|
| Часть 17.5.1
Слух и речь Часть 5 Акустические характеристики вокальной речиИрина Алдошина
В предыдущих статьях из серии "Слух и речь" были рассмотрены способы образования речи и ее акустические характеристики. В данной статье остановимся на специфических акустических характеристиках вокальной речи, работа с которой составляет значительную часть деятельности звукорежиссеров, особенно при известном уровне вокального искусства на современной эстраде.
Термин "вокальная речь" обозначает то же, что и термин "пение", но пение – это прежде всего музыкально-эстетический термин ("искусство пения"). Под термином "вокальная речь" понимается рассмотрение процесса пения с позиций акустики, поэтому при дальнейшем изложении будет использоваться в основном первый термин.
Информацию, которую несет речевой сигнал, принято делить на семантическую (смысловую, логическую) и эмоционально-эстетическую.
Если в разговорной речи основным является первый вид информации, то в вокальной речи главная задача состоит в передаче эмоционально-эстетической информации.
Эти задачи, а также особенности их реализации (оперное, концертное, хоровое пение, эстрадное и др.), привели к тому, что вокальная речь, несмотря на наличие общего механизма звукообразования, имеет ряд существенных отличий от обычной речи. Они заключаются, прежде всего, в следующем:
- специфике организации дыхания; - использовании различных регистров; - наличии специфической структуры формант, характеризующейся появлением особых певческих формант; - способности к подстройке формант в верхнем диапазоне певческого голоса; - наличии амплитудной и частотной модуляций (вибрато и тремоло); - больших эмоциональных флюктуациях параметров звукообразования; - особой системе обратной связи (эффект Томатиса) и др.
Все это обусловливает специфику акустических характеристик вокальной речи – более широкий частотный диапазон, большой динамический диапазон, особое спектральное распределение мощности и др., – и также создает специфические проблемы с разборчивостью.
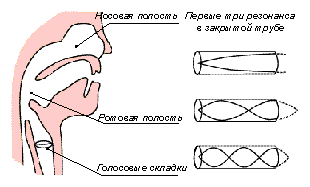 Рис. 1 Общая структура вокального тракта
Процесс звукообразования вокальной речи (пения) включает в себя все основные этапы, которые используются при создании обычной речи: аспирации (генерации), фонации (для гласных и звонких согласных), артикуляции и излучения (рисунок 1). Однако перечисленные особенности вокальной речи вносят свои коррективы в организацию процессов, связанных с использованием как голосовых источников, так и резонаторных полостей (артикуляционного аппарата).
Начнем рассмотрение с резонаторных свойств, поскольку они создают наиболее заметные отличия в акустических характеристиках вокальной речи. К их числу прежде всего относятся появление певческой форманты, эффект подстройки формант, отличия в первых формантах, особенности частотных диапазонов различных голосов и др.
Это обусловлено особыми требованиями к тембру певческого голоса, музыкальной экспрессивности, к мощности, обеспечивающей слышимость голоса на фоне аккомпанемента (например, симфонического оркестра), к способности воспроизводить широкий звуковысотный диапазон и др. Субъективные оценки тембра певческого голоса связаны, прежде всего, с его спектральными характеристиками (звонкость, яркость, полетность и др.), которые зависят как от спектрального состава звука, создаваемого голосовым источником, так и от использования резонансных свойств артикуляционных органов. Поэтому особые требования к тембру певческого голоса, существенно отличающиеся от требований к обычной речи, приводят в первую очередь к особенностям в настройке резонансов голосового тракта, т.е. его формантных частот.
Певческая форманта Рис. 1 Общая структура вокального тракта
Процесс звукообразования вокальной речи (пения) включает в себя все основные этапы, которые используются при создании обычной речи: аспирации (генерации), фонации (для гласных и звонких согласных), артикуляции и излучения (рисунок 1). Однако перечисленные особенности вокальной речи вносят свои коррективы в организацию процессов, связанных с использованием как голосовых источников, так и резонаторных полостей (артикуляционного аппарата).
Начнем рассмотрение с резонаторных свойств, поскольку они создают наиболее заметные отличия в акустических характеристиках вокальной речи. К их числу прежде всего относятся появление певческой форманты, эффект подстройки формант, отличия в первых формантах, особенности частотных диапазонов различных голосов и др.
Это обусловлено особыми требованиями к тембру певческого голоса, музыкальной экспрессивности, к мощности, обеспечивающей слышимость голоса на фоне аккомпанемента (например, симфонического оркестра), к способности воспроизводить широкий звуковысотный диапазон и др. Субъективные оценки тембра певческого голоса связаны, прежде всего, с его спектральными характеристиками (звонкость, яркость, полетность и др.), которые зависят как от спектрального состава звука, создаваемого голосовым источником, так и от использования резонансных свойств артикуляционных органов. Поэтому особые требования к тембру певческого голоса, существенно отличающиеся от требований к обычной речи, приводят в первую очередь к особенностям в настройке резонансов голосового тракта, т.е. его формантных частот.
Певческая форманта
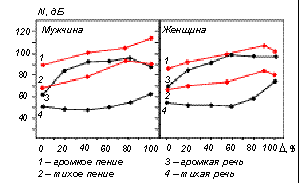 Рис. 2 Сравнительный уровень звукового давления при пении и речи ( - изменение частоты фонации)
Для того, чтобы голос оперного певца (или концертного исполнителя) был слышен на фоне оркестра, необходимо, прежде всего, развивать значительно более высокий уровень звукового давления – проще говоря, петь громче. Сравнительный анализ уровней звукового давления на расстоянии 0,5 м при пении и речи для разных частот фонации (высоты тона) показан на рисунке 2. Однако одного увеличения громкости оказывается недостаточно для решения этой проблемы, поэтому в процессе многолетнего совершенствования техники пения, прежде всего оперного (bel canto), были отработаны особые приемы перестройки спектральных характеристик голоса, в частности создание так называемой певческой форманты. Рис. 2 Сравнительный уровень звукового давления при пении и речи ( - изменение частоты фонации)
Для того, чтобы голос оперного певца (или концертного исполнителя) был слышен на фоне оркестра, необходимо, прежде всего, развивать значительно более высокий уровень звукового давления – проще говоря, петь громче. Сравнительный анализ уровней звукового давления на расстоянии 0,5 м при пении и речи для разных частот фонации (высоты тона) показан на рисунке 2. Однако одного увеличения громкости оказывается недостаточно для решения этой проблемы, поэтому в процессе многолетнего совершенствования техники пения, прежде всего оперного (bel canto), были отработаны особые приемы перестройки спектральных характеристик голоса, в частности создание так называемой певческой форманты.
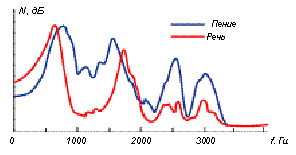 Рис. 3 Расположение формант при речи и пении
Если сравнить расположение формантных частот (т.е. резонансов вокального тракта) для одних и тех же гласных в обычной и вокальной речи, то отчетливо видно, что для всех гласных положение первой форманты на шкале частот мало изменилось, вторая форманта в случае вокальной речи сдвинута по частоте вниз, значительно изменились положения третьей, четвертой и пятой формант в сторону их совместного сближения (рисунок 3). Рис. 3 Расположение формант при речи и пении
Если сравнить расположение формантных частот (т.е. резонансов вокального тракта) для одних и тех же гласных в обычной и вокальной речи, то отчетливо видно, что для всех гласных положение первой форманты на шкале частот мало изменилось, вторая форманта в случае вокальной речи сдвинута по частоте вниз, значительно изменились положения третьей, четвертой и пятой формант в сторону их совместного сближения (рисунок 3).
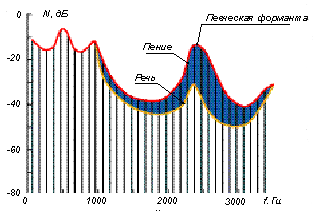 Рис. 4 Форма огибающего спектра при речи и пении
Если проанализировать спектральную огибающую любого из гласных звуков при речи и пении (рисунок 4), то отчетливо видно наличие выраженного пика в области 2…3 кГц. Этот пик создается в результате объединения (кластеризации) третьей, четвертой и пятой формант и носит название "певческой форманты".
Такая группа подчеркнутых формант наблюдается только в спектрах хорошо поставленных, чаще оперных, голосов, как показано в работах В.П.Морозова и Дж. Сандберга (наиболее известные ученые, занимающиеся проблемами акустики певческого голоса). При этом центральная частота располагается в зависимости от типа голоса в области: бас и баритон – 2,1…2,5 кГц, тенор – 2,5…2,8 кГц, сопрано – 3…3,5 кГц.
Для одного и того же певца эта форманта не смещается по частоте, она стабильно занимает одно и то же положение при пении нот разной высоты (рисунок 5а) или разных гласных (рисунок 5б). Таким образом, положение этой форманты не зависит ни от фундаментальной частоты (это свойство подстройки есть у других формант), ни от позиции других резонансов (нижних формант). Рис. 4 Форма огибающего спектра при речи и пении
Если проанализировать спектральную огибающую любого из гласных звуков при речи и пении (рисунок 4), то отчетливо видно наличие выраженного пика в области 2…3 кГц. Этот пик создается в результате объединения (кластеризации) третьей, четвертой и пятой формант и носит название "певческой форманты".
Такая группа подчеркнутых формант наблюдается только в спектрах хорошо поставленных, чаще оперных, голосов, как показано в работах В.П.Морозова и Дж. Сандберга (наиболее известные ученые, занимающиеся проблемами акустики певческого голоса). При этом центральная частота располагается в зависимости от типа голоса в области: бас и баритон – 2,1…2,5 кГц, тенор – 2,5…2,8 кГц, сопрано – 3…3,5 кГц.
Для одного и того же певца эта форманта не смещается по частоте, она стабильно занимает одно и то же положение при пении нот разной высоты (рисунок 5а) или разных гласных (рисунок 5б). Таким образом, положение этой форманты не зависит ни от фундаментальной частоты (это свойство подстройки есть у других формант), ни от позиции других резонансов (нижних формант).
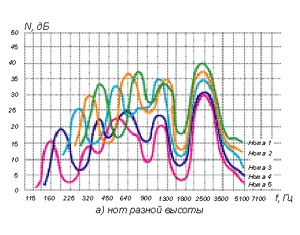 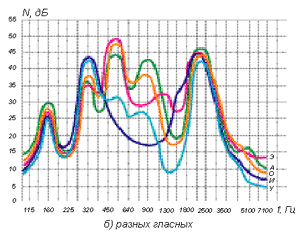 Рис. 5 Положение ВПФ при пении
Амплитуда певческой форманты зависит как от амплитуд объединяемых формант (третьей, четвертой и пятой), так и от амплитуд соответствующих обертонов в спектре голосового источника, а это, в свою очередь, зависит от особенностей использования голосового источника (в частности, скорости и силы сведения при колебаниях голосовых связок). Кроме того, поскольку при увеличении громкости огибающая спектра звука голосового источника меняется и увеличивается амплитуда высоких обертонов, то и амплитуда певческой форманты будет в громких звуках выше.
Исследования, выполненные различными учеными (результаты приведены, например, в замечательной книге В.П.Морозова "Биофизические основы вокальной речи"), показали, что при прослушивании записей певческих голосов, из которых электрическим путем вырезалась высокая певческая форманта, в голосе теряется звонкость, полетность, чистота и ясность тембра, голос звучит тускло, глухо, невыразительно.
Звучание высокой певческой форманты в изолированном виде (например, если отфильтровать в записи все частотные области, кроме третьего-четвертого резонансов) воспринимается как звонкий мелодичный звук типа соловьиной трели. Он слышен при пении любой гласной, усиливаясь при увеличении громкости. Эти опыты позволили установить, что от наличия и амплитуды высокой певческой форманты зависит звонкость певческого голоса. Интересно отметить, что у старинных скрипок (Страдивари, Амати, Гварнери), отличающихся особой звонкостью, полетностью звука, также в этой области частот (2,5…3 кГц) находится область выраженных резонансов (третья форманта). В работах В.П.Морозова была даже предложена количественная величина K – коэффициент звонкости голоса:
K = Iвпф/ I,
где: Iвпф – интенсивность спектра в области высокой певческой форманты, I – общая интенсивность голоса. Измерения, проведенные у разных категорий певцов, показали, что у выдающихся певцов этот коэффициент достигает 33…35%, у неквалифицированных певцов – 5…11%, а у детей – 3%.
Однако основной причиной использования певческой форманты в оперных голосах является, по-видимому, повышение помехоустойчивости голоса.
Средний уровень оркестра при достаточно громком исполнении в концертном зале составляет 90…100 дБ. Создание такого среднего уровня выше возможностей человеческого голоса. Кроме того, маскирующее действие оркестра зависит от частотного распределения спектральных уровней. Рис. 5 Положение ВПФ при пении
Амплитуда певческой форманты зависит как от амплитуд объединяемых формант (третьей, четвертой и пятой), так и от амплитуд соответствующих обертонов в спектре голосового источника, а это, в свою очередь, зависит от особенностей использования голосового источника (в частности, скорости и силы сведения при колебаниях голосовых связок). Кроме того, поскольку при увеличении громкости огибающая спектра звука голосового источника меняется и увеличивается амплитуда высоких обертонов, то и амплитуда певческой форманты будет в громких звуках выше.
Исследования, выполненные различными учеными (результаты приведены, например, в замечательной книге В.П.Морозова "Биофизические основы вокальной речи"), показали, что при прослушивании записей певческих голосов, из которых электрическим путем вырезалась высокая певческая форманта, в голосе теряется звонкость, полетность, чистота и ясность тембра, голос звучит тускло, глухо, невыразительно.
Звучание высокой певческой форманты в изолированном виде (например, если отфильтровать в записи все частотные области, кроме третьего-четвертого резонансов) воспринимается как звонкий мелодичный звук типа соловьиной трели. Он слышен при пении любой гласной, усиливаясь при увеличении громкости. Эти опыты позволили установить, что от наличия и амплитуды высокой певческой форманты зависит звонкость певческого голоса. Интересно отметить, что у старинных скрипок (Страдивари, Амати, Гварнери), отличающихся особой звонкостью, полетностью звука, также в этой области частот (2,5…3 кГц) находится область выраженных резонансов (третья форманта). В работах В.П.Морозова была даже предложена количественная величина K – коэффициент звонкости голоса:
K = Iвпф/ I,
где: Iвпф – интенсивность спектра в области высокой певческой форманты, I – общая интенсивность голоса. Измерения, проведенные у разных категорий певцов, показали, что у выдающихся певцов этот коэффициент достигает 33…35%, у неквалифицированных певцов – 5…11%, а у детей – 3%.
Однако основной причиной использования певческой форманты в оперных голосах является, по-видимому, повышение помехоустойчивости голоса.
Средний уровень оркестра при достаточно громком исполнении в концертном зале составляет 90…100 дБ. Создание такого среднего уровня выше возможностей человеческого голоса. Кроме того, маскирующее действие оркестра зависит от частотного распределения спектральных уровней.
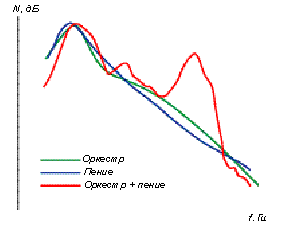 Рис. 6 Огибающая звуков оркестра, речи и пения
Если сравнить огибающую долговременного спектра для звуков оркестра и для звуков нормальной речи и пения (рисунок 6), то видно, что максимум энергии в звуках оркестра находится в области 400…500 Гц, затем ее уровень быстро спадает и в области 2,5…3 кГц становится ниже на 20 дБ.
Примерно такое же распределение энергии и в звуках обычной речи (только ниже по уровню громкости), и поэтому она будет полностью замаскирована звуками оркестра. В певческом голосе до 30% энергии может быть сосредоточено в певческой форманте в области 2…3 кГц, которая к тому же совпадает с областью максимальной чувствительности слуха. Такая перегруппировка формант и позволяет услышать певческий голос на фоне оркестра. Это свойство голоса "перекрывать" оркестр называется "полетностью".
Следует отметить две слуховые особенности. Тихий звук ниже порога маскера (маскирующего звука) может быть услышан, если он вступает чуть раньше по времени или регулярно варьируется по времени. Звук оркестра непрерывно меняется по уровню, поэтому необязательно все время слышать певческую форманту, достаточно слышать ее в определенные моменты, когда звук оркестра становится тише в этой области. Если маскер регулярно прерывать, то тихий звук можно не только услышать, но он может быть услышан как непрерывный во времени – слуховая система сама достраивает звучание, делает интерполяцию во времени.
Следующее преимущество певческой форманты относится к условиям излучения. Низкие частоты излучаются во всех направлениях (здесь рот – это ненаправленный источник звука), а высокие концентрируются только вперед, поэтому высокие частоты меньше поглощаются обратной стороной сцены, декорациями и др. Если в голосе есть певческая форманта, т.е. высокий уровень обертонов в высокочастотной части диапазона, то они попадают к слушателю менее поглощенными, чем низкочастотные компоненты, что помогает слушателю выделить голос певца из сопровождения оркестра (если он стоит лицом к слушателю). Это соответствует требованиям педагогов "сфокусировать" голос для слышимости в большой аудитории, что можно сделать только при наличии певческой форманты.
Механизм образования певческой форманты служит предметом многочисленных исследований. Результаты рентгенологических исследований показывают, что при пении профессиональных опытных певцов гортань занимает значительно более низкое положение, чем при речи (снижение до 15 мм). При этом удлиняется общая длина вокального тракта и глотки ("Звукорежиссер", 1/2002), что приводит к некоторому снижению второй форманты. При опускании гортани значительно расширяются боковые стенки дна глотки. При этом, если диаметр трубы гортани (в глубине которой на расстоянии примерно 20 мм от края находятся голосовые связки) составляет 1/6 от диаметра расширенной трубы глотки, то четвертая форманта снижается от 3,5 кГц (где она обычно находится у взрослого мужчины) до 2,8 кГц. Таким образом, за кластеризацию (объединение) высших формант в единую певческую форманту ответственна резонансная полость, которая образуется трубой гортани и дном расширенной глотки, слегка прикрытой надгортанником. Длина этой полости составляет примерно 1/6 длины всего тракта, нижний край полости ограничен голосовой щелью, верхний – кольцом надгортанника.
Такой метод образования певческой форманты за счет понижения позиции гортани и значительного расширения глотки используется не во всех манерах пения. Например, в китайской опере (или в некоторых видах средневекового пения) имеет место значительная певческая форманта, но без понижения позиции гортани, а, очевидно, за счет другой организации тракта.
Имеются и другие теории образования высокой певческой форманты: например, как краевых тонов, возникающих за счет турбулентного потока при прохождении струи воздуха через щель голосовых связок (как у флейты) и др.
Имеется значительное противоречие между использованием положения гортани в речи и пении: если при повышении высоты тона в обычной речи гортань занимает все более и более высокое положение, то при профессиональном мужском пении при повышении высоты тона положение гортани снижается, что требует специального обучения. Расширение гортани и снижение глотки ("открытое горло") при пении в грудном регистре являются признаками хорошо поставленного профессионального голоса.
Таким образом, спектральная перестройка голоса позволяет получить значительный энергетический выигрыш, повысить помехоустойчивость и звонкость голоса без увеличения энергетических затрат голосового источника. Не удивительно, что этот прием, найденный в процессе совершенствования техники пения, особенно пения "бель канто", получил такое широкое распространение.
Существуют виды пения, где певческая форманта не используется, например, хоровое пение, пение в бытовой манере, современное эстрадное пение, где баланс и тембр регулируются системой звукоусиления, и певческая форманта, т.е. усиление особой группы обертонов, может быть сформирована звукорежиссером. Вообще, качество пения у многих современных певцов – это почти исключительно искусство звукорежиссера, а не исполнителя, поэтому таким успехом и пользуется пение под фонограмму (под "фанеру").
Местоположение певческой форманты играет большую роль в классификации голосов, так как каждый голос – бас, баритон, тенор – имеет четкую позицию форманты, что, очевидно, отражает различия в длине вокального тракта и форме глотки. Следует еще отметить, что певческая форманта служит тембральной "униформой" для всех певческих гласных – в речи уровень третьей форманты отличается, например, на 28 дБ для "и" и "у", а уровень певческой форманты для всех гласных примерно одинаков.
Подстройка формантных частот
Следующей характерной особенностью акустических свойств вокальной речи является способность к подстройке формант. При пении на высоких тонах, особенно в женском пении, перестройка формант, приводящая к появлению певческой форманты, часто не используется. Во-первых, у высоких женских голосов другая структура вокального тракта (короче длина, трудно реализовать опускание гортани и расширение глотки и др.), во-вторых, наличие значительного подъема в области 3 кГц может привести к "пестроте" голоса, потому что при высокой фонационной частоте, например 700 Гц (F5), обертоны находятся на расстоянии 700 Гц друг от друга (редко), и поэтому отдельные обертоны будут то попадать, то не попадать в формантную область при сдвиге основной частоты, в отличие от обычной картины заполнения формантных областей при низкой фонационной частоте (рисунок 7). Поэтому в женском пении (и в высоких мужских голосах) используется другой способ повышения помехоустойчивости голоса, обеспечивающий его слышимость на фоне оркестра, который получил название "подстройка формант". Рис. 6 Огибающая звуков оркестра, речи и пения
Если сравнить огибающую долговременного спектра для звуков оркестра и для звуков нормальной речи и пения (рисунок 6), то видно, что максимум энергии в звуках оркестра находится в области 400…500 Гц, затем ее уровень быстро спадает и в области 2,5…3 кГц становится ниже на 20 дБ.
Примерно такое же распределение энергии и в звуках обычной речи (только ниже по уровню громкости), и поэтому она будет полностью замаскирована звуками оркестра. В певческом голосе до 30% энергии может быть сосредоточено в певческой форманте в области 2…3 кГц, которая к тому же совпадает с областью максимальной чувствительности слуха. Такая перегруппировка формант и позволяет услышать певческий голос на фоне оркестра. Это свойство голоса "перекрывать" оркестр называется "полетностью".
Следует отметить две слуховые особенности. Тихий звук ниже порога маскера (маскирующего звука) может быть услышан, если он вступает чуть раньше по времени или регулярно варьируется по времени. Звук оркестра непрерывно меняется по уровню, поэтому необязательно все время слышать певческую форманту, достаточно слышать ее в определенные моменты, когда звук оркестра становится тише в этой области. Если маскер регулярно прерывать, то тихий звук можно не только услышать, но он может быть услышан как непрерывный во времени – слуховая система сама достраивает звучание, делает интерполяцию во времени.
Следующее преимущество певческой форманты относится к условиям излучения. Низкие частоты излучаются во всех направлениях (здесь рот – это ненаправленный источник звука), а высокие концентрируются только вперед, поэтому высокие частоты меньше поглощаются обратной стороной сцены, декорациями и др. Если в голосе есть певческая форманта, т.е. высокий уровень обертонов в высокочастотной части диапазона, то они попадают к слушателю менее поглощенными, чем низкочастотные компоненты, что помогает слушателю выделить голос певца из сопровождения оркестра (если он стоит лицом к слушателю). Это соответствует требованиям педагогов "сфокусировать" голос для слышимости в большой аудитории, что можно сделать только при наличии певческой форманты.
Механизм образования певческой форманты служит предметом многочисленных исследований. Результаты рентгенологических исследований показывают, что при пении профессиональных опытных певцов гортань занимает значительно более низкое положение, чем при речи (снижение до 15 мм). При этом удлиняется общая длина вокального тракта и глотки ("Звукорежиссер", 1/2002), что приводит к некоторому снижению второй форманты. При опускании гортани значительно расширяются боковые стенки дна глотки. При этом, если диаметр трубы гортани (в глубине которой на расстоянии примерно 20 мм от края находятся голосовые связки) составляет 1/6 от диаметра расширенной трубы глотки, то четвертая форманта снижается от 3,5 кГц (где она обычно находится у взрослого мужчины) до 2,8 кГц. Таким образом, за кластеризацию (объединение) высших формант в единую певческую форманту ответственна резонансная полость, которая образуется трубой гортани и дном расширенной глотки, слегка прикрытой надгортанником. Длина этой полости составляет примерно 1/6 длины всего тракта, нижний край полости ограничен голосовой щелью, верхний – кольцом надгортанника.
Такой метод образования певческой форманты за счет понижения позиции гортани и значительного расширения глотки используется не во всех манерах пения. Например, в китайской опере (или в некоторых видах средневекового пения) имеет место значительная певческая форманта, но без понижения позиции гортани, а, очевидно, за счет другой организации тракта.
Имеются и другие теории образования высокой певческой форманты: например, как краевых тонов, возникающих за счет турбулентного потока при прохождении струи воздуха через щель голосовых связок (как у флейты) и др.
Имеется значительное противоречие между использованием положения гортани в речи и пении: если при повышении высоты тона в обычной речи гортань занимает все более и более высокое положение, то при профессиональном мужском пении при повышении высоты тона положение гортани снижается, что требует специального обучения. Расширение гортани и снижение глотки ("открытое горло") при пении в грудном регистре являются признаками хорошо поставленного профессионального голоса.
Таким образом, спектральная перестройка голоса позволяет получить значительный энергетический выигрыш, повысить помехоустойчивость и звонкость голоса без увеличения энергетических затрат голосового источника. Не удивительно, что этот прием, найденный в процессе совершенствования техники пения, особенно пения "бель канто", получил такое широкое распространение.
Существуют виды пения, где певческая форманта не используется, например, хоровое пение, пение в бытовой манере, современное эстрадное пение, где баланс и тембр регулируются системой звукоусиления, и певческая форманта, т.е. усиление особой группы обертонов, может быть сформирована звукорежиссером. Вообще, качество пения у многих современных певцов – это почти исключительно искусство звукорежиссера, а не исполнителя, поэтому таким успехом и пользуется пение под фонограмму (под "фанеру").
Местоположение певческой форманты играет большую роль в классификации голосов, так как каждый голос – бас, баритон, тенор – имеет четкую позицию форманты, что, очевидно, отражает различия в длине вокального тракта и форме глотки. Следует еще отметить, что певческая форманта служит тембральной "униформой" для всех певческих гласных – в речи уровень третьей форманты отличается, например, на 28 дБ для "и" и "у", а уровень певческой форманты для всех гласных примерно одинаков.
Подстройка формантных частот
Следующей характерной особенностью акустических свойств вокальной речи является способность к подстройке формант. При пении на высоких тонах, особенно в женском пении, перестройка формант, приводящая к появлению певческой форманты, часто не используется. Во-первых, у высоких женских голосов другая структура вокального тракта (короче длина, трудно реализовать опускание гортани и расширение глотки и др.), во-вторых, наличие значительного подъема в области 3 кГц может привести к "пестроте" голоса, потому что при высокой фонационной частоте, например 700 Гц (F5), обертоны находятся на расстоянии 700 Гц друг от друга (редко), и поэтому отдельные обертоны будут то попадать, то не попадать в формантную область при сдвиге основной частоты, в отличие от обычной картины заполнения формантных областей при низкой фонационной частоте (рисунок 7). Поэтому в женском пении (и в высоких мужских голосах) используется другой способ повышения помехоустойчивости голоса, обеспечивающий его слышимость на фоне оркестра, который получил название "подстройка формант".
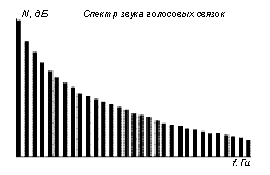 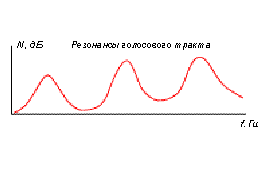 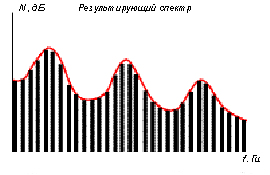 Рис. 7 Заполнение форматных областей обертонами
Большинство певцов использует в пении значение фундаментальной частоты выше, чем в обычной речи. В речи средняя фундаментальная частота составляет 110 Гц для мужского голоса и 200 Гц для женского (максимальный предел 200 и 350 Гц соответственно). В то же время в пении для высших нот сопрано, альта, тенора, баритона и баса значения фундаментальной частоты равны 1400 (С6), 700 (F5), 523 (C5), 390 (G4 ) и 350 (F4) Гц. Поэтому в речи первая форманта обычно выше, чем фундаментальная частота, а в пении во многих случаях первая форманта оказывается ниже ее. То есть, способность вокального тракта усиливать звук будет проявляться на частоте, где никакого звука от голосового источника не поступает. Рис. 7 Заполнение форматных областей обертонами
Большинство певцов использует в пении значение фундаментальной частоты выше, чем в обычной речи. В речи средняя фундаментальная частота составляет 110 Гц для мужского голоса и 200 Гц для женского (максимальный предел 200 и 350 Гц соответственно). В то же время в пении для высших нот сопрано, альта, тенора, баритона и баса значения фундаментальной частоты равны 1400 (С6), 700 (F5), 523 (C5), 390 (G4 ) и 350 (F4) Гц. Поэтому в речи первая форманта обычно выше, чем фундаментальная частота, а в пении во многих случаях первая форманта оказывается ниже ее. То есть, способность вокального тракта усиливать звук будет проявляться на частоте, где никакого звука от голосового источника не поступает.
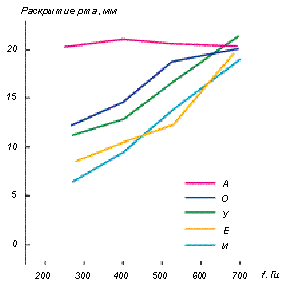 Рис. 8 Связь между шириной открытия рта и частотой фонации
Как только первая форманта становится ниже по частоте, чем фундаментальная частота, певцы стараются подтянуть первую форманту к фундаментальной частоте, широко открывая рот. Это объясняет, почему открытие рта у певцов зависит от высоты тона, а не от типа гласной, как в обычной речи (рисунок 8). Поскольку открытие челюстей вызывает повышение первой форманты, то сопрано при пении увеличивает ее открытие синхронно с частотой фонации, обеспечивая при этом сдвиг – подстройку первой формантной области к частоте фонации. На рисунке 9 показано, как сдвигаются первые три форманты в женском оперном пении при увеличении высоты тона (величины фундаментальной частоты). Эта методика используется для большинства гласных в верхнем регистре сопрано, а также в верхнем диапазоне тенорами. Открытие губ не увеличивает эффективность излучения, так как источник не производит больше энергии, но это сдвигает форманты, что может изменить перераспределение энергии в определенных диапазонах и улучшить помехозащищенность. Рис. 8 Связь между шириной открытия рта и частотой фонации
Как только первая форманта становится ниже по частоте, чем фундаментальная частота, певцы стараются подтянуть первую форманту к фундаментальной частоте, широко открывая рот. Это объясняет, почему открытие рта у певцов зависит от высоты тона, а не от типа гласной, как в обычной речи (рисунок 8). Поскольку открытие челюстей вызывает повышение первой форманты, то сопрано при пении увеличивает ее открытие синхронно с частотой фонации, обеспечивая при этом сдвиг – подстройку первой формантной области к частоте фонации. На рисунке 9 показано, как сдвигаются первые три форманты в женском оперном пении при увеличении высоты тона (величины фундаментальной частоты). Эта методика используется для большинства гласных в верхнем регистре сопрано, а также в верхнем диапазоне тенорами. Открытие губ не увеличивает эффективность излучения, так как источник не производит больше энергии, но это сдвигает форманты, что может изменить перераспределение энергии в определенных диапазонах и улучшить помехозащищенность.
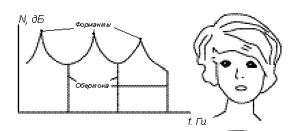 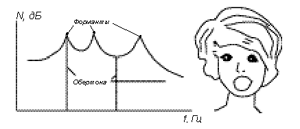 Рис. 9 Подстройка формант
Подстройка формант под первую фундаментальную частоту позволяет получить выигрыш в звуковом давлении, максимальное значение которого составляет 30 дБ. Это усиление звука является, как и певческая форманта, чисто резонансным процессом. Оно происходит без увеличения затрат энергии от вокального источника (колебаний голосовых связок). Выигрыш в громкости необходим также в связи с пением в сопровождении оркестра, других певцов или аккомпанемента.
Для большинства гласных значение первой форманты лежит в области 300…800 Гц. Отсюда получается, что гласные, у которых первые форманты ниже 500 Гц, могут маскироваться оркестром. Если фундаментальная частота превышает 500 Гц (В4), и происходит подстройка формант (сближение, кластеризация формантных частот), то общая громкость усиливается, поскольку первая и вторая форманты, где имеет место максимальное усиление звука, сдвигаются по частотному диапазону и сближаются друг с другом, и высокие женские голоса хорошо слышны даже на фоне громкого оркестра. То есть достигается такой же эффект, как и в мужских и низких женских голосах, где для этих целей используется другой механизм– певческая форманта.
Модификация качества гласных
В пении для повышения формантной частоты при повышении высоты тона используется еще один прием, получивший название "модификация гласных".
Пение как с подстройкой формант, так и с певческой формантой, требует перестройки вокального тракта: расширения глотки, снижения гортани и др., что, естественно, влияет на две низшие формантные частоты, которые критичны для идентификации гласных. Сравнение всех формантных частот при речи и пении (рисунок 3) показывает, что вторая и третья форманты значительно различаются (вторая форманта при пении ниже по частоте), что оказывает влияние на разборчивость гласных. Поэтому при пении используется прием модифицикации гласных (например, "э" заменяется на "а" и т.д.) для того, чтобы перейти на гласные звуки, формантные области которых ближе к тем, которые формируются при вокальной речи с высокой певческой формантой.
Интегральные характеристики вокальной речи Рис. 9 Подстройка формант
Подстройка формант под первую фундаментальную частоту позволяет получить выигрыш в звуковом давлении, максимальное значение которого составляет 30 дБ. Это усиление звука является, как и певческая форманта, чисто резонансным процессом. Оно происходит без увеличения затрат энергии от вокального источника (колебаний голосовых связок). Выигрыш в громкости необходим также в связи с пением в сопровождении оркестра, других певцов или аккомпанемента.
Для большинства гласных значение первой форманты лежит в области 300…800 Гц. Отсюда получается, что гласные, у которых первые форманты ниже 500 Гц, могут маскироваться оркестром. Если фундаментальная частота превышает 500 Гц (В4), и происходит подстройка формант (сближение, кластеризация формантных частот), то общая громкость усиливается, поскольку первая и вторая форманты, где имеет место максимальное усиление звука, сдвигаются по частотному диапазону и сближаются друг с другом, и высокие женские голоса хорошо слышны даже на фоне громкого оркестра. То есть достигается такой же эффект, как и в мужских и низких женских голосах, где для этих целей используется другой механизм– певческая форманта.
Модификация качества гласных
В пении для повышения формантной частоты при повышении высоты тона используется еще один прием, получивший название "модификация гласных".
Пение как с подстройкой формант, так и с певческой формантой, требует перестройки вокального тракта: расширения глотки, снижения гортани и др., что, естественно, влияет на две низшие формантные частоты, которые критичны для идентификации гласных. Сравнение всех формантных частот при речи и пении (рисунок 3) показывает, что вторая и третья форманты значительно различаются (вторая форманта при пении ниже по частоте), что оказывает влияние на разборчивость гласных. Поэтому при пении используется прием модифицикации гласных (например, "э" заменяется на "а" и т.д.) для того, чтобы перейти на гласные звуки, формантные области которых ближе к тем, которые формируются при вокальной речи с высокой певческой формантой.
Интегральные характеристики вокальной речи
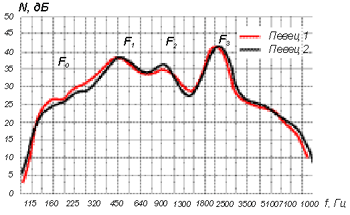 Рис. 10 Три области максимумов на огибающей вокальной речи
Если произвести статистическую обработку спектров вокальной речи большого количества певцов с их индивидуальными формантами, то в среднем получаются кривые, показанные на рисунке 10. На них отчетливо видны три области максимумов (чего нет на обобщенной спектральной кривой для речи). Наибольших уровней достигает в мужских голосах третья область – это высокая певческая форманта, о которой уже было сказано выше.
Первую область называют первой (нижней) певческой формантой, она определяет мягкость, массивность голоса. Вторая область, которую называют артикуляционной (фонетической) формантой, ниже по уровню и совпадает со второй формантой звука "а" (хотя певец поет все гласные, по-видимому, при пении они все становятся ближе к "а" по артикуляции). Различия между басами, баритонами и тенорами отчетливо видны на расположении этих трех максимумов:
F1, Гц F2, Гц F3, Гц Басы 380…540 760…1100 2100…2500 Баритоны 450…540 1100 2500 Тенора 540…640 1300 2500…3000 Рис. 10 Три области максимумов на огибающей вокальной речи
Если произвести статистическую обработку спектров вокальной речи большого количества певцов с их индивидуальными формантами, то в среднем получаются кривые, показанные на рисунке 10. На них отчетливо видны три области максимумов (чего нет на обобщенной спектральной кривой для речи). Наибольших уровней достигает в мужских голосах третья область – это высокая певческая форманта, о которой уже было сказано выше.
Первую область называют первой (нижней) певческой формантой, она определяет мягкость, массивность голоса. Вторая область, которую называют артикуляционной (фонетической) формантой, ниже по уровню и совпадает со второй формантой звука "а" (хотя певец поет все гласные, по-видимому, при пении они все становятся ближе к "а" по артикуляции). Различия между басами, баритонами и тенорами отчетливо видны на расположении этих трех максимумов:
F1, Гц F2, Гц F3, Гц Басы 380…540 760…1100 2100…2500 Баритоны 450…540 1100 2500 Тенора 540…640 1300 2500…3000
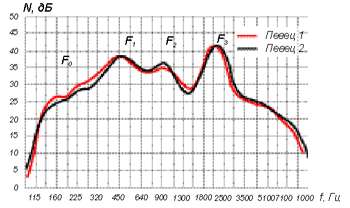 Рис. 11 Огибающая для женских голосов
В женских певческих голосах также отчетливо видны три стабильные области максимумов (рисунок 11), только основная частота на октаву выше, чем у мужчин, и практически совпадает с первой формантной областью (примерно 450 Гц), вторая форманта выражена сильнее, чем у мужчин, а третья область 3,5 кГц ниже по уровню.
В обычной речи при произнесении различных гласных формантные области все время смещаются в процессе речевого потока, эта вариабельность и обеспечивает разборчивость речи. Одним из требований к хорошему певческому голосу является "ровность" тембра, так как, если при пении произносить гласные как и при речи, то имеет место "пестрота" пения. Это требование приводит к выравниванию гласных – при пении на высоких тонах все гласные воспринимаются как "а", так как из-за подстройки формант все гласные поются с широко открытым ртом. По-видимому, в начальный период атаки звука все форманты устанавливаются для опознания звуков, затем голосообразующий аппарат перестраивается для пения и стабилизирует форманты. Это, конечно, не сглаживает общие тембральные различия при исполнении разных произведений разными людьми, поскольку сохраняются существенные различия в высших обертонах, характере атаки и спада звука и др. Однако эту специфику спектральных характеристик вокальной речи следует учитывать при ее обработке и записи.
Разборчивость вокальной речи
Спектральная перестройка голоса для повышения его помехоустойчивости как с помощью создания особой певческой форманты, так и с помощью подстройки формант, неизбежно приводит к перестройке первых формантных областей по частоте, амплитуде, добротности и др., а поскольку именно первые две формантные области отвечают за распознавание гласных в речи, то перестройка первых формантных областей в процессе пения приводит в целом к ухудшению разборчивости вокальной речи. Хотя главная задача вокальной речи состоит в передаче эмоционально-эстетической информации, но передача семантической информации (понимание произносимого текста) также имеет существенное значение (во всяком случае, в классической вокальной культуре). Многие педагоги, певцы (например, Карузо, Шаляпин и др.) и композиторы уделяли очень большое значение дикции при исполнении вокальных произведений (хотя дикция – более широкое понятие, включающее в себя как разборчивость, так и другие особенности произношения).
Попытки количественно оценить разборчивость вокальной речи и влияние на нее перестройки формант были предприняты в работах В.П. Морозова. За основу был взят субъективный метод оценки слоговой разборчивости ("Звукорежиссер", 5/2002). Группа тренированных экспертов также проводила прослушивание слогов из стандартных артикуляционных таблиц, произносимых как в обычной речи, так и пропетых на разной высоте тона. Статистическая обработка большого количества испытаний позволила выявить некоторые общие закономерности: средняя разборчивость вокальной речи оказалась у всех испытуемых вокалистов ниже, чем разборчивость обычной речи у них же – ее значение снизилось в среднем с 87 до 70,7%. Причем, если у мужчин эти величины составляли 86,7 и 75%, то у женщин – 88% и 65%, то есть разборчивость женских голосов в вокальной речи падает гораздо значительнее, что, очевидно, связано с высотой их голоса. Рис. 11 Огибающая для женских голосов
В женских певческих голосах также отчетливо видны три стабильные области максимумов (рисунок 11), только основная частота на октаву выше, чем у мужчин, и практически совпадает с первой формантной областью (примерно 450 Гц), вторая форманта выражена сильнее, чем у мужчин, а третья область 3,5 кГц ниже по уровню.
В обычной речи при произнесении различных гласных формантные области все время смещаются в процессе речевого потока, эта вариабельность и обеспечивает разборчивость речи. Одним из требований к хорошему певческому голосу является "ровность" тембра, так как, если при пении произносить гласные как и при речи, то имеет место "пестрота" пения. Это требование приводит к выравниванию гласных – при пении на высоких тонах все гласные воспринимаются как "а", так как из-за подстройки формант все гласные поются с широко открытым ртом. По-видимому, в начальный период атаки звука все форманты устанавливаются для опознания звуков, затем голосообразующий аппарат перестраивается для пения и стабилизирует форманты. Это, конечно, не сглаживает общие тембральные различия при исполнении разных произведений разными людьми, поскольку сохраняются существенные различия в высших обертонах, характере атаки и спада звука и др. Однако эту специфику спектральных характеристик вокальной речи следует учитывать при ее обработке и записи.
Разборчивость вокальной речи
Спектральная перестройка голоса для повышения его помехоустойчивости как с помощью создания особой певческой форманты, так и с помощью подстройки формант, неизбежно приводит к перестройке первых формантных областей по частоте, амплитуде, добротности и др., а поскольку именно первые две формантные области отвечают за распознавание гласных в речи, то перестройка первых формантных областей в процессе пения приводит в целом к ухудшению разборчивости вокальной речи. Хотя главная задача вокальной речи состоит в передаче эмоционально-эстетической информации, но передача семантической информации (понимание произносимого текста) также имеет существенное значение (во всяком случае, в классической вокальной культуре). Многие педагоги, певцы (например, Карузо, Шаляпин и др.) и композиторы уделяли очень большое значение дикции при исполнении вокальных произведений (хотя дикция – более широкое понятие, включающее в себя как разборчивость, так и другие особенности произношения).
Попытки количественно оценить разборчивость вокальной речи и влияние на нее перестройки формант были предприняты в работах В.П. Морозова. За основу был взят субъективный метод оценки слоговой разборчивости ("Звукорежиссер", 5/2002). Группа тренированных экспертов также проводила прослушивание слогов из стандартных артикуляционных таблиц, произносимых как в обычной речи, так и пропетых на разной высоте тона. Статистическая обработка большого количества испытаний позволила выявить некоторые общие закономерности: средняя разборчивость вокальной речи оказалась у всех испытуемых вокалистов ниже, чем разборчивость обычной речи у них же – ее значение снизилось в среднем с 87 до 70,7%. Причем, если у мужчин эти величины составляли 86,7 и 75%, то у женщин – 88% и 65%, то есть разборчивость женских голосов в вокальной речи падает гораздо значительнее, что, очевидно, связано с высотой их голоса.
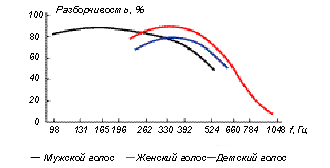 Рис. 12 Зависимость разборчивости вокальной речи от высоты тона
Зависимость слоговой разборчивости от высоты основного тона голоса показана для мужских, женских и детских голосов на рисунке 12. Как следует из полученных данных, область максимальной разборчивости соответствует частоте основного тона для мужских голосов в области 110…262 Гц (почти полторы октавы), а для женских голосов – 330…524 Гц. При повышении частоты основного тона до 500 Гц разборчивость мужских голосов падает, но все-таки сохраняется на уровне примерно 50%, в женских голосах при повышении основного тона до 104 Гц (С3) разборчивость практически стремится к нулю.
Таким образом, зона хорошей разборчивости находится в средней части диапазона голоса, несколько уменьшается в области низких частот и значительно падает в области высоких, причем у женских голосов значительно больше, чем у мужских.
Поэтому в области средних частот, совпадающей с речевым диапазоном для данного певца, разборчивость вокальной речи практически такая же, как и обычной речи, но по мере повышения высоты голоса разборчивость резко падает. Существует несколько основных причин этого явления. При повышении частоты основного тона (например, до 1000 Гц) на высоких тонах остается слишком мало обертонов, которые попадают в слышимый диапазон, это также меняет тембр звуков и затрудняет их опознание. Основной тон оказывается в области за пределами формантных частотных областей, и певец старается произвести подстройку формант, но сдвиг первых формант резко ухудшает распознавание звуков речи и соответственно разборчивость. Более 30% энергии концентрируется в области певческой форманты, соответственно снижается уровень первых формант, что также сказывается на разборчивости. Наконец, в вокальной речи особенно проявляется разница по уровню и по длительности между гласными и согласными звуками. Уровень гласных может достигать 110…120 дБ, уровень согласных 40…70 дБ, что приводит к явлениям маскировки согласных, а, поскольку согласные передают основную семантическую информацию, то значительная потеря разборчивости в вокальной речи обусловлена также нечеткой артикуляцией согласных, что важно учитывать при записи и обработке речи.
В целом, если ставится задача передачи слова в пении, то лучше, если произведение написано для средних (и низких) регистров, что всегда учитывалось раньше композиторами (по-видимому, на интуитивном уровне); при пении в высоких регистрах передача вербального содержания происходит плохо, основная задача здесь – передача эмоций.
(продолжение следует) Рис. 12 Зависимость разборчивости вокальной речи от высоты тона
Зависимость слоговой разборчивости от высоты основного тона голоса показана для мужских, женских и детских голосов на рисунке 12. Как следует из полученных данных, область максимальной разборчивости соответствует частоте основного тона для мужских голосов в области 110…262 Гц (почти полторы октавы), а для женских голосов – 330…524 Гц. При повышении частоты основного тона до 500 Гц разборчивость мужских голосов падает, но все-таки сохраняется на уровне примерно 50%, в женских голосах при повышении основного тона до 104 Гц (С3) разборчивость практически стремится к нулю.
Таким образом, зона хорошей разборчивости находится в средней части диапазона голоса, несколько уменьшается в области низких частот и значительно падает в области высоких, причем у женских голосов значительно больше, чем у мужских.
Поэтому в области средних частот, совпадающей с речевым диапазоном для данного певца, разборчивость вокальной речи практически такая же, как и обычной речи, но по мере повышения высоты голоса разборчивость резко падает. Существует несколько основных причин этого явления. При повышении частоты основного тона (например, до 1000 Гц) на высоких тонах остается слишком мало обертонов, которые попадают в слышимый диапазон, это также меняет тембр звуков и затрудняет их опознание. Основной тон оказывается в области за пределами формантных частотных областей, и певец старается произвести подстройку формант, но сдвиг первых формант резко ухудшает распознавание звуков речи и соответственно разборчивость. Более 30% энергии концентрируется в области певческой форманты, соответственно снижается уровень первых формант, что также сказывается на разборчивости. Наконец, в вокальной речи особенно проявляется разница по уровню и по длительности между гласными и согласными звуками. Уровень гласных может достигать 110…120 дБ, уровень согласных 40…70 дБ, что приводит к явлениям маскировки согласных, а, поскольку согласные передают основную семантическую информацию, то значительная потеря разборчивости в вокальной речи обусловлена также нечеткой артикуляцией согласных, что важно учитывать при записи и обработке речи.
В целом, если ставится задача передачи слова в пении, то лучше, если произведение написано для средних (и низких) регистров, что всегда учитывалось раньше композиторами (по-видимому, на интуитивном уровне); при пении в высоких регистрах передача вербального содержания происходит плохо, основная задача здесь – передача эмоций.
(продолжение следует)
|
|