Работа с программой FineReader
Все операции, необходимые в ходе преобразования бумажного документа в электронную форму, могут быть выполнены с помощью программы FineReader (рис. 17.2). Эта программа способна выполнять сканирование и распознавание текстов на разных языках, в том числе и смешанных двуязычных текстов. С ее помощью можно выполнять пакетную обработку многостраничных документов, а также настраивать режим распознавания для улучшения соответствия электронного документа бумажному оригиналу при плохом качестве последнего или использовании в нем шрифтов, далеких от стандартных.
Основные операции обработки бумажного документа в программе FineReader выполняются с помощью панели инструментов Scan&Read. С точки зрения этой программы, процесс обработки документа состоит из пяти этапов:
• сканирование документа (кнопка Сканировать);
• сегментация документа (кнопка Сегментировать);
• распознавание документа (кнопка Распознать);
• редактирование и проверка результата (кнопка Проверить);
• сохранение документа (кнопка Сохранить).
Сканирование документа.На этапе сканирования производится получение изображений при помощи сканера и сохранение их в виде, удобном для последующей обработки. Чтобы начать сканирование, надо включить сканер и щелкнуть на кнопке Сканировать на панели инструментов Scan&Read. В программе FineReader сканирование может производиться как через драйвер TWAIN, так и в обход его. Первый способ используют, когда требуется точная настройка параметров сканирования, когда документ включает цветные иллюстрации, которые необходимо сохранить, а также когда разные страницы многостраничного документа сильно различаются по качеству. Второй вариант обеспечивает максимальную скорость и удобство сканирования. Выбор используемого варианта осуществляется при помощи флажка Показывать диалог TWAIN-драйвера сканера (Сервис > Опции > Сканирование).
Процесс сканирования осуществляется автоматически и требует от пользователя только вспомогательных операций, таких, как смена сканируемой страницы. Возможность вмешательства в работу программы заблокирована размещением на экране специального диалогового окна, уведомляющего о том, что идет сканирование, и позволяющего прервать это процесс.
По завершении сканирования значки всех обработанных страниц отображаются в окне Пакет. В основной части рабочей области появляется окно Изображение, содержащее изображение текущей страницы. Добавлять страницы в пакет можно не только путем сканирования, но и путем открытия файлов с изображениями, имеющихся на компьютере.
Сегментация документа.Второй этап работы — сегментация, разбиение страницы на блоки текста. Естественный порядок распознавания — по строкам, расположенным на странице сверху вниз и идущим от левого края до правого. Если страница содержит колонки, иллюстрации, врезки, подрисуночные подписи или таблицы, то порядок распознавания требует коррекции.
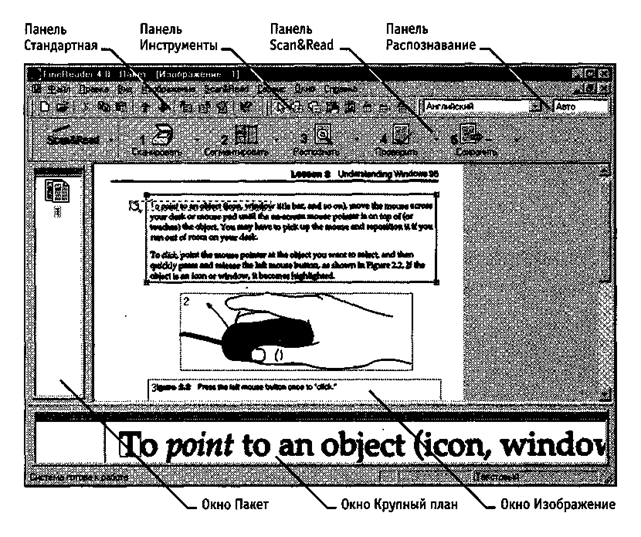
Рис. 17.2. Рабочее окно программы FineReader в процессе
распознавания отсканированного документа
Содержимое страницы разбивается на блоки, внутри каждого из которых распознавание осуществляется в естественном порядке. Блоки нумеруются, исходя из порядка включения их в документ. При автоматической сегментации (кнопка Сегментировать на панели инструментов Scan&Read) определение границ блоков осуществляется автоматически. При этом учитываются поля документа, просветы между колонками, рамки.
Если структура страницы очень сложная, удобнее использовать ручную сегментацию или ручное редактирование результатов автоматической сегментации. Блоки отображаются в виде цветных прямоугольников с номером в левом верхнем углу. Новый блок создают протягиванием мыши по диагонали прямоугольника. Текущий блок помечается выделенной линией, а его углы — прямоугольными маркерами. С помощью этих маркеров можно изменить размер или положение блока.
Команды редактирования блоков выведены на панель Инструменты. Они позволяют:
• объединить два блока в один (Добавить часть блока);
• удалить фрагмент блока (Удалить часть блока);
• изменить положение блоков (Переместить блоки);
• изменить порядок нумерации блоков (Перенумеровать блоки);
• изменить разбиение таблицы на ячейки (Добавить вертикаль, Добавить горизонталь, Удалить линии);
Разные типы блоков обрабатываются программой по-разному. Чтобы изменить тип блока, надо щелкнуть правой кнопкой мыши в его пределах и назначить новый тип с помощью меню Тип блока в контекстном меню. Программа FineReader поддерживает следующие типы блоков:
• текстовый (Текст) — на этапе распознавания преобразуется в текст;
• табличный (Таблица) — представляет собой набор ячеек, каждая из которых преобразуется в текст по отдельности;
• изображение (Картинка) — включается в документ без изменений как графическая иллюстрация, если формат сохранения преобразованного документа допускает вставные объекты;
• лишний (Нераспознаваемый) — игнорируется;
• содержащий штрих-код (Штрих-код) — распознается как штрих-код.
Распознавание текста. Процесс распознавания текста после сегментации начинается с щелчка на кнопке Распознать и полностью автоматизирован. В ходе процесса отображается диалоговое окно Распознавание, позволяющее прервать процесс. Кроме того, в этом окне отображаются сообщения, указывающие на наличие проблем при распознавании. Проблемы обычно вызываются неверными настройками или плохим качеством распознаваемого изображения. Если же дело в каких-то шрифтовых особенностях распознаваемого документа, применяют распознавание с обучением.
Распознавание с обучением. Распознавание с обучением состоит в формировании эталона, который используется в ходе распознавания в дальнейшем. Эталон настраивается так, чтобы соответствовать определенному документу или группе однотипных документов. Чтобы создать эталон, используют команду Сервис > Редактор эталонов > Новый эталон. После этого надо указать имя эталона и щелкнуть на кнопке ОК. Режим распознавания с обучением включается при настройке параметров работы программы (Сервис >Опции > Распознавание). На панели Обучение следует выбрать нужный эталон и установить флажок Распознавание с обучением.
Когда в ходе распознавания с обучением программа FineReader обнаруживает символ, который не может интерпретировать однозначно, на экран выдается диалоговое окно Ручное обучение эталона (рис. 17.3). Программа указывает элемент изображения, вызвавший сомнения, и показывает, как именно он будет интерпретирован. Если допущена ошибка, можно указать нужный символ в поле Символ или уточнить область распознавания с помощью кнопок Сдвинуть влево и Сдвинуть вправо.
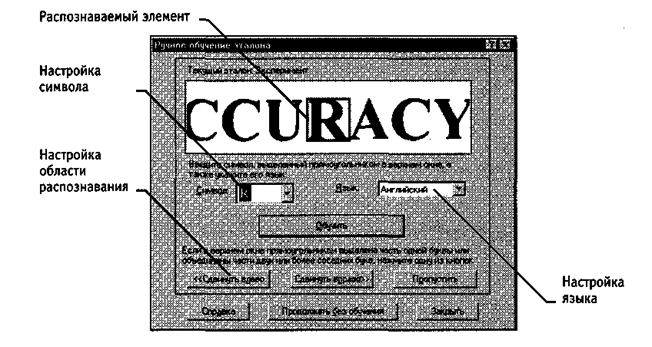
Рис. 17.3. Ручное «обучение» механизма распознавания текста
Затем надо щелкнуть на кнопке Обучить. Необходимые сведения сохраняются и используются при дальнейшем анализе изображения. Если число ошибок невелико, можно продолжить распознавание в обычном режиме щелчком на кнопке Продолжать без обучения.
Редактирование документа. Когда распознавание данной страницы завершается, полученный текстовый документ отображается в окне Текст. Заключительные этапы работы позволяют отредактировать полученный текст с помощью средств, напоминающих текстовый редактор WordPad (панель для форматирования открывается при помощи команды Вид > Панели инструментов > Форматирование). Провести проверку орфографии с учетом трудностей распознавания позволяет кнопка Проверить на панели инструментов Scan&Read.
Сохранение документа. По щелчку на кнопке Сохранить на панели инструментов Scan&Read запускается Мастер сохранения результатов. Он позволяет сохранить распознанный текст или передать его в другую программу (например, в Microsoft Word) для последующей обработки.
Обработка бланков
Бланки, или формы, представляют собой особый род документов. Они используются как анкеты, бюллетени для голосования, опросные листы и состоят из постоянной части, содержащей информацию, используемую в ходе заполнения бланка, и переменной части, куда при заполнении бланка заносятся данные. В ходе обработки бланков требуется получить внесенные в него данные и представить их в виде, удобном для дальнейшей обработки. При этом часто приходится иметь дело с тысячами однотипных бланков.
Для обработки бланков используется автономное приложение FineReader Forms. Процесс работы с бланками несколько отличается от работы с обычными документами. Вначале подготавливается шаблон, который содержит все постоянные и переменные зоны бланка. Этап сегментации заменяется наложением шаблона, то есть его совмещением с постоянными элементами бланка. Это позволяет определить местонахождение переменных элементов бланка и провести их распознавание. Данные, полученные с отдельного бланка, рассматриваются как строка таблицы или как отдельная запись базы данных. Содержимое отдельного поля бланка соответствует ячейке таблицы.
Для создания шаблона требуется электронное изображение отдельного бланка, хотя бы и незаполненного. Чтобы создать шаблон, надо в приложении FineReader Forms дать команду Файл > Новый, после чего указать имя пакета форм и папку для хранения отсканированных бланков. Затем необходимо отсканировать или выбрать готовое изображение, которое будет использоваться в качестве основы шаблона.
Сам процесс создания шаблона состоит в ручной сегментации бланка. При этом кроме окна Редактор шаблонов открыто также диалоговое окно Параметры. Следует определить как блоки, охватывающие фиксированные элементы бланка, так и те, которые содержат области, подлежащие заполнению. Блоки, соответствующие постоянным элементам, используются как приводные метки. Чтобы исключить такой блок из процесса распознавания, следует щелкнуть на нем правой кнопкой мыши и выбрать в контекстном меню команду Тип блока > Статический текст.
Параметры блока задают на вкладке Блок диалогового окна Параметры. Для каждого распознаваемого блока надо установить флажок Экспортируемый блок, а также указать имя поля базы данных. Информация из этого блока будет заноситься в указанное поле. После того как все нужные блоки созданы и настроены, следует щелкнуть на кнопке Закрыть на панели инструментов. При этом производится проверка, обеспечивают ли заданные блоки возможность однозначного наложения шаблона на бланк.
В результате сканирования заполненного бланка, наложения шаблона и распознавания, полученные данные представляются в виде формы, содержащей названия полей и данные, полученные при распознавании. Сохранение данных производят в формате, ориентированном на последующую обработку средствами электронных таблиц или баз данных, например, в виде электронной таблицы Excel (файл .XLS).
Дата добавления: 2016-09-26; просмотров: 6617;
Поиск по сайту
Узнать еще
- I.2.1 ПОЛНАЯ И ВНУТРЕННЯЯ ЭНЕРГИЯ СИСТЕМЫ. ТЕПЛОТА И РАБОТА
- I.3.1 РАБОТА. МОЩНОСТЬ
- I.4.3 РАБОТА. МОЩНОСТЬ. ЭНЕРГИЯ ВРАЩАТЕЛЬНОГО ДВИЖЕНИЯ
- II.Работа с Internet Explorer (проводник)
- III. 3 РАБОТА И ЭНЕРГИЯ. ЗАКОНЫ СОХРАНЕНИЯ
- MS Word. Выделение текста. Понятие фрагмента текста. Способы форматирования фрагментов, работа с фрагментами (копирование, удаление, перемещение).
- Window - работа с окнами.
- А) Совместная работа элементов турбокомпрессора высокого давления.

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
