Назначение и общая схема подключения кэш-памяти
Кэш-память – это промежуточная память между оперативной памятью и процессором.
Основной целью использования кэш-памяти в ЭВМ является согласование полосы пропускания оперативной памяти и процессора. Полоса пропускания определяется количеством передаваемых бит за единицу времени (количество передаваемых бит на частоту передачи).
В современных ЭВМ быстродействие процессоров (количество выполняемых команд за единицу времени) в десятки раз превышает потока данных обмена с оперативной памятью. Это связано с особенностями развития схемотехнической базы процессоров и оперативной памяти. При использовании любой схемотехники рост быстродействия оперативной памяти почти всегда отставал от роста тактовой частоты процессора. Кроме этого, рост быстродействия процессора в последних моделях ЭВМ значительно возрастал за счет различных способов параллелизма выполнения команд. Это суперконвейерная и суперскалярная обработка команд, при которых одновременно выполняются множество команд.
Оперативная память большой емкости принципиально не может работать на тактовой частоте процессора. Основная проблема – большие задержки при выборке информации. Тому имеются две основные причины: большие задержки в адресных цепях (пропорциональные емкости памяти) и ограничения по использованию больших значений энергий при чтении и записи информации в массовой памяти в связи с проблемами охлаждения. Все это приводит к увеличению времени ожидания данных (уменьшения частоты обращений) с ростом емкости памяти.
В современных ЭВМ в качестве элементной базы в оперативной памяти используются интегральные схемы с большой степенью интеграции, часто на основе МОП-транзистров (МОП - Металл - Оксид - полупроводник). При этом в качестве элементарной ячейки хранения используется однотранзисторный вариант элемента динамической памяти схранениеминформации в виде заряда на конденсаторе (С) в цепи стока транзистора (рис. 7.1).
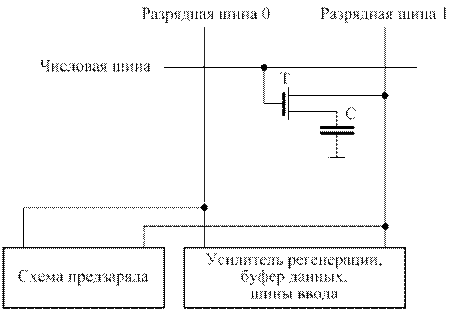
Рис. 7.1. Однотранзисторный вариант элемента динамической памяти
с хранением информации в виде заряда на емкости в цепи стока транзистора
Транзистор в динамической ячейке работает как ключ, управляющий передачей заряда. При записи информации открывают транзисторный ключ (Т) управляющим напряжением на числовой шине и заряжают конденсатор (С) до напряжения нуля или единицы с использованием разрядной шины 1.
При считывании информации специальная схема предзаряда сообщает потенциал (опорное напряжение) разрядным шинам. При подаче напряжения на числовую шину открывается транзистор, и на разрядную шину 1 передается заряд конденсатора. При единичном значении считываемой информации потенциал на разрядной шине 1 становится больше, чем потенциал на разрядной шине 0, при чтении нуля – меньше. По разности потенциалов определяется значение считываемого разряда. При чтении заряд на конденсаторе меняется, т.е. чтение производится с разрушением информации. Поэтому производится процедура восстановления прочитанной информации с использованием схемы регенерации. Схема однобитового среза матрицы динамической памяти представлена на рис.7.2.
В этой памяти время задержек обращения по чтению включает время задержки при чтении и регенерации. Периодическая регенерация в динамических ЗУ необходима и при отсутствии обращений к памяти. Причиной является саморазряд емкостей С (конденсатора) ячеек памяти. Для сохранения информации в ячейках памяти требуется циклическая регенерация ячеек памяти. Буфер данных используется для временного хранения прочитанных или записываемых данных. В качестве буфера данных используется регистр на статических триггерах.
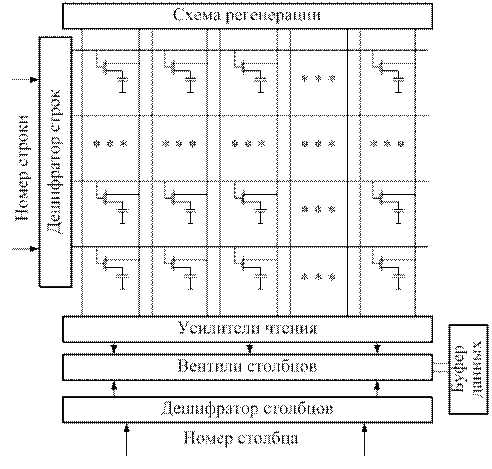
Рис.7.2. Схема матрицы динамической памяти
Потери на регенерацию также уменьшают быстродействие динамической памяти. Но наибольшие потери времени при обращениях к памяти (динамической и статической) составляют задержки в адресных цепях выборки данных при обращении как по чтению, так и по записи. Увеличение емкости памяти всегда связано с увеличением задержек в адресных цепях, т.е. с уменьшением быстродействия.
Память, представленная на рис.7.2 является однобитовой. Память для полноразрядных данных реализуется параллельной работой системы из множества однобитовых.
Основной причиной увеличения задержек в адресных цепях при увеличении емкости оперативной памяти являются задержки в дешифраторе.
Рассмотрим схему оперативной памяти, например, емкостью в 1Мбайт. Для задания адреса байта в такой, относительно небольшой, памяти требуется 20 разрядов. Для уменьшения оборудования адресных схем запоминающие элементы памяти располагают в виде восьми равносторонних матриц (1024 строки по 1024 бита). В соответствии с этим распределением адрес конкретной ячейкив разрядных матрицах определяется пересечением соответствующих строки и столбца.
Выбор строки и столбца производится двумя дешифраторами: строки и столбца (см. рис. 7.2).
Входами дешифраторов являются, соответственно, адресные шины строки и столбца. Каждый дешифратор имеет 10 входных адресных шин и 1024 выходные шины.
Полезный сигнал формируется только на одной "выбранной шине". На остальных шинах (не выбранных) входные токи выходных шин шунтируются диодами при несовпадении разрядов адресов (поданного и "прошитых" в дешифраторе). Таким образом, ток чтения "выбранных строк" уменьшается по отношению к входному на все строки в 102 раза, и этот ток должен создать "канал" чтения (заряд на затворе МПД транзисторов) для транзисторов всей строки матрицы (1024 транзистора). Затвор МДП-транзистора (метал — диэлектрик — полупроводник) является емкостной нагрузкой, и время заряда затвора обратно пропорционально току заряда.
Эта задержка в адресных цепях является основной задержкой при использовании любой памяти.
Информационный поток данных определяется количеством подаваемых или обработанных данных за единицу времени.
Для простоты рассмотрим работу процессора с одноадресной системой команд. В этом варианте выполнение одной команды связано с одним обращением к оперативной памяти по чтению или записи операнда.
Пусть процессор за такт (t) выполняет одну команду с формированием одного результата в формате двойного слова (4 байта), а обращение к оперативной памяти по чтению или записи составляет 4 такта процессора.
Очевидно, что в этом случае полосы пропускания процессора и оперативной памяти не совпадают, что приводит к простою процессора по 3 такта из четырех. Для согласования информационных потоков увеличивают ширину обращения к памяти. Например, можно при обращении к памяти производить чтение не одного двойного слова (4 байта), а строку из четырех двойных слов (16 байт). Простейший вариант этого решения представлен на рис. 7.3.
Эффективность этого решения основывается на статистической локальности обращений к памяти по месту и времени. Это означает, что существует большая вероятность того, что обращения к памяти в локальный промежуток времени с большой вероятностью будут производиться в локальный участок адресов памяти.

Рис. 7.3. Оперативная память с расслоением адресов
Здесь важно, что память разбивается на несколько блоков с обязательным расслоением адресов. Расслоение адресов (интерливинг) означает, что последовательность адресов двойных слов располагается в независимых блоках памяти.
Но это еще не кэш-память, а просто выборка данных с упреждением.
Передачу выбранной строки байтов на процессор можно выполнять параллельно или последовательно. Так как процессору при каждом обращении требуются данные в соответствии с шириной обработки, например, по 4 байта (двойное слово), то передачу данных можно производить последовательно по 4 байта без расширения разрядности шины данных, например, с использованием пакетной передачи.
Это параллельная работа нескольких блоков оперативной памяти с поблочным чередованием адресов. За одно обращение к оперативной памяти выбирается в N раз больше байтов (строка байтов со смежными адресами), что уравнивает информационные потоки быстрого процессора и "медленной" оперативной памяти.
Но процессор работает по командам, каждая из которых оперирует с данными ограниченной разрядности и необязательно расположенными по смежным адресам в пределах ширины обращения. Любое обращение к памяти за пределами выбранной строки приводит к чтению новой строки и замене содержимого регистра данных. Этот случай характерен для обработки двух массивов, например, при сложении их элементов. В этих случаях, при каждом обращении к памяти по чтению, содержимое регистра данных будет обновляться, и эффект групповой выборки данных сведется к нулю.
Проблема решается введением множества регистров, по одному для множества чтений из памяти, т.е. использованием дополнительной памяти, но уже на основе статических регистров, расположенных как можно ближе к процессору или в самом процессоре.
Важность расположения кэш-памяти в процессоре определяется тем, что в этом случае она может использовать тактовую частоту процессора, а не материнской платы.
Схема использования многоблочной оперативной памяти с расслоением адресов и использования дополнительной (промежуточной) кэш-памяти представлена на рис. 7.4.
При использовании умеренного адресного пространства кэш-памяти и расположении этой памяти в кристалле процессора можно избежать временных потерь, т.е. согласовать информационные потоки данных оперативной памяти и процессора. Но, даже если кэш-память размещается в кристалле процессора, при обращении к ней может теряться один такт.
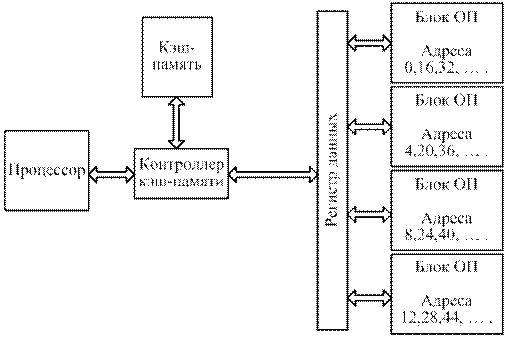
Рис.7.4.Система процессор-память с использованием кэш-памяти
Взаимодействие устройств, представленных на рис. 7.4, следующее.
Для выборки команды или данных процессор посылает запрос к оперативной памяти: код операции (прочитать, записать), адрес данных в оперативной памяти и размер операнда (для данных). Кэш-контроллер перехватывает(копирует) запрос к оперативной памяти ипроверяет наличие запрашиваемых данных или команд в кэш-памяти,используя адреса данных (или команд) в оперативной памяти. При наличии в кэш-памяти данных по запрашиваемым адресам (кэш-попадание), обращение к оперативной памяти блокируется, и данные пересылаются в процессор из ячеек кэш-памяти, в противном случае (кэш промах) данные по запрашиваемому адресу пересылаются из оперативной
памяти с сохранением копии всей строки в кэш-памяти.
Здесь возможны варианты. Рассмотренный алгоритм предусматривает одновременный запрос к двум устройствам: оперативной памяти и кэш-памяти, но и при кэш-попаданиях оперативная память оказывается занятой, и доступ к ней других процессоров или устройств ПДП блокирован. По этой причине в многопроцессорных системах часто используется другая схема: вначале проверяется наличие данных или команд в кэш-памяти, и только при кэш промахе запрос пересылается в оперативную память. В этой схеме при кэш-промахах время незначительно увеличивается, но при кэш-попаданиях память остается доступной для других процессоров или устройств ПДП.
Альтернативой многоблочной памяти с расслоением (рис.7.4) является одноблочная память с внутренним регистром на статических триггерах на строку (или несколько строк) кэш-памяти. Схема матрицы однобитовой динамической памяти с внутренним регистром строки кэш-памяти представлена на рис.7.5.
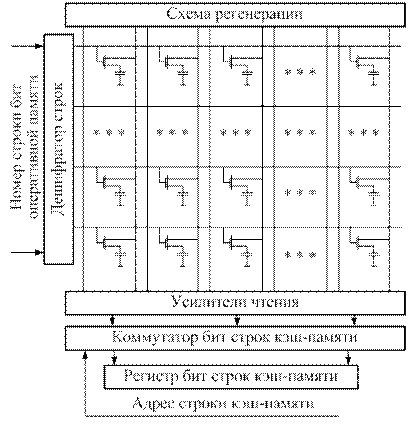
Рис.7.5. Схема матрицы однобитовой динамической памяти с внутренним
регистром строки кэш-памяти на статических элементах памяти
В этой схеме нет "расслоения" адресов по блокам. Вся память может быть выполнена в виде разрядных матриц. При выборке данных из памяти данные выбираются не по двойным словам, а строками кэш-памяти (например, по 4 двойных слова).
Такая выборка реализуется за счет того, что при адресации строки матриц каждого разряда производится фиксация ее значения на внутреннем регистре матрицы оперативной памяти. На этом регистре, выполненном на быстродействующих статических триггерах, может сохраняться вся строка бит или часть строки (одна или несколько строк кэш-памяти). Нужные биты (по младшим разрядам адреса) выбираются уже из быстродействующего регистра. При этом выбираются значения разрядов по соседним адресам, т.е. вся строчка кэш-памяти.
Дополнительной проблемой для кэш-памяти остается задержка первого чтения строки данных из оперативной памяти. Но и эта проблема в современных ЭВМ решается разделением команд на команды действия и команды обращения к памяти. Команды действия – это команды типа регистр/регистр, без обращения к оперативной памяти. Команды обращения к памяти – это команды только обращения к оперативной памяти по чтению или записи (загрузки данных в РОН или сохранения данных в ячейке памяти).
Проблема задержек при первом обращении к памяти может решатьсявынесением команд загрузки данных вперед на несколько команд до их исполнения.
Вопросы для самопроверки:
1. Цель использования кэш-памяти.
2. Особенности схемы ячейки динамической памяти.
3. Природа основных задержек при обращении к оперативной памяти.
4. Механизм считывания информации из ячейки динамической памяти.
5. Простейший механизм согласования плотности информационных потоков памяти и процессора.
6. Взаимодействие устройств: процессор – оперативная память – кэш-память.
7. Взаимодействие устройств в системе: процессор, кэш-память, оперативная память.
8. Поисковый адрес данных, используемый при обращении к кэш-памяти.
Дата добавления: 2021-01-26; просмотров: 872;
Поиск по сайту
Узнать еще
- I. Общая характеристика категории состояния как часть речи
- II. Лексико-грамматические разряды местоимений. Их общая характеристика
- IV. ОБЩАЯ ХАРАКТЕРИСТИКА ВИРУСОВ
- MATHCAD. Назначение. Основные возможности. Простейшие приемы работы.
- PCI является стандартной шиной для подключения периферийных устройств. Среди них можно отметить сетевые карты, модемы, звуковые карты и платы захвата видео.
- V. Схема разбора глагола
- XXIII. ОБЩАЯ ХАРАКТЕРИСТИКА
- А — растяжение; б — сжатие; в — изгиб; г — кручение (ориг.). На схемах внизу — смещение элементов (по С. Э. Хайкипу)

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
