Двоичное кодирование текстовой информации
Начиная с конца 60-х годов, компьютеры все больше стали использоваться для обработки текстовой информации и в настоящее время большая часть персональных компьютеров в мире (и наибольшее время) занято обработкой именно текстовой информации.
Традиционно для кодирования одного символа используется количество информации, равное 1 байту, то есть / = 1 байт = 8 битов.
Если рассматривать символы как возможные события, то по формуле (2.1) можно вычислить, какое количество различных символов можно закодировать:
Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и строчные буквы русского и латинского алфавита, цифры, знаки, графические символы и пр.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертаниям, а компьютер — по их кодам.
При вводе в компьютер текстовой информации происходит ее двоичное кодирование, изображение символа преобразуется в его двоичный код. Пользователь нажимает на клавиатуре клавишу с символом, и в компьютер поступает определенная последовательность из восьми электрических импульсов (двоичный код символа). Код символа хранится в оперативной памяти компьютера, где занимает один байт.
В процессе вывода символа на экран компьютера производится обратный процесс — декодирование, то есть преобразование кода символа в его изображение.
Важно, что присвоение символу конкретного кода — это вопрос соглашения, которое фиксируется в кодовой таблице. Первые 33 кода (с 0 по 32) соответствуют не символам, а операциям (перевод строки, ввод пробела и так далее).
Коды с 33 по 127 являются интернациональными и соответствуют символам латинского алфавита, цифрам, знакам арифметических операций и знакам препинания.
Коды с 128 по 255 являются национальными, то есть в национальных кодировках одному и тому же коду соответствуют различные символы. К сожалению, в настоящее время существуют пять различных кодовых таблиц для русских букв (КОИ8, СР1251, СР866, Мае, 18О — табл. 2.3), поэтому тексты, созданные в одной кодировке, не будут правильно отображаться в другой.
В настоящее время широкое распространение получил новый международный стандарт Unicode, который отводит на каждый символ не один байт, а два, поэтому с его помощью можно закодировать не 256 символов, а. N = 216 — = 65536 различных символов.
Таблица 2.3. Кодировки символов
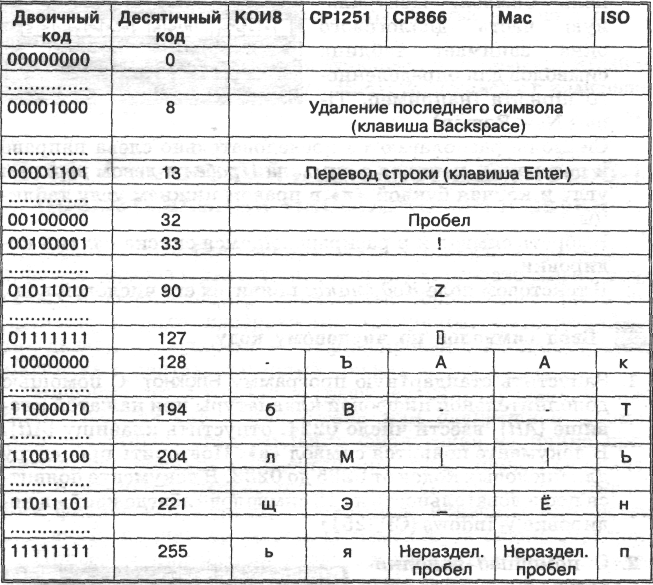
| Каждая кодировка задается своей собственной кодовой таблицей. Как видно из табл. 2.3, одному и тому же двоичному коду в различных кодировках поставлены в соответствие различные символы. Например, последовательность числовых кодов 221, 194, 204 в кодировке СР1251 образует слово «ЭВМ», тогда как в других кодировках это будет бессмысленный набор символов. К счастью, в большинстве случаев пользователь не должен заботиться о перекодировках текстовых документов, так как это делают специальные программы-конверторы, встроенные в приложения. |
Дата добавления: 2016-05-31; просмотров: 2203;
Поиск по сайту
Узнать еще
- Автоматическая локомотивная сигнализация непрерывного действия с числовым кодированием (АЛСН)
- Адекватность информации
- Адресация информации на диске
- Актуальность информации
- Алфавитное кодирование, порядок его применения.
- Аналитический сигнал как источник информации о качественном и количественном составе вещества. Классификация методов химического анализа по характеру аналитического сигнала.
- Аппаратные средства хранения и обработки информации
- Аппаратура и способы активной защиты помещений от утечки речевой информации

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
