Основные определения
Структуры данных типа “дерево” исключительно широко используются в программной индустрии. В отличие от списковых структур деревья относятся к нелинейным структурам. Любое дерево состоит из элементов – узлов или вершин, которые по определенным правилам связаны друг с другом рёбрами. В списковых структурах за текущей вершиной (если она не последняя) всегда следует только одна вершина, тогда как в древовидных структурах таких вершин может быть несколько. Математически дерево рассматривается как частный случай графа, в котором отсутствуют замкнутые пути (циклы).
Дерево является типичным примером рекурсивно определённой структуры данных, поскольку оно определяется в терминах самого себя.
Рекурсивное определение дерева с базовым типом Т – это:
· либо пустое дерево (не содержащее ни одного узла)
· либо некоторая вершина типа Т с конечным числом связанных с ней отдельных деревьев с базовым типом Т, называемых поддеревьями
Отсюда видно, что в любом непустом дереве есть одна особая вершина – корень дерева, которая как бы определяет “начало” всего дерева. С другой стороны, существуют и вершины другого типа, не имеющие связанных с ними поддеревьев. Такие вершины называют терминальными или листьями.
Классификацию деревьев можно провести по разным признакам.
1. По числу возможных потомков у вершин различают двоичные (бинарные) или недвоичные (сильноветвящиеся) деревья.
Двоичное дерево: каждая вершина может иметь не более двух потомков.
Недвоичное дерево: вершины могут иметь любое число потомков.
 |  |
2. Если в дереве важен порядок следования потомков, то такие деревья называют упорядоченными.Для них вводится понятие левый и правый потомок (для двоичных деревьев) или более левый/правый (для недвоичных деревьев). В этом смысле два следующих простейших упорядоченных дерева с одинаковыми элементами считаются разными:
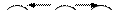 | 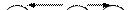 |
При использовании деревьев часто встречаются такие понятия как путь между начальной и конечной вершиной (последовательность проходимых ребер или вершин), высота дерева (наиболее длинный путь от корневой вершины к терминальным).
При рассмотрении дерева как структуры данных необходимо четко понимать следующие два момента:
1. Все вершины дерева, рассматриваемые как переменные языка программирования, должны быть одного и того же типа, более того – записями с некоторым информационным наполнением и необходимым количеством связующих полей
2. В силу естественной логической разветвленности деревьев (в этом весь их смысл!) и отсутствия единого правила выстраивания вершин в порядке друг за другом, их логическая организация не совпадает с физическим размещением вершин дерева в памяти.
Дерево как абстрактная структура данных должна включать следующий набор операций:
· добавление новой вершины
· удаление некоторой вершины
· обход всех вершин дерева
· поиск заданной вершины
Двоичные деревья
Двоичные деревья (ДД) используются наиболее часто и поэтому представляют наибольший практический интерес. Каждая вершина ДД должна иметь два связующих поля для адресации двух своих возможных потомков.
ДД можно реализовать двумя способами:
· на основе массива записей с использованием индексных указателей
· на базе механизма динамического распределения памяти с сохранением в каждой вершине адресов ее потомков (если они есть)
Второй способ является значительно более удобным и поэтому используется наиболее часто. В этом случае каждая вершина описывается как запись, содержащая как минимум три поля: информационную составляющую и два ссылочных поля для адресации потомков:
Type Tp = ^TNode; {объявление ссылочного типа данных}
TNode = record
Inf : <описание информационной части>;
Left, Right : Tp;
end;
Для обработки дерева достаточно знать адрес корневой вершины. Для хранения этого адреса надо ввести ссылочную переменную:
Var pRoot : Tp;
Тогда пустое дерево просто определяется установкой переменной pRoot в нулевое значение (например – nil).
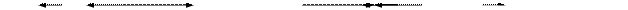
Реализацию основных операций с ДД удобно начать с процедур обхода. Поскольку дерево является нелинейной структурой, то НЕ существует единственной схемы обхода дерева. Классически выделяют три основных схемы:
· обход в прямом направлении
· симметричный обход
· обход в обратном направлении
Для объяснения каждого из этих правил удобно воспользоваться простейшим ДД из трех вершин. Обход всего дерева следует проводить за счет последовательного выделения в дереве подобных простейших поддеревьев и применением к каждому из них соответствующего правила обхода. Выделение начинается с корневой вершины.
Сами правила обхода носят рекурсивный характер и формулируются следующим образом:
1. Обход в прямом направлении:
· обработать корневую вершину текущего поддерева
· перейти к обработке левого поддерева таким же образом
· обработать правое поддерево таким же образом
2. Симметричный обход:
· рекурсивно обработать левое поддерево текущего поддерева
· обработать вершину текущего поддерева
· рекурсивно обработать правое поддерево
3. Обход в обратном направлении:
· рекурсивно обработать левое поддерево текущего поддерева
· рекурсивно обработать правое поддерево
· затем – вершину текущего поддерева
  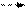 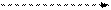 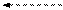  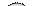 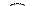
|   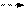 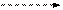 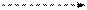 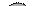 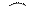 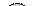
|    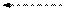 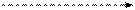 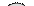 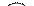 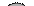
|
| Прямой обход: A - B - C | Симметричный обход: B - A - C | Обратный обход: B - C - A |
В качестве примера по шагам рассмотрим обход следующего ДД с числовыми компонентами (10 вершин):
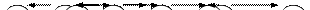
Обход в прямом порядке:
1. Выделяем поддерево 0-1-2
2. обрабатываем его корень – вершину 0
3. переходим к левому потомку и выделяем поддерево 1-3-4
4. обрабатываем его корень – вершину 1
5. выделяем левое поддерево 3-*-* (здесь * обозначает пустую ссылку)
6. обрабатываем его корень – вершину 3
7. т.к. левого потомка нет, обрабатываем правое поддерево
8. т.к. правого поддерева нет, возвращаемся к поддереву 1-3-4
9. выделяем поддерево 4-6-7
10. обрабатываем его корень – вершину 4
11. выделяем левое поддерево 6-*-*
12. обрабатываем его корень – вершину 6
13. т.к. левого потомка нет, обрабатываем правое поддерево
14. т.к. правого потомка нет, то возвращаемся к поддереву 4-6-7
15. выделяем правое поддерево 7-*-*
16. обрабатываем его корень – вершину 7
17. т.к. левого поддерева нет, обрабатываем правое поддерево
18. т.к. правого поддерева нет, то возвращаемся к поддереву 4-6-7
19. т.к. поддерево 4-6-7 обработано, то возвращаемся к поддереву 1-3-4
20. т.к. поддерево 1-3-4 обработано, возвращаемся к поддереву 0-1-2
21. выделяем правое поддерево 2-*-5
22. обрабатываем его корень – вершину 2
23. т.к. левого потомка нет, обрабатываем правого потомка
24. выделяем поддерево 5–8–9
25. обрабатываем его корень – вершину 5
26. выделяем левое поддерево 8-*-*
27. обрабатываем его корень – вершину 8
28. т.к. левого поддерева нет, обрабатываем правое поддерево
29. т.к. правого поддерева нет, то возвращаемся к поддереву 5-8-9
30. выделяем правое поддерево 9-*-*
31. обрабатываем его корень – вершину 9
32. т.к. левого поддерева нет, обрабатываем правое поддерево
33. т.к. правого поддерева нет, то возвращаемся к поддереву 5-8-9
34. т.к. поддерево 5-8-9 обработано, то возвращаемся к поддереву 2-*-5
35. т.к. поддерево 2-*-5 обработано, то возвращаемся к поддереву 0-1-2
36. т.к. поддерево 0-1-2 полностью обработано, то обход закончен
В итоге получаем следующий порядок обхода вершин: 0-1-3-4-6-7-2-5-8-9
В более краткой записи симметричный обход дает следующие результаты:
| 1. поддерево 0-1-2 2. поддерево 1-3-4 3. поддерево 3-*-* 4. вершина 3 5. вершина 1 | 6. поддерево 4-6-7 7. поддерево 6-*-* 8. вершина 6 9. вершина 4 10. поддерево 7-*-* | 10. вершина 7 11. вершина 0 12. поддерево 2-*-5 13. вершина 2 14. поддерево 5-8-9 | 15. поддерево 8-*-* 16. вершина 8 17. вершина 5 18. поддерево 9-*-* 19. вершина 9 |
Итого: 3-1-6-4-7-0-2-8-5-9
Аналогично, обход в обратном порядке дает:
| 1. поддерево 0-1-2 2. поддерево 1-3-4 3. вершина 3 4. поддерево 4-6-7 5. вершина 6 | 6. вершина 7 7. вершина 4 8. вершина 1 9. поддерево 2-*-5 10. поддерево 5-8-9 | 11. вершина 8 12. вершина 9 13. вершина 5 14. вершина 2 15. вершина 0 |
Итого: 3-6-7-4-1-8-9-5-2-0
Видно, что результирующая последовательность вершин существенно зависит от правила обхода. Иногда используются разновидности трех основных правил, например – обход в обратно-симметричном порядке: правое поддерево – корень – левое поддерево.
Учитывая рекурсивный характер правил обхода, программная их реализация наиболее просто может быть выполнена с помощью рекурсивных подпрограмм. Каждый рекурсивный вызов отвечает за обработку своего текущего поддерева. Из приведенных выше примеров видно, что после полной обработки текущего поддерева происходит возврат к поддереву более высокого уровня, а для этого надо запоминать и в дальнейшем восстанавливать адрес корневой вершины этого поддерева. Рекурсивные вызовы позволяют выполнить это запоминание и восстановление автоматически, если описать адрес корневой вершины поддерева как формальный параметр рекурсивной подпрограммы.
Каждый рекурсивный вызов прежде всего должен проверить переданный ей адрес на nil. Если этот адрес равен nil, то очередное обрабатываемое поддерево является пустым и никакая его обработка не нужна, поэтому просто происходит возврат из рекурсивного вызова. В противном случае в соответствии с реализуемым правилом обхода производится либо обработка вершины, либо рекурсивный вызов для обработки левого или правого поддерева.
Рекурсивная реализация обхода в прямом направлении:
Procedure Forward ( pCurrent : Tp );
Begin
If pCurrent <> nil then
Begin
“обработка корневой вершины pCurrent^ ”;
Forward (pCurrent^.Left);
Forward (pCurrent^.Right);
End;
End;
Первоначальный вызов рекурсивной подпрограммы производится в главной программе, в качестве стартовой вершины задаётся адрес корневой вершины дерева: Forward (pRoot).
Остальные две процедуры обхода с именами Symmetric и Back отличаются только порядком следования трех основных инструкций в теле условного оператора.
Для симметричного прохода:
Symmetric (pCurrent^.Left);
“обработка корневой вершины pCurrent^ ”;
Symmetric (pCurrent^.Right);
Для обратного прохода:
Back (pCurrent^.Left);
Back (pCurrent^.Right);
“обработка корневой вершины pCurrent^ ”;
В принципе, достаточно легко реализовать нерекурсивный вариант процедур обхода, если учесть, что рекурсивные вызовы и возвраты используют стековый принцип работы. Например, рассмотрим схему реализации нерекурсивного симметричного обхода. В соответствии с данным правилом сначала надо обработать всех левых потомков, т.е. спустится влево максимально глубоко. Каждое продвижение вниз к левому потомку приводит к запоминанию в стеке адреса бывшей корневой вершины. Тем самым для каждой вершины в стеке запоминается путь к этой вершине от корня дерева.
Обращение к рекурсивной процедуре для обработки левого потомка надо заменить помещением в стек адреса текущей корневой вершины и переходом к левому потомку этой вершины. Обработка правого потомка заключается в извлечении из стека адреса некоторой вершины и переходе к её правому потомку.
Для нерекурсивного обхода дерева необходимо объявить вспомогательную структуру данных – стек. В информационной части элементов стека должны храниться адреса узлов этого дерева, поэтому ее надо описать с помощью соответствующего ссылочного типа Tp.
Схематично нерекурсивный симметричный обход выглядит следующим образом:
pCurrent := pRoot; {начинаем с корневой вершины дерева}
Stop := false; {вспомогательная переменная}
while (not stop) do{основной цикл обхода}
begin
while pCurrent <> nil do {обработка левых потомков}
Begin
“занести pCurrent в стек”;
pCurrent := pCurrent^.left;
end;
if “стек пуст” then stop:= true {обход закончен}
else
Begin
“извлечь из стека адрес и присвоить его pCurrent ”;
“обработка узла pCurrent ”;
pCurrent := pCurrent^.right;
end;
end;
На основе процедур обхода легко можно реализовать поиск в дереве вершины с заданным информационным значением. Для этого каждая текущая вершина проверяется на совпадение с заданным значением и в случае успеха происходит завершение обхода.
Еще одним интересным применением процедур обхода является уничтожение всего дерева с освобождением занимаемой вершинами памяти. Ясно, что в простейшем поддереве надо сначала удалить левого и правого потомка, а уже затем – саму корневую вершину. Здесь наилучшим образом подходит правило обхода в обратном направлении.
Разные правила обхода часто используются для вывода структуры дерева в наглядном графическом виде. Например, для рассмотренного выше дерева с десятью вершинами применение разных правил обхода позволяет получить следующие представления дерева:
  1 1
 3
4
6
7
2
5 3
4
6
7
2
5
 8
9 8
9
|  9
5
2
0
7
4
1 9
5
2
0
7
4
1
| 3
1
6
 4
0
2
8
5 4
0
2
8
5
|
| Прямой обход | Обратно-симметричный | Симметричный проход |
Из этих примеров видно, что наличие нескольких правил обхода дерева вполне обоснованно, и в каждой ситуации надо выбирать подходящее правило.
Дата добавления: 2020-07-18; просмотров: 1035;
Поиск по сайту
Узнать еще
- ОСНОВНЫЕ ТИПЫ И СВОЙСТВА НАПОЛЬНЫХ И БОРТОВЫХ СИСТЕМ ТЕХНИЧЕСКОГО ДИАГНОСТИРОВАНИЯ
- II. Основные положения
- II. Основные характеристики микроскопа.
- II. Языкознание и его основные разделы.
- III. Основные направления развития воспитания
- III. Основные требования к организации рассмотрения обращений граждан
- III. Основные функции ГФС России
- IV. Основные источники поступления загрязняющих веществ в водную среду.

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
