Соблюдение условий ссылочной целостности в реляционной базе данных
Правило соответствия внешних ключей первичным - основное правило соблюдения условий ссылочной целостности. Для каждого значения внешнего ключа должно существовать соответствующее значение первичного ключа в родительской таблице
Ссылочная целостность может нарушиться в результате операций вставки (добавления), обновления и удаления записей в таблицах. В определении ссылочной целостности участвуют две таблицы - родительская и дочерняя, для каждой из них возможны эти операции, поэтому существует шесть различных вариантов, которые могут привести либо не привести к нарушению ссылочной целостности.
Для родительской таблицы:
- Вставка. Возникает новое значение первичного ключа. Существование записей в родительской таблице, на которые нет ссылок из дочерней таблицы, допустимо, операция не нарушает ссылочной целостности.
- Обновление. Изменение значения первичного ключа в записи может привести к нарушению ссылочной целостности.
- Удаление. При удалении записи удаляется значение первичного ключа. Если есть записи в дочерней таблице, ссылающиеся на ключ удаляемой записи, то значения внешних ключей станут некорректными. Операция может привести к нарушению ссылочной целостности.
Для дочерней таблицы:
- Вставка. Нельзя вставить запись в дочернюю таблицу, если для новой записи значение внешнего ключа некорректно. Операция может привести к нарушению ссылочной целостности.
- Обновление. При обновлении записи в дочерней таблице можно попытаться некорректно изменить значение внешнего ключа. Операция может привести к нарушению ссылочной целостности.
- Удаление. При удалении записи в дочерней таблице ссылочная целостность не нарушается.
Таким образом, ссылочная целостность в принципе может быть нарушена при выполнении одной из четырех операций:
- Обновление записей в родительской таблице.
- Удаление записей в родительской таблице.
- Вставка записей в дочерней таблице.
- Обновление записей в дочерней таблице.
В настоящее время наибольшее распространение получили реляционные базы данных. Сетевые и иерархические базы данных считаются устаревшими, объектно-ориентированные пока никак не стандартизированы и не получили широкого распространения. Некоторое возрождение получили иерархические базы данных в связи с появлением и распространением XML.
| Термины реляционной модели | Термины СУБД MS Access |
| Отношение | Таблица |
| Атрибут | Поле |
| Кортеж | Запись |
| Связь | Связь |
Достоинство реляционной модели данных заключается в простоте, понятности и удобстве физической реализации на ЭВМ. Именно простота и понятность для пользователя явились основной причиной их широкого использования. Проблемы же эффективности обработки данных этого типа оказались технически вполне разрешимыми.
Основными недостатками реляционной модели являются следующие: отсутствие стандартных средств идентификации отдельных записей и сложность описания иерархических и сетевых связей.
Примерами зарубежных реляционных СУБД являются следующие: dBaseIII Plus и dBase IV (фирма Ashlon-Tate), DВ2 (IBM), R:BASH (Microrim), FoxPro, Visual FoxPro и Access (Microsoft), Clarion (Clarion Software), Ingres (ASK Computer Systems) u Oracle.
Многомерная модель
Многомерный подход к представлению данных в базе появился практически одновременно с реляционным, но интерес к ним стал приобретать массовый характер с середины 90-х.
Толчком послужила в 1993 году программная статья одного из основоположников реляционного подхода Э.Кодда. В ней сформулированы 12 основных требований к системам класса OLAP (оперативная аналитическая обработка), важнейшие из которых связаны с возможностями обработки многомерных данных. Многомерные системы позволяют оперативно обрабатывать информацию для проведения анализа и принятия решения.
В развитии ИС можно выделить следующие направления:
· Системы оперативной (транзакционной) обработки
· Системы аналитической обработки (системы поддержки принятия решений)
Реляционные СУБД предназначались для информационных систем оперативной обработки и в этой области весьма эффективны. В системах аналитической обработки они показали себя несколько неповоротливыми и недостаточно гибкими. Более эффективными здесь оказываются многомерные СУБД (МСУБД).
Многомерные СУБД являются узкоспециализированными СУБД, предназначенными для интерактивной аналитической обработки информации. Раскроем основные понятия используемые в этих СУБД: агрегируемость, историчность и прогнозируемость данных.
Агрегируемость данных означает рассмотрение информации на различных уровнях ее обобщения. В ИС степень детальности представления информации зависит от уровня пользователя: аналитик, пользователь-оператор, управляющий, руководитель.
Историчность данных предполагает обеспечение высокого уровня статичности собственно данных и их взаимосвязей, а также обязательность привязки ко времени.
Статичность данных позволяет использовать при их обработке специализированные методы загрузки, хранения, индексации и выборки.
Временная привязки необходима для частого выполнения запросов, имеющих значения времени и даты в составе выборки.
Прогнозируемость данных подразумевает задание функций прогнозирования и применение их к различным временным интервалам.
По сравнению с реляционной моделью многомерная организация данных обладает более высокой наглядностью и информативностью.
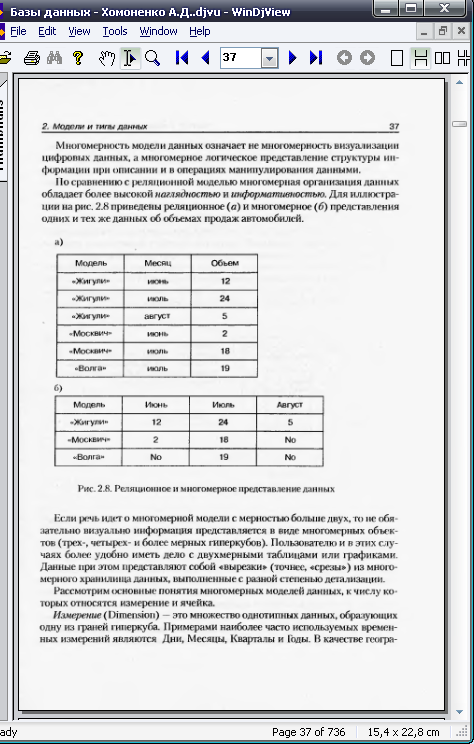
Если речь идет о многомерной модели с мерностью больше двух, то необязательно визуально информация представляется в виде многомерных объектов. Пользователю и в этих случаях более удобно иметь дело с двумерными таблицами или графиками. Данные при этом представляют собой «вырезки» («срезы») из многомерного хранилища данных, выполненные с разной степенью детализации.
Рассмотрим основные понятия многомерной модели.
Измерение – это множество однотипных данных, образующих одну из граней гиперкуба. Примерами наиболее часто используемых временных измерений являются Дни, Месяцы, Кварталы, Годы. В качестве физических измерений широко употребляются Города, Районы, Страны. В многомерной модели измерения играют роль индексов, служащих для идентификации конкретных значений в ячейках гиперкуба.
Ячейка или показатель – это поле, значение которого однозначно определяется фиксированным набором измерений. Тип поля чаще всего определяется как числовой. Значениями ячейки могут переменные или формулы.
Пример трехмерной модели:

В многомерной модели применяется ряд специальных операций:
«Срез» представляет собой подмножество гиперкуба, полученное в результате фиксации одного или нескольких измерений. Например, если ограничить значения измерения Модель автомобиля маркой Жигули, то получится двухмерная таблица продаж этой марки различными менеджерами по годам.
Операция «Вращение» применяется при двухмерном представлении данных. Суть заключается в измерении порядка измерений при визуальном представлении данных. В многомерном случае – процедура изменения порядка следования измерений.
Агрегация и детализация означает соответственно переход к более общему или более детальному представлению информации.
Основным достоинством многомерной модели является удобство и эффективность аналитической обработки больших объемов данных, связанных со временем. При организации обработки аналогичных данных на основе реляционной модели происходит нелинейный рост трудоемкости операций в зависимости от размерности БД.
Недостатком многомерной модели является ее громоздкость для простейших задач обычной оперативной обработки информации.
Примеры систем: Essbase, Media Multi-matrix (и реляционные тоже), Oracle Express Server.
Дата добавления: 2017-01-08; просмотров: 2565;
Поиск по сайту
Узнать еще
- V Патопсихологическое – при нарушении целостности мозга происходит нарушение психической деятельности
- А. Модели экономического прогноза на базе производственных функций.
- Автоматизация обработки табличных данных (обработка списков)
- Автоматизированные банки данных
- Автоматическая генерация базы данных
- Администрирование данных
- Анализ и интерпретация данных контент-анализа
- Анализ и интерпретация данных экспериментально-психологического исследования

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
