ВЫЯВЛЕНИЕ РАЗЛИЧИЙ В УРОВНЕ ИССЛЕДУЕМОГО ПРИЗНАКА
2.1. Обоснование задачи сопоставления и сравнения
Очень часто перед исследователем в психологии стоит задача выявления различий между двумя, тремя и более выборками испытуемых. Это может быть, например, задача определения психологических особенностей хронически больных детей по сравнению со здоровыми, юных правонарушителей по сравнению с законопослушными сверстниками или различий между работниками государственных предприятий и частных фирм, между людьми разной национальности или разной культуры и, наконец, между людьми разного возраста в методе "поперечных срезов".
Иногда по выявленным в исследовании статистически достоверным различиям формируется "групповой профиль" или "усредненный портрет" человека той или иной профессии, статуса, соматического заболевания и др. (см., например, Cattell R.B., Eber H.W., Tatsuoka М.М., 1970).
В последние годы все чаще встает задача выявления психологического портрета специалиста новых профессий: "успешного менеджера", "успешного политика", "успешного торгового представителя", "успешного коммерческого директора" и др. Такого рода исследования не всегда подразумевают участие двух или более выборок. Иногда обследуется одна, но достаточно представительная выборка численностью не менее 60 человек, а затем внутри, этой выборки выделяются группы более и менее успешных специалистов, и их данные по исследованным переменным сопоставляются между собой. В самом простом случае критерием для разделения выборки на "успешных" и "неуспешных" будет средняя величина по показателю успешности. Однако такое деление является довольно грубым: лица, получившие близкие оценки по успешности, могут оказаться в противоположных группах, а лица, заметно различающиеся по оценкам успешности, - в одной и той же группе.
Это может исказить результаты сопоставления групп или по крайней мере сделать различия между группами менее заметными.
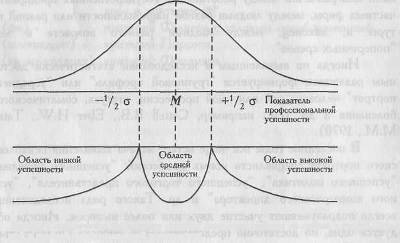
Чтобы избежать этого, можно попробовать выделить группы "успешных" и "неуспешных" специалистов более строго, включая в первую из них только тех, чьи значения превышают среднюю величину не менее чем на 1/4 стандартного отклонения, а во вторую группу - только тех, чьи значения не менее чем на 1/4 стандартного отклонения ниже средней величины. При этом все, кто оказывается в зоне средних величин, М±1/4 σ, выпадают из дальнейших сопоставлений. Если распределение близко к нормальному, то выпадет примерно 19,8% испытуемых. Если распределение отличается от нормального, то таких испытуемых может быть и больше. Чтобы избежать потерь, можно сопоставлять не две, а три группы испытуемых: с высокой, средней и низкой профессиональной успешностью.
(30,9% испытуемых) (38,2% испытуемых) (30,9% испытуемых)
Рис 2.1. Схематическое изображение процесса разделения выборки на группы с низкой, средней и высокой профессиональной успешностью
На Рис. 2.1 представлена схема разделения выборки на группы с низкой, средней и высокой профессиональной успешностью по критерию отклонения значений от средней величины на 1/2 стандартного отклонения. При таком строгом критерии в "среднюю" группу попадают (при нормальном распределении) около 38,2% всех испытуемых, а в крайних группах оказывается по 30,9% испытуемых.
Чем меньше испытуемых оказывается в группах, тем меньше у нас возможностей для выявления достоверных различий, так как критические значения большинства критериев при малых п строже, чем при больших п.
Таким образом, при нестрогом разделении испытуемых на группы мы теряем в точности, а при строгом - в количестве испытуемых.
При решении задач выявления различий в уровневых показателях следует помнить, что "усредненный профиль успешного специалиста" должен рассматриваться скорее как исследовательский результат, позволяющий сформулировать гипотезы для дальнейших исследований, а не как основание для профессионального отбора. Тому есть две причины. Во-первых, ни у одного из успешных специалистов может не наблюдаться "усредненный профиль" - он, в сущности, является отвлеченным обобщением; во-вторых, в профессиональной деятельности наличие собственного индивидуального стиля важнее соответствия "среднегрупповому" профилю. Недостаток в тех качествах, которые могут казаться важными, компенсируется другими качествами. У каждого успешного специалиста его психологические свойства создают неповторимый ансамбль, который при усреднении данных теряется.
Р.Б. Кеттелл, учитывая это, предлагал при исследовании профессиональной успешности включать в рассмотрение индивидуальные профили выдающихся представителей той или иной профессии (Cattell R.B., Eber H.W., Tatsuoka М.М., 1970).
Сопоставление уровневых показателей в разных выборках может быть необходимой частью комплексных диагностических, учебных, пси-хокоррекционных и иных программ. Оно помогает нам обратить внимание на те особенности обследованных выборок, которые должны быть учтены и использованы при адаптации программ к данной группе в процессе их конкретного воплощения.
Критерии, которые рассматриваются в данной главе, предполагают, что мы сопоставляем так называемые независимые выборки, то есть две или более выборки, состоящие из разных испытуемых. Тот испытуемый, который входит в одну выборку, уже не может входить в другую. В противоположность этому, если мы обследуем одну и ту же выборку испытуемых, несколько раз подвергая ее аналогичным измерениям ("замерам"), то перед нами - так называемые связанные, или зависимые, выборки данных. Сопоставление 2-х или более замеров, полученных на одной и той же выборке, рассматривается в Главе 3.
Решение о выборе того или иного критерия принимается на основе того, сколько выборок сопоставляется и каков их объем (см. Алгоритм 7 в конце главы).
2.2. Q - критерий Розенбаума
Назначение критерия
Критерий используется для оценки различий между двумя выборками по уровню какого-либо признака, количественно измеренного. В каждой из выборок должно быть не менее 11 испытуемых.
Описание критерия
Это очень простой непараметрический критерий, который позволяет быстро оценить различия между двумя выборками по какому-либо признаку. Однако если критерий Q не выявляет достоверных различий, это еще не означает, что их действительно нет.
В этом случае стоит применить критерий φ* Фишера. Если же Q-критерий выявляет достоверные различия между выборками с уровнем значимости р<0,01, можно ограничиться только им и избежать трудностей применения других критериев.
Критерий применяется в тех случаях, когда данные представлены по крайней мере в порядковой шкале. Признак должен варьировать в каком-то диапазоне значений, иначе сопоставления с помощью Q -критерия просто невозможны. Например, если у нас только 3 значения признака, 1, 2 и 3, - нам очень трудно будет установить различия. Метод Розенбаума требует, следовательно, достаточно тонко измеренных признаков.
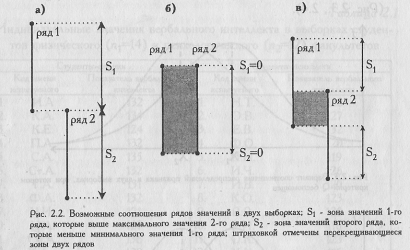
Применение критерия начинаем с того, что упорядочиваем значения признака в обеих выборках по нарастанию (или убыванию) признака. Лучше всего, если данные каждого испытуемого представлены на отдельной карточке. Тогда ничего не стоит упорядочить два ряда значений по интересующему нас признаку, раскладывая карточки на столе. Так мы сразу увидим, совпадают ли диапазоны значений, и если нет, то насколько один ряд значений "выше" (S1), а второй - "ниже" (S2). Для того, чтобы не запутаться, в этом и во многих других критериях рекомендуется первым рядом (выборкой, группой) считать тот ряд, где значения выше, а вторым рядом - тот, где значения ниже.
Гипотезы
H0: Уровень признака в выборке 1 не превышает уровня признака в выборке 2.
H1: Уровень признака в выборке 1 превышает уровень признака в выборке 2.
Графическое представление критерия Q
На Рис. 2.2. представлены три варианта соотношения рядов значений в двух выборках. В варианте (а) все значения первого ряда выше всех значений второго ряда. Различия, безусловно, достоверны, при соблюдении условия, что n1, n2≥11.
В варианте (б), напротив, оба ряда находятся на одном и том же уровне: различия недостоверны. В варианте (в) ряды частично перекрещиваются, но все же первый ряд оказывается гораздо выше второго. Достаточно ли велики зоны S1 и S2, в сумме составляющие Q, можно определить по Таблице I Приложения 1, где приведены критические значения Q для разных п. Чем величина Q больше, тем более достоверные различия мы сможем констатировать.
Ограничения критерия Q
1. В каждой из сопоставляемых выборок должно быть не менее 11 наблюдений. При этом объемы выборок должны примерно совпадать. Е.В. Гублером указываются следующие правила:
а) если в обеих выборках меньше 50 наблюдений, то абсолютная величина разности между n1 и n2 не должна быть больше 10 наблюдений;
б) если в каждой из выборок больше 51 наблюдения, но меньше 100, то абсолютная величина разности между щ и Л2 не должна быть больше 20 наблюдений;
в) если в каждой из выборок больше 100 наблюдений, то допускается, чтобы одна из выборок была больше другой не более чем в 1,5-2 раза (Гублер Е.В., 1978, с. 75).
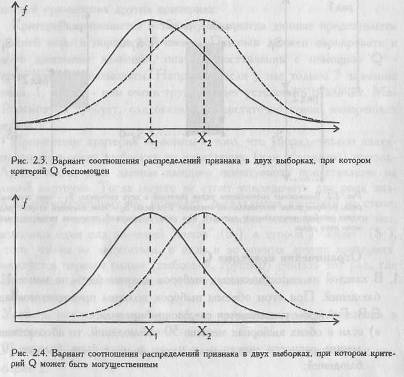
2. Диапазоны разброса значений в двух выборках должны не совпадать между собой, в противном случае применение критерия бессмысленно. Между тем, возможны случаи, когда диапазоны разброса значений совпадают, но, вследствие разносторонней асимметрии двух распределений, различия в средних величинах признаков существенны (Рис. 2.3., 2.4).
Пример
У предполагаемых участников психологического эксперимента, моделирующего деятельность воздушного диспетчера, был измерен уровень вербального и невербального интеллекта с помощью методики Д. Векслера. Было обследовано 26 юношей в возрасте от 18 до 24 лет (средний возраст 20,5 лет). 14 из них были студентами физического факультета, а 12 - студентами психологического факультета Ленинградского университета (Сидоренко Е.В., 1978). Показатели вербального интеллекта представлены в Табл. 2.1.
Можно ли утверждать, что одна из групп превосходит другую по уровню вербального интеллекта?
Таблица 2.1
Индивидуальные значения вербального интеллекта в выборках студентов физического (n1=14) и психологического (n2=12) факультетов
| Студе | нты-физики | Студенты - психологи | |||
| Код имени испытуемого | Показатель вербального интеллекта | Код имени испытуемого | Показатель вербального интеллекта | ||
| 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. | И.А К.А. К.Е. П.А. С.А. Ст.А. Т.А. Ф.А. Ч.И. Ц.А. См.А. К.Ан. Б.Л. Ф.В. | 1. 2. 3. 4. 5. 6. 7. 8. 9. | н.т. о.в. Е.В. Ф.О. и.н. и.ч. и.в. К.О. p.p. Р.И. O.K. н.к. |
Упорядочим значения в обеих выборках, а затем сформулируем гипотезы:
H0: Студенты-физики не превосходят студентов-психологов по уровню вербального интеллекта.
H1: Студенты-физики превосходят студентов-психологов по уровню вербального интеллекта.
Таблица 2.2
Упорядоченные по убыванию вербального интеллекта ряды индивидуальных значений в двух студенческих выборках
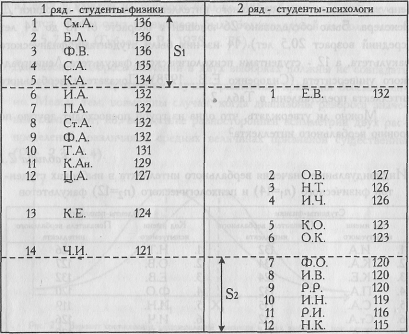
Как видно из Табл. 2.2, мы правильно обозначили ряды: первый, тот, что "выше" - ряд физиков, а второй, тот, что "ниже" - ряд психологов.
По Табл. 2.2 определяем количество значений первого ряда, которые больше максимального значения второго ряда: S1=5.
Теперь определяем количество значений второго ряда, которые меньше минимального значения первого ряда: S2=6.
Вычисляем QЭМП по формуле:
QЭМN=S1+S2=5+6=ll
По Табл.II Приложения 1 определяем критические значения Q для n1=14, n2=12:
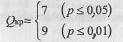
Ясно, что чем больше расхождения между выборками, тем больше величина Q. Но отклоняется при Qэмп>Qкp, а при Qэмп <Qкp мы будем вынуждены принять Но.
Построим "ось значимости".
Принимается H1. Студенты-физики превосходят студентов-психологов по уровню вербального интеллекта (р<0,01). Отметим, что в тех случаях, когда эмпирическая величина критерия оказывается на границе зоны незначимости, мы имеем право утверждать лишь, что различия достоверны при р<0,05, если же оно оказывается между двумя критическими значениями, то мы можем утверждать, что р< 0,05.
Если эмпирическое значение критерия оказывается на границе зоны значимости, р<0,01, в зоне значимости - что р<0,01
Поскольку уровень значимости выявленных различий достаточно высок (р<0,01), мы могли бы на этом остановиться. Однако если исследователь сам психолог, а не физик, вряд ли он на этом остановится. Он может попробовать сопоставить выборки по уровню невербального интеллекта, поскольку именно невербальный интеллект определяет уровень интеллекта в целом и степень его организованности (см., например: Бергер М.А., Логинова НА., 1974).
Мы вернемся к этому примеру при рассмотрении критерия Манна-Уитни и попытаемся ответить на вопрос о соотношении уровней невербального интеллекта в двух выборках. Быть может, психологи еще окажутся в более высоком ряду!
АЛГОРИТМ 3
Подсчет критерия Q Розенбаума
1. Проверить, выполняются ли ограничения: n1•n2≥11, n1 n2≈n2Упорядочить значения отдельно в каждой выборке по степени возрастания признака. Считать выборкой 1 ту выборку, значения в которой предположительно выше, а выборкой 2 - ту, где значения предположительно ниже.
3. Определить самое высокое (максимальное) значение в выборке 2.
4. Подсчитать количество значений в выборке 1, которые выше максимального значения в выборке 2. Обозначить полученную величину как S1.
5. Определить самое низкое (минимальное) значение в выборке 1.
6. Подсчитать количество значений в выборке 2, которые ниже минимального значения выборки 1. Обозначить полученную величину как S2.
7. Подсчитать эмпирическое значение Q по формуле: Q=S1+S2-
8. По Табл. I Приложения I определить критические значения Q для данных n1 и n2. Если Qэмп равно Q0,05 или превышает его, Н0 отвергается.
9. При n1•n2>26сопоставить полученное эмпирическое значение с Qкp=8 (р≤0,05) и Qкp=10(p≤0,01). Если Qэмп превышает или по крайней мере равняется Qкp=8, H0 отвергается.
2.3. U - критерий Манна-Уитни
Назначение критерия
Критерий предназначен для оценки различий между двумя выборками по уровню какого-либо признака, количественно измеренного. Он позволяет выявлять различия между малыми выборками, когда n1•n2≥3 или n1=2, n2≥5, и является более мощным, чем критерий Розенбаума.
Описание критерия
Существует несколько способов использования критерия и несколько вариантов таблиц критических значений, соответствующих этим способам (Гублер Е. В., 1978; Рунион Р., 1982; Захаров В. П., 1985; McCall R., 1970; Krauth J., 1988).
Этот метод определяет, достаточно ли мала зона перекрещивающихся значений между двумя рядами. Мы помним, что 1-м рядом (выборкой, группой) мы называем тот ряд значений, в котором значения, по предварительной оценке, выше, а 2-м рядом - тот, где они предположительно ниже.
Чем меньше область перекрещивающихся значений, тем более вероятно, что различия достоверны. Иногда эти различия называют различиями в расположении двух выборок (Welkowitz J. et al., 1982).
Эмпирическое значение критерия U отражает то, насколько велика зона совпадения между рядами. Поэтому чем меньше Uэмп, тем более вероятно, что различия достоверны.
Гипотезы
Н0: Уровень признака в группе 2 не ниже уровня признака в группе 1.
H1: Уровень признака в группе 2 ниже уровня признака в группе 1.
Графическое представление критерия U
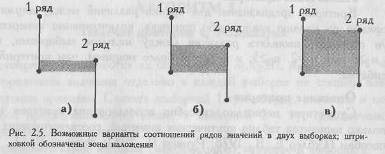
На Рис. 2.5. представлены три из множества возможных вариантов соотношения двух рядов значений.
В варианте (а) второй ряд ниже первого, и ряды почти не перекрещиваются. Область наложения слишком мала, чтобы скрадывать различия между рядами. Есть шанс, что различия между ними достоверны. Точно определить это мы сможем с помощью критерия U.
В варианте (б) второй ряд тоже ниже первого, но и область перекрещивающихся значений у двух рядов достаточно обширна. Она может еще не достигать критической величины, когда различия придется признать несущественными. Но так ли это, можно определить только путем точного подсчета критерия U.
В варианте (в) второй ряд ниже первого, но область наложения настолько обширна, что различия между рядами скрадываются.
Ограничения критерия U
1. В каждой выборке должно быть не менее 3 наблюдений: n1•n2≥3; допускается, чтобы в одной выборке было 2 наблюдения, но тогда во второй их должно быть не менее 5.
2. В каждой выборке должно быть не более 60 наблюдений; n1•n2≤60. Однако уже при n1•n2>20 ранжирование становиться достаточно трудоемким.
На наш взгляд, в случае, если n1•n2>20, лучше использовать другой критерий, а именно угловое преобразование Фишера в комбинации с критерием λ,, позволяющим выявить критическую точку, в которой накапливаются максимальные различия между двумя сопоставляемыми выборками (см. п. 5.4). .Формулировка звучит сложно, но сам метод достаточно прост. Каждому исследователю лучше попробовать разные пути и выбрать тот, который кажется ему более подходящим.
Пример
Вернемся к результатам обследования студентов физического и психологического факультетов Ленинградского университета с помощью методики Д. Векслера для измерения вербального и невербального интеллекта. С помощью критерия Q Розенбаума мы в предыдущем параграфе смогли с высоким уровнем значимости определить, что уровень вербального интеллекта в выборке студентов физического факультета выше. Попытаемся установить теперь, воспроизводится ли этот результат при сопоставлении выборок по уровню невербального интеллекта. Данные приведены в Табл. 2.3.
Можно ли утверждать, что одна из выборок превосходит другую по уровню невербального интеллекта?
Таблица 2.3
Индивидуальные значения невербального интеллекта в выборках студентов физического (щ=\4) и психологического (п2=12) факультетов
| Студенты-физики | Студенты-психологи | ||||
| Код имени испытуемого | Показатель невербального интеллекта | Код имени испытуемого | Показатель невербального интеллекта | ||
| 1. | И.А. | 1. | Н.Т. | ИЗ | |
| 2. | К.А. | 2. | О.В. | ||
| 3. | К.Е. | 3. | Е.В. | ||
| 4. | П.А. | 4. | Ф.О. | ||
| 5. | С.А. | 5. | И.Н. | ||
| 6. | Ст.А. | 6. | И.Ч. | ||
| 7. | Т.А. | 7. | И.В. | ||
| 8. | Ф.А. | 8. | К.О. | ||
| 9. | Ч.И. | 9. | P.P. | ||
| 10. | ЦА. | 10. | Р.И. | ||
| 11. | См.А. | 11. | O.K. | ||
| 12. | К.Ан. | 12. | Н.К. | ||
| 13. | Б.Л. | ||||
| 14. | Ф.В. |
Критерий U требует тщательности и внимания. Прежде всего, необходимо помнить правила ранжирования.
Правила ранжирования
1. Меньшему значению начисляется меньший ранг. Наименьшему значению начисляется ранг 1.
Наибольшему значению начисляется ранг, соответствующий количеству ранжируемых значений. Например, если n=7, то наибольшее значение получит ранг 7, за возможным исключением для тех случаев, которые предусмотрены правилом 2.
2. В случае, если несколько значений равны, им начисляется ранг, представляющий собой среднее значение из тех рангов, которые они получили бы, если бы не были равны.
Например, 3 наименьших значения равны 10 секундам. Если бы мы измеряли время более точно, то эти значения могли бы различаться и составляли бы, скажем, 10,2 сек; 10,5 сек; 10,7 сек. В этом случае они получили бы ранги, соответственно, 1, 2 и 3. Но поскольку полученные нами значения равны, каждое из них получает средний ранг:
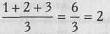
Допустим, следующие 2 значения равны 12 сек. Они должны были бы получить ранги 4 и 5, но, поскольку они равны, то получают средний ранг:
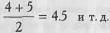
3. Общая сумма рангов должна совпадать с расчетной, которая определяется по формуле:
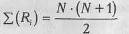
где N - общее количество ранжируемых наблюдений (значений). Несовпадение реальной и расчетной сумм рангов будет свидетельствовать об ошибке, допущенной при начислении рангов или их суммировании. Прежде чем продолжить работу, необходимо найти ошибку и устранить ее.
При подсчете критерия U легче всего сразу приучить себя действовать по строгому алгоритму.
АЛГОРИТМ 4
Подсчет критерия U Манна-Уитни.
1. Перенести все данные испытуемых на индивидуальные карточки.
2. Пометить карточки испытуемых выборки 1 одним цветом, скажем красным, а все карточки из выборки 2 - другим, например синим.
3. Разложить все карточки в единый ряд по степени нарастания признака, не считаясь с тем, к какой выборке они относятся, как если бы мы работали с одной большой выборкой.
4. Проранжировать значения на карточках, приписывая меньшему значению меньший ранг. Всего рангов получится столько, сколько у нас (n1+п2).
5. Вновь разложить карточки на две группы, ориентируясь на цветные обозначения: красные карточки в один ряд, синие - в другой.
6. Подсчитать сумму рангов отдельно на красных карточках (выборка 1) и на синих карточках (выборка 2). Проверить, совпадает ли общая сумма рангов с расчетной.
7. Определить большую из двух ранговых сумм.
8. Определить значение U по формуле:
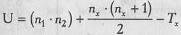
где n1 - количество испытуемых в выборке 1;
n2 - количество испытуемых в выборке 2;
Тх - большая из двух ранговых сумм;
nх - количество испытуемых в группе с большей суммой рангов.
9. Определить критические значения U по Табл. II Приложения 1. Если Uэмп.>Uкp 005, Но принимается. Если Uэмп≤Uкp_005, Но отвергается. Чем меньше значения U, тем достоверность различий выше.
Теперь проделаем всю эту работу на материале данного примера. В результате работы по 1-6 шагам алгоритма построим таблицу.
Таблица 2.4
Подсчет ранговых сумм по выборкам студентов физического и психа-логического факультетов
| Студенты-физики (n1=14) | Студенты-психологи (n2=12) | |||
| Показатель невербального интеллекта | Ранг | Показатель невербального интеллекта | Ранг | |
| 20,5 | ||||
| 20,5 | ||||
| 15,5 | 15.5 | |||
| 14' | ||||
| 11.5 | 11,5 | |||
| 11,5 | ||||
| 11,5 | ||||
| 6.5 | 6,5 | |||
| 4,5 | 4,5 | |||
| Суммы | ||||
| Средние | 107,2 | 111,5 |
Общая сумма рангов: 165+186=351. Расчетная сумма:
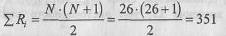
Равенство реальной и расчетной сумм соблюдено.
Мы видим, что по уровню невербального интеллекта более "высоким" рядом оказывается выборка студентов-психологов. Именно на эту выборку приходится большая ранговая сумма: 186.
Теперь мы готовы сформулировать гипотезы:
H0: Группа студентов-психологов не превосходит группу студентов-физиков по уровню невербального интеллекта.
Н1: Группа студентов-психологов превосходит группу студентов-физиков по уровню невербального интеллекта.
В соответствии со следующим шагом алгоритма определяем эмпирическую величину U:
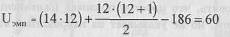
Поскольку в нашем случае п\Фп2, подсчитаем эмпирическую величину U и для второй ранговой суммы (165), подставляя в формулу соответствующее ей пх:
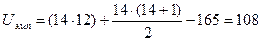
Такую проверку рекомендуется производить в некоторых руководствах (Рунион Р., 1982; Greene J., D'Olivera M., 1989). Для сопоставления с критическим значением выбираем меньшую величину U: Uэмп=60.
По Табл. II Приложения 1 определяем критические значения для n1=14, n2=12.
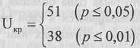
Мы помним, что критерий U является одним из двух исключений из общего правила принятия решения о достоверности различий, а именно, мы можем констатировать достоверные различия, если Uэмп≤Uкp
Построим "ось значимости".
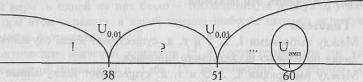
Uэмп=60
Uэмп>Uкp
Ответ: H0 принимается. Группа студентов-психологов не превосходит группы студентов-физиков по уровню невербального интеллекта.
Обратим внимание на то, что для данного случая критерий Q Розенбаума неприменим, так как размах вариативности в группе физиков шире, чем в группе психологов: и самое высокое, и самое низкое значение невербального интеллекта приходится на группу физиков (см. Табл. 2.4).
2.4. Н - критерий Крускала-Уоллиса
Назначение критерия
Критерий предназначен для оценки различий одновременно между тремя, четырьмя и т.д. выборками по уровню какого-либо признака.
Он позволяет установить, что уровень признака изменяется при переходе от группы к группе, но не указывает на направление этих изменений.
Описание критерия
Критерий Н иногда рассматривается как непараметрический аналог метода дисперсионного однофакторного анализа для несвязных выборок (Тюрин Ю. Н., 1978). Иногда его называют критерием "суммы рангов" (Носенко И.А., 1981).
Данный критерий является продолжением критерия U на большее, чем 2, количество сопоставляемых выборок. Все индивидуальные значения ранжируются так, как если бы это была одна большая выборка. Затем все индивидуальные значения возвращаются в свои первоначальные выборки, и мы подсчитываем суммы полученных ими рангов отдельно по каждой выборке. Если различия между выборками случайны, суммы рангов не будут различаться сколько-нибудь существенно, так как высокие и низкие ранги равномерно распределятся между выборками. Но если в одной из выборок будут преобладать низкие значения рангов, в другой - высокие, а в третьей - средние, то критерий Н позволит установить эти различия.
Гипотезы
H0: Между выборками 1, 2, 3 и т. д. существуют лишь случайные различия по уровню исследуемого признака.
Н1: Между выборками 1, 2, 3 и т. д. существуют неслучайные различия по уровню исследуемого признака.
Графическое представление критерия Н
Критерий Н оценивает общую сумму перекрещивающихся зон при сопоставлении всех обследованных выборок. Если суммарная область наложения мала (Рис. 2.6 (а)), то различия достоверны; если она достигает определенной критической величины и превосходит ее (Рис. 2.6 (б)), то различия между выборками оказываются недостоверными.
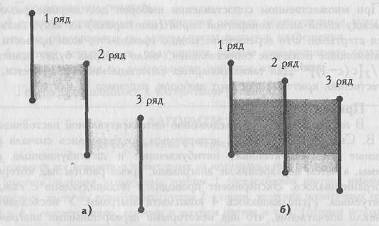
Рис. 2.6. 2 возможных варианта соотношения рядов значений в трех выборках; штриховкой отмечены зоны наложения
Ограничения критерия Н
1. При сопоставлении 3-х выборок допускается, чтобы в одной из них п—Ъ, а двух других n=2. Но при таких численных составах выборок мы сможем установить различия лишь на низшем уровне значимости (р≤0,05).
Для того, чтобы оказалось возможным диагностировать различия на более высоком уровнем значимости (р5~0,01), необходимо, чтобы в каждой выборке было не менее 3 наблюдений, или чтобы по крайней мере в одной из них было 4 наблюдения, а в двух других - по 2; при этом неважно, в какой именно выборке сколько испытуемых, а важно соотношение 4:2:2.
2. Критические значения критерия Н и соответствующие им уровни значимости приведены в Табл. IV Приложения 1. Таблица предусмотрена только для трех выборок и {n1, n2, n3}≤5.
При большем количестве выборок и испытуемых в каждой выборке необходимо пользоваться Таблицей критических значений критерия χ2, поскольку критерий Крускала-Уоллиса асимптотически приближается к распределению χ2 (Носенко И.А., 1981; J. Greene, M. D'Olivera, 1982).
Количество степеней свободы при этом определяется по формуле: V=c-1 где с - количество сопоставляемых выборок.
3. При множественном сопоставлении выборок достоверные различия между какой-либо конкретной парой (или парами) их могут оказаться стертыми. Это ограничение можно преодолеть, если провести все возможные попарные сопоставления, число которых будет равняться ½·[c·(c-1)]*[5] таких попарных сопоставлений используется, естественно, критерий для двух выборок, например U или φ*.
Пример
В эксперименте по исследованию интеллектуальной настойчивости (Е. В. Сидоренко, 1984) 22 испытуемым предъявлялись сначала разрешимые четырехбуквенные, пятибуквенные и шестибуквенные анаграммы, а затем неразрешимые анаграммы, время работы над которыми не ограничивалось. Эксперимент проводился индивидуально с каждым испытуемым. Использовалось 4 комплекта анаграмм. У исследователя возникло впечатление, что над некоторыми неразрешимыми анаграммами испытуемые продолжали работать дольше, чем над другими, и, возможно, необходимо будет делать поправку на то, какая именно неразрешимая анаграмма предъявлялась тому или иному испытуемому. Показатели длительности попыток в решении неразрешимых анаграмм представлены в Табл. 2.5. Все испытуемые были юношами-студентами технического вуза в возрасте от 20 до 22 лет.
Можно ли утверждать, что длительность попыток решения каждой из 4 неразрешимых анаграмм примерно одинакова?
Таблица 2.5
Показатели длительности попыток решения 4 неразрешимых анаграмм в секундах (7V=22)
| Группа 1: анаграмма | Группа 2: анаграмма | Группа 3: анаграмма | Группа 4: анаграмма | |
| ФОЛИТОН (n1=4) | КАМУСТО (n2=8) | СНЕРАКО (n3=6) | ГРУТОСИЛ (n4=4) | |
| Суммы | ||||
| Средние |
Сформулируем гипотезы.
H0: 4 группы испытуемых, получившие разные неразрешимые анаграммы, не различаются по длительности попыток их решения.
H1: 4 группы испытуемых, получившие разные неразрешимые анаграммы, различаются по длительности попыток их решения.
Теперь познакомимся с алгоритмом расчетов.
АЛГОРИТМ 5 Подсчет критерия Н Крускала-Уоллиса
1. Перенести все показатели испытуемых на индивидуальные карточки.
2. Пометить карточки испытуемых группы 1 определенным цветом, например красным, карточки испытуемых группы 2 - синим, карточки испытуемых групп 3 и 4 - соответственно, зеленым и желтым цветом и т. д. (Можно использовать, естественно, и любые другие обозначения.)
3. Разложить все карточки в единый ряд по степени нарастания признака, не считаясь с тем, к какой группе относятся карточки, как если бы мы работали с одной объединенной выборкой.
4. Проранжировать значения на карточках, приписывая меньшему значению меньший ранг. Надписать на каждой карточке ее ранг. Общее количество рангов будет равняться количеству испытуемых в объединенной выборке.
5. Вновь разложить карточки по группам, ориентируясь на цветные или другие принятые обозначения.
6. Подсчитать суммы рангов отдельно по каждой группе. Проверить совпадение общей суммы рангов с расчетной.
7. Подсчитать значение критерия Н по формуле:
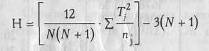
где N - общее количество испытуемых в объединенной выборке;
n - количество испытуемых в каждой группе;
Т - суммы рангов по каждой группе.
8а. При количестве групп с=3, n1•n2•n3≤5определить критические значения и соответствующий им уровень значимости по Табл. IV Приложения 1.
Если Нэмп равен или превышает критическое значение H0,05, H0 отвергается.
8б. При количестве групп с>3 или количестве испытуемых n1•n2•n3>5, определить критические значения χ2 по Табл. IX Приложения 1.
Если Нэмп равен или превышает критическое значение χ2, H0 отвергается.
Воспользуемся этим алгоритмом при решении задачи о неразрешимых анаграммах. Результаты работы по 1-6 шагам алгоритма представлены в Табл. 2.6.
Таблица 2.6
Подсчет ранговых сумм по группам испытуемых, работавших над четырьмя неразрешимыми анаграммами
| Группа 1: анаграмма ФОЛИТОЫ (n1=4) | Группа 2: анаграмма КАМУСТО (n2=8) | Группа 3: анаграмма СНЕРАКО (n3=6) | Группа 4: анаграмма ГРУТОСИЛ (n4=4) | ||||
| Длительность | Ранг | Длительность | Ранг | Длительность | Ранг | Длительность | Ранг |
| 3.5 | 3.5 |
Дата добавления: 2020-08-31; просмотров: 788;
Поиск по сайту
Узнать еще
- IV. 7. Управление состоянием окружающей среды на локальном уровне
- VI. 1. ПЕРВИЧНОЕ ВЫЯВЛЕНИЕ ДЕТЕЙ С ОТКЛОНЕНИЯМИ В РАЗВИТИИ С ИСПОЛЬЗОВАНИЕМ ПЕДАГОГИЧЕСКОГО НАБЛЮДЕНИЯ
- А) доступность до центра осознания различных логическнх уровней
- Анатомо-физиологические особенности скелетных мышц на уровне шейного отдела позвоночника
- Анкета на выявление детей группы риска (от 5 до 10 лет)
- Биосинтез ферментов и его регуляция на генетическом уровне. Конститутивные и индуцибельные (адаптивные) ферменты. Репрессия и индукция биосинтеза ферментов
- Было установлено 5 основных уровней школьной мотивации.
- В заключении указывают, обнаружены или отсутствуют сальмонеллы в 25 г исследуемого продукта.

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
