Нелинейные модели парной регрессии и корреляции
Если между экономическими явлениями существуют нелинейные соотношения, то они выражаются с помощью соответствующих нелинейных функций.
Различают два класса нелинейных регрессий:
1. Регрессии, нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам, например
– полиномы различных степеней – 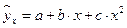 ,
, 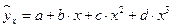 ;
;
– равносторонняя гипербола –  ;
;
– полулогарифмическая функция – 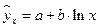 .
.
2. Регрессии, нелинейные по оцениваемым параметрам, например
– степенная – 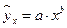 ;
;
– показательная – 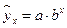 ;
;
– экспоненциальная – 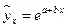 .
.
Регрессии нелинейные по включенным переменным приводятся к линейному виду простой заменой переменных, а дальнейшая оценка параметров производится с помощью метода наименьших квадратов. Рассмотрим некоторые модели.
Равносторонняя гипербола может быть использована для характеристики связи удельных расходов сырья, материалов, топлива от объема выпускаемой продукции, времени обращения товаров от величины товарооборота, процента прироста заработной платы от уровня безработицы (например, кривая Филлипса), расходов на непродовольственные товары от доходов или общей суммы расходов (например, кривые Энгеля) и в других случаях. Гипербола приводится к линейному уравнению простой заменой: 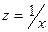 . Система линейных уравнений при применении МНК выглядит следующим образом:
. Система линейных уравнений при применении МНК выглядит следующим образом:
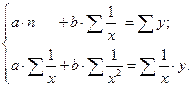 (1.17)
(1.17)
Аналогичным образом приводятся к линейному виду зависимости , 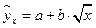 и другие.
и другие.
Иначе обстоит дело с регрессиями нелинейными по оцениваемым параметрам, которые делятся на два типа: нелинейные модели внутренне линейные (приводятся к линейному виду с помощью соответствующих преобразований, например, логарифмированием) и нелинейные модели внутренне нелинейные (к линейному виду не приводятся).
К внутренне линейным моделям относятся, например, степенная функция – , показательная – , экспоненциальная – , логистическая – 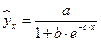 , обратная –
, обратная – 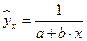 .
.
К внутренне нелинейным моделям можно отнести следующие модели: 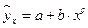 ,
, 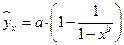 .
.
Среди нелинейных моделей наиболее часто используется степенная функция 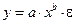 , которая приводится к линейному виду логарифмированием:
, которая приводится к линейному виду логарифмированием:
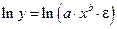 ;
;
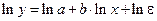 ;
;
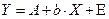 ,
,
где 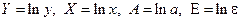 .
.
Таким образом, МНК мы применяем для преобразованных данных:
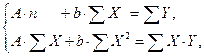
а затем потенцированием находим искомое уравнение.
Широкое использование степенной функции связано с тем, что параметр b в ней имеет четкое экономическое истолкование – он является коэффициентом эластичности. (Коэффициент эластичности показывает, на сколько процентов измениться в среднем результат, если фактор изменится на 1%.) Формула для расчета коэффициента эластичности имеет вид:
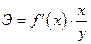 . (1.18)
. (1.18)
Так как для остальных функций коэффициент эластичности не является постоянной величиной, а зависит от соответствующего значения фактора x, то обычно рассчитывается средний коэффициент эластичности:
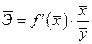 . (1.19)
. (1.19)
Уравнение нелинейной регрессии, так же, как и в случае линейной зависимости, дополняется показателем тесноты связи. В данном случае это индекс корреляции:
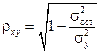 , (1.20)
, (1.20)
где 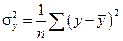 – общая дисперсия результативного признака y,
– общая дисперсия результативного признака y, 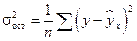 – остаточная дисперсия.
– остаточная дисперсия.
Величина данного показателя находится в пределах: 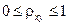 . Чем ближе значение индекса корреляции к единице, тем теснее связь рассматриваемых признаков, тем более надежно уравнение регрессии.
. Чем ближе значение индекса корреляции к единице, тем теснее связь рассматриваемых признаков, тем более надежно уравнение регрессии.
Квадрат индекса корреляции носит название индексадетерминации и характеризует долю дисперсии результативного признака y, объясняемую регрессией, в общей дисперсии результативного признака:
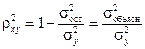 , (1.21)
, (1.21)
т.е. имеет тот же смысл, что и в линейной регрессии; 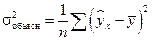 .
.
Индекс детерминации 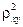 можно сравнивать с коэффициентом детерминации
можно сравнивать с коэффициентом детерминации 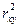 для обоснования возможности применения линейной функции. Чем больше кривизна линии регрессии, тем величина меньше . А близость этих показателей указывает на то, что нет необходимости усложнять форму уравнения регрессии и можно использовать линейную функцию.
для обоснования возможности применения линейной функции. Чем больше кривизна линии регрессии, тем величина меньше . А близость этих показателей указывает на то, что нет необходимости усложнять форму уравнения регрессии и можно использовать линейную функцию.
Индекс детерминации используется для проверки существенности в целом уравнения регрессии по F-критерию Фишера:
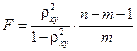 , (1.22)
, (1.22)
где – индекс детерминации, n – число наблюдений, m – число параметров при переменной x. Фактическое значение F-критерия (1.22) сравнивается с табличным при уровне значимости 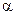 и числе степеней свободы
и числе степеней свободы 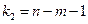 (для остаточной суммы квадратов) и
(для остаточной суммы квадратов) и 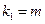 (для факторной суммы квадратов).
(для факторной суммы квадратов).
О качестве нелинейного уравнения регрессии можно также судить и по средней ошибке аппроксимации, которая, так же как и в линейном случае, вычисляется по формуле (1.8).
Рассмотрим пример из параграфа 1.1, предположив, что связь между признаками носит нелинейный характер, и найдем параметры следующих нелинейных уравнений: 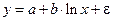 и
и 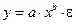 .
.
А. Для нахождения параметров регрессии делаем замену 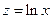 и составляем вспомогательную таблицу (
и составляем вспомогательную таблицу ( 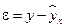 ).
).
Найдем уравнение регрессии:
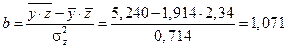 ,
,
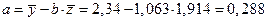 .
.
Таблица 1.5
| x | z | y | 
| 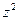
| 
| 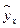
| 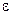
| 
| 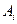
| |
| 1,2 | 0,182 | 0,9 | 0,164 | 0,033 | 0,81 | 0,483 | 0,417 | 0,174 | 46,33 | |
| 3,1 | 1,131 | 1,2 | 1,358 | 1,280 | 1,44 | 1,499 | –0,299 | 0,089 | 24,93 | |
| 5,3 | 1,668 | 1,8 | 3,002 | 2,781 | 3,24 | 2,073 | –0,273 | 0,075 | 15,19 | |
| 7,4 | 2,001 | 2,2 | 4,403 | 4,006 | 4,84 | 2,431 | –0,231 | 0,053 | 10,49 | |
| 9,6 | 2,262 | 2,6 | 5,881 | 5,116 | 6,76 | 2,709 | –0,109 | 0,012 | 4,21 | |
| 11,8 | 2,468 | 2,9 | 7,157 | 6,092 | 8,41 | 2,930 | –0,030 | 0,001 | 1,04 | |
| 14,5 | 2,674 | 3,3 | 8,825 | 7,151 | 10,89 | 3,151 | 0,149 | 0,022 | 4,52 | |
| 18,7 | 2,929 | 3,8 | 11,128 | 8,576 | 14,44 | 3,423 | 0,377 | 0,142 | 9,92 | |
| Сумма | 71,6 | 15,315 | 18,7 | 41,918 | 35,035 | 50,83 | 18,700 | 0,000 | 0,568 | 116,62 |
| Среднее значение | 8,95 | 1,914 | 2,34 | 5,240 | 4,379 | 6,35 | – | – | 0,0711 | 14,58 |
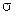
| – | 0,845 | 0,943 | – | – | – | – | – | – | – |
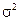
| – | 0,714 | 0,890 | – | – | – | – | – | – | – |
Таким образом, уравнение регрессии имеет вид: 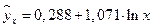 .
.
Индекс корреляции находим по формуле (1.20):
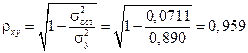 ,
,
а индекс детерминации 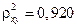 , который показывает, что 92,0% вариации результативного показателя объясняется вариацией фактора дохода, а 8,2% приходится на долю прочих факторов.
, который показывает, что 92,0% вариации результативного показателя объясняется вариацией фактора дохода, а 8,2% приходится на долю прочих факторов.
Средняя ошибка аппроксимации: 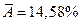 , что недопустимо велико.
, что недопустимо велико.
F-критерий Фишера:
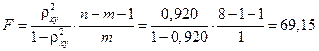 ,
,
значительно превышает табличное 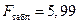 .
.
Изобразим на графике исходные данные и линию регрессии:
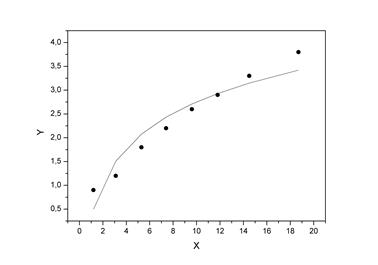
Рис. 1.6.
Б. Для нахождения параметров регрессии необходимо провести ее линеаризацию посредством логарифмирования:
,
где .
Составим таблицу для преобразованных данных (см. таблицу 1.6).
Построим линейную форму уравнения регрессии:
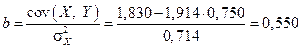 ,
,
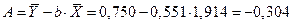 .
.
Т.е. линейная форма уравнения регрессии имеет вид: 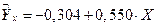 .
.
После потенцирования находим искомое уравнение регрессии:
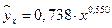 .
.
Индекс корреляции находим по формуле (1.20):
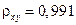 ,
,
Таблица 1.6
| X | Y | 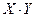
| 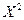
| 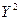
|
|
|
|
| |
| 0,182 | –0,105 | –0,019 | 0,033 | 0,011 | 0,816 | 0,084 | 0,0070 | 9,316 | |
| 1,131 | 0,182 | 0,206 | 1,280 | 0,033 | 1,376 | –0,176 | 0,0310 | 14,677 | |
| 1,668 | 0,588 | 0,980 | 2,781 | 0,345 | 1,849 | –0,049 | 0,0024 | 2,706 | |
| 2,001 | 0,788 | 1,578 | 4,006 | 0,622 | 2,222 | –0,022 | 0,0005 | 0,980 | |
| 2,262 | 0,956 | 2,161 | 5,116 | 0,913 | 2,564 | 0,036 | 0,0013 | 1,393 | |
| 2,468 | 1,065 | 2,628 | 6,092 | 1,134 | 2,872 | 0,028 | 0,0008 | 0,960 | |
| 2,674 | 1,194 | 3,193 | 7,151 | 1,425 | 3,217 | 0,083 | 0,0069 | 2,512 | |
| 2,929 | 1,335 | 3,910 | 8,576 | 1,782 | 3,701 | 0,099 | 0,0099 | 2,615 | |
| Сумма | 15,315 | 6,002 | 14,637 | 35,035 | 6,266 | 18,616 | 0,084 | 0,0597 | 35,159 |
| Среднее значение | 1,914 | 0,750 | 1,830 | 4,379 | 0,783 | – | – | 0,0075 | 4,395 |
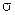
| 0,845 | 0,469 | – | – | – | – | – | – | – |
|
| 0,716 | 0,220 | – | – | – | – | – | – | – |
а индекс детерминации 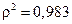 , который показывает, что 98,3% вариации результативного показателя объясняется вариацией фактора дохода, а 1,7% приходится на долю прочих факторов.
, который показывает, что 98,3% вариации результативного показателя объясняется вариацией фактора дохода, а 1,7% приходится на долю прочих факторов.
Средняя ошибка аппроксимации: 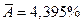 показывает, что линия регрессии хорошо приближает исходные данные.
показывает, что линия регрессии хорошо приближает исходные данные.
F-критерий Фишера:
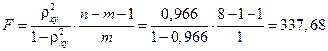
значительно превышает табличное .
Изобразим на графике исходные данные и линию регрессии:
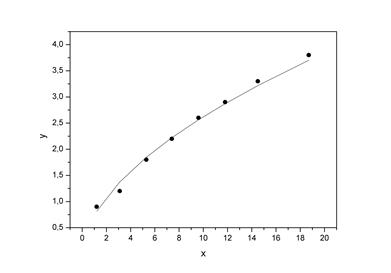
Рис. 1.8.
Сравним построенные модели по индексу детерминации и средней ошибке аппроксимации:
Таблица 1.7
| Модель | Индекс детерминации,
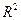 ( , ) ( , )
| Средняя ошибка
аппроксимации, 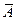 , % , %
|
Линейная модель,
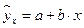
| 0,982 | 6,35 |
| Полулогарифмическая
модель,
| 0,920 | 14,58 |
| Степенная модель,
| 0,983 | 4,395 |
Наиболее хорошо исходные данные аппроксимирует степенная модель.
Дата добавления: 2016-10-18; просмотров: 2069;
Поиск по сайту
Узнать еще
- А. Аналитические модели.
- А. Модели экономического прогноза на базе производственных функций.
- Автоматизация технологического проектирования. Основные задачи и модели автоматизации технологического проектирования
- Автоматизация ТП. Моделирование техпроцесса.
- АВТОРСКИЕ МОДЕЛИ ПСИХОЛОГИЧЕСКОЙ СЛУЖБЫ, ИЛИ КАК ОБРЕСТИ СВОЕ ЛИЦО
- Адекватность модели и объекта
- Алгоритмы и модели компоновки
- Анализ качества эмпирического уравнения множественной линейной регрессии

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
