A SIMPLE CONTEXT-FREE GRAMMAR
Let us consider an example of a context-free grammar for generating very simple English sentences. It uses the initial symbol S of a sentence to be generated and several other non-terminal symbols: the noun phrase symbol NP, verb phrase symbol VP, noun symbol N, verb symbol V, and determinant symbol D. All these non-terminal symbols are interpreted as grammatical categories.
Several production rules for replacement of a non-terminal symbol with a string of several other non-terminal symbols are used as the nucleus of any generative grammar. In our simple case, let the set of the rules be the following:
S® NPVP
VP ® V NP
NP® D N
NP® N
Each symbol at the right side of a rule is considered a constituent of the entity symbolized at the left side. Using these rules in any possible order, we can transform S to the strings DN V D N, or D N V N, or N V D N, or N V N, etc.
An additional set of rules is taken to convert all these non-terminal symbols to the terminal symbols corresponding to the given grammatical categories. The terminals are usual words of Spanish, English, or any other language admitting the same categories and the same word order. We use the symbol “|” as a metasymbol of an alternative (i.e. for logical OR). Let the rules be the following:
N ® estudiante | niña | María | canción | edificio...
V ® ve | canta | pregunta...
D ® el | la | una | mi | nuestro...
Applying these rules to the constituents of the non-terminal strings obtained earlier, we can construct a lot of fully grammatical and meaningful Spanish sentences like María ve el edificio (from N V D N) or la estudiante canta una canción (from DN V D N). Some meaningless and/or ungrammatical sentences likecanción ve el María can be generated too. With more complicate rules, some types of ungrammaticality can be eliminated. However, to fully get rid of potentially meaningless sentences is very difficult, since from the very beginning the initial symbol does not contain any specific meaning at all. It merely presents an abstract category of a sentence of a very vast class, and the resulting meaning (or nonsense) is accumulated systematically, with the development of each constituent.
On the initial stage of the elaboration of the generative approach, the idea of independent syntax arose and the problem of natural language processing was seen as determining the syntactic structure of each sentence composing a text. Syntactic structure of a sentence was identified with the so-called constituency tree. In other words, this is a nested structuresubdividing the sentence into parts, then these parts into smaller parts, and so on. This decomposition corresponds to the sequence of the grammar rules applications that generate the given sentence. For example, the Spanish sentence la estudiante canta una canción has the constituency tree represented graphically in Figure II.1. It also can be represented in the form of the following nested structure marked with square brackets:
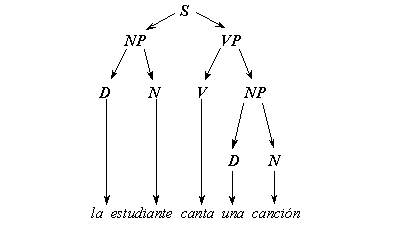 FIGURE II.1. Example of constituency tree.
FIGURE II.1. Example of constituency tree.
|
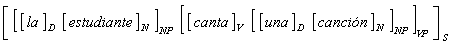
This structure shows the sentence S consisting of a noun phrase NP and a verb phrase VP, that in its turn consists of a verb V followed by a noun phrase NP, that in its turn consists of a determiner D (an articleor pronoun) followed by a noun N that is the word canción, in this case.
Дата добавления: 2016-09-06; просмотров: 1891;
Поиск по сайту
Узнать еще
- Bacteria Are Simple Cells
- BLOCK 2. SIMPLE COMMERCIAL LETTERS-2
- BLOCK 3. SIMPLE COMMERCIAL LETTERS-3
- Ex 2. Fill in the blanks with one of the following words. Mind your grammar
- Ex.2. Fill in the blanks with one of the following words. Mind your grammar.
- Ex.2. Fill in the blanks with one of the following words. Mind your grammar.
- FUNDAMENTAL CONCEPTS OF GRAMMAR.

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
