Двоичная запись цифровых данных
Алгоритмы и машины Тьюринга
Основы алгоритмов
Как точно определить понятие алгоритма, или машины Тьюринга, или универсальной машины Тьюринга? Почему эти понятия играют одну из главных ролей в современном представлении о «мыслящем устройстве»? Есть ли какие-нибудь абсолютные ограничения на принципиальные возможности использования алгоритмов? Для того чтобы ответить на эти вопросы, нам придется разобраться в деталях, что представляют собой алгоритм и машины Тьюринга.
В дальнейших рассуждениях я буду иногда прибегать к математическим выражениям. Вероятно, некоторых читателей эти выкладки напугают и даже заставят отложить книгу в сторону. Если вы как раз такой читатель, то я прошу вашего снисхождения и рекомендую вам последовать совету, данному мной в Обращении к читателю.! Доказательства, которые здесь встретятся, не потребуют владения математическим аппаратом, выходящим за пределы школьного курса, но чтобы в них детально разобраться, все же понадобятся интеллектуальные усилия. На самом деле, большинство рассуждений изложено весьма подробно, и если внимательно им следовать, можно добиться глубокого понимания. Однако, даже беглый просмотр доказательств позволяет ухватить основную идею. С другой стороны, если вы являетесь экспертом в этой области, то я опять вынужден принести свои извинения. Но я осмелюсь предположить, что даже в этом случае вам будет небесполезно ознакомиться с моими рассуждениями, в которых почти наверняка найдется что-то интересное и для вас.
Слово «алгоритм» происходит от имени персидского математика IX века Абу Джа-фара Мухаммеда ибн Мусы аль-Хорезми, написавшего около 825 года н. э. руководство по математике Kitab al-jabr wa'l-muqa-bala, которое оказало значительное влияние на математическую мысль того времени. Современное написание «алгоритм», пришедшее на смену более раннему и точному «алгоризм», своим происхождением обязано, скорее всего, ассоциации со словом «арифметика»). (Примечательно, что и слово «алгебра» происходит от арабского al-jabr, фигурирующего в названии вышеупомянутой книги).
Примеры алгоритмов были, однако, известны задолго до появления книги аль-Хорезми. Один из наиболее известных - алгоритм Евклида — процедура отыскания наибольшего общего делителя двух чисел, восходит к античности (примерно 300 лет до н. э.). Давайте посмотрим, как он работает. Возьмем для определенности два числа, скажем, 1365 и 3654. Наибольшим общим делителем двух чисел называется самое большое натуральное число, на которое делится каждое из этих чисел без остатка. Алгоритм Евклида состоит в следующем. Мы берем одно из этих чисел, делим его на другое и вычисляем остаток: так как 1365 входит дважды в 3654, в остатке получается 3654 - 2 х 1365 = 924. Далее мы заменяем наши два исходные числа делителем (1365) и полученным остатком (924), соответственно, производим с этой парой ту же самую операцию и получаем новый остаток: 1365 - 924 = 441. Для новой пары чисел — а именно, 924 и 441, — получаем остаток 42. Эту процедуру надо повторять до тех пор, пока очередная пара чисел не поделится нацело. Выпишем эту последовательность:
3654 : 1365 дает в остатке 924
1365 : 924 дает в остатке 441
924 : 441 дает в остатке 42
441 : 42 дает в остатке 21
42 : 21 дает в остатке 0.
Последнее число, на которое мы делим, а именно 21, и есть искомый наибольший общий делитель.
Алгоритм Евклида является систематической процедурой, которая позволяет найти этот делитель. Мы только что применили эту процедуру к двум конкретным числам, но она работает и в самом общем случае с произвольными числами. Для очень больших чисел эта процедура может занять много времени, и будет выполняться тем дольше, чем больше сами числа. Но в каждом конкретном случае выполнение процедуры в конце концов заканчивается, приводя за конечное число шагов к вполне определенному ответу. На каждом этапе мы точно представляем себе действие, которое должно быть выполнено, и точно знаем, когда получен окончательный результат. Более того, всю процедуру можно описать конечным числом терминов, несмотря на то, что она может применяться к любым, сколь угодно большим натуральным числам. («Натуральными числами» называются неотрицательные 14 целые числа О, 1, 2, 3,4, 5, 6, 7, 8, 9, 10, 11, ... ). На самом деле нетрудно изобразить (конечную) блок-схему, описывающую логическую последовательность операций алгоритма Евклида (рис. 2.1).
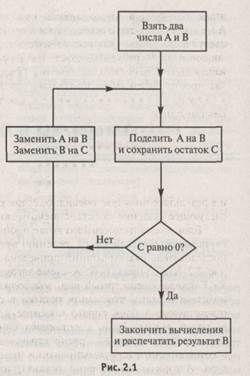
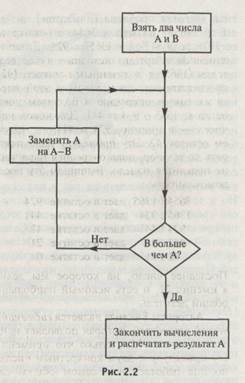
Нужно заметить, что на схеме эта процедура не до конца разбита на простейшие составляющие, поскольку мы неявным образом предположили, что нам уже «известно», как выполнять необходимую базовую операцию получения остатка от деления двух произвольных натуральных чисел А и В. Эта операция, в свою очередь, также алгоритмична и выполняется при помощи хорошо знакомой нам со школы процедуры деления. Эта процедура, на самом деле, сложнее, чем все остальные части алгоритма Евклида, но и она может быть представлена в виде блок-схемы. Основное затруднение здесь возникает из-за использования привычной «десятичной» записи натуральных чисел, что вынуждает нас выписывать все таблицы умножения, учитывать перенос и т. п. Если бы для представления некоторого числа п мы использовали последовательность из п каких-нибудь одинаковых знаков, например, пяти звездочек (*****) для обозначения пятерки, то определение остатка свелось бы к совершенно элементарной алгоритмической операции. Для того чтобы получить остаток от деления А на В, достаточно просто убирать из записи числа А последовательность знаков, представляющих В, до тех пор, пока на некотором этапе оставшееся число знаков в записи А не станет недостаточным для выполнения следующего шага. Эта последовательность знаков и даст требуемый ответ. Например, желая получить остаток от деления 17 на 5, мы просто будем последовательно удалять ***** из *****************, как это показано ниже:
*****************
************
*******
**
и в результате получим, очевидно, 2, так как следующее удаление уже станет невозможно.
Блок-схема изложенного выше процесса нахождения остатка от деления путем последовательных вычитаний приведена на рис. 2.2. Чтобы придать блок-схеме алгоритма Евклида завершенный вид, мы должны подставить схему отыскания остатка в соответствующий блок справа в центре предыдущей схемы. Такая подстановка одного алгоритма в другой — распространенная в компьютерном программировании процедура. Алгоритм вычисления остатка, изображенный на рис. 2.2, служит примером подпрограммы, иначе говоря, это алгоритм (как правило, уже известный), вызываемый и используемый по мере надобности в ходе выполнения основного алгоритма.
Безусловно, обозначение числа n просто набором из п звездочек чрезвычайно неэффективно, когда речь заходит о больших числах. Именно поэтому обычно используют более компактную запись, например, стандартную (десятичную) систему. Однако оставим в стороне эффективность операций и обозначений и уделим все внимание вопросу о том, какие операции в принципе могут выполняться алгоритмически. Действие, которое поддается алгоритмизации в одной записи, сохранит это свойство и в любой другой. Эти два случая различаются только техническими нюансами и сложностью выполнения алгоритма.
Алгоритм Евклида — это лишь одна из многих, часто классических, алгоритмических процедур, встречающихся в математике повсеместно. Но, вероятно, не лишним будет отметить, что, несмотря на значительный исторический возраст отдельных алгоритмов, точная формулировка универсального определения алгоритма появилась только в двадцатом веке. В 1930-х годах было предложено несколько альтернативных формулировок этого понятия, из которых наиболее емкая и убедительная — и, к тому же, наиболее значимая в историческом плане — опирается на понятие машины Тьюринга. Поэтому нам будет полезно рассмотреть некоторые свойства этих «машин».
Прежде всего следует помнить, что «машина» Тьюринга принадлежит области «абстрактной математики» и ни в коем случае не является физическим объектом. Это понятие было введено в 1935-1936 годах английским математиком и кибернетиком Аланом Тьюрингом, внесшим огромный новаторский вклад в развитие компьютерной науки (Тьюринг [1937]). Тьюринг рассматривал задачу весьма общего характера (известную как проблема алгоритмической разрешимости), которая была поставлена великим немецким математиком Давидом Гильбертом частично в 1900 году на Парижском Конгрессе математиков (так называемая «десятая проблема Гильберта»), и более полно — на международном конгрессе 1928 года в Болонье. Проблема, поставленная Гильбертом, состояла ни больше, ни меньше как в отыскании универсальной алгоритмической процедуры для решения математических задач или, вернее, ответа на вопрос о принципиальной возможности такой процедуры. Кроме того, Гильберт сформулировал программу, целью которой было построение математики на несокрушимом фундаменте из аксиом и правил вывода, установленных раз и навсегда. Но к тому моменту, когда Тьюринг написал свою великую работу, сама идея этой программы уже была опровергнута поразительной теоремой, доказанной в 1931 году блестящим австрийским логиком Куртом Геделем. Мы рассмотрим теорему Геделя и ее значение в четвертой главе. Проблема Гильберта, которую исследовал Тьюринг (Entscheidungsproblem), не зависит от какого-либо конкретного построения математики в терминах аксиоматической системы. Вопрос формулировался так: существует ли некая универсальная механическая процедура, позволяющая, в принципе, решить все математические задачи (из некоторого вполне определенного класса) одну за другой?
Трудность с ответом на этот вопрос была связана отчасти с определением смысла «механической процедуры» — это понятие выходило за рамки стандартных математических идей того времени. Чтобы как-то ее преодолеть, Тьюринг постарался представить, как можно было бы формализовать понятие «машина» путем расчленения ее действий на элементарные операции. Вполне вероятно, что в качестве примера «машины», помимо прочего, Тьюринг рассматривал и человеческий мозг, тем самым относя к «механическим процедурам» все действия, которые математики выполняют, размышляя над решением математических задач.
Хотя такой взгляд на процесс мышления оказался весьма полезным при разработке Тьюрингом его в высшей степени важной теории, нам совершенно необязательно его придерживаться. Действительно, дав точное определение механической процедуры, Тьюринг тем самым показал, что существуют совершенно четко определенные математические операции, которые никак не могут называться механическими в общепринятом смысле слова. Можно, наверное, усмотреть некую иронию в том, что эта сторона работы Тьюринга позволяет нам теперь косвенным образом выявить его собственную точку зрения на природу мышления. Однако, нас это пока занимать не будет. Прежде всего нам необходимо выяснить, в чем же, собственно, заключается теория Тьюринга.
Концепция Тьюринга
Попробуем представить себе устройство, предназначенное для выполнения некоторой (конечноопределенной) вычислительной процедуры. Каким могло бы быть такое устройство в общем случае? Мы должны быть готовы к некоторой идеализации и не должны обращать внимания на практические аспекты — мы на самом деле рассматриваем математическую идеализацию «машины». Нам нужно устройство, способное принимать дискретное множество различных возможных состояний, число которых конечно (хотя и может быть очень большим). Мы назовем их внутренними состояниями устройства. Однако мы не хотим, чтобы объем выполняемых на этом устройстве вычислений был принципиально ограничен. Вспомним описанный выше алгоритм Евклида. В принципе, не существует предельной величины числа, после которой алгоритм перестает работать. Этот алгоритм, или некая общая вычислительная процедура, будет тем же самым независимо от того, сколь велики числа, к которым он применяется. Естественно, для очень больших чисел выполнение процедуры может занять много времени и может потребоваться огромное количество «черновиков» для выполнения пошаговых вычислений. Но сам по себе алгоритм останется тем же конечным набором инструкций, сколь бы большими ни были эти числа.
Значит, несмотря на конечность числа внутренних состояний, наше устройство должно быть приспособлено для работы с входными данными неограниченного объема. Более того, устройство должно иметь возможность использовать внешнюю память неограниченного объема (наши «черновики») для хранения данных, необходимых для вычислений, а также уметь выдавать окончательное решение любого размера. Поскольку наше устройство имеет только конечное число различных внутренних состояний, мы не можем ожидать, что оно будет «хранить внутри себя» все внешние данные, равно как и результаты своих промежуточных вычислений. Напротив, оно должно обращаться только к тем данным и полученным результатам, с которыми оно работает непосредственно в настоящий момент, и уметь производить над ними требуемые (опять же, в данный момент) операции. Далее, устройство записывает результаты этих операций — возможно, в отведенной для этого внешней памяти — и переходит к следующему шагу. Именно неограниченные объемы входных данных, вычислений и окончательного результата говорят о том, что мы имеем дело с идеализированным математическим объектом, который не может быть реализован на практике (рис. 2.3). Но подобная идеализация является очень важной. Чудеса современных компьютерных технологий позволяют создавать электронные устройства хранения информации, которые мы можем рассматривать как неограниченные в приложении к большинству практических задач.
На самом деле память устройства, которая выше была названа «внешней», можно рассматривать как внутренний компонент современного компьютера. Но это уже технические детали — рассматривать часть объема для хранения информации как внутреннюю или внешнюю по отношению к устройству. Одним из способов проводить такое деление между «устройством» и «внешней» частью могло бы стать использование понятий аппаратного (hardware) и программного (software) обеспечения вычислений. В этой терминологии внутренняя часть могла бы соответствовать аппаратному обеспечению (hardware), тогда как внешняя — программному обеспечению (software). Я не буду жестко придерживаться именно этой классификации, однако, какую бы точку зрения мы не заняли, не вызывает сомнений, что идеализация Тьюринга достаточно точно аппроксимируется современными электронными компьютерами.
Тьюринг представлял внешние данные и объем для хранения информации в виде «ленты» с нанесенными на нее метками. Устройство по мере необходимости могло обращаться к этой ленте, «считывать» с нее информацию и перемещать ее вперед или назад в ходе выполнения операций. Помимо этого, устройство могло ставить новые метки на ленту и стирать с нее старые, что позволяло использовать одну и ту же ленту и как внешнюю память (то есть «черновик»), и как источник входных данных. На самом деле, не стоило бы проводить явное различие между этими двумя понятиями, поскольку во многих операциях промежуточные результаты вычислений могут играть роль новых исходных данных. Вспомним, что при использовании алгоритма Евклида мы раз за разом замещали исходные числа (А и В) результатами, полученными на разных этапах вычислений. Сходным образом та же самая лента может быть использована и для вывода окончательного результата («ответа»). Лента будет двигаться через устройство туда-сюда до тех пор, пока выполняются вычисления. Когда, наконец, все вычисления закончены, устройство останавливается, и результат вычислений отображается на части ленты, лежащей по одну сторону от устройства. Для определенности будем считать, что ответ всегда записывается на части ленты, расположенной слева от устройства, а все исходные числовые данные и условия задачи — на части ленты, расположенной справа от него.
Меня всегда несколько смущало представление о конечном устройстве, которое двигает потенциально бесконечную ленту вперед и назад. Неважно, насколько легок материал ленты — сдвинуть бесконечную ленту все-таки будет трудно! Вместо этого я предпочитаю представлять себе эту ленту как некое окружение, по которому может перемещаться наше конечное устройство. (Конечно же, в современных электронных устройствах ни «лента», ни само «устройство» не должны в обычном смысле физически «перемещаться», но представление о таком «движении» позволяет достичь известной наглядности.) При таком подходе устройство получает все входные данные из этого окружения, использует его в качестве «черновика» и, наконец, записывает в него конечный результат.
В представлении Тьюринга «лента» состоит из бесконечной в обоих направлениях линейной последовательности квадратов. Каждый квадрат либо пуст, либо помечен. Использование помеченных и пустых квадратов означает, что мы допускаем разбиение нашего «окружения» (т. е. ленты) на части и возможность его описания множеством дискретных элементов (в противоположность непрерывному описанию). Это представляется вполне разумным, если мы хотим, чтобы наше устройство работало надежно и совершенно определенным образом. В силу используемой математической идеализации мы допускаем (потенциальную) бесконечность «окружения», однако в каждом конкретном случае входные данные, промежуточные вычисления и окончательный результат всегда должны быть конечными. Таким образом, хотя лента и имеет бесконечную длину, на ней должно быть конечное число непустых квадратов. Другими словами, и с той, и с другой стороны от устройства найдутся квадратики, после которых лента будет абсолютно пустой. Мы обозначим пустые квадраты символом «0», а помеченные — символом «1», например:

Нам нужно, чтобы устройство «считывало» информацию с ленты. Мы будем считать, что оно считывает по одному квадрату за раз и смещается после этого ровно на один квадрат влево или вправо. При этом мы не утрачиваем общности рассуждений: устройство, которое читает за один раз п квадратов или перемещается на k квадратов, легко моделируется устройством, указанным выше. Передвижение на k квадратов можно построить из k перемещений по одному квадрату, а считывание п квадратов за один прием сводится к запоминанию результатов п однократных считываний.
Что именно может делать такое устройство? Каким образом в самом общем случае могло бы функционировать устройство, названное нами «механическим»? Вспомним, что число внутренних состояний нашего устройства должно быть конечным. Все, что нам надо иметь в виду помимо этого — это то, что поведение нашего устройства полностью определяется его внутренним состоянием и входными данными. Входные данные мы упростили до двух символов «0» и «1». При заданном начальном состоянии и таких входных данных устройство должно работать совершенно определенным образом: оно переходит в новое состояние (или остается в прежнем), заменяет считанный символ 0 или 1 тем же или другим символом 1 или 0, передвигается на один квадрат вправо или влево, и наконец, оно решает, продолжить вычисления или же закончить их и остановиться.
Чтобы явно определить операции, производимые нашим устройством, для начала пронумеруем его внутренние состояния, например: 0, 1, 2, 3, 4, 5. Тогда действия нашего устройства, или машины Тьюринга, полностью определялись бы неким явным списком замен, например:

Выделенная цифра слева от стрелки - это символ на ленте, который устройство в данный момент считывает. Оно заменяет этот символ выделенной цифрой в середине справа от стрелки. R означает, что устройство должно переместиться вдоль ленты на один квадрат вправо, a L соответствует такому же перемещению влево. (Если, в соответствии с исходным представлением Тьюринга, мы полагаем, что движется не устройство, а лента, то R означает перемещение ленты на один квадрат влево, a L — вправо.) Слово STOP означает, что вычисления завершены и устройство должно остановиться. Например, вторая инструкция 01 —> 131L говорит о том, что если устройство находится в начальном состоянии 0 и считывает с ленты 1, то оно должно перейти в состояние 13, оставить на ленте тот же символ 1 и переместиться по ленте на один квадрат влево. Последняя же инструкция 2591 —> OOR.STOP говорит о том, что если устройство находится в состоянии 259 и считывает с ленты 1, то оно должно вернуться в состояние 0, стереть с ленты 1, т. е. записать в текущий квадрат 0, переместиться по ленте на один квадрат вправо и прекратить вычисления.
Вместо номеров 0, 1, 2, 3, 4, 5,... для обозначения внутренних состояний мы можем — и это более соответствовало бы знаковой системе нанесения меток на ленту — прибегнуть к системе нумерации, построенной только на символах «0» и «1». Состояние п можно было бы обозначить просто последовательностью из п единиц, но такая запись неэффективна. Вместо этого мы используем двоичную систему счисления, ставшую теперь общепринятой:
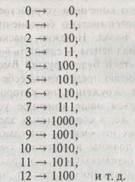
Здесь последняя цифра справа соответствует «единицам» точно так же, как и в стандартной (десятичной) системе записи, но цифра прямо перед ней показывает число «двоек», а не «десятков». В свою очередь третья цифра справа относится не к «сотням», а к «четверкам»; четвертая -к «восьмеркам», а не к «тысячам» и т. д. При этом разрядность каждой последующей цифры (по мере продвижения влево) дается соответственной степенью двойки: 1, 2, 4 (= 2 х 2), 8 (= 2 х 2 х 2), 16 (= 2 x 2 x 2 x 2), 32 (= 2 x 2 x 2 x 2 x 2). (В дальнейшем нам будет иногда удобно использовать в качестве основания системы счисления числа, отличные от «2» и «10». Например, запись десятичного числа 64 по основанию «три» даст 2101, где каждая цифра теперь — некоторая степень тройки: 64 = ( 2 х З3 ) + З2 + 1.
Используя двоичную запись для внутренних состояний, можно представить вышеприведенную инструкцию, описывающую машину Тьюринга, следующим образом:

Здесь я к тому же сократил R.STOP до STOP, поскольку мы вправе считать, что L.STOP никогда не происходит, так как результат последнего шага вычислений, будучи частью окончательного ответа, всегда отображается слева от устройства.
Предположим, что наше устройство находится во внутреннем состоянии, представленном бинарной последовательностью 11010010, и процессу вычисления соответствует участок ленты, изображенный на с. 46. Пусть мы задаем команду:

Та цифра на ленте, которая в данный момент считывается (в нашем случае цифра «0»), показана «жирным» символом справа от последовательности нулей и единиц, обозначающих внутреннее состояние.
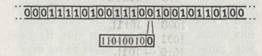
В частично описанном выше примере машины Тьюринга (который я выбрал более-менее произвольно) считанный «0» был бы тогда замещен на «1», внутреннее состояние поменялось бы на «11» и устройство переместилось бы на один шаг влево:
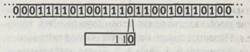
Теперь устройство готово к считыванию следующей цифры, снова «О». Согласно таблице, оно оставляет этот «0» нетронутым, но изменяет свое внутреннее состояние на «100101» и передвигается по ленте назад, т. е. на один шаг вправо. Теперь оно считывает «1» и находит где-то ниже в таблице инструкцию, которая определяет изменение внутреннего состояния и указывает, должна ли быть изменена считанная цифра и в каком направлении по ленте должно дальше двигаться устройство. Таким образом устройство будет действовать до тех пор, пока не достигнет команды STOP. В этой точке — после еще одного шага вправо -раздастся звонок, оповещающий оператора о том, что вычисления завершены.
Мы будем считать, что машина всегда начинает с внутреннего состояния «0» и что вся лента справа от устройства изначально пуста. Все ттструкции и данные подаются в устройство с правой стороны. Как упоминалось ранее, эта информация всегда имеет форму конечной строки из нулей и единиц, за которой следует пустая лента (т. е. нули). Когда машина получает команду STOP, результаты вычислений оказываются на ленте слева от считывающего устройства.
Поскольку мы хотели бы иметь возможность вводить в устройство и числовые данные, то нам потребуется некий способ описания обычных чисел (под которыми я здесь имею в виду целые неотрицательные числа 0, 1, 2, 3, 4,...) как части входной информации. Для представления числа п можно было бы просто использовать строку из п единиц (хотя при этом могут возникнуть трудности, когда речь зайдет о нуле):

Эта примитивная схема нумерации называется (хотя и довольно нелогично) унарной (единичной) системой. В этом случае символ 0 мог бы использоваться в качестве пробела для разделения двух разных чисел. Наличие такого способа разделения для нас существенно, так как многие алгоритмы оперируют не отдельными числами, а множествами чисел. Например, для выполнения алгоритма Евклида наше устройство должно производить определенные действия над парой чисел А и В. Соответствующая машина Тьюринга может быть легко записана в явном виде. В качестве упражнения заинтересованный читатель может проверить, что нижеследующий набор инструкций действительно описывает машину Тьюринга (которую я буду называть EUC), выполняющую алгоритм Евклида, если в качестве исходных данных использовать два «унарных» числа, разделенных символом 0:

Однако я бы порекомендовал такому читателю начать не с этого упражнения, а с чего-нибудь гораздо более простого, например, с машины Тьюринга UN + 1, которая просто прибавляет единицу к числу в унарном представлении:

Чтобы убедиться в том, что UN+1 на самом деле производит такую операцию, давайте мысленно применим ее, скажем, к ленте вида

соответствующей числу четыре. Мы будем полагать, что наше устройство сначала находится где-то слева от последовательности единиц. Находясь в исходном состоянии О, оно считывает 0, в соответствии с первой инструкцией сохраняет его неизмененным, после чего перемещается на шаг вправо, оставаясь во внутреннем состоянии 0. Оно продолжает последовательно передвигаться вправо до тех пор, пока не встретит первую единицу. После этого вступает в силу вторая инструкция: устройство оставляет единицу как есть и сдвигается на шаг вправо, но уже в состоянии 1. В соответствии с четвертой инструкцией оно сохраняет внутреннее состояние 1, равно как и все считываемые единицы, двигаясь вправо до встречи с первым после набора единиц нулем. Тогда начинает действовать третья инструкция, согласно которой устройство заменяет этот нуль на 1, перемещается на один шаг вправо (вспомним, что команда STOP эквивалентна R.STOP) и останавливается. Тем самым к последовательности из четырех единиц прибавляется еще одна, превращая — как и требовалось — 4 в 5.
В качестве несколько более трудного упражнения можно проверить, что машина UN x 2, определяемая набором инструкций

удваивает унарное число, как и должно быть, судя по ее названию.
Чтобы понять, как работает машина EUC,нужно явным образом задать пару подходящих чисел, скажем, 6 и 8. Как и ранее, изначально машина находится во внутреннем состоянии 0 и расположена слева, а лента выглядит следующим образом:
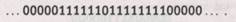
После того, как машина Тьюринга после большого числа шагов останавливается, мы получаем ленту с записью вида
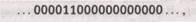
при этом машина располагается справа от ненулевых цифр. Таким образом, найденный наибольший общий делитель равен 2 (как и должно быть).
Исчерпывающее объяснение, почему машина EUC (или UN x 2) на самом деле осуществляет действие, для которого она предназначена, включает в себя некоторые тонкости, и разобраться в нем, может быть, даже труднее, чем понять устройство самой машины — довольно обычная ситуация с компьютерными программами! (Чтобы полностью понять, почему алгоритмические процедуры делают то, что от них ожидается, необходима определенная интуиция. А не являются ли интуитивные прозрения сами алгоритмическими? Это один из вопросов, которые будут для нас важны в дальнейшем.) Я не буду пытаться дать здесь такое объяснение для приведенных примеров EUC или UN x 2. Читатель, шаг за шагом проверив их действие, обнаружит, что я незначительно изменил обычный алгоритм Евклида, чтобы получить более компактную запись в рамках используемой схемы. И все же описание EUC остается достаточно сложным, включая в себя 22 элементарные инструкции для 11 различных внутренних состояний. В основном эти сложности носят чисто организационный характер. Можно отметить, например, что из этих 22 инструкций только 3 в действительности изменяют запись на ленте! (Даже для UN x 2 я использовал 12 инструкций, половина из которых меняют запись на ленте.)
Двоичная запись цифровых данных
Унарная система чрезвычайно неэффективна для записи больших чисел. Поэтому мы по большей части будем использовать вышеописанную двоичную систему. Однако, сделать это напрямую и попытаться читать ленту просто как двоичное число мы не сможем. Дело в том, что мы не имеем возможности сказать, когда кончается двоичное представление числа и начинается бесконечная последовательность нулей справа, которая отвечает пустой ленте. Нам нужен способ как-то обозначать конец двоичной записи числа. Более того, часто нам будет нужно вводить в машину несколько чисел, как, например, в случае с алгоритмом Евклида, когда требуется пара чисел '2'. Но в двоичном представлении мы не можем отличить пробелы между числами от нулей или строчек нулей, входящих в записи этих двоичных чисел. К тому же, помимо чисел нам может понадобиться и запись всевозможных сложных инструкций на той же ленте. Для того чтобы преодолеть эти трудности, воспользуемся процедурой, которую я буду в дальнейшем называть сокращением и согласно которой любая строчка нулей и единиц (с конечным числом единиц) не просто считывается как двоичное число, но замещается строкой из нулей, единиц, двоек, троек и т.д. таким образом, чтобы каждое число в получившейся строчке соответствовало числу единиц между соседними нулями в исходной записи двоичного числа. Например, последовательность:

превратиться в

Мы теперь можем считывать числа 2, 3, 4, ... как метки или инструкции определенного рода. Действительно, пусть 2 будет просто «запятой», указывающей на пробел между двумя числами, а числа 3, 4, 5, ... могли бы по нашему желанию символизировать различные инструкции или необходимые обозначения, как, например, «минус», «плюс», «умножить», «перейти в позицию со следующим числом», «повторить предыдущую операцию следующее число раз» и т.п. Теперь у нас есть разнообразные последовательности нулей и единиц, разделенные цифрами большей величины. Эти последовательности нулей и единиц будут представлять собой обычные числа, записанные в двоичной форме. Тогда записанная выше строка (при замене двоек «запятыми») примет вид:

Используя обычные арабские числа «9», «3», «4», «О» для записи соответствующих двоичных чисел 1001, 11, 100и 0,получаем новую запись всей последовательности в виде:

Такая процедура дает нам, в частности, возможность указывать, где заканчивается запись числа (и тем самым отделять ее от бесконечной полосы пустой ленты справа), просто используя запятую в конце этой записи. Более того, она позволяет закодировать любую последовательность натуральных чисел, записанных в двоичной системе, как простую последовательность нулей и единиц, в которой для разделения чисел мы используем запятые. Посмотрим, как это сделать, на конкретном примере. Возьмем последовательность:
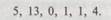
В двоичном представлении она эквивалентна последовательности
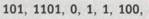
что на ленте можно записать с помощью операции расширения (обратной по отношению к описанной выше процедуре сокращения) как

Такое кодирование легко выполнить, если в исходной двоичной записи чисел провести следующие замены:
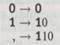
и после этого добавить бесконечные последовательности нулей с обеих сторон вновь полученной записи. Чтобы сделать более понятной эту процедуру в применении к нашему примеру, разделим полученные двоичные числа пробелами:

Я буду называть этот способ представления (наборов) чисел расширенной двоичной записью. (Так, в частности, в расширенной двоичной форме записи число 13 выглядит как 1010010.)
Есть еще одно, последнее, замечание, которое надо сделать в связи с этой системой записи. Это не более, чем техническая деталь, но она необходима для полноты изложения. Двоичная (или десятичная) запись натуральных чисел в некоторой степени избыточна в том смысле, что нули, расположенные слева от записи числа, «не считаются» и обычно опускаются, так что 00110010представляет собой то же самое двоичное число, что и 110010(а 0050 — то же самое десятичное число, что и 50). Эта избыточность распространяется и на нуль, который может быть записан и как 000, и как 00, и, конечно, как 0. На самом деле и пустое поле, если рассуждать логически, должно обозначать нуль! В обычном представлении это привело бы к большой путанице, но в описанной выше системе кодирования никаких затруднений не возникает: нуль между двумя запятыми можно записать просто в виде двух запятых, следующих подряд (,,). На ленте такой записи будет соответствовать код, состоящий из двух пар единиц, разделенных одним нулем:
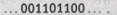
Тогда исходный набор из шести чисел может быть записан в двоичной форме как
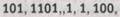
и на ленте при кодировании в расширенной двоичной форме мы получим последовательность

в которой на один нуль меньше по сравнению с предыдущим кодом того же набора.
Теперь мы можем рассмотреть машину Тьюринга, реализующую, скажем, алгоритм Евклида в применении к паре чисел, записанных в расширенной бинарной форме. Для примера возьмем ту же пару чисел — 6 и 8, которую мы брали ранее. Вместо прежней унарной записи
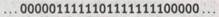
воспользуемся двоичным представлением 6 и 8, т.е. ПО и 1000, соответственно. Тогда эта пара имеет вид: 6, 8, или в двоичной форме 110, 1000, и в расширенной двоичной записи на ленте она будет выглядеть следующим образом
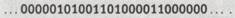
Для этой конкретной пары чисел двоичная форма записи не дает никакого выигрыша по сравнению с унарной. Предположим, однако, что мы берем для вычислений (десятичные) числа 1 583 169 и 8610. В двоичной записи они имеют вид

На ленте при расширенном двоичном кодировании им будет соответствовать последовательность

которая занимает менее двух строк, тогда как для у
Дата добавления: 2022-02-05; просмотров: 545;
Поиск по сайту
Узнать еще
- STEP – стандарт для описания данных об изделии
- АВТОМАТИЗИРОВАННАЯ ОБРАБОТКА ДАННЫХ В СЛУЖБЕ ПРИЕМА И РАЗМЕЩЕНИЯ
- Автоматизированная система технической паспортизации (АСПАД) и создание автоматизированного банка дорожных данных (АБДЦ).
- Автоматизированная система технической паспортизации дорог и создание банка дорожных данных
- АВТОМАТИЗИРОВАННЫЕ БАНКИ ДАННЫХ, ИНФОРМАЦИОННЫЕ БАЗЫ, ИХ ОСОБЕННОСТИ
- Автоматизированные банки дорожных данных.
- Адресация и протоколы данных в сети Интернет.
- Анализ данных и подготовка заключительного доклада

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
