Постреляционная модель
Классическая реляционная модель предполагает неделимость данных, хранящихся в полях записей таблиц. Существует ряд случаев, когда это ограничение мешает эффективной реализации приложений.
Постреляционная модель данных представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных, хранящихся в ячейках таблицы. Поскольку атомарность данных постулируется первой нормальной формой, то исходя из этого определения, ее называют также непервой нормальной формой (Non-First Normal Form - NFNF или NF2) реляционной моделью. Постреляционная модель данных допускает многозначные и составные поля. Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу. Вследствие этого ее еще часто называют вложенной (Nested) реляционной моделью. Все атрибуты в постреляционной модели рассматриваются как составные, имеющие иерархическую структуру, причем на количество ветвей не накладывается каких либо ограничений. Это позволяет на одном уровне иерархии хранить целые массивы данных.
| ID | Имя | Адрес | Тел | |||||||
| Фамилия | Имя | Отчество | Страна | Город | Доп. адрес | Номер | Тип | |||
| Улица | Д. | Кв. | ||||||||
| Сидоров | Петр | Петрович | Беларусь | Минск | Пушкина | Дом. | ||||
| Толстого | Раб. | |||||||||
| (029)6257533 | Моб. | |||||||||
| Иванов | Иван | Иванович | Беларусь | Гродно | Ленина | Дом. | ||||
| Литва | Вильнюс | Лесная | Дом. |
По сравнению с реляционной в постреляционной модели данные хранятся более эффективно, а при обработке не требуется выполнять операцию соединения данных из двух и более таблиц. Помимо обеспечения вложенности полей постреляционная модель поддерживает ассоциированные многозначные поля (множественные группы). Совокупность ассоциированных полей называется ассоциацией. При этом в некоторой строке первое значение одного столбца ассоциации соответствует первым значениям всех остальных столбцов ассоциации. Аналогичным образом связаны все вторые значения столбцов и т. д. На длину полей и количество полей в записях таблицы не накладывается требование постоянства. Это означает, что структура данных и таблиц имеет большую гибкость. Но поскольку постреляционная модель допускает хранение в таблицах ненормализованных данных, возникает проблема обеспечения целостности и непротиворечивости данных. Эта проблема решается с помощью процедур, автоматически выполняемых до или после обращения к данным.
Достоинством постреляционной модели является возможность представления совокупности связанных реляционных таблиц одной постреляционной таблицей. Это обеспечивает высокую наглядность представления информации и повышение эффективности ее обработки. Недостатком постреляционной модели является сложность решения проблемы обеспечения целостности и непротиворечивости хранимых данных. Эта модель пока не реализована в полном объеме в коммерческих СУБД. Примером использования некоторых концепций этой модели может служить система Oracle 8. В этой СУБД реализована поддержка составных и многозначных атрибутов, а также вложенных таблиц (Nested Tables). Для хранения составных атрибутов в Oracle 8 используется тип данных OBJECT. Например:
CREATE TYPE Tel_Type AS OBJECT(Tel_Number CHAR(10), Tel_Descr CHAR(5));
Для хранения многозначных атрибутов используется тип данных VARRAY, представляющий собой массив некоторых объектов переменной длины, имеющий два свойства: (1) Count – число элементов в массиве и (2) Limit – максимальное число элементов в массиве (задается при определении этого типа). Для формирования массива объектов вначале требуется определить тип объектов, которые будут храниться в массиве, например:
CREATE TYPE Tel_Type AS OBJECT(Tel_Number CHAR(10), Tel_Descr CHAR(5));
CREATE TYPE Tel_List_Type AS VARRAY(5) OF Tel_Type;
Этот же набор данных можно определить и как вложенную таблицу (Nested Tables).
CREATE TYPE Tel_List_Type AS TABLE OF Tel_Type;
Оба объекта VARRAY и TABLE имеют похожие свойства, но имеют и существенные различия. Во первых, тип VARRAY имеет верхний предел число элементов, а TABLE – не имеет. Во вторых, во вложенных таблицах можно обращаться к отдельным ее элементам и дополнительно определять индексы, что не допустимо в VARRAY.
Многомерная модель
Многомерный подход к представлению данных в базе появился практически одновременно с реляционным, но реально работающих многомерных СУБД (МСУБД) до настоящего времени было очень мало. С середины 90-х годов с развитием систем OLAP (On Line Analytical Processing — оперативная аналитическая обработка данных), Data Warehousing и Data Mining (применяющихся для сложного анализа данных, принятия решений, менеджмента и получения новых знаний) интерес к ним стал приобретать массовый характер. Основное назначение OLAP систем заключается в динамическом синтезе, анализе и консолидации больших объемов многомерных данных, а это, в свою очередь, связано с необходимостью извлекать большое количество записей из больших БД и производить их оперативную обработку (например, быстро вычислять итоговые значения). Кратко определить Data Warehousing можно как предметно (проблемно) ориентированную, интегрированную, постоянную в структуре, но зависящую от времени совокупность данных, предназначенных для принятия некоторых решений. Главное ее отличие от стандартных баз данных состоит в том, что она представляется собранием данных из многих баз данных, объединенных вместе для решения какой-либо частной задачи, либо является построенной по определенным правилам выборкой из очень большой базы данных. Существенным ее отличием можно считать также отсутствие операций обновления данных.
Data Mining (добыча данных) также является системой, основанной на данных, главная задача которой состоит в исследовании данных с целью получения новых знаний. Эта система применяется преимущественно не для выборки данных и представления их в определенной форме, а для сложного анализа данных, как например, поиск цепочек ДНК и т. д. Data Mining преследует следующие цели:
предсказание (например, прогноз погоды, устойчивость развития экономики);
идентификация (по образцу, …);
классификация;
оптимизация (создание более оптимально действующих систем на основе анализа уже существующих).
Многомерные СУБД являются узкоспециализированными СУБД, предназначенными для интерактивной аналитической обработки информации. Многомерность модели данных в них означает не многомерность визуализации цифровых данных, а многомерное логическое представление структуры информации при описании и в операциях манипулирования данными. При этом зачастую создается только многомерное логическое представление данных, а не их хранение. То есть сами данные могут храниться в больших БД, например, реляционных, а в требуемый момент времени извлекаться оттуда. Обычно в этом случае доступ производится с помощью многомерных индексов. Поскольку многомерные модели предназначены в основном для аналитической обработки данных, а не для создания удобных хранилищ информации, основные задачи в них реализуются операциями консолидации, выполняющие расчет всех промежуточных и основных итоговых значений, причем по всем размерностям. Это позволяет в много раз уменьшить объем представляемой информации и значительно ускорить доступ к данным и их последующую обработку. Такое предварительное обобщение является особенно ценным при работе с иерархически связанной информацией, например, при работе с данными, зависящими от времени.
По сравнению с реляционной моделью многомерная модель данных обладает более высокой скоростью доступа к данным, наглядностью и информативностью. Для сравнения ниже приведены реляционное (таблица 1) и многомерное (таблица 2) представления одних и тех же данных о продаже товаров:
Таблица 1. Реляционное представление данных
| Клиент | Товар | Цена | Количество | Дата |
| Иванов | Масло | 1000,00 | 02.02.2005 | |
| Петров | Молоко | 400,00 | 02.02.2005 | |
| Иванов | Сметана | 750,00 | 06.02.2005 | |
| Иванов | Масло | 1000,00 | 22.02.2005 | |
| Петров | Молоко | 400,00 | 03.03.2005 | |
| Сидоров | Масло | 1000,00 | 02.03.2005 | |
| Иванов | Сметана | 1500,00 | 12.03.2005 | |
| Иванов | Молоко | 500,00 | 05.04.2005 | |
| Сидоров | Сметана | 800,00 | 14.04.2005 | |
| Петров | Масло | 1200,00 | 28.04.2005 |
Таблица 2. Многомерное представление данных
| Дата Товар | Июнь 2005 | Июль 2005 | Август 2005 |
| Масло | |||
| Молоко | |||
| Сметана |
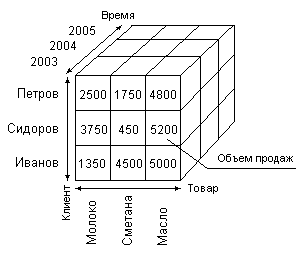
Рис. 2.13. Пример трехмерной модели таблиц, вычисляются по заранее заданным формулам)
Консолидация включает в себя простые обобщающие операции типа расчета итоговых значений, матричную арифметику, а также расчет сложных выражений;
Срез (Slice) представляет собой подмножество гиперкуба, полученное в результате фиксации одного или нескольких размерностей. Формирование среза выполняется, если размерностей всего две (таблица 2), то такое представление называется перекрестной или сводной таблицей. Объем продаж вычисляется на основе группированного представления продаж по товарам, клиентам и месяцам. На Рис. 2.13 показан пример трехмерной модели данных, где введена еще одна размерность Клиент. Если число размерностей велико, то информация не обязательно должна представляться визуально в виде каких-то многомерных объектов (n-мерных гиперкубов), тем более, что это не представляется возможным. Пользователь привык иметь дело с двумерными таблицами, диаграммами, графиками. Многомерная модель как раз предоставляет расширенный набор средств для выборки данных из многомерного хранилища данных, выполненных с разной степенью детализации.
Основными понятиями многомерных моделей являются измерение и ячейка, а операциями – консолидация, формирование среза, вращение, агрегация и детализация:
Размерность (Dimension) – это множество однотипных данных, образующих одну из граней гиперкуба. В многомерной модели данных размерности играют роль индексов, служащих для идентификации конкретных значений в ячейках гиперкуба;
Ячейка (Cell) или показатель – это поле, значение которого однозначно определяется фиксированным набором размерности. В зависимости от того, как формируются значения некоторой ячейки, обычно она может быть переменной (значения изменяются и могут быть загружены из внешнего источника данных или сформированы программно) либо формулой (значения, подобно формульным ячейкам электронных для ограничения выборки данных, поскольку все значения гиперкуба очень трудно представить визуально.
Вращение (Rotate) заключается в изменении порядка измерений при визуальном представлении данных.
Агрегация (Drill Up) и Детализация (Drill Down) означают соответственно переход к более общему и к более детальному представлению информации пользователю из гиперкуба. Например, в БД хранится информация о дате продажи товара. Тогда с помощью операции детализации можно уточнить момент продажи, а с помощью операции агрегации представить суммарную информацию по месяцам, кварталам и годам. Основным достоинством многомерной модели данных является удобство и эффективность аналитической обработки больших объемов данных, связанных со временем. При организации обработки аналогичных данных на основе реляционной модели происходит нелинейный рост трудоемкости операций в зависимости от размерности БД и существенное увеличение затрат оперативной памяти на индексацию. Недостатком многомерной модели данных является ее громоздкость для простейших задач обычной оперативной обработки информации.
Примерами систем, поддерживающими многомерные модели данных, являются Essbase (Arbor Software), Media Multi-matrix (Speedware), Oracle Express Server (Oracle), Cache (Inter Systems). В последней СУБД, основанной на многомерной модели данных, реализованы три способа доступа к данным: прямой (на уровне узлов многомерных массивов), объектный и реляционный.
Дата добавления: 2016-10-26; просмотров: 3819;
Поиск по сайту
Узнать еще
- Автоматна модель шифратору
- Автомодельного ламинарного течения жидкости в трубе с использованием системы дифференциальных уравнений, описывающих течение жидкости в трубе
- Адаптационная модель К. Рой
- Аддитивная цветовая модель
- АНАЛИЗ СОВОКУПНОГО СПРОСА И СОВОКУПНОГО ПРЕДЛОЖЕНИЯ. МОДЕЛЬ «AD-AS»
- Аналитическая модель решения задачи
- Багатосегментна модель
- База данных и модель представления данных

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
