Структура и функции гена. Организация генов в хромосомах
Термин «ген» ввел датский ученый В. Иоганнсен в 1909 г., когда еще не была известна его материальная природа. Пониманию структуры и функций гена способствовали результаты экспериментов американских исследователей Дж. Бидла и Э. Тейтума, которые изучали биохимическую роль различных генов у гриба Neurospora crassa. Было установлено однозначное соответствие между появлением генетической мутации, индуцированной рентгеновским излучением, и исчезновением определенного фермента, необходимого для данной биохимической стадии метаболизма. Исходя из этого, Бидл и Тейтум сформулировали гипотезу «один ген — один фермент», которая означала, что каждый ген направляет синтез одного фермента. В настоящее время эта гипотеза претерпела лишь одно изменение, связанное с тем, что структура некоторых белков, включающих более чем одну полипептидную цепь, кодируется несколькими генами. При этом последовательность аминокислот в каждой полипептидной цепи кодируется отдельным геном, цепи синтезируются отдельно и лишь затем соединяются в готовый продукт. Чаще гены, контролирующие синтез двух или нескольких полипептидных цепей, располагаются рядом на хромосоме, но не всегда. Так, например, гены, определяющие структуру a- и b-цепей гемоглобина, не сцеплены между собой. Таким образом, современная трактовка постулата Бидла и Тейтума звучит «один ген — одна полипептидная цепь». Это открытие позволило вплотную подойти к расшифровке механизмов реализации генетической информации.
В настоящее время ген понимают как структурную единицу наследственной информации, далее неделимую в функциональном отношении. Ген — это участок молекулы ДНК (реже, только у некоторых вирусов —РНК), кодирующий структуру одной макромолекулы: полипептида, тРНК или рРНК. В структуре генов прокариот, эукариот и вирусов, а также в организации этих генов в хромосомах много общего, однако есть и существенные различия.
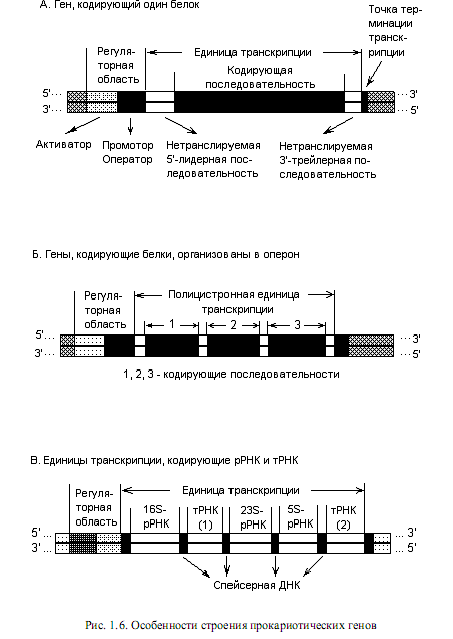
Нуклеоид прокариот содержит примерно 2—3 тыс. не перекрывающихся генов. Среди них выделяют независимые геныи гены, организованные в группы. Независимые гены называются так потому, что мРНК, считанная с такого гена, всегда моноцистронная (под цистроном понимают последовательность нуклеотидов, кодирующую единую полипептидную цепь или стабильную РНК). В свою очередь, независимые гены у прокариот могут содержать регуляторные области (рис. 1.6, А), и в таком случае их транскрипцияподвержена регуляции; а могут и не содержать таковых. В последнем случае они носят название конститутивных генов, поскольку их транскрипция осуществляется непрерывно (конститутивно), независимо от ситуации в клетке. Конститутивные гены кодируют структуру конститутивных белков.
В большинстве случаев, однако, единицы транскрипции прокариот являются полицистроннымии содержат последовательности, кодирующие не один, а несколько типов белков или РНК (рис. 1.6, Б и В). Как правило, транскрипция кодирующих последовательностей в полицистронной единице осуществляется согласованно, с участием общих 5’- и 3’-регуляторных элементов. При этом последовательности, кодирующие один или несколько полипептидов, транскрибируются с образованием зрелой мРНК, которая не претерпевает событий модификации перед трансляцией. Наоборот, последовательности, кодирующие разные типы РНК, специфически расщепляются в ходе посттранскрипционного процессинга с образованием зрелых стабильных РНК-продуктов.
Таким образом, современное представление о прокариотическом гене распространяется на следующие элементы:
1) единицы транскрипции, включающие последовательности, кодирующие зрелую РНК, либо полипептид, 5’-лидерную и 3’-трейлерную последовательности, а также спейсерную ДНК;
2) 5’-последовательности, необходимые для начала правильной транскрипции (промотор) и 3’-последовательности, нужные для правильного окончания транскрипции (терминатор);
3) последовательности, регулирующие частоту инициации транскрипции.
На рис. 1.6 показаны все перечисленные элементы, входящие в состав разных прокариотических генов. Единица транскрипции представляет собой участок ДНК между сайтами, в которых начинается и заканчивается транскрипция. Для белок-кодирующих генов характерно наличие в составе транскрипционной единицы определенного количества нуклеотидов, которые предшествуют белок-кодирующей последовательности (5’-лидер) или следующих за ней (3’-трейлер). Эти элементы присутствуют в зрелых мРНК, известно участие 5’-лидерной последовательности в процессе регуляции транскрипции.
Спейсерная ДНК представляет собой промежуточные последовательности, разделяющие кодирующие области, и она удаляется в ходе процессинга первичных транскриптов. Последовательности, необходимые для правильного начала транскрипции, представляют собой, прежде всего, промотор, с которым связывается РНК-полимераза, и участки, влияющие на скорость инициации транскрипции (оператор, активатор). Нуклеотидные последовательности, ответственные за терминацию транскрипции, располагаются на 3’-конце гена.
В нуклеоиде гены почти непрерывно следуют один за другим по всей длине ДНК, а иногда (в очень редких случаях) даже перекрываются. Значительная часть прокариотических генов объединена в группы по функциональному признаку. Например, гены путей биосинтеза аминокислот, путей катаболизма углеводов у прокариот часто объединяются в опероны. В этом случае их экспрессия осуществляется согласованно.
Число генов в геномах эукариот обычно на порядок больше, чем у прокариот. Например, в геноме человека по разным оценкам насчитывается 40— 60*103 генов. Организация в эукариотических хромосомах и сама структура генов характеризуются некоторыми отличительными особенностями. В первую очередь, у эукариот в процессе транскрипции принимает участие не один тип РНК-полимеразы, как это имеет место в прокариотических
клетках, а несколько разных ферментов. Поэтому сами единицы транскрипции и их регуляторные последовательности отличаются большей сложностью и разнообразием структурных элементов. Во-вторых, в составе эукариотических генов изобилуют мозаичные единицы транскрипции, в которых чередуются кодирующие (экзоны) и некодирующие (интроны) последовательности. Интроны чаще всего встречаются в генах, кодирующих полипептиды и тРНК, и реже в рРНК-генах. Размеры, число и местоположение интронов у разных генов различны. В целом общая длина последовательностей интронов превышает суммарную длину экзонов в 2— 10 раз и больше. Интроны вырезаются из состава мРНК в процессе сплайсинга. Третья особенность эукариотических генов состоит в том, что все белок-кодирующие мРНК у них – моноцистронные, не сгруппированные в опероны. Гены 5 S- рРНК располагаются в хромосомах эукариот тандемно (следуя один за другим в количестве нескольких копий), но каждый ген транскрибируется со своего собственного промотора с образованием РНК, имеющей только одну последовательность 5 S-рРНК на молекулу. Напротив, остальные типы рРНК образуют кластеры (группы тесно расположенных генов с общим промотором) и транскрибируются в виде полицистронной молекулы РНК, из которой в ходе посттранскрипционного процессинга образуются зрелые молекулы 18 S-, 5,8 S- и 28 S-рРНК. Количество генов в геномах разных эукариот сильно отличается, приближаясь к 105 .
Количество генов в вирусных геномах самое маленькое — обычно до десяти. Их особенностью является способность к перекрыванию в результате использования нескольких рамок считывания генетического кода. При таком способе записи наследственной информации увеличивается емкость генетического материала, что необходимо вирусам из-за ограниченных размеров капсидов, в которые может поместиться строго определенное количество нуклеиновых кислот.
Генетический код
Первые представления о том, каким образом в генах закодирована наследственная информация, изложил Ф. Крик в своей «гипотезе последовательности», согласно которой последовательность аминокислот в полипептидной цепи определяется последовательностью элементов в гене. Экспериментальные подтверждения данная гипотеза получила уже после расшифровки генетического кода в экспериментах Ч. Яновского. Чарльз Яновский в 1964 г. показал совпадение относительного положения индуцированных мутаций в гене trpA E.coli и аминокислотных замен в кодируемом этим геном ферменте — триптофан-синтетазе. Таким образом, была доказана колинеарностьструктуры гена и кодируемого им полипептида.
Тем не менее молекулярные основы этой колинеарности были вовсе не очевидны, поскольку все разнообразие аминокислот в полипептидах описывается значением 20, а разнообразие нуклеотидов в ДНК —значением 4. Таким образом, один нуклеотид никак не может кодировать одну аминокислоту в пептиде.
Эксперименты Ф. Крика и его соавторов по исследованию мутаций у бактериофага Т4 кишечной палочки позволили прийти к заключению, что каждая аминокислота кодируется тремя нуклеотидами, т. е. генетический код триплетный. Этот вывод следовал из наблюдения, что мутации, сопровождающиеся вставками или выпадениями (делециями) одного либо двух нуклеотидов из генома Т4, приводили к образованию аномальных белков с нарушенной функцией. Наоборот, вставки или делеции трех нуклеотидов сопровождались часто незначительными изменениями в составе белков, в результате чего последние сохраняли активность. Крик и Бреннер заключили, что генетический код считывается дискретными единицами по 3 нуклеотида. В таком случае вставка (делеция) триплета нуклеотидов должна приводить к добавлению (изъятию) всего одной аминокислоты из состава соответствующего полипептида. В ситуации, когда вставка (делеция) нуклеотидов совершается в количестве, не кратном трем, должен происходить сдвиг «рамки считывания» и последовательность аминокислот в белке должна полностью меняться.
Таким образом, генетический код — триплетный, т. е. положение каждой аминокислоты в полипептиде задается последовательностью из трех нуклеотидов, которая носит название кодон. Поскольку число разных нуклеотидов в ДНК равно четырем, то количество возможных вариантов триплетов нуклеотидов будет описываться количеством: 4 *4 * 4 = 64. 61 из 64 триплетов кодируют аминокислоты, причем каждый триплет — только одну аминокислоту, а три оставшихся кодона служат сигналами окончания (терминации) трансляции (рис. 1.7). Эти кодоны называют стоп (stop)-кодонами или нонсенс-кодонами, поскольку они не определяют никакой аминокислоты. Помимо этого, два кодирующих триплета (чаще ATG — для Met, иногда GTG — для Val) выполняют двойную функцию: кодируют аминокислоты метионин или валин и служат стартовыми кодонами, на которых начинается процесс трансляции (рис. 1.7).

Особенностью генетического кода является то, что в нем отсутствуют запятые, т. е. нет знаков, отделяющих один кодон от другого. При этом генетический код не перекрывается в пределах одной рамки считывания, а рамка считывания задается первым «читаемым» нуклеотидом (рис. 1.8). Максимальное количество рамок считывания в гене — 3, столько же, сколько и «букв» в коде.
Для большинства клеточных организмов характерна реализация лишь одной рамки считывания, в то время как у некоторых вирусов их может быть две или даже три.
Направление чтения закодированной записи осуществляется от 5’-конца к 3’-концу мРНК, являющейся транскриптом «+»-цепи ДНК, считанным с нее в направлении 5’ → 3’. Первый с 5’-конца кодон отвечает N-концевой аминокислоте полипептидной цепи. Следовательно, белки синтезируются от N-конца к С-концу (рис. 1.8).
Еще одним свойством генетического кода является его вырожденность. Это означает, что одна аминокислота может кодироваться более чем одним триплетом нуклеотидов. С другой стороны, код не является двусмысленным: каждый кодон кодирует только одну аминокислоту. Такая закономерность выражается в том, что если известна последовательность нуклеотидов в ДНК, то с ее помощью легко узнать последовательность аминокислот в белке; наоборот, известную последовательность аминокислот нельзя однозначно перевести в нуклеотидную последовательность ДНК. Вырожденность генетического кода, как правило, приводит к тому, что у кодонов, определяющих одну и ту же аминокислоту, реально распознаются только первые два нуклеотида, а третий может не иметь значения.

Для объяснения этого феномена Крик предложил гипотезу «качания» (от англ. wobble), которая впоследствии подтвердилась, и в настоящее время называется правилом неоднозначного соответствия. Согласно этому правилу, cоответствие третьего нуклеотида в кодоне мРНК первому нуклеотиду в антикодоне тРНК является нестрогим, поскольку часто первое положение в антикодоне тРНК занимает минорный нуклеотид, содержащий в качестве азотистого основания инозин. Инозин может образовывать водородные связи с урацилом, цитозином или аденином, находящимися в кодоне в третьем положении. Существование такого механизма позволяет клетке иметь меньше 61 разной тРНК, поскольку многие тРНК способны узнавать до трех кодонов.
Генетический код универсален. Это свойство кода состоит в том, что любая молекула мРНК при трансляции в клетке любого организма приведет к синтезу полипептида с одинаковой последовательностью аминокислот. Данное правило, однако, имеет исключения, которые касаются генетического кода ДНК митохондрий. Большей частью и здесь используется основной «генетический словарь», но, например, в митохондриях млекопитающих кодон UGA в мРНК «читается» как триптофан, и в пептид в соответствующее положение включается триптофан, в то время как в ядерной мРНК данный кодон служит стоп-кодоном (рис. 1.7) и на нем заканчивается процесс трансляции. Наоборот, в митохондриях млекопитающих триплеты нуклеотидов AGA и AGG прочитываются как сигналы терминации, а в ядре они кодируют аминокислоту аргинин. В митохондриях других организмов могут встречаться иные отклонения от универсального для ядерной ДНК генетического кода.
Структура триплетов нуклеотидов коррелирует с химическими свойствами кодируемых ими аминокислот. Так, все кодоны с уридилатом во втором положении кодируют аминокислоты с гидрофобной боковой цепью: фенилаланин, лейцин, изолейцин, валин, метионин. Если исключить терминирующие кодоны, то наличие аденилата во втором положении определяет полярную или заряженную боковую цепь (тирозин, гистидин, глютамин, аспарагин, лизин, глютаминовая и аспарагиновая кислоты) . К тому же кодоны для большинства гидрофобных аминокислот различаются только одним нуклеотидом (рис. 1.7). Аналогичная ситуация наблюдается и для кодонов серина и треонина (их боковые группы содержат гидроксил) или аланина и глицина (имеют наименее сложно устроенные боковые группы). Таким образом, генетический код устроен так, что при замене нуклеотидов даже в первой или второй позиции некоторых кодонов в полипептид включается структурно родственная aминокислота, сводя тем самым к минимуму нарушения во вторичной структуре белка.
Расшифровка генетического кода осуществлена Ниренбергом и Кораной в начале 60-х годов прошлого столетия. В ходе первых экспериментов в бесклеточную систему для синтеза белка, содержащую все необходимые компоненты, в качестве мРНК вносили искусственно синтезированные гомополинуклеотиды: полиуридилат, полицитидилат и др. Синтезированные в таких условиях полипептиды подвергали аминокислотному анализу и установили, что на мРНК, представляющей собой poly(U) (т. е. UUUUUU…), синтезируется полифенилаланин, на poly(С) — полипролин и т. д. Таким образом, можно было заключить, что триплет нуклеотидов UUU кодирует аминокислоту фенилаланин, а ССС — пролин. Окончательную расшифровку всех 64 кодонов удалось осуществить с использованием в бесклеточных системах трансляции синтетических полирибонуклеотидов с известными повторяющимися последовательностями. Эти регулярные сополимеры удалось получить благодаря комбинированию методов органического и ферментативного синтеза.
Дата добавления: 2016-05-30; просмотров: 5705;
Поиск по сайту
Узнать еще
- a-спираль b-складчатая структура
- Cоединения галогенов
- I. Общие принципы структурно-функциональной организации клетки и её компоненты. Плазмолемма, её структура и функции.
- I.2. Антигены системы АВ0. Генетика. Структура
- II. Митохондрии (строение и функции)
- II. Организация дезинфекционных и стерилизационных мероприятий в организациях, осуществляющих медицинскую деятельность
- II. Признаки, ресурсы и функции власти.
- II. Функционально-структурная организация и программное обеспечение персонального компьютера

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
