, j=1,…,k),
где σi – среднеквадратическое отклонение значений в кластере Wj .
Шаг 9: Затем выполняется поиск максимальной компоненты в векторе σj .
Шаг 10: Если для какого-либо σmax выполняется условие:
σmax > QS, Dj > D, Rj > 2QK, то разделяется mj на два новых кластерных центра mj+ и mj- , которые образуются прибавлением ±δ соответствующего значению σmax кластера. Где δ = α σmax, для произвольного α >0. Прежний кластерный центр удаляется и k←k+1. Алгоритм переходит на начальный Шаг 2, иначе на Шаг 14.
Шаг 11: Это первый шаг по слиянию кластеров. Вычисляется попарно расстояние в пространстве значений (разница) Dij между двумя кластерными центрами:
Dij = DL (mi, mj), для всех i ≠j. Сортируется k(k-1)/2 значений Dij в порядке возрастания.
Шаг 12: Определяются не более P наименьших Dij , которые меньше чем Qc и сортируются в порядке возрастания: Di1j1 ≤ Di2j2 ≤ … ≤ Dipjp
Шаг 13: Выполняется попарное объединение кластеров по кластерным центрам с условием о том, что если не 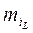 не
не 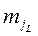 не используются в текущей итерации, то они сливаются в один кластерный центр:
не используются в текущей итерации, то они сливаются в один кластерный центр:
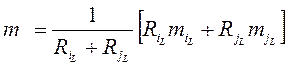 , где L = 1, …, P
, где L = 1, …, P
После чего предыдущие варианты кластерных центров удаляются и k←k-1 и выполняется Шаг 2.
Шаг 14: Процесс завершается, если максимальное число итераций достигнуто I, в ином случае возвращаются к Шагу 2.
Алгоритм ISODATA, реализованный в ENVI, использует поле значений вегетационного индекса, для определения соответствующего кластера (класса) для каждого пикселя. Процесс начинается с назначения случайного (приближенного) среднего значения кластера (mi) и повторяется до тех пор, пока это значение не достигнет величины среднего для каждого кластера исходных данных. Начальные средние значения кластеров распределяются равномерно вдоль центрального вектора пространства значений.
При первой итерации кластеризации поле значений ВИ1 равномерно разбивается на области, центром каждой из которых являются средние значения кластеров (m1,m2, … mn). Пиксели анализируются с левого верхнего угла изображения к нижнему правому. Вычисляется разница между значением пикселя ВИ1 и средним значением кластера. Пиксели назначаются в тот кластер, где разница минимальна (см. Шаг 2). Затем рассчитывают реальные средние значения ВИ1 в полученных кластерах, их средние значения меняются из-за попавших новых пикселей (m’1,m’2, … m’n). Выполняется вторая итерация, в процессе которой повторяют кластеризацию с новыми средними значениями и рассчитывают границы кластеров. После этого определяют новые средние значения и выполняют новую итерацию. В процессе второй итерации снова определяется минимальная разница между значениями ВИ1 пикселя и новыми средними значениями самих кластеров, по окончанию пиксели перераспределяются. Перераспределения выполняются до тех пор, пока все пиксели поля значений ВИ1 с заданной вероятностью (порог сходимости) не попадут в свой кластер. В случае не способности перераспределения пикселя в кластер, алгоритм ограничивается заданным числом итераций I. Окончательно сформированные кластеры поля значений ВИ1 запоминаются для поиска пересечений с кластерами полей значений ВИ2, который формируется аналогично вышеописанной процедуре (рис.2). На этапе кластеризации отдельных ВИ указываются ограничения по минимальному числу пикселей в ДОВ (полученных классах). Следующий этап процесса формирования ДОВ подразумевает ограничение и по максимальному количеству пикселей их образующих, исходя из пространственного разрешения снимка.

Рисунок 2. Этап формирования ДОВ. Пространственное пересечение кластеров ВИ1 и ВИ2.
Формирование ДОВ может быть выполнено после поиска пространственных пересечений большего числа кластеров различных ВИ, однако в этом случае снижается возможность их пересечения для выделения общего участка. Основные этапы формирования ДОВ представлены на рисунке 3. В случае отсутствия пространственных пересечений кластеров, ДОВ формируется на основе приоритетного ВИ, который выбирается экспертом.

Рисунок 3. Основные этапы формирования ДОВ.
К наиболее простым в реализации вегетационным индексам можно отнести NDVI, EVI, ARVI ,IPVI, GEMI. Их расчёт можно осуществить в специализированном программном продукте ENVI. Ниже приведём пример формирования ДОВ на основе одного приоритетного индекса NDVI по спутниковому снимку Landsat ETM+ за июль 2010 года.
Согласно рис.3 первоначально определяется область исследования, т.е. территория леса. Шаг1: Общий снимок подвергается управляемой или неуправляемой классификации с участием эксперта. По полученному классу лесов создаются векторные слои для ограничения от других классов. Выбирается конкретный интересующий лесной массив (Рис.4).

Рисунок 4 Выделенный лесной массив
Шаг 2: Проводится вычисление необходимых вегетационных индексов. В нашем примере ограничимся расчётом наиболее популярного ВИ – NDVI, определяя его как приоритетный (Рис. 5).

Рисунок 5 Поле значений NDVI исследуемого участка леса.
Шаг 3: Выполняется кластеризация полей значений ВИ алгоритмом ISODATA (Рис. 6). При его реализации вводится ряд параметров, которые определяют итоговую картину сформированных ДОВ. На сегодня остаётся открытой задачей поиск оптимального варианта кластеризации и выработка критериев отбора наилучших ДОВ, поэтому в нашем случае этот процесс возложен на участие эксперта.

Рис.6 Кластеризация полей ВИ.
Шаг 4: Так как других ВИ не было, то сразу выполняется процесс векторизации классифицированных участков леса (Рис.7). В итоге, получаем повыделенное разбиение лесного массива, которое ориентировано именно на дистанционный спутниковый мониторинг с учётом однородности значений ВИ.
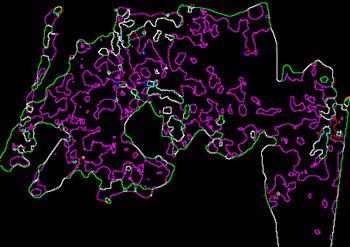
Рисунок 7 Векторный слои ДОВ.
Модель формирования ДОВ встраивается в общий функционал специализированного программного продукта ENVI. Её реализация осуществляется в диалоговом исполнении с минимальным участием пользователя. Основные этапы выполняются в автоматическом режиме. Так как автоматический режим не исключает появления ошибок и браков, поэтому предложенный в настоящий момент вариант модели формирования ДОВ подразумевает тесное участие эксперта. Дальнейшие исследования будут направлены на отладку конкретных этапов алгоритма с минимизацией субъективного воздействия пользователя.
Концепция использования ДОВ может быть полезна при непрерывном многомесячном или многолетнем мониторинге лесов, выявляя количественные изменения значений вегетационных индексов, которые в свою очередь имеют известные регрессионные связи с биологическими параметрами леса. Интересен многолетний контроль изменения непосредственно самих границ ДОВ, сформированных с помощью спутниковых снимков определённой даты годового сезона.
Таким образом, метод мониторинга на основе ДОВ может дать объективную обобщённую информацию о состоянии участка леса и его изменении во времени, упрощая при этом процедуру поиска важных качественных и количественных признаков.
Список литературы
1. Официальный сайт ФГУП «Рослесинфорг». [Электронный ресурс]: Сайт ФГУП «Рослесинфорг». — Электрон. дан. (2 файла). — [Б. м.]. — Режим доступа http://www.roslesinforg.ru/activity/forest , свободный. — Загл. с экрана. — Яз. рус.
2. Журнал Промышленник России №10 (121) 2010
3. Сухих В.И. Аэрокосмические методы в лесном хозяйстве и ландшафтном строительстве: Учебник. – Йошкар-Ола: МарГТУ, 2005. – 392 с.
4. Барталев С.А. Разработка методов оценки состояния и динамики лесов на основе данных спутниковых наблюдений. Автореферат диссертации на соискание ученой степени доктора технических наук. ИКИ РАН, 48 стр. Москва 2007.
5. Данилин И.М., Медведев Е.М, Абэ Н.И., Худак Т., Санит-Онге Б. Высокие технологии ХХI века для аэрокосмического мониторинга и таксации лесов // Лесная таксация и лесоустройство. 2005. №1(34), с. 28-39.
6. Ильючик М.А. Разработка методов оценки текущих изменений в лесном фонде по данным дистанционного зондирования хвойных лесов Беларуси. Автореферат диссертации на соискание учёной степени кандидата сельскохозяйственных наук, БГТУ, 26 стр. Минск, 2004
7. Козодеров В.В. Методы оценки почвенно-растительного покрова по данным оптических систем дистанционного аэрокосмического зондирования // Кондранин Т.В. / Учебное пособие. – М.: МФТИ, 2008. – 222с.
8. Myneni, RB., A.L. Marshak, and Y. V. Knyazikhin, Transport theory for a leaf canopy of finite-dimensional scattering centers, Quant. Spectrosc. Radiat. Transfe, 46, 25 9-280, 1991.
9. Myneni, R.B., J. Ross, and 0. Asrar, A review on the theory of photon transport in leaf canopies in slab geometry, Agric. For. MeteoroL, 45, 1-165, 1989.
10. Shabanov, N.V., Huang, D., Yang, W., Tan, B., Knyazikhin, Y., Myneni, R.B., Ahl, D.E., Gower, S.T., Huete, A., Aragao, L.E., Shimabukuro, Y.E. (2005). Analysis and Optimization of the MODIS LAI and FPAR Algorithm Performance over Broadleaf Forests. IEEE Transactions on Geoscience and Remote Sensing, 43(8): 1855-1865.
11. Патент на изобретение № 2294622, РФ, МПК А01G23/00 Способ определения полноты древостоев / Московский государственный университет леса, РФ, заявка № 2005111787/11 от 21.04.2005
Дата добавления: 2017-01-26; просмотров: 2151;
Поиск по сайту
Узнать еще
- He рекомендуем использовать данный метод, если в дальнейшем будет необходимость прибегнуть к отгибу приборной панели.
- I. История открытия и методы исследования вирусов
- I. Классификация углеводов.
- I. Расчёт методом контурных токов.
- I. Судовождение, основанное только на лоцманском методе.
- II. В сравнении с другими органами управления, функционирующих на профессиональной основе
- II. Категории и методы политологии.
- II. Общие методические принципы в канистерапии

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
