Образование согласных звуков
В отличие от гласных звуков согласные отличаются гораздо большим разнообразием способов звукообразования, что усложняет их анализ и распознавание, и соответственно затрудняет работу звукорежиссеров с речевыми и вокальными сигналами. Однако именно согласные требуют особого внимания при звуковой обработке, поскольку в речи они несут основную смысловую нагрузку.
Во-первых, при образовании согласных могут использоваться все источники звука и их сочетания: фонация, турбулентный шум, импульс.
Во-вторых, месторасположение источника звука также может сильно варьироваться: если при образовании гласных резонаторы всегда находятся впереди источника звука, поскольку положение голосовых связок закреплено в гортани, то при образовании согласных источник звука может находиться в любом месте тракта (например, у зубов для звука "с"; в задней нёбной части для звуков "г", "к" и др.).
В-третьих, при образовании согласных чаще используется подключение дополнительной носовой полости (в русском языке вообще нет носовых гласных, только согласные "м", "н").
Кроме того, они отличаются значительно более короткими стационарными периодами (служат как бы переходом от одной гласной к другой), и значительно большим разнообразием спектров. Средняя длительность гласных звуков 0,15 с, средняя длительность согласных 0,08 с.
При создании согласных звуков процесс образования формантных областей значительно усложняется.
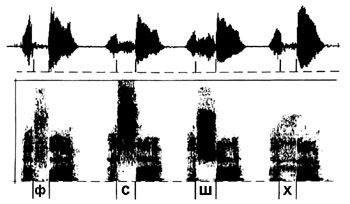
|
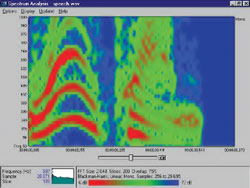
| Рис. 2 Осциллограммы и спектрограммы шума при образовании глухих согласных |
Поскольку источник возбуждения (вибратор) может располагаться в любом месте голосового тракта, то в этом случае резонансные полости располагаются как перед источником, так и позади него.
Резонансы полости перед источником создают пики в выходном сигнале, такие резонансы называются "полюсами" (формантами); резонансы задних полостей называются "нулями" передаточной функции, и проявляются в виде провалов. Модель тракта для согласных "к", "п", "т" и соответствующая передаточная функция тракта показана на рисунке 3. На графике отчетливо видны пики (полюса) и провалы (нули).
Когда нули и полюса находятся близко к друг к другу, происходит их нейтрализация, и на выходной характеристике не видно ни нулей, ни полюсов. В таком случае они называются "связанными".
Для описания процессов образования согласных звуков вводится понятие локусной формантной картины. При образовании гласных звуков передаточная функция тракта, как уже было отмечено выше, полностью зависит от структуры ее формант (F-картины), которые в процессе беглой речи непрерывно изменяются, поскольку непрерывно перестраиваются артикуляционные органы. Эта плавность изменения конфигурации речевого тракта и его резонансных частот имеет место и при произнесении согласных звуков, только эти резонансы не всегда видны в передаточной функции.
Под локусной F-картиной понимается совокупность резонансов (формант) ротовой полости тракта, которая соответствует положению артикуляционных органов при произнесении данного согласного звука. Таким образом, локусы – это те форманты, которые должны быть при данной конфигурации тракта, независимо от того, слышны они или нет. Их положение можно восстановить из спектрограмм сигнала, и оно имеет существенное значение для процессов восприятия согласных.
Артикуляционные возможности речевого тракта при образовании звуков чрезвычайно разнообразны, и могут быть использованы для создания огромного многообразия звуков. Однако для речи используется ограниченный набор звуков (количество фонем в разных языках мира в основном не превышает 50…70). Такой разрыв между возможностями голосового аппарата и его применением объясняется с помощью квантальной теории, в соответствии с которой из всех звуков в речи используются только те, которые создают достаточно четкие слуховые контрасты и легко различимы слуховой системой (т.е. речь была приспособлена к слуху). Например, гласные "и", "у", "а" резко контрастируют на слух, поэтому они используются почти во всех языках мира. Поэтому для разных звуков для речи были отобраны те виды артикуляции, которые создают существенные акустические и слуховые различия.
Рассмотренные выше механизмы звукообразования с учетом квантальных артикуляционно-акустических и слуховых отношений и лежат в основе классификации звуков речи, краткое ознакомление с которой необходимо для анализа акустических характеристик речи и их связи с фонетическими признаками в процессе слухового восприятия и распознавания.
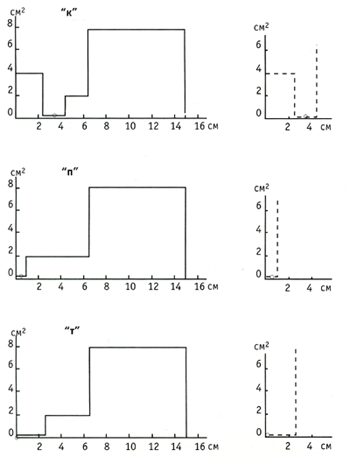
|
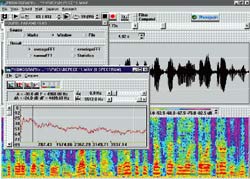
| Рис. 3 Форма голосового тракта и спектры звуков "к", "п", "т" (точкой отмечено место расположения источника шума) |
Классификация звуков речи
В основе классификации всех звуков речи, участвующих в различении слов, лежит классификация Международной фонетической ассоциации (МФА), основанная на артикуляционных признаках. Однако, поскольку все звуки, с одной стороны, представляют собой семиотические знаки, создаваемые органами речи, а, с другой, они представляют собой акустические сигналы, восприятие которых создает сложные слуховые образы, существуют классификации, основанные на акустических признаках. Признаки, используемые в классификации МФА, делятся на группы, в зависимости от того, какой из нижеперечисленных процессов они описывают:
- способы формирования воздушного потока – генерации (инициации);
- способы участия голосовых связок в образовании звука – фонации;
- способы формирования структуры вокального тракта – артикуляции.
Все звуки речи можно разделить на две большие группы: гласные и согласные, существенно отличающихся друг от друга по всем вышеперечисленным признакам.
Поскольку согласные звуки несут основную смысловую нагрузку в тексте речи, а гласные – основную эмоциональную нагрузку, то разное количественное сочетание этих звуков в разных языках определяет различие в избыточности речи, и разные требования к их обработке в каналах звукопередачи и звукозаписи.
 Классификация гласных
Классификация гласных
При образовании гласных звуков всегда используется один способ формирования воздушного потока (генерации или инициации): модуляция потока воздуха за счет колебаний голосовых связок (фонация), поэтому этот признак не может использоваться для их классификации.
В основе классификации гласных лежат другие признаки.
Дополнительная тембровая окраска гласных, которая используется в разговорной и вокальной речи требует сложной вокальной артикуляции с дополнительными движениями, модифицирующими свойства вокального тракта. Наконец, при создании гласных могут использоваться такие признаки как:
- долгота (долгий/короткий) – в русском языке они не несут смыслового различия, а в других языках, например, английском, это существенный различительный признак.
- напряженность (напряженный/ненапряженный) – этот различительный признак также используется в ряде языков. Ненапряженные гласные отличаются меньшей длительностью и интенсивностью, некоторым сдвигом в артикуляции.
Кроме чистых гласных, во многих языках используются сложные гласные, где происходит плавный переход от одного типа артикуляции к другому. Если в этом участвуют два гласных, то такой звук называется дифтонгом. Например, в русском языке: "я" [йа], "ю" [йу]. Существуют сочетания, где используются три звука (трифтонги).
Классификация согласных
Артикуляция согласных звуков связана с созданием препятствия на пути воздушного потока в различных частях голосового тракта. Кроме того, при образовании согласных используются все три типа генерации (инициации) звука: фонация, турбулентный шум и звуковой импульс (взрыв) и их всевозможные сочетания. Поэтому классификация согласных осуществляется по всем трем вышеперечисленным критериям.
По способам генерации
Основной способ создания воздушного потока у большинства согласных – легочный выдыхательный механизм (как и у гласных).
По способам артикуляции
При классификации по этим способам используются следующие основные признаки: способ образования преграды, и место ее образования.
Образование согласных может сопровождаться дополнительными сложными артикуляционными движениями. Например, можно выделить согласные, которые образуются с образованием двойной преграды (их называют иногда двухфокусными) – "ш", "ж"; если эта вторая преграда образуется за счет сближения губ, то такие согласные называются лабиальными, например, английское "w".
Кроме того, имеются согласные с дополнительной артикуляцией, например, широко распространенные в русском языке мягкие согласные "л'", "м'", которые образуются путем наложения дополнительной язычной артикуляции [и]-образного типа; этот процесс называется палатализацией.
Наконец, согласные могут различаться по длительности (долгий/краткий) и степени напряженности артикуляции (сильный/слабый). В русском языке они не несут смыслоразличительных функций.
Кроме того, все согласные, при образовании которых не образуется сильного турбулентного шума, потому что при их образовании имеется дополнительный проход для воздуха, объединяются под названием "сонорные". К их числу относятся носовые согласные ("м", "н"), аппроксиматы ("л", "р") и полугласные "й".
Все вышесказанное относится к отдельным звукам, но в беглой речи имеет место процесс коартикуляции. В процессе артикуляции любого звука имеется три фазы:
- подготовительная (экскурс), когда органы речи начинают устанавливаться в исходную позицию;
- стационарную, когда все органы (язык, губы и др.) находятся в точной позиции, соотвествующей данному звуку;
- рекурсия, когда органы речи начинают перестройку для следующего звука.
Если бы для каждого звука все эти позиции точно выдерживались, как при четком произношении отдельного звука, то речь происходила бы в слишком медленном темпе. При быстрой речи (14…18 звуков в секунду), происходит переслаивание этих фаз между соседними звуками. Этот процесс влияния артикуляции соседних звуков друг на друга называется коартикуляцией. При этом на артикуляционное положение органов речи для данного звука накладываются положения (движения) органов речи, соответствующие последующему звуку.
Эти процессы коартикуляции в беглой речи существенно влияют на акустические характеристики речи и процессы ее слухового распознавания, о чем мы поговорим в следующих статьях.
|

|










