Философский язык Джона Уилкинса
Следующий язык, отнесенный к этому разделу, занимает свое место с намного большим правом. Его создатель Джон Уилкинс (1614–1672) жил в Англии XVII в. – очень непростое время для этой страны, что нашло свое отражение и в его бурной биографии. Уилкинс был не только многогранным ученым, но и видным университетским администратором: он успел повозглавлять колледж и в Оксфорде, и в Кембридже, а это очень большая редкость. В 1656 г. Уилкинс женился на младшей сестре Оливера Кромвеля. Правда, его шурин умер спустя два года, а в 1660 г. была восстановлена монархия, так что едва ли ему приходилось ожидать хорошего к себе отношения от новых властей. Тем не менее в 1668 г. он был рукоположен в епископы и оставался в этом сане до смерти, представляя умеренное крыло англиканской церкви.
Тогда же, в 1668 г., он опубликовал книгу «Опыт о подлинной символике и философском языке». Черновик ее сгорел в 1666 г. во время Великого лондонского пожара, но автор сумел восстановить свой труд. В «Опыте» Уилкинс предвидел много научных и технических открытий. В частности, он предложил заменить десятичную систему счисления восьмеричной, поскольку это было бы удобнее для деления на два[24]. Тем самым Уилкинс фактически предвосхитил использование двоичной системы счисления в современной компьютерной технике. Он предлагал, чтобы пенс состоял из 8 фартингов, шиллинг – из 8 пенсов, энджел – из 8 шиллингов, а фунт – из 8 энджелов. Впрочем, понимая, что это нереалистично, Уилкинс не стал и пытаться провести эту систему в жизнь. Вместо этого он предложил другую важную идею: создать пусть и десятичную, но зато унифицированную систему мер. Известно, что в основе традиционных мер длины лежат размеры человеческого тела; например, фут – это длина ступни (или, возможно, башмака) взрослого мужчины. Но ясно, что взрослые мужчины бывают разные, и ноги у них тоже различаются, а значит, унификацию обеспечить сложно, хотя разные способы стандартизации мер и изобретались. Поэтому Уилкинс предложил выработать универсальную меру длины на основе физических свойств маятника и мер времени, которые задаются движением небесных тел. Если подвесить тяжелый шар к тончайшей нити, получим маятник; как известно, периодичность колебаний такого идеального маятника не зависит от его массы, а зависит только от длины нити. Вот Уилкинс и предложил взять в качестве универсальной меры длину такой нити, при которой маятник за одну секунду доходит от одного крайнего положения до другого (или, другими словами, колеблется с периодом 2 секунды). Затем эту меру можно разделить или умножить на 10 частей, потом еще на 10 частей и так далее. Этим способом он изобрел не что иное, как метр – именно такова длина нити подобного маятника. Но нет пророка в своем отечестве: как известно, именно британцы пользуются метрической системой очень неохотно, предпочитая традиционную.
В предисловии к своей книге Уилкинс раскритиковал существующие языки, подчеркнув четыре их недостатка:
1. Омонимия : приводя в пример латинское слово liber , Уилкинс пишет, что «у грамотных людей оно означает 'кодекс', у политиков – 'пользующийся свободой', у ораторов – 'сын', а у крестьян – 'древесная кора'». Действительно, если мы откроем латинский словарь, то обнаружим там все четыре значения слова liber : 'книга', 'свободный', 'ребенок' и 'лыко' (правда, первое и четвертое значения имеют краткое i , а второе и третье – долгое);
2. Синонимия : «Говорят, что в арабском языке более тысячи обозначений меча, 500 обозначений льва, 200 обозначений змеи и 80 обозначений меда»[25]. Все это Уилкинс считал излишним;
3. Нерегулярности в грамматике ;
4. Несоответствие звучания и написания : Уилкинс отмечал, что оно присуще не только английскому языку. «Если десять писцов, незнакомых с каким-либо языком, возьмутся записывать его в соответствии с произношением, никакие два из них не напишут одинаково»[26].
Для того чтобы со всем этим справиться, и нужно было придумать новый язык. Но нельзя было сделать это просто так: предварительно требовалось разработать классификацию явлений, чтобы понять, чему и какие названия присваивать. Именно этому и посвящен самый большой – второй – раздел книги Уилкинса. Тем самым он для начала отвлекся от третьего и четвертого недостатков, которые так или иначе беспокоят большинство создателей искусственных языков, и начал решать самые сложные проблемы – первую и вторую.
Весь мир Уилкинс поделил на 40 классов – от общих сущностей (класс I) до церковных отношений (класс XL), которые представлены на схеме:

Внутри каждого класса выделяются роды и виды; например, собака относится к классу XVIII (звери), а внутри него – к роду 5 (хищники, похожие на собак) и к виду 1 (собака)[27].
Как же это соотносится с языком? Очень просто: зная класс, род и вид каждого объекта, мы можем построить для него знак универсального алфавита, а также словесное обозначение. Знаки алфавита устроены так: есть 40 обозначений для классов, к которым добавляются 9 обозначений для родов и 9 обозначений для видов.
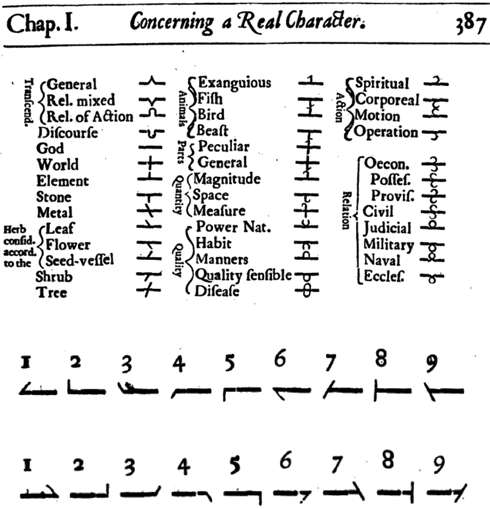
Комбинируя элементы для обозначения собаки (XVIII. Beast + род 5 + вид 1), получаем такой знак:

К знаку, объединяющему в себе класс, род и вид, могут быть добавлены элементы, обозначающие грамматические категории: число, глагольное время и так далее.
Вот как при помощи системы Уилкинса записывается молитва «Отче наш»:
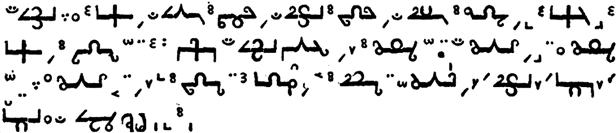
Эта система легко трансформируется и в устный язык: каждому из 40 классов соответствует слог вида «согласный + гласный» (например, классу зверей – zi ), каждому из 9 родов – согласный и каждому из 9 видов – гласный. В итоге получаются базовые понятия из четырех звуков (к ним еще могут добавляться различные уточняющие грамматические показатели). Если мы попробуем перевести на язык Уилкинса слово 'собака', то получится zit α (буква α у Уилкинса обозначает звук [о]), а 'краснота' на этом языке будет tida: ti – это класс XXXVII (ощущаемые качества), d – 2-й род таких качеств, а именно цвета́, а a – 2-й из цветов, то есть красный.
Разумеется, сама идея классификации далеко не чужда естественному языку, и примером тому может служить распределение существительных по родам в русском. Правда, как уже обсуждалось выше, эта классификация во многих своих местах произвольна – вспомним про луну и месяц, табурет и табуретку . В некоторых языках мира классификация более дробная и конкретная – так, для африканских языков банту (самый известный из них – суахили, широко распространенный в Кении, Танзании, Демократической Республике Конго и в других странах) характерна система, в которой на основании выбора приставок в единственном и множественном числе выделяются такие группы существительных[28]:
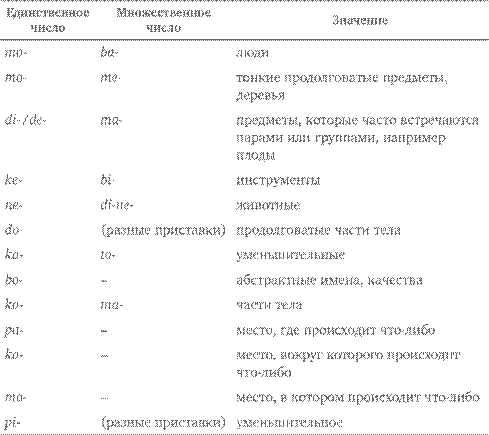
Видно, что некоторые группы дублируют друг друга и отнюдь не любое значение можно легко отнести к одной из этих групп; кроме того, это лишь условная реконструкция, сделанная на основе нескольких языков, тогда как в каждом конкретном языке система классификации еще менее четкая.
Можно сопоставить язык Уилкинса с некоторыми строгими терминологическими системами – например, с той, которая принята в химии. Там название каждого соединения строится так, чтобы выражать состав (и, если надо, строение) молекулы, так что, даже если слышишь его в первый раз, все равно поймешь, о чем речь. Мы легко догадываемся, что, скажем, октин и нонин принадлежат к одному и тому же классу соединений, а если мы еще и знаем, что названия на -ин обозначают органические вещества с формулой Cn Hn –2 (алкины), а корень выражает n (число атомов углерода), то поймем, что это C8H14 и C9H16. Создателям философских языков хотелось и хочется, чтобы так был устроен весь словарь всего языка.
Может быть, нам всем стоило бы перейти на язык Уилкинса, раз он так строен и логичен, в отличие от естественных языков? Но произошло как раз обратное: к середине XX в. о философском языке почти никто не помнил. От полного забвения изобретение Уилкинса спас Хорхе Луис Борхес, который посвятил ему небольшое эссе «Аналитический язык Джона Уилкинса». В нем он продемонстрировал произвольность делений Уилкинса и сопоставил их с еще двумя классификационными системами, столь же несовершенными:
Ознакомившись с методом Уилкинса, придется еще рассмотреть проблему, которую невозможно или весьма трудно обойти: насколько удачна система из сорока делений, составляющая основу его языка. Взглянем на восьмую категорию – категорию камней. Уилкинс их подразделяет на обыкновенные (кремень, гравий, графит), среднедрагоценные (мрамор, амбра, коралл), драгоценные (жемчуг, опал), прозрачные (аметист, сапфир) и нерастворяющиеся (каменный уголь, голубая глина и мышьяк). Как и восьмая, почти столь же сумбурна девятая категория. Она сообщает нам, что металлы бывают несовершенные (киноварь, ртуть), искусственные (бронза, латунь), отделяющиеся (опилки, ржавчина) и естественные (золото, олово, медь). Красота фигурирует в шестнадцатой категории – это живородящая, продолговатая рыба. Эти двусмысленные, приблизительные и неудачные определения напоминают классификацию, которую доктор Франц Кун приписывает одной китайской энциклопедии под названием «Небесная империя благодетельных знаний». На ее древних страницах написано, что животные делятся на а) принадлежащих Императору, б) набальзамированных, в) прирученных, г) сосунков, д) сирен, е) сказочных, ж) отдельных собак, з) включенных в эту классификацию, и) бегающих как сумасшедшие, к) бесчисленных, л) нарисованных тончайшей кистью из верблюжьей щерсти, м) прочих, н) разбивших цветочную вазу, о) похожих издали на мух. В Брюссельском библиографическом институте также царит хаос; мир там разделен на 1000 отделов из которых 262-й содержит относящееся к папе, 282-й – относящееся к Римской католической церкви, 263-й – к празднику Тела Господня, 268-й – к воскресным школам, 298-й – к мормонству, 294-й – к брахманизму, буддизму, синтоизму и даосизму. Не чураются там и смешанных отделов, например 179-й: «Жестокое обращение с животными. Защита животных. Дуэль и самоубийство с точки зрения морали. Пороки и различные недостатки. Добродетели и различные достоинства»[29].
Немецкий китаист Франц Кун действительно существовал, но в основном занимался переводом литературных произведений, а не энциклопедиями. Скорее всего, Борхес сам выдумал эту 14-разрядную псевдокитайскую классификацию. Но даже если и так, Джон Уилкинс заслужил свое место в истории хотя бы тем, что вдохновил Борхеса на этот постоянно цитируемый пассаж.
Язык ро
«Дорогие друзья (я имею в виду весь мир), у меня есть для вас послание. Оно интересно всем – президенту, королю, королеве, кайзеру, царю, микадо, шаху, князю, крестьянину, подданному, гражданину, ученому и неученому, богатому и бедному, в Европе, Азии, Африке, Америке и на островах в океане». Так начинает свою книгу «Ru Ro: Очерк универсального языка», опубликованную в 1913 г., американский священник Эдвард Пауэлл Фостер (1853–1937)[30]. Как нетрудно догадаться, это универсально значимое послание – не что иное, как проект мирового языка. «Человек – животное, которое пользуется инструментами, и его инструменты подвергаются постоянному улучшению. 〈…〉 Один из таких инструментов, доступных для улучшения, – это язык».
Название Ru Ro состоит из двух частей: ru 'письменный язык' + ro 'язык'. Письменность языка ро обеспечивает соответствие между буквами и звуками намного однозначнее, чем английская: например, c читается как [ш], а не совпадает по звучанию то с k , то с s , а q – как ng в английском слове sing и тоже не совпадает по звучанию с k .
«Словарь языка неизмеримо сложнее, чем его грамматика», – пишет Фостер. Возможно, многие лингвисты с ним не согласились бы, но как раз по этой причине основное внимание в своем проекте он уделяет именно словарю. Главная особенность языка ро формулируется в небольшом абзаце про словообразование перед словарем:
Ро не заимствует корней или корневых слов из латыни и других языков. Слова этого языка совершенно новые, они основываются на анализе идей и сконструированы по априорному принципу. Начальная буква или начальный слог контролирует слово. Остальные буквы отвечают за подразделение или категоризацию на основе научной классификации. Начальный слог никогда не меняет своего значения. Это фундаментальный принцип.
Язык ро весьма похож на язык Уилкинса: и там и там слово начинается с обозначения класса, которое позволяет примерно догадаться, о чем речь, даже если не знаешь точного значения. С другой стороны, классификационная система в ро гораздо менее жесткая, в частности, не является обязательной именно трехуровневая классификация.
В качестве примера рассмотрим обозначения чисел в ро. Все они начинаются на z :

Из этих слов можно образовывать составные числительные: так, zidzab означает 301, zifzeb – 410, а zifzefzaf – 444. Кстати, числительные языка ро демонстрируют еще одну важную его особенность: огромное значение в нем придается алфавитному порядку. Если какая-то буква стоит между двумя другими в алфавите, она с большой вероятностью будет выражать что-то промежуточное между тем, что обозначают эти две буквы: согласная f идет между согласными d и g и обозначает 4, стоящую между 3 и 5; гласная e идет между гласными a и i и обозначает десятки, стоящие между единицами и сотнями. Как легко догадаться по аналогии, 1000 на языке ро обозначается словом zob – со следующим гласным. И так же легко догадаться, что в естественных языках такого не бывает, потому что алфавитный порядок – вещь абсолютно условная.
Алфавит действительно может играть роль в системах записи чисел: к примеру, в древнегреческом буква α (альфа) обозначала 1, буква β (бета) – 2, буква γ (гамма) – 3, буква δ (дельта) – 4, и так далее. Но это лишь значки на письме (как наши цифры), а не слова языка: 1 по-древнегречески – εἷς (ейс), 2 – δύο (дю́о), 3 – τρεῖς (трейс), 4 – τέσσαρες (те́ссарес), и ни о каких алфавитных закономерностях здесь уже речь не идет.
Еще один пример, где в дело вступает алфавит, – это химическая терминология, которая уже обсуждалась в связи с языком Уилкинса. Из школьного курса химии многие помнят, что бывают алка ны, алке ны и алки ны – углеводороды, в которых все связи между атомами углерода простые, с одной двойной связью и с одной тройной связью соответственно. Видно, что и здесь работает алфавитный принцип. Но, разумеется, и это совсем не слова естественного языка.
Алфавитная закономерность работает и в других случаях: так, dec значит 'ширина', decab – 'линия' (нечто, не имеющее ширины), decac – 'тонкий, как нить', decad – 'узкий', decaf – 'средней ширины', decak – 'широкий', decal – 'всемирный' (нечто шириной в мир), decar – 'безграничный'.
На a – у Фостера начинаются местоимения и артикли (ab 'я', ac 'ты', ad 'он', ap 'один, какой-то, неопределенный артикль'), на ba – названия химических элементов и веществ (bac 'водород', baced 'вода', bad 'кислород', bal 'углерод', baqsa 'стронций'), на ger – валюты (gerb 'британские деньги', gerbo 'фунт', gerd 'американские деньги', gerdo 'доллар'), на h – отношения обладания (ha 'иметь', he 'получать', hel 'красть', helir 'вор', het 'наследовать', hetir 'наследник', hi 'желать', ho 'давать', hos 'одалживать', hov 'продавать', hu 'терять'), на i – предлоги (ib 'от', ic 'через', id 'к'). Немного грамматики Фостер тоже описывает. Например, в предложениях обычно используется слово с корнем -e -, которое обозначает глагольность: в частности, ek выражает прошедшее время, el – настоящее, em – будущее. К нему добавляются приставки: в частности, n – обозначает отрицание, а w – вопрос. Опираясь на все эти знания, вы легко разберетесь, как устроено одно из немногочисленных предложений-примеров, приводимых Фостером:
(14) Ac wem hos idab ap gerdo?
'Ты одолжишь мне доллар?'
Впрочем, сам Фостер местами отклоняется от идеи априорности, давая звучанию тех или иных элементов своего языка обоснования. Так, слова, начинающиеся на l -, обозначают понятия, связанные с жизнью, и сам Фостер объясняет, почему это так: «Начальное l происходит от английского life и немецкого Leben ». Да и слово ha 'иметь' наверняка вдохновлено английским have , и в слове gerdo опознается do – из слова dollar . Таким образом, в ро, в отличие от языка Уилкинса, не приходится говорить об априорности в чистом виде: априорны связи между словами, а внешний вид слов – не всегда.
Еще одну сферу словаря, в которой чистой априорности нет места, вы найдете, решив задачу № 1:
Задача № 1
Даны названия географических объектов на русском языке и все их переводы на язык ро:
Аргентина, Волга, Куба, Конго, Корея, Нил, Сицилия, Янцзы
Bufesi, Bufucu, Buraya, Burevo, Buriko, Burini, Dradako, Dradiko, Draduar
Задание 1. Установите правильные соответствия.
Задание 2. Переведите на русский язык: Dradaaf, Bufima, Bufonze . Если в каком-то случае вы не можете сделать это однозначно, укажите возможные варианты.
Задание 3. Переведите на язык ро: Алжир, Ганг, Лена, Сербия.
Задание 4. Как вы думаете, что означают на языке ро слова Bugacas и Bugacup , если известно, что других слов на Bugac – в c ловаре языка ро не приводится, а слово Bugacas , вероятно, могло бы иметь и другую предпоследнюю букву?
Мы видим в словаре ро два слова, которые начинаются на Buf -, четыре слова, которые начинаются на Bur -, и три слова, которые начинаются на Drad -. При этом в списке географических названий на русском есть два острова (Сицилия и Куба), четыре реки (Волга, Конго, Нил и Янцзы), а также по крайней мере две страны (Аргентина и Корея; как Фостер классифицировал Кубу и Конго, пока непонятно). Разобраться, что есть что, нам помогает тот факт, что конечные слоги слов на ро напоминают начальные слоги этих географических названий, записанных латиницей. Значит, Bufesi – это Сицилия, Bufucu – Куба, а Buf – означает 'остров'. Тогда Buraya – это Янцзы, Burevo – это Волга, Buriko – это Конго, Burini – это Нил, а Bur – означает 'река'. Остаются слова на Drad – названия стран: Draduar – это явно Аргентина. Но как выбрать между Dradako и Dradiko – что из этого Конго, а что Корея (видимо, Кубу как страну Фостер не удостоил отдельного обозначения в своем словаре, хотя она и обрела независимость в 1902 г., в то время как Конго продолжало оставаться колонией)? Для этого надо разобраться с гласными, которые стоят между частью, обозначающей тип объекта, и частью, дублирующей первый слог его обычного названия. Выпишем по отдельности слова с разными гласными:
a: Buraya 'Янцзы', Dradako '?'
e: Bufesi 'Сицилия', Burevo 'Волга'
i: Buriko 'Конго', Burini 'Нил', Dradiko '?'
u: Bufucu 'Куба', Draduar 'Аргентина'.
Принцип очевиден: гласная обозначает часть света. Гласный a – это Азия, e – Европа, i – Африка, u – Америка. Зная это, может понять, что Dradako – это Корея (страна на Ko – в Азии), а Dradiko – Конго (страна на Ko – в Африке). Тем самым, мы полностью выполнили задание 1.
В задании 2 нам нужно перевести на русский три географических названия:
Dradaf = страна на Af – в Азии = Афганистан;
Bufima = остров на Ma – в Африке = Мадагаскар (хотя можно предложить и другие варианты, например Мадейра или Маврикий);
Bufonze = остров на Nze – в части света o , которая нам ранее не встречалась. Можно предположить, что это Новая Зеландия, а o – Океания. Проблема, правда, в том, что Новая Зеландия – не остров, а государство на двух больших островах и нескольких маленьких.
В задании 3 нам надо в каждом случае решить, сколько букв из названия оставлять в конце слова на ро. Мы видели, что от большинства географических названий берутся первые две буквы, только от Новой Зеландии три – но там и в исходном названии два слова, так что это, наверное, особый случай, на который мы ориентироваться не будем:
Алжир = страна на Al – в Африке = Dradial
Ганг = река на Ga – в Азии = Buraga
Лена = река на Le – в Азии = Burale
Сербия = страна на Se – в Европе = Dradese.
Задание 4 требует от нас понять, о каких двух географических объектах одного типа идет речь, если известно, что один из них (на P -) находится в Америке, а другой (на S -) – в Азии, хотя мог бы быть отнесен к другой части света. Ясно, что это что-то у границы Азии с другой частью света, а раз так, ответ напрашивается сам собой: Bugac – значит 'канал', Bugacas – это Суэцкий канал, который, наверное, мог бы быть и Bugacis , а Bugacup – Панамский канал.
Таким образом, мы полностью решили задачу, и теперь осталось понять, какую интересную информацию о языке ро из нее можно извлечь. Во-первых, видно, что этот язык все же не полностью априорен. Названия географических объектов не берутся из ниоткуда, а основываются на названиях из естественных языков, а точнее, из одного естественного языка – английского. Кроме того, пример с Суэцким каналом показывает, что не все в языке ро однозначно даже в простом случае географических названий.
Да и заявленной научности у Фостера не всегда хватает: к примеру, мясо (pom ) в ро делится на говядину, баранину, свинину, яйца (включая устрицы!) и колбасу (poma-, pome-, pomi– pomo-, pomu- ) – пожалуй, можно даже не комментировать. Впрочем, так было только в работе 1913 г.; в 1919 г. Фостер издает словарь[31], и в нем все по-новому, но тоже не слишком убедительно: теперь pomab – это 'мясо', pomad – 'стейк', pomaf – 'отбивная', pomal – 'омлет', pomas – 'колбаса'.
Заключение к «Очерку универсального языка» открывается уверенной фразой: «Ро победит». Но этого, судя по всему, не случилось. Сейчас о языке ро обычно вспоминают в исторических обзорах, а популярность среди искусственных языков логико-философского направления завоевали другие, более современные изобретения, о которых и пойдет речь дальше.
Логлан
В 1960 г. в журнале Scientific American появилась статья со странным названием Loglan[32]. В аннотации к статье ее автор, социолог Джеймс Кук Браун (1921–2000), пишет: «Этот логический язык основывается на современных лингвистических принципах и предназначен в первую очередь для того, чтобы проверить гипотезу о том, что мировоззрение представителей той или иной культуры определяется структурой их языка». Эту гипотезу, которую сейчас принято именовать гипотезой Сепира – Уорфа, Браун называет гипотезой Лейбница – Уорфа. Может показаться неожиданным, что в серьезном научном журнале появилась такая статья: к середине XX в. интерес к искусственным языкам, которым был отмечен рубеж XIX–XX вв.[33], уже снизился, и их создатели воспринимались скорее скептически. Но Брауну удалось пробить стену недоверия – в первую очередь благодаря тому, что его язык действительно вобрал в себя достижения формальной логики, которая в то время начала очень активно применяться и в лингвистике.
В основе логлана лежит логика предикатов, а именно идея, что высказывания можно представить в некоторой стандартизованной форме, а дальше, анализируя их, получать из них логические следствия или оценивать их истинность. Рассмотрим фразу на логлане:
(15) Radaku da mreni u da rizdonsu
'Все люди разумны'.
Видно, что на логлане слов вдвое больше, чем на русском. Первое – ra-da-ku – состоит из трех частей, которые переводятся на русский язык примерно так: 'все x –' (ra 'все', da 'x ', ku – аналог тире), или, другими словами, 'для всякого x '. Слог da – основное местоимение логлана, в русском переводе обозначенное как x , – мы еще два раза увидим и дальше, поскольку именно об этом x и делается суждение. Следующая часть, da mreni , означает 'x человек'. Пользуясь системой, принятой в логике предикатов, можно сказать, что мы имеем предикат ЧЕЛОВЕК (на русском языке может быть удобнее выражать это глаголом: 'быть человеком'), у которого есть один аргумент: ЧЕЛОВЕК (Петя ) переводится на русский как Петя – человек . В примере, который мы переводим с логлана, аргументом является не Петя, а переменная x . Слово u обозначает импликацию: из того высказывания, которое стоит слева от него, следует то высказывание, которое стоит справа. Итак, из того, что x – человек, следует da rizdonsu . Предикат rizdonsu означает 'разумный' (или 'быть разумным'). Таким образом, получается, что фраза на логлане буквально означает: 'Для всякого x верно, что если x – человек, то x разумен'. Ту же самую идею можно записать и при помощи нотации, принятой в формальной логике:
(16) ∀x (ЧЕЛОВЕК (x ) → РАЗУМНЫЙ (x )).
Здесь ∀x обозначает 'для всякого x ', а остальные части записи в специальных объяснениях не нуждаются.
Такое устройство, собственно говоря, и делает логлан логическим языком, в котором каждое предложение может быть понято единственным способом, а неоднозначность полностью искоренена.
Откуда же берутся слова на логлане? Их изобретение Браун тоже обсуждает в своей статье весьма подробно. Он стремится к тому, чтобы слова логлана могли легко выучить носители основных мировых языков, и поэтому заботится о фонетическом сходстве. В качестве своей целевой аудитории он избрал носителей восьми самых значимых мировых языков: английского, китайского, хинди, русского, испанского, японского, французского и немецкого.
Для каждого слова из них, которое получает перевод на логлан, Браун высчитывает, какая доля его звуков содержится в слове на логлане (при этом считаются только звуки, идущие в том же порядке). Дальше эти доли умножаются на вес языка, пропорциональный количеству говорящих на языке, эти произведения суммируются, и получается «индекс изучаемости», лежащий в пределах от 0 (очень низкий) до 1 (очень высокий). Следовательно, задача построения словаря на логлане сводится к тому, чтобы для каждого понятия подобрать последовательность звуков с наиболее высоким индексом изучаемости.
Например, для значения 'синий / голубой' на логлане используется слово blanu . Сравним его с обозначением этого же понятия на восьми языках (я сохраняю транслитерацию и транскрипцию, использованные Брауном, и его выделение общих звуков):
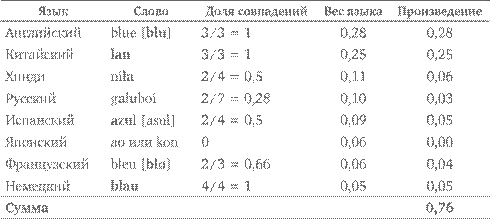
Итак, для слова blanu индекс изучаемости оказывается равен 0,76, и это выше, чем для остальных слов-кандидатов, которые рассматривает Браун: например, для blula индекс составил бы 0,67. Именно поэтому слово blanu и выбирается в качестве обозначения для понятия 'синий / голубой' (или, точнее, для предиката 'быть синим').
Ясно, что критерий, описанный выше, было бы очень легко обойти, если разрешить слова произвольной длины: обозначим понятие 'синий / голубой' словом blulannilagaluboiasulaokonbløblau – и окажется, что для любого из восьми языков соответствующее обозначение целиком находится внутри слова на логлане, а значит, доля совпадений в каждом случае – 1. Но такой жульнический прием не работает, потому что предикаты на логлане имеют строго определенную структуру: ССГСГ или СГССГ, где С – согласная, а Г – гласная. Предикатами правильного вида являются, к примеру, blanu 'быть синим', fleti 'быть усталым', sorlu 'быть ухом', bosni 'быть костью'. Правда, мы уже видели один предикат, который имеет иную структуру: rizdonsu 'быть разумным'. Дело в том, что он не первообразный, а составной: это слово составлено из rizna 'разум' и donsu 'давать'. Наличие таких 8-буквенных (а также еще более длинных – 11-буквенных) предикатов Браун обосновывает отсылкой к исследованиям знаменитого американского ученого Джорджа Кингсли Ципфа (1902–1950). Ципф прославился тем, что установил, как разные свойства слова соотносятся с его частотностью: он заметил, что короткие слова частотнее длинных и что коротких слов меньше. Всему этому соответствует структура логлана: 5-буквенные предикаты – это базовые частотные понятия; количество их комбинаций очевидным образом велико, но и значения с их помощью выражаются не самые основные.
Вскоре после опубликования первой статьи о логлане Браун завершил свою научную карьеру и посвятил себя работе над новым языком, благо его финансовое благополучие обеспечивали заработки от настольной игры Careers, которую он выпустил в 1955 г. Он основал Институт логлана, который, с одной стороны, направлял развитие языка, а с другой – не позволял ему распадаться на диалекты, что неизбежно произошло бы, если бы разные сторонники логлана начали изменять его в разных направлениях. В 1975 г. Браун издал книгу с подробной грамматикой логлана[34].
Как бы то ни было, противоречия между любителями логлана накапливались, а желание Брауна полностью контролировать язык вызывало у многих раздражение. В 1987 г. Боб Лешевалье и его жена Нора Тански начали разрабатывать собственный язык на основе логлана. После долгих споров (в том числе и судебных), имеют ли они право называть этот новый язык словом логлан, он получил название «ложбан» (Lojban). Оба эти названия – сокращения словосочетания «логический язык» на английском (logical language ) и на самом ложбане (logji bangu ) соответственно. Идеи, лежащие в основе этой новой версии логического языка, в целом остались прежними, но лексика ложбана так сильно отличается от лексики логлана, что эти два языка не взаимопонятны[35].
В любом случае пока так и не удалось проверить, помогают ли логлан и ложбан мыслить четче и логичнее и влияют ли они на мышление в соответствии с гипотезой Сепира – Уорфа, ведь никто так и не выучил ни логлан, ни ложбан как родной язык, так что мы не знаем, чем мышление носителей логлана отличалось бы от нашего.
Токипона
Язык токипона был изобретен канадкой Соней Ланг (она также известна как Соня Элен Киса) в 2001 г. В 2014 г. она издала полную грамматику этого языка под названием «Токипона: язык добра» (Toki Pona: The Language of Good)[36]. Впрочем, название Toki Pona может быть переведено по-разному: не исключено, что речь идет о языке добрых людей или просто о хорошем языке. Дело в том, что токипона не проясняет смысл больше, чем английский, а, наоборот, выражает его еще более размыто, и это одно из ключевых свойств этого языка: «Если английский – это толстый роман, то токипона – это хокку», – пишет создательница языка.
Дата добавления: 2020-03-17; просмотров: 1301;
Поиск по сайту
Узнать еще
- DBASe-подобные реляционные языки
- II. Языкознание и его основные разделы.
- Алгоритмы и языки программирования
- Алфавит языка и его синтаксис
- АЛФАВИТНЫЙ УКАЗАТЕЛЬ ТЕРМИНОВ НА РУССКОМ ЯЗЫКЕ
- Американский прагматизм. Новаторство философии Джона Дьюи
- Анализ понятия языковой нормы
- АРЕАЛЬНАЯ И ФУНКЦИОНАЛЬНАЯ КЛАССИФИКАЦИИ ЯЗЫКОВ

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
