МОДЕЛЬ МНОЖЕСТВЕННОЙ РЕГРЕССИИ
На любой экономический показатель чаще всего оказывает влияние не один, а несколько факторов. Например, спрос на некоторое благо определяется не только ценой данного блага, но и ценами на замещающие и дополняющие блага, доходом потребителей и многими другими факторами. В этом случае вместо парной регрессии рассматривается множественная регрессия
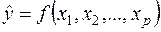 (1)
(1)
Множественная регрессия широко используется в решении проблем спроса, доходности акций, при изучении функции издержек производства, в макроэкономических расчетах и в ряде других вопросов экономики. В настоящее время множественная регрессия – один из наиболее распространенных методов в эконометрике. Основной целью множественной регрессии является построение модели с большим числом факторов, а также определение влияния каждого фактора в отдельности и совокупного их воздействия на моделируемый показатель.
Множественный регрессионный анализ является развитием парного регрессионного анализа в случаях, когда зависимая переменная связана более чем с одной независимой переменной. Большая часть анализа является непосредственным расширением парной регрессионной модели, но здесь также появляются и некоторые новые проблемы, из которых следует выделить две. Первая проблема касается исследования влияния конкретной независимой переменной на зависимую переменную, а также разграничения её воздействия и воздействий других независимых переменных. Второй важной проблемой является спецификация модели, которая состоит в том, что необходимо ответить на вопрос, какие факторы следует включить в регрессию (1), а какие – исключить из неё. В дальнейшем изложение общих вопросов множественного регрессионного анализа будем вести, разграничивая эти проблемы. Поэтому вначале будем полагать, что спецификация модели правильна.
Самой употребляемой и наиболее простой из моделей множественной регрессии является линейная модель множественной регрессии:
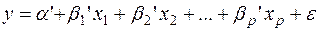 (2)
(2)
По математическому смыслу коэффициенты 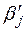 в уравнении (2) равны частным производным результативного признака y по соответствующим факторам:
в уравнении (2) равны частным производным результативного признака y по соответствующим факторам:
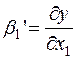 ,
, 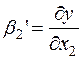 ,…,
,…, 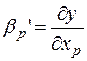 .
.
Параметр α называется свободным членом и определяет значение y в случае, когда все объясняющие переменные равны нулю. Однако, как и в случае парной регрессии, факторы по своему экономическому содержанию часто не могут принимать нулевых значений, и значение свободного члена не имеет экономического смысла. При этом, в отличие от парной регрессии, значение каждого регрессионного коэффициента равно среднему изменению y при увеличении xj на одну единицу лишь при условии, что все остальные факторы остались неизменными. Величина ε представляет собой случайную ошибку регрессионной зависимости.
Попутно отметим, что наиболее просто можно определять оценки параметров , изменяя только один фактор xj, оставляя при этом значения других факторов неизменными. Тогда задача оценки параметров сводилась бы к последовательности задач парного регрессионного анализа по каждому фактору. Однако такой подход, широко используемый в естественнонаучных исследованиях, (физических, химических, биологических), в экономике является неприемлемым. Экономист, в отличие от экспериментатора – естественника, лишен возможности регулировать отдельные факторы, поскольку не удаётся обеспечить равенство всех прочих условий для оценки влияния одного исследуемого фактора.
Получение оценок параметров 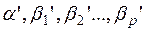 уравнения регрессии (2) – одна из важнейших задач множественного регрессионного анализа. Самым распространенным методом решения этой задачи является метод наименьших квадратов (МНК). Его суть состоит в минимизации суммы квадратов отклонений наблюдаемых значений зависимой переменной y от её значений
уравнения регрессии (2) – одна из важнейших задач множественного регрессионного анализа. Самым распространенным методом решения этой задачи является метод наименьших квадратов (МНК). Его суть состоит в минимизации суммы квадратов отклонений наблюдаемых значений зависимой переменной y от её значений 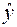 , получаемых по уравнению регрессии. Поскольку параметры являются случайными величинами, определить их истинные значения по выборке невозможно. Поэтому вместо теоретического уравнения регрессии (2) оценивается так называемое эмпирическое уравнение регрессии, которое можно представить в виде:
, получаемых по уравнению регрессии. Поскольку параметры являются случайными величинами, определить их истинные значения по выборке невозможно. Поэтому вместо теоретического уравнения регрессии (2) оценивается так называемое эмпирическое уравнение регрессии, которое можно представить в виде:
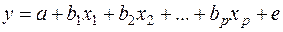 (3)
(3)
Здесь 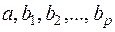 - оценки теоретических значений , или эмпирические коэффициенты регрессии, е – оценка отклонения ε. Тогда расчетное выражение имеет вид:
- оценки теоретических значений , или эмпирические коэффициенты регрессии, е – оценка отклонения ε. Тогда расчетное выражение имеет вид:
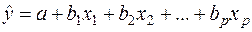 (4)
(4)
Пусть имеется n наблюдений объясняющих переменных и соответствующих им значений результативного признака:
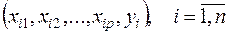 (5)
(5)
Для однозначного определения значений параметров уравнения (4) объем выборки n должен быть не меньше количества параметров, т.е. 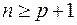 . В противном случае значения параметров не могут быть определены однозначно. Если n=p+1, оценки параметров рассчитываются единственным образом без МНК простой подстановкой значений (5) в выражение (4). Получается система (p+1) уравнений с таким же количеством неизвестных, которая решается любым способом, применяемым к системам линейных алгебраических уравнений (СЛАУ). Однако с точки зрения статистического подхода такое решение задачи является ненадежным, поскольку измеренные значения переменных (5) содержат различные виды погрешностей. Поэтому для получения надежных оценок параметров уравнения (4) объём выборки должен значительно превышать количество определяемых по нему параметров. Практически, как было сказано ранее, объём выборки должен превышать количество параметров при xj в уравнении (4) в 6-7 раз.
. В противном случае значения параметров не могут быть определены однозначно. Если n=p+1, оценки параметров рассчитываются единственным образом без МНК простой подстановкой значений (5) в выражение (4). Получается система (p+1) уравнений с таким же количеством неизвестных, которая решается любым способом, применяемым к системам линейных алгебраических уравнений (СЛАУ). Однако с точки зрения статистического подхода такое решение задачи является ненадежным, поскольку измеренные значения переменных (5) содержат различные виды погрешностей. Поэтому для получения надежных оценок параметров уравнения (4) объём выборки должен значительно превышать количество определяемых по нему параметров. Практически, как было сказано ранее, объём выборки должен превышать количество параметров при xj в уравнении (4) в 6-7 раз.
Для проведения анализа в рамках линейной модели множественной регрессии необходимо выполнение ряда предпосылок МНК. В основном это те же предпосылки, что и для парной регрессии, однако здесь нужно добавить предположения, специфичные для множественной регрессии:
50.Спецификация модели имеет вид (2).
60.Отсутствие мультиколлинеарности: между объясняющими переменными отсутствует строгая линейная зависимость, что играет важную роль в отборе факторов при решении проблемы спецификации модели.
70.Ошибки 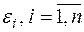 имеют нормальное распределение
имеют нормальное распределение 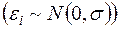 . Выполнимость этого условия нужна для проверки статистических гипотез и построения интервальных оценок.
. Выполнимость этого условия нужна для проверки статистических гипотез и построения интервальных оценок.
При выполнимости всех этих предпосылок имеет место многомерный аналог теоремы Гаусса – Маркова: оценки , полученные по МНК, являются наиболее эффективными (в смысле наименьшей дисперсии) в классе линейных несмещенных оценок.
Оценка параметров линейного уравнения множественной регрессии
Рассмотрим три метода расчета параметров множественной линейной регрессии.
1. Матричный метод. Представим данные наблюдений и параметры модели в матричной форме.
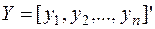 - n – мерный вектор – столбец наблюдений зависимой переменной;
- n – мерный вектор – столбец наблюдений зависимой переменной;
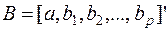 - (p+1) – мерный вектор – столбец параметров уравнения регрессии (3);
- (p+1) – мерный вектор – столбец параметров уравнения регрессии (3);
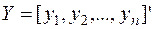 - n – мерный вектор – столбец отклонений выборочных значений yi от значений
- n – мерный вектор – столбец отклонений выборочных значений yi от значений 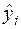 , получаемых по уравнению (4).
, получаемых по уравнению (4).
Для удобства записи столбцы записаны как строки и поэтому снабжены штрихом для обозначения операции транспонирования.
Наконец, значения независимых переменных запишем в виде прямоугольной матрицы размерности 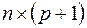 :
:
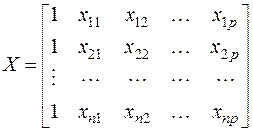
Каждому столбцу этой матрицы отвечает набор из n значений одного из факторов, а первый столбец состоит из единиц, которые соответствуют значениям переменной при свободном члене.
В этих обозначениях эмпирическое уравнение регрессии выглядит так:
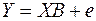 (6)
(6)
Отсюда вектор остатков регрессии можно выразить таким образом:
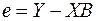 (7)
(7)
Таким образом, функционал 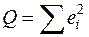 , который, собственно, и минимизируется по МНК, можно записать как произведение вектора – строки е’ на вектор – столбец е:
, который, собственно, и минимизируется по МНК, можно записать как произведение вектора – строки е’ на вектор – столбец е:
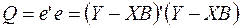 (8)
(8)
В соответствии с МНК дифференцирование Q по вектору В приводит к выражению:
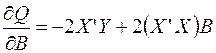 (9)
(9)
которое для нахождения экстремума следует приравнять к нулю. В результате преобразований получаем выражение для вектора параметров регрессии:
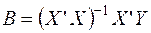 10)
10)
Здесь 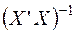 - матрица, обратная к
- матрица, обратная к 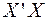 .
.
Пример. Бюджетное обследование пяти случайно выбранных семей дало следующие результаты (в тыс. руб.):
| Семья | Накопления, S | Доход, Y | Имущество, W |
| 3,5 | |||
| 1,5 |
Оценить регрессию S на Y и W.
Введем обозначения:
S=[3;6;5;3,5;1,5]’ – вектор наблюдений зависимой переменной;
B=[a;b1;b2]’ – вектор параметров уравнения регрессии;
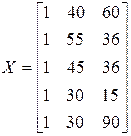
- матрица значений независимых переменных.
Далее с помощью матричных операций вычисляем (используем табличный процессор MS Excel и функции ТРАНСП, МУМНОЖ и МОБР в нем):
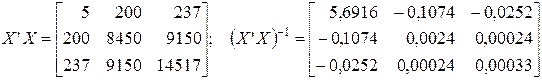
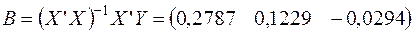
Регрессионная модель в скалярном виде:
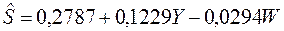
2. Скалярный метод. При его применении строится система нормальных уравнений, решение которой и позволяет получить оценки параметров регрессии:
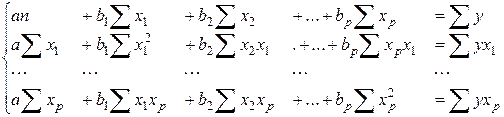 (11)
(11)
Решить эту систему можно любым подходящим способом, например, методом определителей или методом Гаусса. При небольшом количестве определяемых параметров использование определителей предпочтительнее.
Рассмотрим пример, приведенный выше. Здесь для двух факторов, Y и W, система нормальных уравнений запишется так:
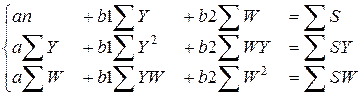
Рассчитываем значения сумм, получаем:
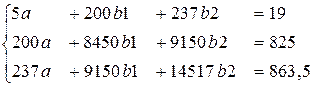
Рассчитаем значения определителей этой системы, используем функцию МОПРЕД в Excel:
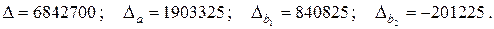
Отсюда получим оценки параметров модели:
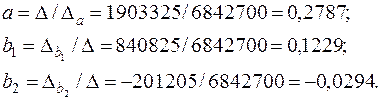
Обратите внимание, что коэффициенты в левой части системы нормальных уравнений совпадают с соответствующими элементами матрицы .
3. Регрессионная модель в стандартизованном масштабе. Уравнение регрессии в стандартизованном масштабе имеет вид:
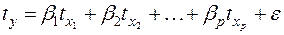 (12)
(12)
где 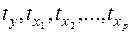 - стандартизованные переменные:
- стандартизованные переменные:
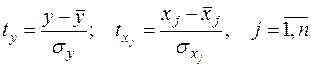 (13)
(13)
для которых среднее значение равно нулю: 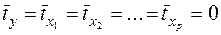 , а среднее квадратическое отклонение равно единице:
, а среднее квадратическое отклонение равно единице: 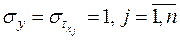 ; βj – стандартизованные коэффициенты регрессии, или β – коэффициенты (не следует путать их с параметрами уравнения (2)).
; βj – стандартизованные коэффициенты регрессии, или β – коэффициенты (не следует путать их с параметрами уравнения (2)).
Применяя МНК к уравнению (12), после соответствующих преобразований получим систему нормальных уравнений:
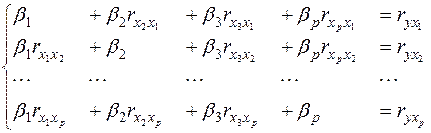 (14)
(14)
В этой системе 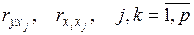 - элементы расширенной матрицы парных коэффициентов корреляции или, другими словами, коэффициенты парной корреляции между различными факторами или между факторами и результативным признаком. Имея измеренные значения всех переменных, вычислить матрицу парных коэффициентов корреляции на компьютере не составляет большого труда, используя, например, табличный процессор MS Excel или программу Statistica.
- элементы расширенной матрицы парных коэффициентов корреляции или, другими словами, коэффициенты парной корреляции между различными факторами или между факторами и результативным признаком. Имея измеренные значения всех переменных, вычислить матрицу парных коэффициентов корреляции на компьютере не составляет большого труда, используя, например, табличный процессор MS Excel или программу Statistica.
Решением системы (14) определяются β – коэффициенты. Эти коэффициенты показывают, на сколько значений с.к.о. изменитися в среднем результат, если соответствующий фактор хj изменится на одну с.к.о. при неизменном среднем уровне других факторов. Поскольку все переменные заданы как центрированные и нормированные, β – коэффициенты сравнимы между собой. Сравнивая их друг с другом, можно ранжировать факторы по силе их воздействия на результат. В этом основное достоинство стандартизованных коэффициентов регрессии, в отличие от коэффициентов обычной регрессии, которые несравнимы между собой.
Пусть функция издержек производства y (тыс. руб.) характеризуется уравнением вида:
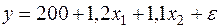
где факторами являются основные производственные фонды (тыс. руб.) и численность занятых в производстве (чел.). Отсюда видно, что при постоянной занятости рост стоимости основных производственных фондов на 1 тыс. руб. влечет за собой увеличение затрат в среднем на 1,2 тыс. руб., а увеличение числа занятых на одного человека при неизменной технической оснащенности приводит к росту затрат в среднем на 1,1 тыс. руб.. Однако это не означает, что первый фактор сильнее влияет на издержки производства по сравнению со вторым. Такое сравнение возможно, если обратиться к уравнению регрессии в стандартизованном масштабе. Пусть оно выглядит так:
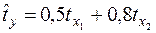
Это означает, что с ростом первого фактора на одно с.к.о. при неизменном числе занятых затраты на продукцию увеличиваются в среднем на 0,5 с.к.о. Так как β1<β2 (0,5<0,8), то можно заключить, что большее влияние на производство продукции оказывает второй фактор, а не первый, как кажется из уравнения регрессии в натуральном масштабе.
В парной зависимости стандартизованный коэффициент регрессии есть не что иное, как линейный коэффициент корреляции r. Подобно тому, как в парной зависимости коэффициенты регрессии и корреляции связаны между собой, так и во множественной регрессии коэффициенты «чистой» регрессии bj связаны с β – коэффициентами:
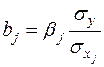 (15)
(15)
Это позволяет от уравнения регрессии в стандартизованном масштабе:
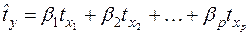 (16)
(16)
переходить к уравнению регрессии в натуральном масштабе (4). Параметр а определяется так:
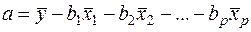 (17)
(17)
Свободный член в уравнении (16) отсутствует, поскольку все стандартизованные переменные имеют нулевое среднее значение.
Рассмотренный смысл стандартизованных коэффициентов регрессии позволяет использовать их при отсеве факторов – из модели исключаются факторы с наименьшим значением βj.
Компьютерные программы построения уравнения множественной регрессии в зависимости от использованного в них алгоритма решения позволяют получить либо только уравнение регрессии для исходных данных, либо, кроме того, уравнение регрессии в стандартизованном масштабе.
В заключение приведем расчет стандартизованного уравнения регрессии по данным рассмотренного выше числового примера. Используя функцию КОРРЕЛ в Excel, рассчитаем расширенную матрицу парных коэффициентов корреляции:
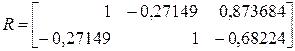
в которой последний столбец состоит из элементов 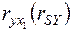 и
и 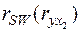 соответственно, а неединичные элементы в первых двух столбцах соответствуют
соответственно, а неединичные элементы в первых двух столбцах соответствуют 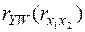 . Эта матрица является расширенной матрицей системы уравнений для определения β – коэффициентов:
. Эта матрица является расширенной матрицей системы уравнений для определения β – коэффициентов:
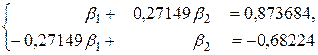
Решаем систему методом определителей, получаем:
Δ=0,926291; Δ1=0,688461; Δ2=-0,44504;
β1=0,688461/0,926291=0,743245;
β2=-0,44504/0,926291=-0,48045;
Тогда стандартизованное уравнение регрессии запишется так:
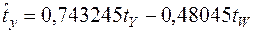
Отсюда видно, что первый фактор оказывает большее воздействие на результат, чем второй (|β1|>|β2|), однако эта разница не так велика, как для коэффициентов в натуральном масштабе (0,1229 и –0,0294). От этого уравнения можно перейти к уравнению в натуральном масштабе. Для этого с помощью функции СТАНДОТКЛОН в Excel определим стандартные отклонения всех переменных:
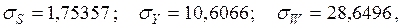
а с помощью функции СРЗНАЧ – средние значения:
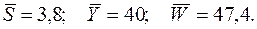
Далее определяем оценки параметров:
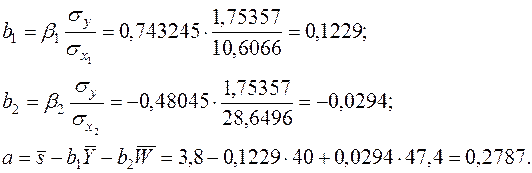
Эти значения оценок совпадают с оценками, полученными ранее.
Дата добавления: 2021-01-11; просмотров: 574;
Поиск по сайту
Узнать еще
- IV. Структурно-иерархическая модель личности Реймонда Кеттела
- R-плазмиды, функции, строение. Пути передачи. Механизм множественной лекарственной устойчивости.
- АВТОРИТАРНАЯ МОДЕЛЬ
- АДАПТИВНАЯ ИНТЕРПРЕТАЦИОННАЯ МОДЕЛЬ ННМ
- Адаптивное управление с авторегрессивной моделью
- Американская модель
- Анализ качества эмпирического уравнения множественной
- Аналитическая модель производительности дискового зубчатого бункерного загрузочного устройства с кольцевым ориентатором

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
