Статистические гипотезы
Формулирование гипотез систематизирует предположения исследователя и представляет их в четком и лаконичном виде. Благодаря гипотезам исследователь не теряет путеводной нити в процессе расчетов и ему легко понять после их окончания, что, собственно, он обнаружил.
Статистические гипотезы подразделяются на нулевые и альтернативные, направленные и ненаправленные.
Нулевая гипотеза - это гипотеза об отсутствии различий. Она обозначается как H0 и называется нулевой потому, что содержит число 0: X1- Х2=0, где X1, X2 - сопоставляемые значения признаков.
Нулевая гипотеза - это то, что мы хотим опровергнуть, если перед нами стоит задача доказать значимость различий.
Альтернативная гипотеза - это гипотеза о значимости различий. Она обозначается как H1. Альтернативная гипотеза - это то, что мы хотим доказать, поэтому иногда ее называют экспериментальной гипотезой.
Бывают задачи, когда мы хотим доказать как раз незначимость различий, то есть подтвердить нулевую гипотезу. Например, если нам нужно убедиться, что разные испытуемые получают хотя и различные, но уравновешенные по трудности задания, или что экспериментальная и контрольная выборки не различаются между собой по каким-то значимым характеристикам. Однако чаще нам все-таки требуется доказать значимость различий, ибо они более информативны для нас в поиске нового. Нулевая и альтернативная гипотезы могут быть направленными и ненаправленными.
Направленные гипотезы
H0: X1 не превышает Х2
H1: X1 превышает Х2
Ненаправленные гипотезы
H0: X1 не отличается от Х2
Н1: Х1 отличается от Х2
Если вы заметили, что в одной из групп индивидуальные значения испытуемых по какому-либо признаку, например по социальной смелости, выше, а в другой ниже, то для проверки значимости этих различий нам необходимо сформулировать направленные гипотезы.
Если мы хотим доказать, что в группе А под влиянием каких-то экспериментальных воздействий произошли более выраженные изменения, чем в группе Б, то нам тоже необходимо сформулировать направленные гипотезы.
Если же мы хотим доказать, что различаются формы распределения признака в группе А и Б, то формулируются ненаправленные гипотезы.
При описании каждого критерия в руководстве даны формулировки гипотез, которые он помогает нам проверить.
Построим схему - классификацию статистических гипотез.
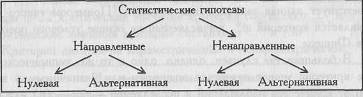
Проверка гипотез осуществляется с помощью критериев статистической оценки различий.
1.5. Статистические критерии
Статистический критерий - это решающее правило, обеспечивающее надежное поведение, то есть принятие истинной и отклонение ложной гипотезы с высокой вероятностью (Суходольский Г.В., 1972, с. 291).
Статистические критерии обозначают также метод расчета определенного числа и само это число.
Когда мы говорим, что достоверность различий определялась по критерию χ2, то имеем в виду, что использовали метод χ2 - для расчета определенного числа.
Когда мы говорим, далее, что χ2=12,676, то имеем в виду определенное число, рассчитанное по методу χ2. Это число обозначается как эмпирическое значение критерия.
По соотношению эмпирического и критического значений критерия мы можем судить о том, подтверждается ли или опровергается нулевая гипотеза. Например, если χ2эмп> χ2кр, H0 отвергается.
В большинстве случаев для того, чтобы мы признали различия значимыми, необходимо, чтобы эмпирическое значение критерия превышало критическое, хотя есть критерии (например, критерий Манна-Уитни или критерий знаков), в которых мы должны придерживаться противоположного правила.
Эти правила оговариваются в описании каждого из представленных в руководстве критериев.
В некоторых случаях расчетная формула критерия включает в себя количество наблюдений в исследуемой выборке, обозначаемое как п. В этом случае эмпирическое значение критерия одновременно является тестом для проверки статистических гипотез. По специальной таблице мы определяем, какому уровню статистической значимости различий соответствует данная эмпирическая величина. Примером такого критерия является критерий φ*, вычисляемый на основе углового преобразования Шишера.
В большинстве случаев, однако, одно и то же эмпирическое значение критерия может оказаться значимым или незначимым в зависимости от количества наблюдений в исследуемой выборке (n) или от так называемого количества степеней свободы, которое обозначается как v или как df.
Число степеней свободы v равно числу классов вариационного ряда минус число условий, при которых он был сформирован (Ивантер Э.В., Коросов А.В., 1992, с. 56). К числу таких условий относятся объем выборки (n), средние и дисперсии.
Если мы расклассифицировали наблюдения по классам какой-либо номинативной шкалы и подсчитали количество наблюдений в каждой ячейке классификации, то мы получаем так называемый частотный вариационный ряд. Единственное условие, которое соблюдается при его формировании - объем выборки п. Допустим, у нас 3 класса: "Умеет работать на компьютере - умеет выполнять лишь определенные операции - не умеет работать на компьютере". Выборка состоит из 50 человек. Если в первый класс отнесены 20 испытуемых, во второй - тоже 20, то в третьем классе должны оказаться все остальные 10 испытуемых. Мы ограничены одним условием - объемом выборки. Поэтому даже если мы потеряли данные о том, сколько человек не умеют работать на компьютере, мы можем определить это, зная, что в первом и втором классах - по 20 испытуемых. Мы не свободны в определении количества испытуемых в третьем разряде, "свобода" простирается только на первые две ячейки классификации:
v= c-l = 3-1 = 2
Аналогичным образом, если бы у нас была классификация из 10 разрядов, то мы были бы свободны только в 9 из них, если бы у нас было 100 классов - то в 99 из них и т. д.
Способы более сложного подсчета числа степеней свободы при двухмерных классификациях приведены в разделах, посвященных критерию χ2и дисперсионному анализу.
Зная n и/или число степеней свободы, мы по специальным таблицам можем определить критические значения критерия и сопоставить с ними полученное эмпирическое значение. Обычно это записывается так: "при n=22 критические значения критерия составляют ..." или "при v=2 критические значения критерия составляют ..." и т.п.
Критерии делятся на параметрические и непараметрические.
Параметрические критерии
Критерии, включающие в формулу расчета параметры распределения, то есть средние и дисперсии (t - критерий Стьюдента, критерий F и др.)
Непараметрические критерии
Критерии, не включающие в формулу расчета параметров распределения и основанные на оперировании частотами или рангами (критерий Q Розенбаума, критерий Т Вилкоксона и др.)
И те, и другие критерии имеют свои преимущества и недостатки. На основании нескольких руководств можно составить таблицу, позволяющую оценить возможности и ограничения тех и других (Рунион Р., 1982; McCall R., 1970; J.Greene, M.D'Olivera, 1989).
Таблица 1.1
Возможности и ограничения параметрических и непараметрических критериев
| ПАРАМЕТРИЧЕСКИЕ КРИТЕРИИ | НЕПАРАМЕТРИЧЕСКИЕ КРИТЕРИИ |
| 1. Позволяют прямо оценить различи* в средних, полученных в двух выборках (t - критерий Стьюдента). | Позволяют оценить лишь средние тенденции, например, ответить на вопрос, чаще ли в выборке А встречаются более высокие, а в выборке Б - более низкие значения признака (критерии Q, U, φ* и др.). |
| 2. Позволяют прямо оценить различия в дисперсиях (критерий Фишера). | Позволяют оценить лишь различия в диапазонах вариативности признака (критерий φ*). |
| 3. Позволяют выявить тенденции изме-нения признака при переходе от условия к условию (дисперсионный однофакторный анализ), но лишь при условии нормального распределения признака. | Позволяют выявить тенденции изменения признака при переходе от условия к условию при любом распределении признака (критерии тенденций L и S). |
| 4. Позволяют оценить взаимодействие двух и более факторов в их влиянии на изменения признака (двухфакторный дисперсионный анализ). | Эта возможность отсутствует. |
| 5. Экспериментальные данные должны отвечать двум, а иногда трем, условиям: а) значения признака измерены по интервальной шкале; б) распределение признака является нормальным; в) в дисперсионном анализе должно соблюдаться требование равенства дисперсий в ячейках комплекса. | Экспериментальные данные могут не отвечать ни одному из этих условий: а) значения признака могут быть представлены в любой шкале, начиная от шкалы наименований; б) распределение признака может быть любым и совпадение его с каким-либо теоретическим законом распределения необязательно и не нуждается в проверке; в) требование равенства дисперсий отсутствует. |
| 6. Математические расчеты довольно сложны. | Математические расчеты по большей части просты и занимают мало времени (за исключением критериев χ2и λ). |
| 7. Если условия, перечисленные в п.5, выполняются, параметрические критерии оказываются несколько более мощными, чем непараметрические. | Если условия, перечисленные в п.5, не выполняются, непараметрические критерии оказываются более мощными, чем параметрические, так как они менее чувствительны к "засорениям'. |
Из Табл. 1.1 мы видим, что параметрические критерии могут оказаться несколько более мощными[4], чем непараметрические, но только в том случае, если признак измерен по интервальной шкале и нормально распределен. С интервальной шкалой есть определенные проблемы (см. раздел "Шкалы измерения"). Лишь с некоторой натяжкой мы можем считать данные, представленные не в стандартизованных оценках, как интервальные. Кроме того, проверка распределения "на нормальность" требует достаточно сложных расчетов, результат которых заранее неизвестен (см. параграф 7.2). Может оказаться, что распределение признака отличается от нормального, и нам так или иначе все равно придется обратиться к непараметрическим критериям.
Непараметрические критерии лишены всех этих ограничений и нетребуют таких длительных и сложных расчетов. По сравнению с параметрическими критериями они ограничены лишь в одном - с их помощью невозможно оценить взаимодействие двух или более условий или факторов, влияющих на изменение признака. Эту задачу может решить только дисперсионный двухфакторный анализ.
Учитывая это, в настоящее руководство включены в основном непараметрические статистические критерии. В сумме они охватывают большую часть возможных задач сопоставления данных.
Единственный параметрический метод, включенный в руководство - метод дисперсионного анализа, двухфакторный вариант которого ничем невозможно заменить.
1.6. Уровни статистической значимости
Уровень значимости - это вероятность того, что мы сочли различия существенными, а они на самом деле случайны.
Когда мы указываем, что различия достоверны на 5%-ом уровне значимости, или при р<0,05, то мы имеем виду, что вероятность того, что они все-таки недостоверны, составляет 0,05.
Когда мы указываем, что различия достоверны на 1%-ом уровне значимости, или при р<0,01, то мы имеем в виду, что вероятность того, что они все-таки недостоверны, составляет 0,01.
Если перевести все это на более формализованный язык, то уровень значимости - это вероятность отклонения нулевой гипотезы, в то время как она верна.
Ошибка, состоящая в том, что мы отклонили нулевую гипотезу, в то время как она верна, называется ошибкой 1 рода.
Вероятность такой ошибки обычно обозначается какα. В сущности, мы должны были бы указывать в скобках не р≤0,05 или р≤0,01, а α≤0,05 или α≤0,01. В некоторых руководствах так и делается (Рунион Р., 1982; Захаров В.П., 1985 и др.).
Если вероятность ошибки - это α, то вероятность правильного решения: 1 — α. Чем меньше α, тем больше вероятность правильного решения.
Исторически сложилось так, что в психологии принято считать низшим уровнем статистической значимости 5%-ый уровень (р<0,05): достаточным - 1%-ый уровень (р<0,01) и высшим 0,1%-ый уровень (р<0,001), поэтому в таблицах критических значений обычно приводятся значения критериев, соответствующих уровням статистической значимости р<0,05 и р<0,01, иногда - р<0,001. Для некоторых критериев в таблицах указан точный уровень значимости их разных эмпирических значений. Например, для φ*=1,56 р=0,06.
До тех пор, однако, пока уровень статистической значимости не достигнет р=0,05, мы еще не имеем права отклонить нулевую гипотезу. В настоящем руководстве мы, вслед за Р. Рунионом (1982), будем придерживаться следующего правила отклонения гипотезы об отсутствии различий (H0) и принятия гипотезы о статистической достоверности различий (Н1).
Правило отклонения H0 и принятия H1
Если эмпирическое значение критерия равняется критическому значению, соответствующему р<0,05 или превышает его, то H0 отклоняется, но мы еще не можем определенно принять H1. Если эмпирическое значение критерия равняется критическому значению, соответствующему р<0,01 или превышает его, то H0 отклоняется и принимается H1.
Исключения: критерий знаков G, критерий Т Вилкоксона и критерий U Манна-Уитни. Для них устанавливаются обратные соотношения.
Для облегчения процесса принятия решения можно всякий раз вычерчивать "ось значимости".
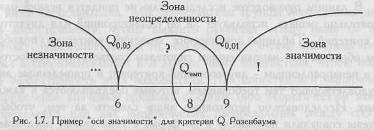
Критические значения критерия обозначены как Q0,05 и Q0,01, эмпирическое значение критерия как Qэмп. Оно заключено в эллипс.
Вправо от критического значения Q0,01 простирается "зона значимости" - сюда попадают эмпирические значения, превышающие Q0,01 и, следовательно, безусловно значимые.
Влево от критического значения Q0,05 простирается "зона незначимости", - сюда попадают эмпирические значения Q, которые ниже Q0,05, и, следовательно, безусловно незначимы.
Мы видим, что Q0,05=6; Q0,01=9; Qэмп =8
Эмпирическое значение критерия попадает в область между Q0,05 и Q0,01- Это зона "неопределенности": мы уже можем отклонить гипотезу о недостоверности различий (H0), но еще не можем принять гипотезы об их достоверности (H1).
Практически, однако, исследователь может считать достоверными уже те различия, которые не попадают в зону незначимости, заявив, что они достоверны при р<0,05, или указав точный уровень значимости полученного эмпирического значения критерия, например: р=0,02. С помощью таблиц Приложения 1 это можно сделать по отношению к критериям Н Крускала-Уоллиса, χ2, Фридмана, L Пейджа, φ* Фишера, А, Колмогорова.
Уровень статистической значимости или критические значения критериев определяются по-разному при проверке направленных и ненаправленных статистических гипотез.
При направленной статистической гипотезе используется односторонний критерий, при ненаправленной гипотезе - двусторонний критерий. Двусторонний критерий более строг, поскольку он проверяет различия в обе стороны, и поэтому то эмпирическое значение критерия, которое ранее соответствовало уровню значимости р<0,05, теперь соответствует лишь уровню р<0,10.
В данном руководстве исследователю не придется всякий раз самостоятельно решать, использует ли он односторонний или двухсторонний критерий. Таблицы критических значений критериев подобраны таким образом, что направленным гипотезам соответствует односторонний, а ненаправленным - двусторонний критерий, и приведенные значения удовлетворяют тем требованиям, которые предъявляются к каждому из них. Исследователю необходимо лишь следить за тем, чтобы его гипотезы совпадали по смыслу и по форме с гипотезами, предлагаемыми в описании каждого из критериев.
Мощность критериев
Мощность критерия - это его способность выявлять различия, если они есть. Иными словами, это его способность отклонить нулевую гипотезу об отсутствии различий, если она неверна.
Ошибка, состоящая в том, что мы приняли нулевую гипотезу, в то время как она неверна, называется ошибкой II рода.
Вероятность такой ошибки обозначается как β. Мощность критерия - это его способность не допустить ошибку II рода, поэтому:
Мощность=1—β
Мощность критерия определяется эмпирическим путем. Одни и те же задачи могут быть решены с помощью разных критериев, при этом обнаруживается, что некоторые критерии позволяют выявить различия там, где другие оказываются неспособными это сделать, или выявляют более высокий уровень значимости различий. Возникает вопрос: а зачем же тогда использовать менее мощные критерии? Дело в том, что основанием для выбора критерия может быть не только мощность, но и другие его характеристики, а именно:
а) простота;
б) более широкий диапазон использования (например, по отношению к данным, определенным по номинативной шкале, или по отношению к большим n);
в) применимость по отношению к неравным по объему выборкам;
г) большая информативность результатов.
1.8. Классификация задач и методов их решения
Множество задач психологического исследования предполагает те или иные сопоставления. Мы сопоставляем группы испытуемых по какому-либо признаку, чтобы выявить различия между ними по этому признаку. Мы сопоставляем то, что было "до" с тем, что стало "после" наших экспериментальных или любых иных воздействий, чтобы определить эффективность этих воздействий. Мы сопоставляем эмпирическое распределение значений признака с каким-либо теоретическим законом распределения или два эмпирических распределения между собой, с тем, чтобы доказать неслучайность выбора альтернатив или различия в форме распределений.
Мы, далее, можем сопоставлять два признака, измеренные на одной и той же выборке испытуемых, для того, чтобы установить степень согласованности их изменений, их сопряженность, корреляцию между ними.
Наконец, мы можем сопоставлять индивидуальные значения, полученные при разных комбинациях каких-либо существенных условий, с тем чтобы выявить характер взаимодействия этих условий в их влиянии на индивидуальные значения признака.
Именно эти задачи позволяет решить тот набор методов, который предлагается настоящим руководством. Все эти методы могут быть использованы при так называемой "ручной" обработке данных.
Краткая классификация задач и методов дана в Таблице 1.2.
Таблица 1.2
| Классификация задач | и методов их решения | |
| Задачи | Условия | Методы |
| 1. Выявление различий в уровне исследуемого признака | а) 2 выборки испытуемых | Q - критерий Розенбаума; U - критерий Манна-Уитни; φ* - критерий (угловое преобразование Фишера) |
| б) 3 и более выборок испытуемых | S - критерий тенденций Джонкира; Н - критерий Крускала-Уоллиса. | |
| 2. Оценка сдвига значений исследуемого признака | а) 2 замера на одной и той же выборке испытуемых | Т - критерий Вилкоксона; G - критерий знаков; φ* - критерий (угловое преобразование Фишера). |
| б) 3 и более замеров на одной и той же выборке испытуемых | χл2 - критерий Фридмана; L - критерий тенденций Пейджа. | |
| 3. Выявление различий в распределении | а) при сопоставлении эмпирического признака распределения с теоретическим | χ2 - критерий Пирсона; λ - критерий Колмогорова-Смирнова; m - биномиальный критерий. |
| б) при сопоставлении двух эмпирических распределений | χ2 - критерий Пирсона; λ - критерий Колмогорова-Смирнова; φ* - критерий (угловое преобразование Фишера). | |
| 4.Выявление степени согласованности изменений | а) двух признаков | rs - коэффициент ранговой корреляции Спирмена. |
| б) двух иерархий или профилей | rs - коэффициент ранговой корреляции Спирмена. | |
| 5. Анализ изменений признака под влиянием контролируемых условий | а) под влиянием одного фактора | S - критерий тенденций Джонкира; L - критерий тенденций Пейджа; однофакторный дисперсионный анализ Фишера. |
| б) под влиянием двух факторов одновременно | Двухфакторный дисперсионный анализ Фишера. |
1.9. Принятие решения о выборе метода математической обработки
Если данные уже получены, то вам предлагается следующий алгоритм определения задачи и метода.
АЛГОРИТМ 1
Принятие решения о задаче и методе обработки на стадии, когда данные уже получены
1. По первому столбцу Табл. 1.2 определить, какая из задач стоит в вашем исследовании.
2. По второму столбцу Табл. 1.2 определить, каковы условия решения вашей задачи, например, сколько выборок обследовано или на какое количество групп вы можете разделить обследованную выборку.
3. Обратиться к соответствующей главе и по алгоритму принятия решения о выборе критерия, приведенного в конце каждой главы, определить, какой именно метод или критерий вам целесообразно использовать.
Если вы еще находитесь на стадии планирования исследования, то лучшее заранее подобрать математическую модель, которую вы будете в дальнейшем использовать. Особенно необходимо планирование в тех случаях, когда в перспективе предполагается использование критериев тенденций или (в еще большей степени) дисперсионного анализа. , В этом случае алгоритм принятия решения таков:
АЛГОРИТМ 2
Принятие решения о задаче и методе обработки на стадии планирования исследования
1. Определите, какая модель вам кажется наиболее подходящей для доказательства] ваших научных предположений.
2. Внимательно ознакомьтесь с описанием метода, примерами и задачами для самостоятельного решения, которые к нему прилагаются.
3. Если вы убедились, что это то, что вам нужно, вернитесь к разделу "Ограничения критерия" и решите, сможете ли вы собрать данные, которые будут отвечать этим ограничениям (большие объемы выборок, наличие нескольких выборок, монотонно различающихся по какому-либо признаку, например, по возрасту и т.п.).
4. Проводите исследование, а затем обрабатывайте полученные данные по заранее! выбранному алгоритму, если вам удалось выполнить ограничения.
5. Если ограничения выполнить не удалось, обратитесь к алгоритму 1.
В описании каждого критерия сохраняется следующая последовательность изложения:
· назначение критерия;
· описание критерия;
· гипотезы, которые он позволяет проверить;
· графическое представление критерия;
· ограничения критерия;
· пример или примеры.
Кроме того, для каждого критерия создан алгоритм расчетов. Если критерий сразу удобнее рассчитывать по алгоритму, то он приводится в разделе "Пример"; если алгоритм легче можно воспринять уже после рассмотрения примера, то он приводится в конце параграфа, соответствующего данному критерию.
1.10. Список обозначений
Латинские обозначения:
А - показатель асимметрии распределения
с - количество групп или условий измерения
d - разность между рангами, частотами или частостями
df - число степеней свободы в дисперсионном анализе
Е - показатель эксцесса
F - критерий Фишера для сравнения дисперсий
f - частота
f* - частость, или относительная частота
G - критерий знаков
Н - критерий Крускала-Уоллиса
i - индекс, обозначающий порядковый номер наблюдения
j - индекс, обозначающий порядковый номер разряда, класса, группы
k - количество классов или разрядов признака
L - критерий тенденций Пейджа
М - среднее значение признака или средняя арифметическая; то же, что и х
m - биномиальный критерий
n - количество наблюдений (испытуемых, реакций, выборов и т.п.)
N - общее количество наблюдений в двух или более выборках
Р - вероятность того, что событие произойдет
р - вероятность ошибки 1 рода (то же, что и а), уровень статистической значимости
Q - 1) вероятность того, что событие не произойдет; 2) критерий Розенбаума
rs - коэффициент ранговой корреляции Спирмена
S - критерий Джонкира
S2 - оценка дисперсии
Si - количество значений, которые выше или ниже данного значения
SS - суммы квадратов (в дисперсионном анализе)
Т - критерий Вилкоксона
Тс - суммы рангов по столбцам
Тк - большая сумма рангов в критерии U
U - критерий Манна-Уитни
Wn - размах вариативности, или диапазон значений от наименьшего до
наибольшего
хi - текущее наблюдение; каждое наблюдение по порядку
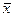 - среднее значение признака (то же, что и М)
- среднее значение признака (то же, что и М)
Греческие обозначения:
α (альфа) - вероятность ошибки I рода (отклонения H0, которая верна)
β (бета) - вероятность ошибки II рода (принятия H0, которая неверна)
λ, (ламбда) - критерий Колмогорова-Смирнова
v (ню) - число степеней свободы в непараметрических критериях
σ (сигма) - стандартное отклонение
φ (фи) - центральный угол, определяемый по процентной доле в критерии φ*
φ* (фи) - критерий Фишера с угловым преобразованием
χ2 (хи-квадрат) - критерий Пирсона
χ2r (хи-ар-квадрат) - критерий Фридмана.
Дата добавления: 2020-08-31; просмотров: 1264;
Поиск по сайту
Узнать еще
- Абсолютные и относительные статистические показатели
- Абсолютные и относительные статистические показатели
- Автоматизированные аналитико-статистические информационные системы, системы учета и управления
- Вариационные (статистические) ряды
- Вторая и третья гипотезы прочности
- Выделяют следующие методы РУР: аналитические, статистические, математического программирования, эвристические, активизирующие, экспертные, методы сценариев и метод дерева решений.
- Г. Статистические материалы
- Гипотезы исследования

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
