Системы адресации кэш-памяти
При обращении к оперативной памяти процессор указывает в качестве критерия поиска адрес данных в оперативной памяти. Контроллеру кэш-памяти при перехвате обращения к оперативной памяти этот адрес становится доступным. При первом обращении к конкретному слову данных, контроллер кэш-памяти его не обнаружит. Это кэш-промах. В этом случае запрос процессора обслужит оперативная память, но выбрано будет не одно заданное двойное слово, а вся строчка, например, четыре двойных слова, причем, в целочисленных границах строки. Вся строка будет записана в кэш-памяти, а затребованное двойное слово будет отправлено в процессор.
Здесь встает проблема адресации ячеек строк данных в кэш-памяти. Адресация строк данных в кэш-памяти должна допускать нахождение данных по адресам двойных слов (тегов) в оперативной памяти.
В настоящее время широко известны три схемы адресации, удовлетворяющие этому требованию. Это системы адресации на основе:
· аппаратной ассоциативной выборки,
· адресации с прямым отображением адресов,
· множественно-ассоциативной выборки.
Рассмотрим эти схемы применительно к процессору с параметрами МП Intel 486:
· ширина обработки данных – 4 байта,
· размер адресного пространства – 4 Гбайта,
· размер строки кэш-памяти – 128 байт,
· размер адресного пространства кэш-памяти – 8 Кбайт.
Для упрощения схемы, добавим требование расположения слов в ячейках памяти только в целочисленных границах и передачи данных из кэш-памяти в процессор только двойными словами. В этом случае для задания адреса двойного слова используются 30 бит.
Последнее требование упрощает схему, но не соответствует большинству реальных схем. В МП Intel 486 это требование не соблюдается и адреса данных по интерфейсу передаются с использованием 34х бит. 30 бит определяют адрес двойного слова, 4 бита (сигналы #BE0, #BE1, #BE2и #BE3)используются для индивидуального указания позиций передаваемых байтов.
Организация кэш-памяти на основе ассоциативной выборки.Упрощенная функциональная схема кэш-памяти на основе аппаратной ассоциативной выборки информации представлена на рис. 7.6.
В ядро кэш-памяти входят:
· ассоциативная память тегов со схемами параллельного сравнения входного слова (адреса данных в оперативной памяти) с тегами,
· схемы обнаружения кэш-промаха,
· регистры хранения строк данных,
· регистр команд обращения процессора к оперативной памяти,
· дешифратор адреса двойного слова в строке кэш-памяти,
· входные/выходные усилители и вентильные схемы.
При включении процессора строки адресных тегов и данных не заполнены. При первом же обращении процессора к памяти, например по чтению, контроллер кэш-памяти проверяет присутствие запрашиваемых данных в кэш-памяти. Для этого адрес строки оперативной памяти (старшие 24 бита адреса данных в оперативной памяти) сравнивается со всеми адресами строк, записанными в памяти в качестве тегов поиска. Если совпадений нет, то:
· фиксируется кэш-промах,
· производится обращение к оперативной памяти,
· читается и записывается в схемы хранения строк данных вся строчка (8 байт), по любому свободному адресу, а адрес строки – в соответствующую ячейку поисковой части ассоциативной памяти,
· запрашиваемые данные (слово или двойное слово) пересылаются в процессор,
· дополнительная информация (например, биты присутствия, модификации операцией записи и т.д.).
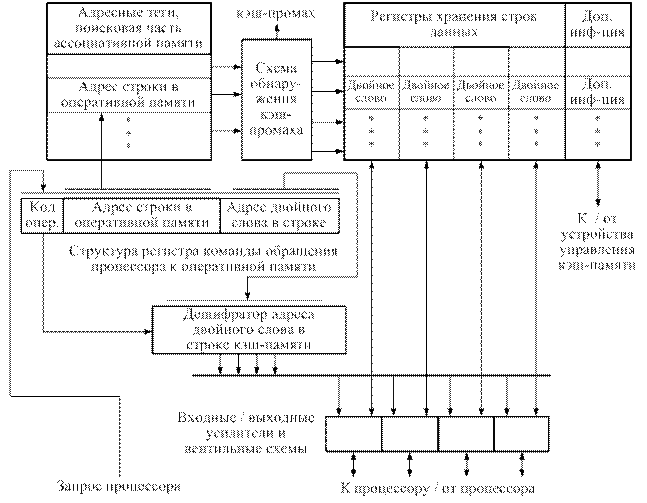 Рис. 7.6. Упрощенная схема работы кэш-памяти на основе
Рис. 7.6. Упрощенная схема работы кэш-памяти на основе
ассоциативной памяти
Повторное обращение к данным из этой же строчки производится уже без обращения к оперативной памяти.
Первоначальное заполнение памяти при промахах может производиться в любом порядке. При полном заполнении кэш-памяти, новые строчки данных, как и при использовании виртуальной памяти, записываются с использованием алгоритмов листания. Для реализации алгоритмов листания каждая строка данных имеет поле дополнительной информации, в котором отмечаются обращения и типы обращения (по чтению или по записи).
Основным недостатком ассоциативной памяти является сложность её реализации на микросхемах из-за сложной топологии поисковой части, вернее, наличия многочисленных вертикальных (адресных) и горизонтальных (разрядных) линий. В интегральном исполнении памяти каждой линии должен соответствовать выводной штырек (ножка микросхемы). Для соединения штырька с линиями микросхемы требуется отдельная "пайка", которая занимает много места на кристалле. При использовании микросхем малой степени интеграции, на саму схему ассоциативной памяти не хватает площади кристалла. Ассоциативная память широко использовалась до появления интегральной технологии.
В современных ЭВМ кэш-память размещают на одной микросхеме с процессором, в этом случае количество выводов микросхемы определяется не кэш-памятью, а интерфейсом процессора. Но и в этом случае использование чисто ассоциативной памяти ограничено.
Организация кэш-памяти с прямым отображением адресов.Основная идея кэш-памяти с прямым отображением – это нахождение функциональной зависимости адресов кэш-памяти от адресов оперативной памяти:
Адрес кэш-памяти = f (адрес оперативной памяти).
Но такой детерминированной функции для не равновеликих множеств не существует. На практике используют вероятностные функции – хеш-функции. Это функции (вернее класс функции) равномерного разбрасывания. Их часто используют для формирования псевдослучайных чисел с равномерным распределением. Используя свойство локальности обращений программ к памяти по времени, в качестве хеш-функции используют функцию прямого отображения.
Функция прямого отображения заключается в выделении младших разрядов аргумента. Количество выделяемых разрядов определяется емкостью кэш-памяти, вернее, количеством строк в кэш-памяти. Для рассматриваемого случая:
· емкость кэш-памяти – 8 Кбайт (215 байт),
· разрядность строки кэш-памяти – 128 Кбайт(27 байт),
· количество строк кэш-памяти – 256.
Упрощенная схема кэш-памяти с прямым отображением адресов представлена на рис. 7.7.
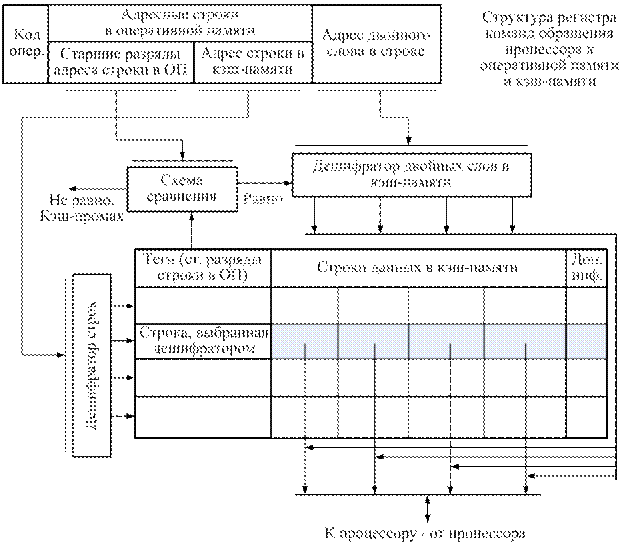
Рис. 7.7. Упрощенная схема работы кэш-памяти
с прямым отображением адресов.
Для сохранения каждой строки оперативной памяти определена единственная строка кэш-памяти. Это строка, адрес которой совпадает с адресом, составленным из старших цифр адреса этой строки в оперативной памяти.
Но по этим же адресам могут быть записаны данные из множества строк оперативной памяти, адреса которых различаются младшими разрядами. При максимально возможной емкости оперативной памяти (равной математической)
количество совпадающих строк может быть равным 217.
Для идентификации строк в старшие разряды строк кэш-памяти записываются "идентифицирующие" теги, равные (по численному значению) старшим разрядам адреса оперативной памяти.
При обращении к кэш-памяти старшие разряды адреса строк оперативной памяти сравниваются с тегами на внешних схемах сравнения. При несовпадении этих строк фиксируется кэш-промах, при совпадении – фиксируется попадание. При кэш-попадании данные (двойное слово) выбираются из кэш-памяти по адресу двойных слов в строке с использованием дешифратора.
Таким образом, здесь используется тройная адресация: адресация строки кэш-памяти по младшим разрядам адреса оперативной памяти, ассоциативный поиск по сравнению старших разрядов адреса оперативной памяти с тегами и для выбора двойного слова из строки кэш-памяти.
Рассмотренная схема относительно проста, но имеет свои недостатки.
Основным недостатком схемы является повышенная вероятность кэш-промахов. Этот недостаток проявляется при обработке массивов, например, при сложении двух массивов. Перебор строк производится путем изменения младших разрядов при сохранении старших. При несовпадении старших адресов и совпадении младших, будут выявляться "сплошные" промахи с перезаписью информации в кэш-память. В этих случаях использование кэш-памяти будет только тормозить работу процессора.
При использовании кэш-памяти с прямым отображением нет проблемы выбора устаревшей строки, так как каждому адресу соответствует одна строка. Она и удаляется при кэш-промахе. Но поле для дополнительной информации предусмотрено, например, для отметок присутствия данных и модификации информации операцией записи.
Организация кэш-памяти на основе множественно-ассоциативной памяти.Это модификация поиска с прямым отображением адресов. В этой схеме отображение адресов оперативной памяти в адреса кэш-памяти производится не для одной строки (кэш-памяти), а для множества строк, имеющих сов-
падения в младших разрядах их адресов в оперативной памяти.
Правомерна и другая интерпретация этой схемы как множеств отдельных блоков памяти с ассоциативным поиском информации, но с адресной выборкой "целевого" блока.
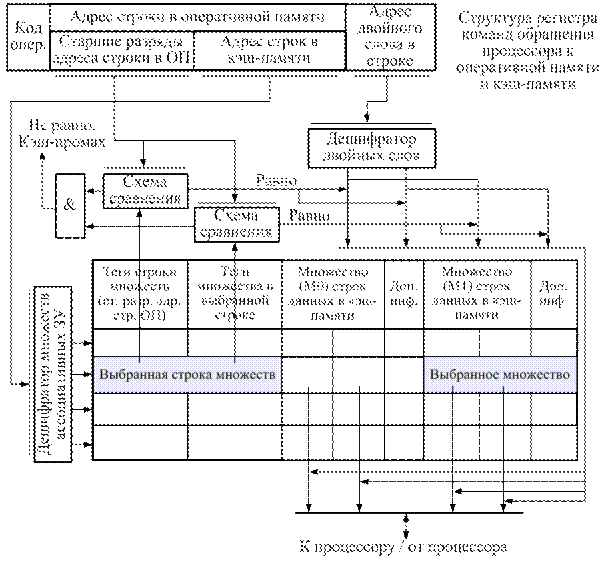
Рис. 7.8. Упрощенная схема работы кэш-памяти на основе
множественно ассоциативной памяти
В этой схеме для строк оперативной памяти с совпадающими значениями младших разрядов оперативной памяти определена для сохранения не единственная строка кэш-памяти, а множество строк, кратное степени двух: два, четыре или восемь, наиболее часто – четыре. На рис. 7.8 представлена схема множественно-ассоциативной памяти с двумя множествами строк (М0 и М1 в одной выбранной строке кэш-памяти). Каждая из этих строк идентифицируется адресами, составленными из старших цифр адреса строки в оперативной памяти.
При обращении к кэш-памяти старшие разряды адреса строки оперативной памяти сравниваются с тегами на внешних схемах сравнения. При несовпадении этих строк фиксируется кэш-промах, при совпадении – фиксируется попадание для одного из множеств (М0 или М1 на рис. 7.8). При кэш-попадании данные (двойное слово) выбираются из кэш-памяти с учетом выбранного множества (М0 или М1) по адресу двойного слова в строке с использованием дешифратора двойных слов.
В множественно-ассоциативной кэш-памяти при кэш-промахе для обновления информации имеется альтернатива выбора множества с устаревшими данными. Для случая использования в строках кэш-памяти только двух множеств, определение устаревшего множества определяется элементарно. Устаревшее множество то, в которое не было обращения в последнем кэш-попадании.
Для 4-х и более множеств при решении этого вопроса используются более сложные алгоритмы выбора по "вероятности неиспользования" (LRU). Сложность этих алгоритмов значительно возрастает по мере роста числа множеств. Для 4 множеств (наиболее часто используемый вариант кэш-памяти) алгоритм (LRU) использует три бита дополнительной информации B0, B1 и B2, кроме битов присутствия и модификации информации операцией записи.
Алгоритм выбора устаревшей строки предусматривает при последних доступах:
· к массиву М0 или М1 установление бита В0 = 1,
· к массиву М0 установление бита В1,
· к массиву М1 очищение бита В1.
· к массиву М2, установление бита В2,
· к массиву М3 очищение бита В2.
Биты LRU обновляются после каждого доступа к кэш-памяти и очищаются при каждой перезаписи или очистке кэш-памяти.
При кэш-промахе кэш-контроллер определяет множество-кандидата на удаление по его адресу, составленному из значений В0, В1 и В3. Это адрес удаляемого множества в двоичной системе счисления:
· старшая двоичная цифра адреса соответствует значению бита В0,
· младшая двоичная цифра адреса соответствует значению функции
___
(В0 & В2) V (В0 & В1).
Кэш-память на основе прямого отображения и множественно-ассоциативной памяти является наиболее распространенной. Но, по сравнению с реализацией на основе чисто ассоциативной памяти, она требует не два, а три такта работы:
1. определение строки кэш-памяти (по младшим разрядам адреса физической оперативной памяти),
2. определение строки или множества строк (по части старших разрядов адреса физической оперативной памяти),
3. чтение или обновление (запись) строки.
Этот недостаток можно компенсировать совместной оптимизацией алгоритмов работы механизмов кэш-памяти и виртуальной памяти на основе использования таблицы математических страниц (наиболее распространенный вариант реализации виртуальной памяти).
Программист пишет свои программы в диапазоне адресов своей математической памяти, операционная система с использованием механизма виртуальной памяти производит динамическую переадресацию команд и данных в пространство адресов физической памяти, выделенных данной программе.
В установившихся режимах работы процессора переадресация программ производится с использованием TLB (буфера быстрой переадресации на основе ассоциативной памяти) за один такт процессора.
Этот такт работы механизма виртуальной памяти можно совместить с первым тактом работы кэш-памяти. В этом случае, в первом такте работы кэш-памяти, при формировании адресов кэш-памяти с прямым отображением можно использовать не физические адреса команды или данных, которые еще не сформированы, а математические. Но в следующем такте сравнения тегов, для идентификации массивов строк данных необходимо использовать в качестве тегов старшие разряды уже физической памяти. Следующий (третий) такт кэш-памяти используется для обращения к массиву команд или данных при кэш-попаданиях.
Вопросы для самопроверки:
1. Проблема адресации данных в кэш-памяти.
2. Кэш-память на основе ассоциативного поиска.
3. Кэш память с прямым отображением.
4. Кэш-память на основе множественно-ассоциативной схемы поиска.
5. Алгоритм определения множества-кандидата на удаление.
6. Совместная оптимизация работы системы виртуальной и кэш-памяти.
Дата добавления: 2021-01-26; просмотров: 855;
Поиск по сайту
Узнать еще
- F45.38 другие органы или системы
- I. История возникновения и развития классно-урочной системы.
- I. Развитие Донбасса в условиях кризиса феодально-крепостнической системы
- I. Создание системы управленческого учета.
- III. Филогенез эндокринной системы.
- IV. Движение поездов при неисправности электрожезловой системы и порядок регулировки количества жезлов в жезловых аппаратах
- L.3. Состояние российской системы образования и необходимость ее
- T-FlexCAD (Топ Системы, Москва) и др.

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
