Объединение записей в блоки и буферизация
Для сглаживания эффекта несоответствия скоростей между внутренними и внешними процессами в системах управления вводом-выводом применяют три основных метода: синхронизация по прерываниям ввода-вывода; буферизация ввода-вывода; блокирование данных.
Буферизация ввода-выводаоснована на размещении между внешним и внутренним процессами одного или нескольких буферов, роль которых выполняют, как правило, непрерывные области первичной памяти.
Буфер является критическим ресурсом для связанных с ним внутренних и внешних процессов (рис.5.7). Введение буферов как средства информационного взаимодействия выдвинуло задачу управления буферами, которая решается средствами супервизора ввода-вывода. На супервизор ввода-вывода возлагаются функции по выделению и уничтожению буферов в первичной памяти, синхронизации обращения к буферам внутренних и внешних процессов, устранения одновременного обращения к буферу этих процессов и т.п.
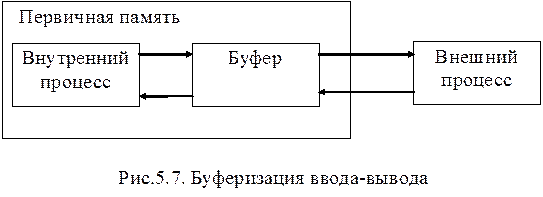
|
При решении задачи буферизации важным является определение количества буферов, закрепляемых за отдельным каналом или устройством, а также размер области первичной памяти, отводимой под каждый буфер.
Важным фактором при управлении буферами является также оперативность обновления информации в буфере. Не всегда является необходимым стремление наиболее быстрой передачи данных из заполненного буфера внешнему процессу. Иногда такую передачу целесообразно задержать на достаточно длительный интервал времени, поскольку хранимые в буфере данные могут понадобиться внутреннему процессу. В этом случае буфер ввода-вывода превращается в программный аналог кэш-памяти при работе с внешними устройствами. Задержка информации в буфере предполагает возможность обращения к ней со стороны программных (внутренних) процессов. Если бы эта информация была «сброшена» на внешнее запоминающее устройство сразу по мере заполнения буфера, то повторное обращение к ней со стороны внутреннего процесса потребовало бы обращение к этому устройству с операцией чтения данных. Оперативность в этом случае была бы существенно ниже, чем в случае использования программной кэш-памяти.
Блокирование данных – это операция объединения порций данных, которыми оперирует внутренний процесс (логические записи), в более крупные образования – блоки логических записей. Такие блоки логических записей называются физическими записями. Физическая запись является единицей обмена данными между первичной памятью и внешним устройством. Каждая физическая запись (блок) представляется на внешнем устройстве непрерывной областью. Чем больше длина блока, тем меньше непроизводительных затрат времени на выполнение операций ввода-вывода больших массивов данных и тем большее время канал работает автономно от центрального процессора. Однако с увеличением количества логических записей в блоке возрастают затраты времени на выполнение дополнительных операций по блокированию данных (при выводе) и деблокированию данных (при вводе). Кроме того, при этом возрастают требования к объему необходимой для реализации этих операций первичной памяти.
С другой стороны, длинные блоки «выгодны» для хранения на внешних запоминающих устройствах, так как количество памяти, отводимое для фиксации межблочных промежутков, в этом случае меньше, чем для коротких блоков (при одном и том же количестве хранимых полезных данных).
Противоречивые требования к длине физических записей делают проблематичным однозначный выбор длины блока при организации обмена данными между первичной памятью и внешним устройством. Поэтому в операционных системах решение этой проблемы нашли в следующем. В некоторых ОС, например, в MS DOS, Windows, Unix, размер блока определяется исходя из технических характеристик внешнего запоминающего устройства и контроллеров ввода-вывода. В других операционных системах определение параметров блокирования данных может быть возложено на программиста.
Управление файлами
5.4.1. Понятие файлового способа хранения данных
и файловой системы
С появлением в составе ЭВМ внешних запоминающих устройств, способных хранить огромные массивы информации в течение длительного времени, привело к необходимости разработки такого способа хранения и управления данными, при котором затраты на доступ к информации со стороны разработчиков прикладных систем и программ были бы сведены к минимуму.
В многопользовательских вычислительных системах вторичная (внешняя) память должна быть так же разделяема между пользователями, как и первичная. Такое разделение в современных операционных системах обеспечивается с использованием файлового способа хранения данных.
Файловый способ хранения данных – это способ хранения данных, при котором каждый набор данных представляются как именованное, возможно, защищенное, собрание записей, называемой файлом.
Файл – идентифицированная совокупность экземпляров полностью описанного в конкретной программе типа данных, находящихся вне программы во внешней памяти и доступных программе посредством специальных операций.
Файловая система – система управления данными с файловым способом хранения.
В результате применения файлового способа хранения данных пользователь получает виртуальное представление внешней памяти и работает с ней не в терминах команд управления конкретными физическими устройствами внешней памяти, а в терминах, обусловленных особенностями структуры и состава его конкретных наборов данных. Пользователь видит виртуальную внешнюю память как среду, способную хранить его обособленные и поименованные информационные объекты, имеющие определенную внутреннюю структуру. Среда должна обеспечить возможность хранения произвольного количества файлов без ограничения объема, причем пользователь должен иметь возможность доступа как к отдельным файлам, так и к их составным частям, с учетом логической структуры.
Файловые системы могут быть простыми и сложными. Их природа зависит от разнообразия применений и среды, в которой будет использоваться операционная система. В общем случае к файловой системе предъявляют следующие основные требования:
- каждый пользователь должен иметь возможность создавать, удалять и изменять файлы;
- каждый пользователь может иметь контролируемый доступ к файлам других пользователей;
- каждый пользователь может контролировать, какие типы доступа разрешены к его файлам;
- каждый пользователь должен иметь возможность переструктурировать свои файлы к форме, соответствующей его задачи;
- каждый пользователь должен иметь возможность пересылать данные между файлами;
- каждый пользователь должен иметь возможность копировать и восстанавливать свои файлы в случае их повреждения;
- каждый пользователь должен иметь возможность доступа к своим файлам по их символическим именам.
Для того, чтобы удовлетворить перечисленные выше требования, программная часть файловых систем должна содержать следующие компоненты:
- средства взаимодействия с процессами пользователей, обеспечивающие прием и интерпретацию запросов от пользователя на обработку файлов и сообщающие ему о результатах выполненной обработки;
- средства реализации методов доступа к файлу и к его составным элементам;
- средства распределения внешней памяти для хранения файлов, а также ее освобождения по мере уничтожения файлов;
- средства учета расположения файлов и их составных элементов.
Все перечисленные средства составляют логический уровень управления данными в файловой системе. Физическим уровнем в ней является система ввода-вывода. В таком обобщенном виде файловая система выступает как интерфейс между программными процессами и файлами (рис.5.8).
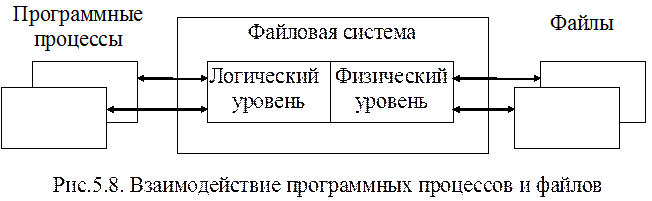
|
Различные подходы к построению файловых систем отличаются уровнем автоматизации действий по управлению данными. Несмотря на имеющиеся различия в построении, все файловые системы имеют совпадающие способы организации хранения файлов во внешней памяти.
Организация файлов
Физическая организация файлов зависит от физических характеристик внешнего устройства. Существуют внешние устройства, которые можно рассматривать как последовательные файлы, где обмен записями доступен только в линейном порядке. К ним относятся накопители на магнитных лентах, стримеры, принтеры, модемы и т.п. По сравнению с ними накопители на магнитных дисках допускают огромную гибкость организации файлов. На поверхности дисковой пластины расположена серия концентрических окружностей, называемых дорожками или цилиндрами диска. Каждая дорожка подразделяется на секторы. Сектор – это минимальный объем информации, обычно передаваемый в дисковой системе.
Физические записи могут располагаться в любом месте диска. Из соображений эффективности при поиске и передаче данных предпринимаются всевозможные попытки расположить связанные физические записи в смежных секторах или на соседних пластинах той же дорожки диска.
Структура диска позволяет системе управления файлами организовать файлы тремя различными способами: последовательным; непрерывным; сегментированным. Каждая организация файлов обладает своими ограничениями и характеристиками производительности.
Последовательная организация файла предполагает создание на диске последовательного файла.
Последовательный файл – файл, к компонентам которого обеспечивается лишь последовательный доступ в соответствии с упорядоченностью этих компонентов.
В последовательных файлах размещают наборы данных с последовательной организацией. Обычно в последовательных файлах используют один указатель от одного блока к другому (рис.5.9). Иногда для ускорения доступа применяют двойные ссылки.

|
Последовательный файл состоит из связанной последовательности блоков. В одном блоке последовательного файла может быть размещена одна или несколько записей последовательного набора данных. Доступ к последовательному файлу отличается простотой и достаточно быстр. Для того, чтобы найти нужную запись, файл должен быть просмотрен блок за блоком от начала файла, пока не будет найдена требуемая запись. При обработке последовательного файла в файловых системах рассматривают следующие случаи размещения логической записи в физических блоках:
- один физический блок под одну логическую запись;
- несколько физических блоков под одну логическую запись;
- один физический блок под несколько логических записей.
В первом случае необходимо считывать в первичную память только один физический блок. Логическая запись может быть обновлена на том же месте путем записи новых данных поверх старых. Включить новую запись довольно просто, т.к. система выделяет еще один физический блок и настраивает соответствующие указатели.
Во втором случае для того, чтобы получить логическую запись целиком, все физические блоки, занятые ею, должны быть считаны в память. Обновление логической записи производится так же, как и в первом случае – путем записи новых данных поверх старых в найденном физическом блоке. Относительно несложно добавить новую логическую запись, т.к. для этого система должна просто выделить необходимое число блоков для новой записи и настроить соответствующие указатели.
В третьем случае для обеспечения доступа к требуемой записи программа управления файлами должна сначала найти блок, где она находится. После того, как этот блок считан в первичную память, выполняется выделение нужной записи из содержимого блока. Добавить новую запись значительно сложнее, чем в первых двух случаях, т.к. если блок заполнен, необходимо перенести в новый блок одну или несколько записей из старого блока с соответствующей коррекцией указателей.
Доступ к записи в последовательном файле требует в среднем чтения и просмотра половины блоков файла.
Непрерывная организация файла предполагает создание на диске непрерывного файла.
Непрерывный файл – файл на носителе, состоящий из ряда физических блоков, которые все расположены в одной сплошной области дискового пространства.
Непрерывная организация файла представляет собой жесткую структуру, что обеспечивает самый быстрый доступ к данным. Размер непрерывного файла фиксирован и задается в момент создания файла. Файл не может быть увеличен в размере, однако уменьшение длины непрерывного файла допускается. Главный недостаток непрерывной организации файла в том, что во внешней памяти не всегда может быть выделено нужное количество смежных физических блоков.
Доступ к записям непрерывного файла достаточно прост. Если обозначить через r – номер записи, l – длину записи и L – длину блока, то номер b блока, где находится запись, вычисляется по формуле
b=l*r/L.
Значение b используется затем для считывания нужного блока в первичную память. Поскольку не нужно проходить по указателям, как в первом случае, то достигается существенное сокращение затрат времени на доступ к данным.
Обновление записи r совершается очень просто – она просто перекрывается новыми данными. При этом происходит обращение к нужному количеству физических блоков.
Для непрерывного файла имеют место те же три случая размещения логических записей в физических блоках, что и для последовательного файла. Включение новой записи в непрерывный файл очень сложно. Для этого системе, в среднем, необходимо переместить половину записей длиной l, прежде чем освободить место для новой записи. Включение новой записи в непрерывный файл может окончиться неудачей, если при сдвиге записей последняя запись будет передвинута за границу файла.
Сегментированная организация файла предполагает создание сегментированного файла.
Сегментированный файл – это файл, состоящий из последовательного индекса, содержащего адреса соответствующих блоков данных.
Сегментированный файл называют также индексным файлом.
Такая организация предназначена для преодоления недостатков доступа в последовательных файлах. Индекс представляет собой меру произвольности доступа и средство обслуживания добавления в файл.
Индекс строится как множество блоков указателей сегментов (БУС) и может быть организован последовательным или непрерывным способами. При непрерывном подходе максимальный размер файла считается известным (например, один дисковый том) и в соответствии с этим выделяется требуемое количество индексных блоков. В случае последовательного подхода размер файла не ограничивается. Однако поиск по последовательному индексу ставит те же проблемы, что и при поиске в последовательном файле. Каждый БУС в индексной файле содержит n элементов или указателей на блоки данных и, возможно, указатель на следующий индексный блок. Указатель на дисковый блок должен иметь размер, достаточный для представления всего диапазона адресов на запоминающем устройстве.
Получение записи из сегментированного файла требует не более двух обращений к диску. В первую очередь вычисляется адрес индексного блока, и он считывается в память. Затем из него извлекается адрес блока данных, и тот считывается в память. Включение новой записи в сегментированный файл также не вызывает больших затруднений.
Дата добавления: 2017-01-26; просмотров: 2538;
Поиск по сайту
Узнать еще
- XI династия. Объединение Египта под властью Фив
- Автоколебательный блокинг-генератор
- Активизация и блокирование строк меню
- Активный контроль заготовок до обработки. Блокирующие устройства
- АНТИБЛОКИРОВОЧНЫЕ СИСТЕМЫ
- Б. Средства, блокирующие адренергические синапсы
- БЛОКИ ВКЛЮЧЕНИЯ КОММУТАЦИОННЫХ ЭЛЕМЕНТОВ
- Блоки оконные и дверные

Публикации по технике и механике

Публикации по биологии

Публикации по информатике

Публикации по строительству

Публикации по физике

Публикации по химии

Публикации по электронике

Публикации по искусству

Публикации по географии

Публикации по медицине
