Операторы языка SQL для работы с реляционной базой данных
1. Создание реляционных таблиц.Создание реляционной базы данных означает спецификацию состава полей: указание имени, типа и длины каждого поля (если это необходимо). Каждая таблица имеет уникальное имя.
Синтаксис оператора создания новой таблицы:
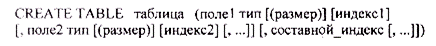
где таблица - имя создаваемой таблицы;
поле1, поле2 - имена полей таблицы;
тип – тип поля;
размер – размер текстового поля;
индекс1, индекс2 - директивы создания простых индексов (по отдельному полю);
составной_индекс – директива создания составного индекса.
Каждый индекс имеет уникальное в пределах данной таблицы имя.
Для создания простого индекса используется фраза (помещается за именем поля):
CONSTRAINT имя_индекса {PRIMARY KEY | UNIQUE |
REFERENCES внешняя_таблица [(внешнее поле)]}
Директива создания составного индекса (помещается в любом месте после определения его элементов):
CONSTRAINT имя {PRIMARY KEY (ключевое1[, ключевое2 [,....]]) | UNIQUE
(уникальное 1[, уникальное [, ...]]) | FOREIGN KEY (ссылка1[, ссылка2 [, ...]])
REFERENCES внешняя_таблица [(внешнее_поле 1 [, внешнее_поле2 [,...]])]}
Служебные слова:
UNIQUE - уникальный индекс (в таблице не может быть двух записей, имеющих одно и то же значение полей, входящих в индекс);
PRIMARY KEY - первичный ключ таблицы (может состоять из нескольких полей; упорядочивает записи таблицы);
FOREIGN KEY – внешний ключ для связи с другими таблицами (может состоять из нескольких полей);
REFERENCES – ссылка на внешнюю таблицу.
Пример 19.60.
CREATE TABLE Студент
([Имя] TEXT,
[Фамилия] TEXT,
[Дата рождения] DATETIME,
CONSTRAINT Адр UNIQUE ([Имя], [Фамилия], [Дата рождения]))
Будет создана таблица СТУДЕНТ, в составе которой:
два текстовых поля: Имя, Фамилия,
одно поле типа дата/время – Дата рождения.
Создан составной индекс с именем Адр по значениям указанных полей, индекс имеет уникальное значение, в таблице не может быть двух записей с одинаковыми значениями полей, образующих индекс.
2. Изменение структуры таблиц.При необходимости можно выполнить реструктуризацию таблицы:
удалить существующие поля,
добавить новые поля,
создать или удалить индексы.
Все указанные действия затрагивают одновременно только одно поле или один индекс:
ALTER TABLE таблица
ADD {[COLUMN] поле тип[(размер)} [CONSTRAINT индекс]|
CONSTRAINT составной_индекс}
DROP {[COLUMN] поле i CONSTRAINT имя_индекса} }
Опция ADD обеспечивает добавление поля, опция DROP – удаление поля таблицы, добавление опции CONSTRAINT означает подобные действия для индексов таблицы.
Пример 19.61.
ALTER TABLE Студент ADD COLUMN [Группа] ТЕХТ(5)
Для создания нового индекса для существующей таблицы можно использовать также команду:
CREATE [ UNIQUE ] INDEX индекс
ON таблица (поле[,...])
[WITH { PRIMARY | DISALLOW NULL | IGNORE NULL }]
Фраза WITH обеспечивает наложение условий на значения полей, включенных в индекс:
DISALLOW NULL – запретить пустые значения в индексированных полях новых записей;
IGNORE NULL – включать в индекс записи, имеющие пустые значения в индексированных полях.
Пример 19.62.
CREATE INDEX Гр ON Студент ([Группа]) WITH DISALLOW NULL
3. Удаление таблицы.Для удаления таблицы (одновременно и структуры, и данных) используется команда:
DROP TABLE имя_таблицы
Для удаления только индекса таблицы (сами данные не разрушаются) выполняется команда:
DROP INDEX имя_индекса ON имя_таблицы
Пример 19.63.
DROP INDEX Адр ON Студент
– удален только индекс Адр
DROP TABLE Студент
– удалена вся таблица
4. Ввод данных в таблицу.Формирование новой записи в таблице выполняется командой:
INSERT INTO таблица_куда [(поле1[, поле2[,...]])]
VALUES (значение1[, значение2[,...]);
Указывается имя таблицы, в которую добавляют запись, состав полей, для которых вводятся значения.
Пример 19.64.
INSERT INTO Студент ([Фамилия], [Имя], [Дата рождения])
VALUES ("Петров", "Иван", 23/3/80)
Возможен групповой ввод записей (пакетный режим), являющихся результатом выборки (запроса) из других таблиц:
INSERT INTO таблица_куда [IN внешняя_база_данных]
SELECT [источник.]поле![, поле2[,...]
FROM выражение
WHERE условие
Перед загрузкой выполняется оператор подзапроса SELECT, который и формирует выборку для добавления. Фраза SELECT определяет структуру данных источника передаваемых записей - имена таблицы и полей, содержащих исходные данные для загрузки в таблицу_куда FROM позволяет указать имена исходных таблиц, участвующих в формировании выборки, а фраза WHERE – задает условия выполнения подзапроса. Структура данных выборки должна соответствовать структуре данных таблицы, в которую производится добавление.
Добавление (перезагрузка) записей возможна и во внешнюю базу данных, для которой указывается полностью специфицированное имя (диск, каталог, имя, расширение).
Пример 19.65.
INSERT INTO Студент SELECT [Студент-заочник].* FROM [Студент-заочник]
Все записи таблицы [Студент-заочник] в полном составе полей будут добавлены в таблицу Студент.
Примечание. Структуры таблиц должны совпадать.
Пример 19.66.
INSERT INTO Студент SELECT [Студент-заочник].* FROM [Студент-заочник] WHERE [Дата рождения] >= #01/01/80#
Записи таблицы [Студент-заочник] добавляются в таблицу Студент, если дата рождения студента больше или равна указанной.
5. Операции соединения таблиц.Операцию INNER JOIN можно использовать в любом предложении FROM. Она создает симметричное объединение, наиболее частую разновидность внутреннего объединения: записи из двух таблиц объединяются, если связующие поля этих таблиц содержат одинаковые значения:
FROM таблица1 INNER JOIN таблица2 ON таблица1.поле1 = таблица2.поле2
Данный оператор описывает симметричное соединение двух таблиц по ключам связи (noлe1; поле2). Новая запись формируется в том случае, если в таблицах содержатся одинаковые значения ключей связи.
Возможные варианты операции:
LEFT JOIN (левостороннее) соединение – выбираются все записи "левой" таблицы и только те записи "правой" таблицы, которые содержат соответствующие ключи связи;
RIGHT JOIN (правостороннее) соединение – выбираются все записи "правой" таблицы и только те записи "левой" таблицы, которые содержат соответствующие ключи связи.
Пример 19.67.
SELECT Студент.*, Оценка.* FROM Студенты INNER JOIN Оценка
ON Студент.[№ зач.книжки] = Оценка.[№ зач.книжки];
SELECT Студент.*, Оценка.* FROM Студенты LEFT JOIN Оценка
ON Студент. [№ зач.книжки] = Оценка. [№ зач.книжки];
SELECT Студент.*, Оценка.* FROM Студенты RIGHT JOIN Оценка
ON Студент. [№ зач.книжки] = Оценка. [№ зач.книжки];
В первом случае создается симметричное соединение двух таблиц по полю [№ зач.книжки]. Не выводятся записи, если значение их ключей связи (указанное поле) не представлено в двух таблицах. Во втором случае будут выведены все записи таблицы СТУДЕНТ и соответствующие им записи таблицы ОЦЕНКА. В третьем случае – наоборот, все записи таблицы ОЦЕНКА и соответствующие им записи таблицы СТУДЕНТ.
Операции JOIN могут быть вложенными для последовательного соединения нескольких таблиц.
Пример 19.68.
SELECT Студент., .Оценка. Дисциплина. [Наименование дисциплины]
FROM (Студент INNER JOIN (Оценка INNER JOIN
( Дисциплина ON Оценка. [Код дисциплины] =
Дисциплина. [Код дисциплины])
ON Студент.[№ зач.книжки]=Оценка. [№ зач.книжки])
Сначала происходит соединение таблиц ОЦЕНКА и ДИСЦИПЛИНА по ключу связи [Код дисциплины]. Соединение симметричное, то есть если коды дисциплины не совпадают, записи этих таблиц не соединяются. Затем происходит соединение таблиц СТУДЕНТ и ОЦЕНКА по ключу связи [№ зач.книжки].
Таким образом, на выходе запроса – результат соединения трех таблиц, но при условии совпадения ключей связи.
6. Удаление записей в таблице.В исходной таблице можно удалять отдельные или все записи, сохраняя при этом структуру и индексы таблицы. При удалении записей в индексированной таблице автоматически корректируются ее индексы:
DELETE [таблица.*] FROM выражение WHERE условия_отбора
Полная чистка таблицы от записей и очистка индексов выполняется операцией:
DELETE * FROM таблица
Пример 19.69.
DELETE * FROM Студент
Все ранее загруженные записи будут удалены.
DELETE * FROM Студент WHERE [Дата рождения]>#1.1.81#
Удаляются только те записи, в которых поле [Дата рождения] больше указанной даты.
Данная операция удаляет записи в таблице, связанные с другой таблицей: условия удаления записей могут относиться к полям связанных таблиц:
DELETE таблица.* FROM таблица INNER JOIN др._таблица
ON таблица, [полеN = др._таблица.[полеМ] WHERE условие
Пример 19.70.
DELETE Студент.* From Студент INner JoIN [Студент заочник]
ON Студент.[Группа]= [Студент заочник]. [Группа]
Удаляются записи в таблице Студент, для которых имеются связанные записи в таблице [Студент заочник].
Примечание.Средствами Microsoft ACCESS невозможно восстановить записи, удаленные с помощью запроса на удаление записей.
7. Обновление (замена) значений полей записи.Можно изменить значения нескольких полей одной или группы записей таблицы, удовлетворяющих условиям отбора:
UPDATE таблица SET новое_значение WHERE условия_отбора
новое_значение указывается как имя_поля=новое значение
Пример 19.71.
UPDATE Студент SET [Группа] = "1212"
WHERE [Фамилия] LIKE 'В*' AND [Дата рождения] < = #01/01/81#
Студентов, чьи фамилии начинаются на букву В и дата рождения не превышает указанной, перевести в группу 1212.
UPDATE Студент INner JoIN [Студент заочник] ON Студент. [Группа]= [Студент заочник]. [Группа] SET [Группа]= [Группа]&"а"
В таблице Студент изменить номера групп, если они встречаются в таблице [Студент заочник], добавив букву а.
Дата добавления: 2021-12-14; просмотров: 908;
Поиск по сайту
Узнать еще
- Andantino con moto А. Бородин. Для берегов отчизны дальней
- Cпецифика логопедической работы в остром периоде
- H. Разработка мер по повышению качества работы органа здравоохранения
- I тип реакций. Реакции, характерные для органических кислот.
- I. 5. Тесты для контроля знаний раздела I
- II раздел. Организация работы логопеда в группе для детей с ОНР
- III. Здания для проживания людей
- III. ОПЕРАТОРЫ И НАБЛЮДАЕМЫЕ

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
