Программное обеспечение ЭИС
Системы управления базами данных.Для манипулирования дан-
ными (вводом, поиском и т. п.) в информационных системах ис-
пользуется специальное программное обеспечение, называемое
СУБД. Этот вид программного обеспечения в последние годы очень быстро совершенствуется. С одной стороны, СУБД все шире используются для манипулирования новыми типами информации (мультимедиа, географические информационные системы и т.п.).С другой стороны, созданы новые технологии (архитектура «клиент—сервер», базы данных, гипертекст и т.п.), которые позволяют обеспечить доступ к информации широкому кругу пользователей в рамках сети Интернет, открывая тем самым принципиально новые возможности для изучения окружающей среды. В настоящее время фактическим стандартом систем управления базами данных для ПК является СУБД Мicrisoft Ассеss. Пакет Мicrosoft Ассеss for Windows — мощное средство управления базами данных, которое поддерживает реляционную модель данных и позволяет создавать сложные приложения на языке Visuа1 BASIС (VВА). Мicrosoft Ассеss можно применять для поиска и обработки всевозможных данных, а также для подготовки отчетных документов. Пользовательский интерфейс достаточно прост и предоставляет пользователю возможности для манипулирования базами данных, так что освоение пакета обычно не вызывает сложностей.
В связи с бурным развитием сети Интернет, которая является
гигантской распределенной базой данных, возрос интерес к та-
ким СУБД, как Оrас1е. В настоящее время эта система управления
базами данных установлена на многих серверах Сети.
Реляционные базы данных. В подавляющем большинстве СУБД
для ПК информация организуется в виде двумерных таблиц, и их
часто, хотя и не всегда корректно, называют реляционными база-
миданных.
Файлы DВF стандарта dВАSЕ представляют собой ото-
бражение двумерной таблицы со столбцами-полями и строками-
записями. При поиске информации в этих файлах часто приходит-
ся использовать сведения о положении данных в файле (номер
строки таблицы, номер записи файла DВF), и в этом отношении
стандарт (dВАSЕ не удовлетворяет требованиям, предъявляемым к
реляционным базам данных. Пока базы данных на ПК были относительно невелики и их можно было разместить в одном файле DBF, это обстоятельство не играло существенной роли, а привычная простота таблицы привлекала к этому способу организации информации многочисленных пользователей. Но при увеличении размеров баз данных хранить их в одной таблице становится невозможным и возникает необходимость выполнения других тре-
бований реляционной модели. В связи с этим важное значение имеет
понятие «нормализация».
Нормализация не является жестко фиксированным поня-
тием или установленной раз и навсегда процедурой. Нормализа-
ция — скорее набор правил, которыми стоит руководствоваться
при проектировании реляционных баз данных. Одно из них гласит:
«В таблице не должно быть повторяющихся полей и дублирования
информации». Например, если к фрагменту подобной таблицы до-
бавить информацию об авторах книг, то в стандарте dВАSЕ фраг-
мент будет выглядеть следующим образом (табл. 6.6).
У первой книги один автор, и для хранения его имени доста-
точно одного поля. Но у второй книги уже два автора, а могут
быть книги и с большим числом авторов. Поэтому возникает пер-
вый вопрос: сколько полей следует предусмотреть для хранения в
таблице информации о фамилиях авторов книги? При этом в таб-
лице появится несколько однотипных полей для хранения имен
авторов книг. Некоторые из этих полей будут пустыми, если чис-
ло авторов книги меньше числа зарезервированных полей. Во
многих полях будет значиться одна и та же фамилия, если один
человек является автором более чем одной книги, т. е. информа-
ция будет дублироваться. Такую таблицу обычно называют не-
нормализованной, и ее не следует включать в реляционную базу
данных.
Как следует организовывать информацию в реляционной базе
данных, можно проиллюстрировать на простейшем примере базы
ВООКS.МDВ, созданной с помощью СУБД Мicrosoft Ассess 7.0.
База ВООК5.МDВ предназначена для хранения информации о
книгах.
В 90-е гг. XX в. реляционная модель данных превратилась в ос-
новное средство организации информации в базах данных не толь-
ко на ПК, но и на больших ЭВМ. В рамках этой модели был разра-
ботан язык структурированных запросов SQL, который стал ос-
Таблица 6.6
Пример ненормализованной таблицы
| Номер записи | Название | Автор 1 | Автор 2 | Автор 3 | Год | Страницы |
| Анализ про- цессов ста- тистически- ми методами | Д. Химмель- блау | |||||
| Методы ре- шения некор- ректных задач | А.Н.Тихо- нов | В.Я.Арсе- нин |
новным средством для получения информации из реляционных
баз данных.
Язык структурированных запросов SQL (Structu-
red Query Language) был разработан корпорацией IВМ в 70-х гг.
XX в., но всеобщее распространение получил существенно поз-
днее, когда после появления компьютерных сетей, связывающих
компьютеры различных типов, потребовались стандартные языки
для обмена информацией. Благодаря своей независимости от спе-
цифики компьютера, а также поддержке лидерами в области тех-
нологии реляционных баз данных SQL стал и в ближайшем обо-
зримом будущем останется таким стандартным языком. Синтаксис
SQL похож на синтаксис английского языка и позволяет констру-
ировать достаточно сложные запросы. SQL является непроцедур-
ным языком, в нем отсутствуют многие стандартные для проце-
дурных языков конструкции — функции, циклы, условные опера-
торы. Он состоит из инструкций, которые передаются СУБД, обес-
печивая выполнение определенных действий. Эти инструкции на-
зываются предложениями, но чаще используется термин «коман-
да SQL».
Интерпретаторы команд SQL встраиваются во многие процедурные языки программирования, такие как Visuа1 ВАSIС, С/С++. В этом случае команда обычно формируется в виде строковой переменной.
Всеобщее распространение компьютерных сетей породило еще
одну, кроме необходимости разработки стандартизованного языка
запросов, проблему. Эта проблема возникает, когда несколько полъзователей с разных компьютеров начинают изменять одну и ту же базу данных. До тех пор пока база данных открыта «только для чтения», особых трудностей не возникает, но как только нескольким пользователям позволяется модифицировать базу, возникают трудно разрешимые конфликты. Эти проблемы преодолеваются в рамках модели базы данных типа «клиент—сервер». При реализации этой модели система управления базами данных разде-
ляется на две части: «клиент» и «сервер». Программа «клиент» раз-
мещается на пользовательской машине и позволяет формировать
запросы (как правило, на языке SQL), которые по сети передаются
на специализированную машину (сервер), где работает программа
«сервер». Таким образом, термин «сервер» иногда относится к ком-
пьютеру, а иногда к программному обеспечению. Программа-сер-
вер обрабатывает запрос, формирует из базы данных требуемую вы-
борку записей и отсылает ее программе-клиенту. Если пользователь
предполагает изменять информацию в запрошенной выборке, дос-
туп любого другого пользователя для модификации выбранных за-
писей блокируется (монопольный захват). Если пользователь запра-
шивает информацию «только для чтения», то доступ к выбранным
записям не ограничивается (коллективный захват).
Основной механизм, который позволяет избежать конфликтов
между пользователями, заключается в разбиении процесса обра-
ботки информации на элементарные события — группы команд
SQL, которые могут выполняться (или не выполняться) только
все вместе. Такие группы команд называются транзакциями. Тран-
закция начинается всякий раз, когда на вход сервера начинают
поступать команды SQL, если никакая другая транзакция не явля-
ется активной. Она заканчивается либо командой внести измене-
ния в базу данных, либо отказом от внесения изменений (откат).
Если в процессе выполнения команд возникает какая-либо ошиб-
ка, автоматически выполняется откат, и база данных остается в
исходном состоянии.
Распределенные базы данных. Успехи модели баз данных типа
«клиент—сервер» привели к очевидной идее, что не только об-
работку информации можно распределить между несколькими
компьютерами, но и саму информацию хранить в разных местах.
Поэтому в начале 90-х гг. XX в. все большую привлекательность
для пользователей ПК стали приобретать распределенные базы
данных и соответственно СУБД, разработанные для больших ЭВМ.
Современные информационные системы очень редко реализуют-
ся на одном ПК, и поэтому возникают проблемы использования
данных, хранящихся на разных ЭВМ, с обеспечением при этом
высокой надежности работы и защиты данных. Многолетний опыт
решения таких проблем, накопленный при разработке СУБД дли
больших машин, широко используется при создании сетей из
ПК. Под распределенной базой данных понимается логически
единая база данных, которая размещается на нескольких ЭВМ.
Гигантской распределенной базой данных является сеть Интер-
нет. Для пользователя любого из компьютеров, объединенных в
сеть, в узлах которой распределена такая база данных, она выг-
лядит как единое целое и одинаково доступна. При этом возника-
ет много проблем с обеспечением целостности и непротиворечи-
вости хранимых данных и одновременно приемлемого быстро-
действия прикладных программ, работающих с распределенной
базой данных. Лишь в очень немногих системах управления база-
ми данных (Sybase, Ingres, Informix) эти проблемы решены в
достаточном объеме, самой известной из них является СУБД
Оrас1е.
Система управления базами данных Оrас1е фирмы Оrас1е явля-
ется одним из лидеров рынка многоплатформенных СУБД. Она
может работать на более чем двухстах типах ЭВМ, включая ПК
типа 1ВМ РС и Арр1е Маcintosh. В программное обеспечение этой
СУБД входит одна из наиболее полных реализаций языка структу-
рированных запросов SQL, а также генераторы меню, отчетов и
других экранных форм. Кроме того, программное обеспечение по-
зволяет на основании информации, хранящейся в СУБД, строить
более 50 типов графиков и диаграмм. Оrас1е содержит очень надеж-
ную систему защиты данных, их целостности и непротиворечи-
вости.
Мультимедиа. Термином «мультимедиа» (тиltimediа) обозна-
чаются интерактивные компьютерные системы, обеспечивающие работу с разнообразными типами данных: неподвижными и движущимися изображениями (включая видео), а также текстом, высококачественным звуком. В соответствующих базах данных хра-
нится не только текстовая информация, но и оцифрованные фильмы, звуки и музыка, факсимильные изображения и многое другое. Современные системы управления мультимедийными базами данных поддерживают технологию «клиент—сервер», описанную выше, а сами базы данных оказываются распределенными по узламвсемирной компьютерной сети. При этом возникает новая
ситуация, которая в ближайшие годы будет определять развитие
цивилизации, — большинство знаний, накопленных человече-
ством, оказывается интегрированным в глобальную информационную систему, а доступ к этим знаниям открыт для каждого члена общества.
Технология мультимедиа широко используется в образовании —
для создания обучающих программ, тренажеров, различных эн-
циклопедий и справочников. На одном компакт-диске (СD-RОМ) можно разместить тексты, составляющие библиотеку средних раз-
меров, или фильм, но чаще на таких дисках размещаются тексты,
движущиеся изображения, звуки и видеоклипы, связанные в еди-
ную интерактивную систему, последовательность событий в кото-
рой определяется пользователем.
Хранилища данных. Следует отметить, что в последние годы не
только появляются новые технологии, но и несколько меняется
подход к формированию баз данных. Базы данных, из которых из-
влекаются знания, должны отвечать определенным требованиям,
чтобы подчеркнуть это, используется специальный термин «хра-
нилище данных».
Термин «хранилище данных» (Datа Warehouse) означает пред-
метно-ориентированный, интегрированный, поддерживающий
хронологию, неизменяемый набор данных, организованный для
целей поддержки принятия решений. Можно выделить две основные трудности при создании хранилищ данных, ориентированных на поддержку принятия решений:
неопределенность задачи — какая именно информация может
понадобиться для поддержки принятия решений в постоянно и
быстро меняющемся мире, какие цели и задачи будут актуальными завтра и т.п.;
неоднородность информации — разные и зачастую плохо опи-
санные форматы файлов данных, полученные на разных приборах
и не стыкующиеся между собой результаты измерений.
Во многих случаях легче повторить дорогостоящий эксперимент,
чем пытаться извлечь результаты из архивных данных предыдущей
го аналогичного эксперимента.
Первым этапом создания хранилища данных является интегра-
ция. При интеграции исходных данных в хранилище необходимо
обеспечить единые правила наименования, унифицированные еди-
ницы измерения для однотипных объектов, единую систему пред-
ставления (атрибуты) для таких объектов и т. п. Кроме того, для
интеграции данных о состоянии окружающей среды важна единая
система географических координат. Другой важной особенностью
данных, включаемых в хранилище данных, является поддержка
хронологии. В настоящее время в датировке данных о состоянии
окружающей среды царит полная неразбериха. Например, трудно
сказать, какая дата — 7 марта или 3 июля — имеется в виду в
записи 99/03/07. Однотипная датировка данных с учетом смены
тысячелетия должна решить все эти проблемы. В результате конеч-
ный пользователь будет иметь единое представление о временной
привязке всех данных. Сформированное хранилище данных долж-
но представлять собой неизменяемый набор данных, т.е. конеч-
ным пользователям данные будут доступны в режиме «только для
чтения». Это простейший способ обеспечения целостности данных
при одновременном обеспечении высокой скорости доступа к ним.
При необходимости изменять данные пользователь может восполь-
зоваться витриной данных (Data Mart). Это сравнительно неболь-
шой набор данных, чаще всего являющийся выборкой из храни-
лища данных, свободно изменяемый и дополняемый пользовате-
лем. Обычно витрины данных используются для агрегирования дан-
ных из хранилища с тем, чтобы повысить скорость анализа дан-
ных.
Геоинформационные системы. Результаты экологического мони-
торинга всегда имеют географическую привязку, поэтому оптималь-
ным способом организации анализа сведений о состоянии окружа-
ющей среды будет тот, который основывается на ГИС. Географи-
ческие информационные системы предназначены для создания циф-
ровых карт и анализа событий, происходящих на планете. Во многих
отношениях географическая информационная система — это ти-
пичная СУБД, примеры которой рассмотрены выше.
Термин «географическая информационная система» означает
организованный набор аппаратуры, программного обеспечения,
географических данных и персонала, предназначенный для эф-
фективного ввода, хранения, обновления, обработки, анализа и
визуализации всех видов географически привязанной информации.
Особое значение для успешной работы ГИС имеет персонал: опе-
раторы, программисты, системные аналитики и т.д. Технические
специалисты, проектирующие и поддерживающие систему, во
многом определяют ее свойства и эффективность последующего
использования. Аппаратные средства включают компьютеры (плат-
формы), на которых работает ГИС. Такие ГИС, как АRС/INFО,
функционируют на достаточно большом числе платформ — на
мощных серверах, обслуживающих клиентские машины в локаль-
ных сетях и Интернете, на рабочих станциях и отдельных ПК. Кроме того, ГИС используют разнообразное периферийное оборудование — дигитайзеры для оцифровки карт, лазерные принтеры, плоттеры для печати карт и т. п. Программное обеспечение позво-
ляет вводить, сохранять, анализировать и отображать географическую информацию. Ключевыми компонентами программного обеспечения являются:
средства для ввода и манипулирования географическими дан-
ными;
система управления базой данных;
программные средства, обеспечивающие поддержку запросов,
географический анализ и визуализацию информации;
графический интерфейс пользователя, облегчающий исполь-
зование программных средств.
Данные — возможно, наиболее важный компонент ГИС. Гео-
графические информационные системы работают с данными двух
основных типов:
пространственные (синонимы: картографические, векторные)
данные, описывающие положение и форму географических объек-
тов, и их пространственные связи с другими объектами;
описательные (синонимы: атрибутивные, табличные) данные
о географических объектах, состоящие из наборов чисел, текстов
и т.п.
Описательная информация организуется в реляционную базу
данных — отдельные таблицы связываются между собой по клю-
чевым полям, для них могут быть определены индексы, отноше-
ния и т.п. Кроме этого, в ГИС описательная информация связыва-
ются с пространственными данными. Отличие ГИС от стандартных систем управления базами данных (dBASЕ, Ассеss и т.п.) состоит как раз в том, что ГИС позволяют работать с пространственными данными.
Пространственные данные в ГИС представляются в двух основных формах — векторной и растровой. Векторная модель данных основывается на представлении карты в виде точек, линий и плос-
ких замкнутых фигур. Растровая модель данных основывается на
представлении карты с помощью регулярной сетки одинаковых по форме и площади элементов. Различия между этими моделями данных поясняются рис. 6.6.
Здесь показано, как объекты местности — озеро, речка, поле —
отображаются с помощью векторной модели линиями и полиго-
нами, а с помощью растровой модели, по-разному окрашенными
квадратиками.
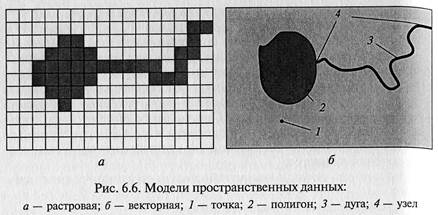
Упрощая ситуацию, можно сказать, что растровая модель дан-
ных — это набор одинаковых по величине, но по-разному окра-
шенных квадратиков. В векторной модели данных озеро изобража-
ется окрашенным многоугольником, который в АRС/INFО назы-
вается полигоном (ро1уgоп), а речка — ломаной линией, которая
называется дугой (аrc). Начало и конец этой ломаной линии назы-
ваются узлами (поdе).
Другой пример растрового и векторного способов отображения
пространственных данных представлен на рис. 6.7 и 6.8, где пока-
зано, как изменяются фрагменты изображения при его увеличе-

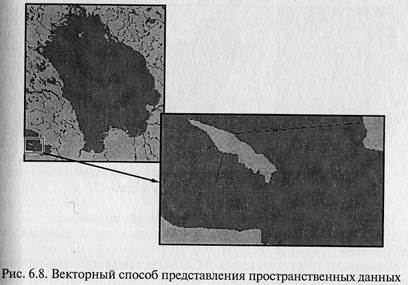
нии. На обоих рисунках на верхних фрагментах представлено Ла-
дожское озеро.
На рис. 6.7 это изображение, полученное прибором АVHRR спут-
ника N0AA и визуализированное с помощью растровой ГИС IDRISI.
Его форма несколько искажена, что объясняется особенностями
орбиты спутника.
На рис. 6.8 представлена карта в проекции Меркатора, сформи-
рованная из покрытий РОNET и DNNЕТ карты DCW спомощью
ГИС АRС/INFО и визуализированная с помощью ГИС АrсView. При
увеличении изображения в первом случае увеличивается размер
прямоугольных ячеек — элементов изображения (пикселей), из
которых состоит растровое изображение. При этом ни форма, ни
цвет прямоугольников (величина сигналов) не изменяются.
На рис. 6.7, б хорошо видны прямоугольники, из которых со-
ставлено изображение острова Котлин. Изменение цвета пикселей
на границах острова объясняется тем, что эти сигналы определя-
ются отражением и от поверхности острова, и от поверхности
Финского залива.
При увеличении изображения на рис. 6.8, б полигон, соответ-
ствующий острову Котлин, преобразуется в подобный полигон
большей площади. Для большего полигона увеличивается длина
отрезков замкнутой ломаной линии, определяющей его границу,
при этом ширина этой линии не изменяется.
На рис. 6.9 показан процесс объединения в простейшую циф-
ровую карту двух слоев цифровой карты DCW:
|

1) РОNEТ — границы государств, морей, океанов;
2) DNNЕТ — гидрографические объекты — реки, каналы, озе-
ра, острова.
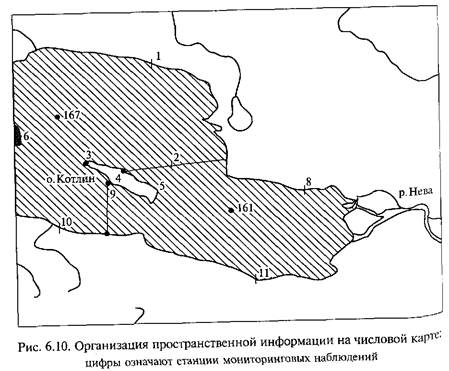
Например, цифровая карта DCW была сформирована на осно-
ве карт масштаба 1:1 000 000, и именно это обстоятельство опре-
деляет, какой объект на этой карте будет изображаться полиго-
ном, а какой ломаной линией. На рис. 6.10, представляющем фраг-
менткарты DCW, р. Нева изображается в виде полигона, а речки,
впадаюшие в нее и в Финский залив, обозначены ломаными ли-
ниями.
В цифровых картах пространственная информация об объектах
хранится в виде координат (X; Y). Точка описывается одной па-
рой координат. Отрезок прямой линии представляется двумя па-
рами координат (X; Y), соответствующими началу и концу отрез-
ка. Ломаные линии описываются упорядоченной последователь-
ностью координат (Х; Y). Если ломаная линия начинается и за-
канчивается в одной и той же точке, она ограничивает замкну-
тую фигуру — полигон. Соответственно первая и последняя пары координат ломаной линии (или первой и последней из ломаных линий, когда полигон ограничивается несколькими дугами) должны совпадать.
Картофафическая информация об объектах включает не толь-
ко ихкоординаты, но и отношения типа «Нева впадает в Балтий-
ское море». На цифровых картах такие отношения описываются с
помощью топологической модели, определяющей пространствен-
ные связи. В ГИС ARС/INFО приняты три основных топологиче-
ских условия:
1)дуги соединяются между собой в узлах;
2)дуги, ограничивающие фигуру, определяют полигон;
3)дуги имеют направление, а также левую и правую сторону.
Географический анализ экологической информации позволяет
изучать процессы, происходящие в окружающей среде, путем про-
ведения различных логических операций над векторными и атрибу-
тивными данными (пространственного и табличного анализа). Для
отображения результатов пространственного анализа обычно ис-
пользуются карты, а для отображения результатов табличного ана-
лиза — отчеты. Пример отображения результатов простейшего про-
странственного анализа приведен на рис. 6.11. На этом примере ниже
обсуждаются некоторые особенности проведения географического
анализа и открывающиеся при этом возможности.
Цельпроведения географического анализа, результаты кото-
рогопредставлены на рис. 6.11, состояла в определении зон воз-
можного загрязнения почв свинцом по критерию, использован-
ному в «Экологической карте Ленинградской области», — пре-
имущественное нахождение свинца вдоль автодорог с интенсив-
ным движением в двухсотметровой полосе. Дополнительное усло-
виеанализа заключалось в исключении из рассмотрения районов
жилой застройки — городов и поселков городского типа, где
загрязнение почв свинцом наблюдается повсеместно. Решение
задачи проходило в несколько этапов. Во-первых, была подго-
товлена карта района Санкт-Петербурга (см. рис. 6.11) в проек-
ции Меркатора, на которой были совмещены четыре покрытия
карты DCW:
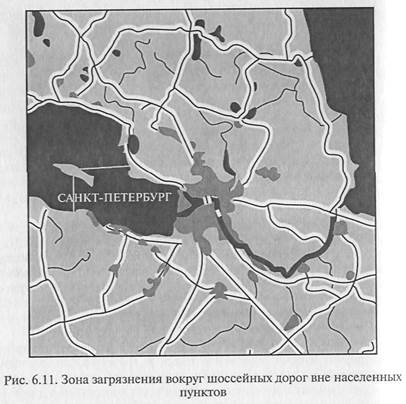
РОNЕТ: океаны, моря, страны;
DNNЕТ: озера, реки;
РРРОLY: районы жилой застройки;
RDLINE: автомобильные дороги.
Далее средствами АRС/INFО было сформировано покрытие
RdlineM1, включающие области, лежащие вблизи автомобильных
дорог (в пределах +/-200 м). Затем из этого покрытия были выре-
заны области, соответствующие жилой застройке. При этом было
сформировано покрытие RdlineМ2. Полигоны этого покрытия, со-
ответствующие внутренним областям буферных зон, показаны бе-
лой заливкой. Эти полигоны представляют решение поставленной
задачи по определению зон возможного загрязнения почв свин-
цом. Первое, что следует отметить в связи с этой задачей,- это
легкость, с которой она решается средствами АRС/INFО. Также
легко решаются и другие задачи пространственного анализа:
формирование областей, лежащих вне полигонов вырезаюшего
покрытия;
создание новых покрытий при помощи «вырезания и склеива-
ния»;
расщепление покрытий на несколько меньших покрытий;
наложение полигонов и сохранение всех областей обоих по-
крытий;
наложение точек, линий или полигонов на полигоны и сохра-
нение всех объектов входных покрытий;
наложение точек, линий или полигонов, но сохранение только
части объектов входного покрытия, попадающей внутрь полиго-
нов формирующего покрытия.
В перечисленных выше операциях создаются таблицы, описы-
вающие полигоны, дуги, границы покрытия и реперные точки.
Эти таблицы изначально пригодны для проведения анализа и для
них можно формировать разнообразные запросы, аналогичные за-
просу на выбор полигонов покрытия RdlineМ2 на рис. 6.11, для
которых выполняется условие «атрибут 1пsidе = 100 в таблице
РAТ.DВF», что соответствует внутренним областям буферных зон.
При проведении табличного анализа, используя логические опе-
рации АND, ОR и формируя другие, более сложные структуриро-
ванные запросы, можно выбрать информацию из нескольких по-
лей одной или разных таблиц.
Возможность проведения географического анализа — это то глав-
ное, что отличает географическую информационную систему. Гео-
графический анализ позволяет сопоставить между собой разнооб-
разную пространственно привязанную информацию и представить
результаты анализа в форме, удобной для восприятия. Рутинные
операции географического анализа легко автоматизируются. Для
этого в каждую полнофункциональную ГИС встраивается внут-
ренний язык программирования — SМL в ГИС РС АRС/INFО,
МарВаsiс в ГИС Мар1пfо и т. п. Все это делает ГИС незаменимым
инструментом для проведения анализа информации о состоянии
окружающей среды.
Интеллектуальный анализ данных.Географические информаци-
онные системы предоставляют мощные средства для анализа эко-
логической информации. Однако сами по себе они не порождают
новых знаний о состоянии окружающей среды — ГИС только ин-
струмент для естествоиспытателя. В то же время, особенно в после-
дние годы, быстро развиваются информационные технологии,
ориентированные на формирование знаний о состоянии окружа-
ющей среды, которые объединяют понятием интеллектуальный
анализ данных (data тining). Модули, основанные на таких техно-
логиях, развиваются в рамках наиболее мощных географических
информационных систем, но значительно чаще они формируются
в экспертно-информационные системы, ориентированные на про-
гнозирование состояния окружающей среды, оценку риска хозяйственной деятельности и поддержку принятия решений, обеспечиивающих устойчивое развитие. С научной точки зрения метод интелектуального анализа данных (ИАД) — сфера пересечения че-
ловеческих знаний, машинного обучения, математического моде-
лирования и баз данных. В последнее время применение интеллек-
туального анализа данных стало частью экономической стратегии
многих компаний, которые стремятся привлечь новых клиентов и
сохранить старых.
Опираясь на различные математические методы, такие как ней-
ронные сети, деревья решений, линейное программирование,
нечеткая логика, удается извлечь из различных, в том числе и
очень больших, баз данных ранее неизвестную и достоверную
информацию, служащую основой для принятия решений. Поэто-
му ИАД определяют также как метод поддержки принятия реше-
ний, основанный на поиске и анализе зависимостей между дан-
ными. Иногда как синоним используется понятие «обнаружение
знаний в базах данных» (knowledgе discoverу in data bases). Следует
отметить, что ИАД основывается на целом комплексе методов
прикладной статистики, как традиционных, так и нетрадицион-
ных. В традиционных методах, таких как регрессионный анализ,
пользователь сам выдвигает гипотезы относительно зависимос-
тей между данными. Это относится и к современным средствам
установления зависимостей, таким как оперативная аналитичес-
кая обработка данных (Оп-Liпе Апа1уtiса1 Рrосеssing, ОLАР), кото-
рые по существу являются развитием классических методов ре-
грессионного и дисперсионного анализов и т.п. Традиционные
методы, основанные на использовании статистических моделей
и априорных предположений о свойствах этих моделей, доста-
точно широко используются в ИАД, но большие надежды в на-
стоящее время возлагаются на нетрадиционные методы. Доста-
точно часто именно эту группу методов связывают с понятием
ИАД. Основополагающая идея, лежащая в основе таких методов,
состоит в установлении зависимостей между рядами данных без
необходимости предварительного формулирования гипотезы о
виде этой зависимости. При этом искомые зависимости далеко не
всегда выражаются математическими уравнениями, и в таких слу-
чаях точнее говорить о взаимосвязях между данными. Следует также
отметить, что большинство из так называемых нетрадиционных
методов ИАД довольно давно разрабатывались прикладными ста-
тистиками и в этом смысле они являются вполне традиционны-
ми. При этом их эффективность, например при решении доста-
точно сложных экономометрических задач, подтверждена резуль-
татами большого числа исследований.
Существует несколько методов, позволяющих находить взаи-
мосвязи между данными без необходимости предварительного
формулирования гипотезы о виде этой зависимости: поиск ассо-
циаций, поиск последовательностей (шаблонов), классификация,
кластерный анализ, прогнозирование. Поиск ассоциаций означает
поиск связанных между собой событий, когда наступление одного
события с высокой степени вероятности означает наступление
другого. События, связанные во времени, обычно называют пос-
ледовательностями, и выявление таких последовательностей по-
зволяет прогнозировать будущее. Классификация означает распре-
деление данных на некоторое количество групп по некоему набору
признаков. Одним из весьма перспективных методов классифика-
ции является нейрокомпьютинг, который предполагает обучение
системы (программы) для решения поставленной задачи на огра-
ниченном числе примеров. Кластеризация отличается от класси-
фикации тем, что сами группы заранее не заданы. Основой про-
гнозирования являются временные ряды.
Возможность анализа временных рядов в экометрии связана с
использованием индикаторов и индексов. Если удается выявить
закономерности, адекватно отражающие динамику поведения ин-
дексов во времени, то на этой основе можно с некоторой вероят-
ностью предсказывать будущее экологических систем.
Особенность настоящего этапа развития методов ИАД состоит
в том, что все эти достаточно сложные методы реализованы в боль-
шом числе программных продуктах, доступных широкому кругу
пользователей. Многие из таких программных продуктов имеют
модули когнитивной графики и предоставляют пользователю боль-
шие возможности по интерпретации результатов анализа данных.
Это, в свою очередь, порождает ряд новых проблем, связанных с
достоверностью такой интерпретации, но опыт эксплуатации про-
граммных продуктов ИАД при поддержке принятия решения под-
тверждает их эффективность.
Для анализа данных о состоянии окружающей среды можно
использовать стандартные пакеты, реализующие те или иные
методы ИАД, — SТАТISТ1СА, МАТLAВ и т.п. Более подробные
сведения об использовании стандартных пакетов для обработки
данных о состоянии окружающей среды можно найти в учеб-
никах, размещенных в Интернете (например, Растоскуев В.В.
Информационные технологии экологической безопасности:
httр://www.есоsafе.nw.ru/win/ЕNY/Read_mе.him).
Экспертные системы обработки данных. Что касается эксперт-
ных и экспертно-информационных систем, предназначенных для
обработки данных, то их разработка сталкивается с большими труд-
ностями. «Интеллектуализация» компьютерной обработки первич-
ной информации об окружающей среде основывается, с одной
стороны, на идеях и методах конкретной области знания, для ко-
торой создается система обработки данных. С другой стороны, в
компьютерной системе обработки используются разнообразные
методы прикладной математики: математической статистики, те-
ории решения обратных задач и т. п. Соответственно при создании
экспертных систем обработки данных приходится учитывать, с
одной стороны, методические и метрологические особенности ме-
тодик выполнения измерения, а с другой — априорные предполо-
жения и ограничения математических алгоритмов обработки. Это
предполагает участие в разработке достаточно большого коллекти-
ва профессионалов: специалистов в предметной области, матема-
тиков, программистов, и, как следствие, высокую стоимость раз-
работки. Поэтому при наличии огромного числа систем общего
назначения — пакетов для статистической обработки данных, элек-
тронных таблиц — существует небольшое число экспертных сис-
тем, способных автоматически провести весь цикл анализа дан-
ных. При этом важнейшее значение приобретают средства для со-
здания нового программного обеспечения: компиляторы, библио-
теки функций, интегрированные средства.
Одной из первых задач, прорабатывающихся в рамках пробле-
мы искусственного интеллекта, к которой традиционно относят
создание экспертных систем, стала компьютерная имитация логи-
ческого мышления человека — решение задач, доказательство те-
орем и т. п.
Существенным отличием систем искусственного интеллекта от
обычных программ является то, что отдельные компоненты такой
системы (факты, правила, цели и т. п.) могут быть дополнены или
изменены независимо друг от друга.
Средства Интернета
В 80-е гг. XX в. в развитых странах существовали десятки инфор-
мационных систем. Каждая такая система представляла собой ло-
кальную или распределенную сеть, объединяющую компьютеры
правительственных, научных учреждений. В конце 80-х гг. такие
локальные сети начали быстро объединяться. В 1992 г. возник Ин-
тернет, который иногда называют «сетью сетей». Интернет — это
некоммерческое объединение многих сетей. В «сети сетей» нет еди-
ного центра управления, и она никому не принадлежит.
К концу XX в. Интернет превратился во всемирную сеть, объе-
диняющую сотни сетей и многие миллионы компьютеров.
Небольшие группы компьютеров соединяются в локальные или
распределенные сети.
Локальной сетью называется компьютерная сеть, объединяю-
щая компьютеры, расположенные в одном здании или в соседних
зданиях, при этом информация передается непосредственно от
компьютера к компьютеру. В локальных сетях используются
различные сетевые платы (обычно Еthernet), обеспечивающие вы-
сокие скорости передачи информации. К сожалению, непосред-
ственное соединение компьютеров можно использовать только на
небольших расстояниях. Если же компьютеры находятся в разных
частях города или в разных городах, то отдельные компьютеры
должны соединяться между собой с помощью модемов (модулято-
ров/демодуляторов сигнала) и посредством множества разно-
образных линий связи.
Модем преобразует информацию, хранящуюся в компьютере,
в сигналы, которые могут быть переданы по телекоммуникацион-
ным линиям связи. И наоборот, принятые по линиям связи сигна-
лы с помощью мо
Дата добавления: 2021-11-16; просмотров: 786;
Поиск по сайту
Узнать еще
- III. Организационное обеспечение специальной оценки условий труда.
- Анализ системных требований к ЭИС
- Аппаратное обеспечение сети.
- АЭРОНАВИГАЦИОННОЕ (РАДИОНАВИГАЦИОННОЕ) ОБЕСПЕЧЕНИЕ ПОЛЕТОВ
- Аэронавигационное обеспечение полетов
- Б). Приказ о назначении лиц ответственных за обеспечение пожарной безопасности территории и здания, отдельных помещений образовательного учреждения
- Базовое программное обеспечение
- Базовое программное обеспечение

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
